







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
+ 分支预测算法
- 1位预测:如果当前的跳转指令上次就发生了一次跳转,就预测此次也会发生跳转(容易翻转)
- 2位预测:跳转1次加1(最大为3),未跳转减1。0、1不跳转,2、3跳转
- 分支预测实现(Intel分支预测模块)
- Branch Target Buffer(BTB):记录跳转语句的跳转情况

- The Static Predictor:静态预测器,在BTB中未记录跳转语句信息时使用,是人为总结出的经验规律:向下跳转预测为不跳转,向上跳转预测为跳转(向上通常是循环)
- Return Stack:函数调用时将函数的返回地址压栈到Return Stack返回栈中,当遇到函数返回指令时就从返回栈中取址
+ 条件执行:分支预测会消耗大量的资源,很多低能耗的处理器没有分支预测,如TI DSP(不擅长处理复杂的控制代码),它采用指令的条件执行来减少跳转指令

4.2.处理器乱序执行
-
为何乱序执行:指令在执行时常常因为一些限制而等待,乱序执行可以让处理器先执行后面不依赖于该数据的指令
-
指令的相关:指令之间的相关和依赖会导致指令无法乱序执行
- 寄存器相关:两条指令共用寄存器时,可能产生寄存器相关
- 读读:寄存器不相关
- 写读、读写(反相关):数据相关,乱序执行可能会导致读数据错误
- 写写:名字相关,也称伪相关,两个写操作实际没有逻辑依赖,只是由于通用寄存器较少,两条指令的写结果共用了一个寄存器
- 控制相关:某指令需要依赖于控制流的结果
- 寄存器相关:两条指令共用寄存器时,可能产生寄存器相关
-
去除指令的相关性
- 通过编译器或编码者去除一定的数据相关
- 通过寄存器重命名的方法去除伪相关,将ISA寄存器映射到更多的实际执行时使用的物理寄存器,对寄存器进行重命名,以去除一定的伪相关

- 通过预测跳转指令的目标地址(投机执行)去除一定的控制相关,预测跳转指令的目标地址,并提前执行后续的分支指令,如果预测错误则丢弃结果,或多条分支路径都预执行(Eager execution)
-
乱序执行过程:顺序发射,乱序执行,顺序提交
- 指令Buffer
- 指令调度:指令执行的的时机
- 指令顺序提交、重排缓冲区ROB(实现精准中断)

4.3.处理器并行执行
- Flynn分类
- SISD:一次处理一条指令,一条指令处理一份数据(早期处理器)
- SIMD:一次处理一条指令,一条指令处理多份数据(数据并行)
- MISD:一次处理多条指令,多条指令处理一份数据(没实际意义)
- MIMD:一次处理多条指令,多条指令能处理多份数据(指令并行)

-
指令并行:流水线中多条指令已经可以同时执行。若发射单元一次能发射多条指令,更多的指令就能并行处理了,这被称为多发射multi-issue
-
Superscalar:超标量处理器。过去的标量处理器时代,指令都是串行执行的,超标量处理器为了提高程序执行效率并做到兼容,在处理器内部做了指令的并行化处理,即指令的并行化是在运行阶段进行的

-
代表实例:Intel P4 CPU(采用乱序执行的超标量处理器,采用NetBurst微架构)
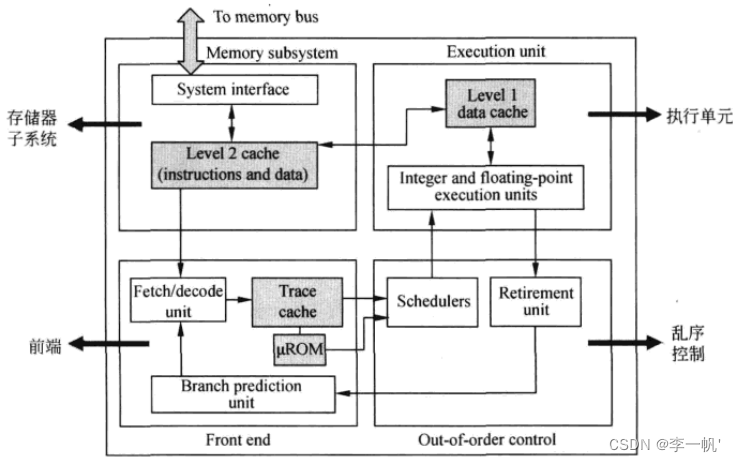
- 存储子系统:包含片内Cache,是处理器内部的存储单元,存储指令和数据 - 前端流水线(负责准备指令)  * 取指:从L2 Cache中读指令,一次读64bit,存储在队列(缓存、隔离节拍)中。读指令时,通过TLB进行指令的虚实地址转换 * 译码 + 译码单元的工作是将x86指令翻译成类似于RISC的微操作uop + 采用预译码的方式解决变长编码多指令的问题,即指令从内存读到Cache中时就开始预解码,得到预译码标识(包括指令的起始位和需要译出的uop数),预译码标识和指令一同存储在指令Cache中 + Intel采用多级译码流水线的方式实现译码,第一级检测指令的起始位,第二级将指令解码为uop + 当一条CISC指令产生的uop数目多于4条时,就将对应的uop存储在micro-ROM(uROM)中,解码时采用查表的方式读码 + 译码后的指令也存储于一个Buffer Queue中 * 按照uop执行的顺序(而非指令顺序)存放在Trace Cache中 * 再从Trace Cache中读uop存储到uop Queue(前后端的桥梁)中 * 注意:运算单元实际指令时,直接从uop Queue中取uop,当uop Queue中没有所需的uop时,才会进行上述的步骤,访存取指 - 后端流水线(负责执行指令) 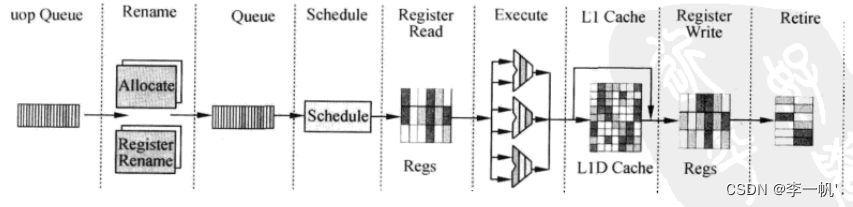 * uop进入后端时,进行资源的分配,为其分配到Buffer(寄存器)中,再被重命名。通用寄存器和物理寄存器的映射关系在RAT中存储 * 指令的调度(Schedule):乱序执行的核心,调度器根据uop操作数的准备情况和执行单元的空闲状态决定uop何时执行。 * 访存指令和ALU运算指令被调度器分配到不同的分牌口Dispatch Ports 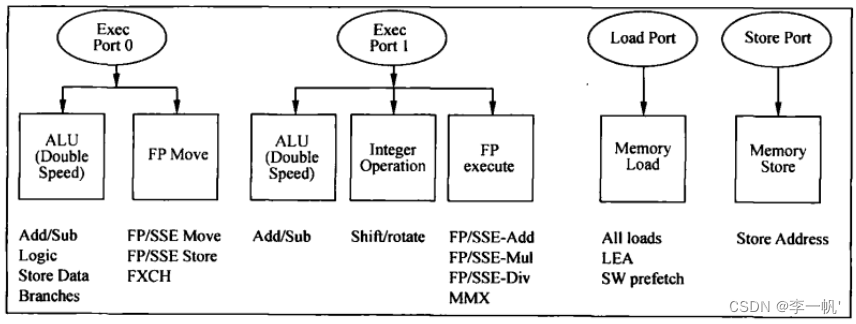 * Register Read、Execute、L1 Cache(MEM)、Register Write(类MIPS5级流水线) * Retire退出:更新ISA寄存器状态,指令按照顺序退出乱序执行内核-
VLIW:指令的并行化由编译器或程序员手工完成,即在编译时完成指令的并行。并行性更好,擅长做密集运算,但不擅处理Cache miss、跳转,顺序执行能耗低
-
DSP的应用:手机中的无线信号处理、语音图像视频信号的处理;多媒体终端;摄像头、基站
-
代表实例:TI C6000 DSP
-
典型的顺序执行单元,指令的执行顺序和并行在指令格式中描述清楚了(成功的关键在于编译器能否将高级语言翻译成并行性好的指令序列)
-
DSP的执行单元由8个单元组成,每个单元可以执行某些类型的运算。拆分成左右两组的设计方式能减少端口数,降低芯片的面积和能耗

-
指令并行性
- 循环展开:将循环按模4进行展开

- 软件流水:将取址、运算、存数以流水方式进行
-
-
-
-
数据并行
-
多媒体应用:语音信号经过8K Hz采样后,1秒钟包含8000个样点,图像在二维上进行采样。多媒体程序的共同特点:同一操作会重复处理多个数据
-
SIMD、MMX、SSE、AVX:高性能处理器基本都包含SIMD指令,Intel逐步推出MMX、SSE、AVX指令集(即具体的SIMD指令集)MMX指令和浮点处理单元FPU指令共用64bit的寄存器,一次可以处理64bit的数据,SSE指令集使用单独的寄存器,一次可以处理128bit的数据(可以是2×64、4×32、8×16数据的组合),AVX指令集可以一次处理256bit的数据
-
SSE指令形式
-
垂直计算形式:X、Y寄存器被看成一个向量,每个标量数据分别运算,这是SIMD指令最常用的计算形式

-
水平计算形式:两个操作数来自于同一个源

-
标量计算形式:垂直形式中,仅有x0和y0进行操作,其他元素不变

-
-
-
线程并行
-
软件多线程(OS):轮询、中断等方式执行不同的线程,上下文切换(ISA寄存器保存线程状态)
-
硬件多线程:在处理器中多开辟几份线程状态,线程切换时,处理器切换到对应的线程状态执行
- 粗粒度:中断切换
- 细粒度:每个cycle轮询不同线程
- 同时多线程STM(Intel 超线程):muti-issue时,多条指令来源于不同线程
-
多核
-
多个核共用处理器的外设与接口(内存控制器、PCI-E等),以及一段Cache
-
多核组织结构:p为核,c为Cache,连线为多核的通信方式

-
Bus:结构简单,两核通信时会发生总线占用,其他核不能通信,通信效率低
-
Switch:通信效率最高,核两两连线,但核心太多时资源消耗大,一般4核时使用
-
Ring:介于Bus和Switch,1、3通信需要经过2,越接近的两个核通信效率越高,连线不复杂成本较低,8核左右时使用
-
Mesh:适合于核数非常多的情况,如众核处理器(64/100),类似于二维的Ring结构,结构简单,易于扩展,通信效率较高
流水线、指令并行、数据并行、线程并行是相互关联的,它们有时只是观察粒度不同
-
-
5.Cache

使用SRAM做Cache
5.1.Cache的时空局部性
- 时间局限性:如果某个数据被访问到,那么在不久的将来它很可能再次被访问(循环)
- 空间局限性:如果某个数据被访问到,那么与它相邻的数据很可能很快被访问(数值、指令)
5.2.Cache的结构
-
Cache的层次和化管理
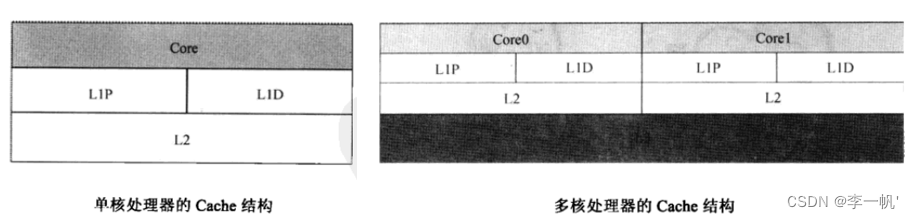
- 2级结构:L1P L1D是程序和数据分别各自的Cache,L2为两者共享的Cache(L1通常与内存同频,L2通常降频使用,级别越大空间越大)
- 3级结构:L3为多核共享的Cache
-
Cache hit与Cache miss:整个Cache空间会被分为N个line,每个Cache line通常是32、64byte,是Cache与内存交换数据的最小单位
-
Cache的映射方式:内存的大小要远大于Cache的大小,因此将内存中的数据填充到Cache中是一种多对一的关系
- 全关联Cache(Full-associative Cache):任意内存分块可以映射到任意Cache line中,缺点是判断一个数据是否在Cache中时,需要遍历Cache line,查每一个tag,检索效率低
- 直接映射Cache(Direct-mapped Cache):将内存按Cache大小分为N个Page页,每个Page页和Cache大小相同,每个Page中的line0只能对应于Cache line0。根据地址就能索引到对应的Cache位置,内存地址 % Cache容量 % Cache line num - 0,缺点就是在一些情况下容易造成某一Cache line数据热点,其余Cache line 空闲
- 组关联Cache(Set-asoociative Cache),结合上面两种映射方式,先将Cache划分为多份way,访问时先通过直接映射的方式计算出Cache set,再通过遍历的方式寻找way。way越多检索效率提高,但cache way容量减少,又容易发生cache miss使得检索效率降低,因此way的个数需要平衡
-
Cache的置换策略:Cache已满但Cache miss,如何置换已装入的Cache line,FIFO、Random、LRU…
-
Cache的写方式:CPU改变了Cache的值,如何更新内存对应的数据
- 写通Write through:立即回写
- 写回Write back:不立即回写,在一定时机下(如其他指令要访问内存中的该数据时)再写回(dirty:是否改写、valid:是否有效、tag:内存中的地址标识、block:实际数据)

5.3.Cache一致性问题
多核处理器中,不同核从内存或公共Cache中读取数据保存于各自的Cache中,其中某一核改写了自己Cache中的该数据,另一核不可见
- 解决方法1:Write invalidate:某一核1改变了自己Cache中的数据,设置其他核中的该Cache line为无效,若其他核也使用该数据,则会造成核1回写内存,其他核再从内存中读,保证一致性
- 解决方法2:Write Update:当一内核修改了数据,其他地方若有这份数据的复制,则将其他核都更新到最新值
- Cache一致性协议:MESI协议(监听协议:每个Cache都要监听总线上的所有操作)
5.4.片内可寻址存储器——对程序员可见的Cache
x86处理器中,Cache对程序员透明,一切由物理硬件来管理;DSP等处理器,其内部的处理器一部分可作Cache,另一部分可作为片内寻址存储器,可由程序员通过软件控制DMA(Direct Memory Access)搬运数据,DMA提供了1D、2D、3D的搬运方式(2D是在1D的基础上进行的)

6.编写高效代码
软件性能优化的第一步:调查程序各个模块(函数)的执行时间(可以使用软件性能剖析工具)
6.1.减少指令数
-
使用更快的算法
-
选择合适的指令:在高级语言编程时,编译器通常不会使用一些如乘累加、求绝对值等复杂指令,而是将高级语言编译为多条简单指令,使用相应功能的复杂指令,能够减少指令数量。使用复杂指令最直接的方式是编写汇编语言,但这不符合当前使用高级语言的场景。编译器提供了一种更方便的汇编指令使用方式:Instrument function,如SSE3中的指令
addsubps,其对应的Instrument function用法为:w = _mm_addsub_ps(u,v);,它会被编译器直接翻译成对应的汇编指令 -
降低数据精度
-
减少函数调用
- 小函数直接写成语句
- 将小函数写成宏
#define min(a,b) ((a)<(b)) ? (a):(b)
c = min(a,b);
+ 将函数声明为内联函数:编译器会自动用函数体覆盖函数调用
inline int min(int a,int b){
return a < b ? a: b;
}
- 空间换时间
- 减少过保护(减少可协调的数据校验)
6.2.减少处理器不擅长的操作
单周期指令是处理器最喜欢的,不仅执行时间短,还有利于流水线执行
- 少用乘法
// 适用于乘2的N次方
len = len\*4;
len = len <<2;
- 少用除法、求余
f = f / 5.0
#define cof 1.0/5
f = f \* cof;
- 在精度允许的条件下,将浮点数定点化
e.g. alpha混合,通过两张图像进行半透明混合模拟CS烟雾弹效果
// alpha为透明度,从0-1的小数
pixel_C = (int) (Pixel_A \* alpha + Pixel_B \* (1 - alpha));
// 将alpha定点化为0-32之间的一个整数值
pixel_C = (Pixel_A \* alpha + Pixel_B \* (32-alpha) + 16 ) >>5;
- 尽量减少分支
for(int i=0;i<100;i++){
if(i%2 == 0) a[i] = x;
else a[i] = j;
}
for(int i=0;i<100;i+=2){
a[i]= x;
a[i+1] = y;
}
- 将最有可能进入的分支放在if中,而不是else中
6.3.优化内存访问
- 少用数组,少用指针
大块数据会存储在内存中,简单局部变量才会被放在寄存器中,因此在等效的情况下,应该少用数组和指针,多用简单局部变量
// 4次访存
c = a[i] \* b[i];
d = a[i] + b[i];
// 2次访存
x = a[i];
y = b[i];
c = x \* y;
d = x + y;
-
少用全局变量:全局变量因为会被多个模块使用,不会被放到寄存器中,局部变量才会被放在寄存器中,应避免使用全局变量
-
一次访问多一些数据(减少访存次数)
-
数据对齐访问
-
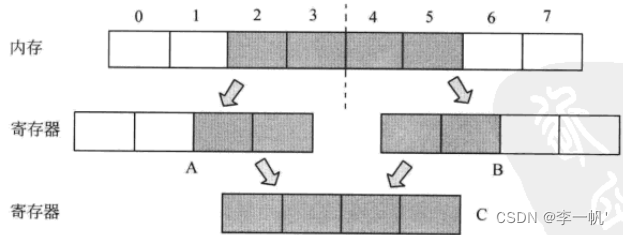
非对齐访问:如32位处理器中,一个int变量占4个byte,若如下图非对齐存储时,内核访问该数据时,会访存两次再拼成一个int型。对齐访问时,则需要只访存一次
-
对齐访问:2字节变量的起始地址应该为2的整数倍,4字节变量的起始地址应该为4的整数倍…处理器通常会提供对齐的数据访问指令和非对齐的数据访问指令,对齐的数据访问指令效率要远高于非对齐的数据访问指令
-
-
大数据结构时的Cache line对齐:Intel处理器的Cache line大多为64byte,在对一个大数据结构(大数组或大结构体)分配内存时,数据结构的起始地址最好是64byte的整数倍,这样Cache miss的次数最少
-
程序、数据访问符合Cache的时空局部性
/\* 以二维数组为例,二维数组的每一个一维数组容易被一起组织到Cache里,
因而访问时尽管按行和按列遍历的逻辑不变,但按行优先访问的Cache hit更高,
因而效率也更高\*/
for(int j=0;j<500;j++){
for(int i=0;i<500;i++){
sum += a[i][j];
}
}
for(int i=0;i<500;i++){
for(int j=0;j<500;j++){
sum += a[i][j];
}
}
将需要一起访问的数据和程序放在一起,可以减少Cache miss数
- 多线程编程时避免false sharing
多核多线程程序若不共享数据,实际执行时它们分别所用的数据仍可能存在于同一Cache line中,这时某一线程修改数据,就会引起Cache冲突,尽管两线程所用的数据是独立的,这种现象叫做假共享false sharing。解决false sharing的方法就是将多个线程访问的数据放置在不同的Cache line中
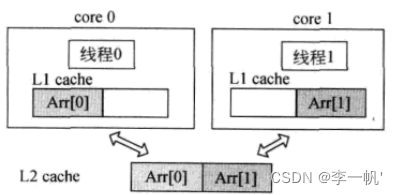
多线程编程时应注意:尽量少共享数据、尽量少修改数据、尽量少频繁的修改数据
- 自己管理动态内存分配
编程时若遇到需要频繁动态申请释放内存的情况,如链表,数据项的修改会修改指针指向并进行堆内存的申请和释放,若修改过于频繁则会导致:
malloc、free函数会消耗大量的执行时间;会产生内存碎片,浪费内存空间,有可能会导致内存泄漏(申请的内存忘记释放),空间比较分散增大了Cache miss的可能
此时可以采用池的思想,申请一大块空间,划分出N个节点,自己管理闲置空间和已使用的空间,如维护两个链表,一个是已使用的,一个是闲置的
- 隐藏数据搬移时间
如果处理器内部有片内可寻址存储器SRAM,应先用DMA把数据搬到处理器内部,这样内核访问数据的速度会快很多,对Cache具有预取机制的处理器,可以让Cache提前预取数据
6.4.充分利用编译器进行优化
-
编译器的结构:编译器的前端分析高级语言代码的文本,生成中间代码,后端对中间代码做通用优化和针对处理器的优化,生成在处理器上执行的目标代码
-
编译器提供优化选项
- 优化参数
- Intel:-ipo
- TI DSP:-pm
- 优化级别
- -O0:不优化或进行很小的优化
- -O1、-O2、-O3:-O3一般是文件内部的优化
- 空间平衡:编译器优化常常会带来程序空间的增加(如自动做函数inline等),编译器会开放一些选项来让程序员平衡时间和空间
- VC 6.0:maximize speed、minimize size
- TI DSP:-ms0
- 优化参数
-
编译器的一些优化工作
- 自动计算常量
a = b + 2.0 / 3.0;
a = b + 0.66666666;
+ 简单表达式简化
b = (a+5) \* (a+5);
c = (a+5) / 4;
int temp = a+5;
b = temp \* temp;
c = temp >> 2;
+ 提取循环中的公共语句
+ 循环展开、软件流水:C6000 DSP在循环代码前通过预编译指令告诉编译器一些信息以便其优化
// 告诉编译器for循环至少执行4次,最多执行256次,循环次数是4的整数倍
#pragma MUST\_ITERATE (4,256,4)
for()
+ 自动向量化:编译器自动向量化通常需要程序员告诉编译器一些信息,如下例restrict关键字告诉编译器这几个变量没有空间交叠,因此编译器才敢将代码优化为SIMD指令
void add(float \*restrict a,float \*restrict b,float \*restrict c){
for(int i=0;i<4;i++) c[i]= a[i] + b[i];
}
+ 高效的数据组织:编译器为程序中的变量分配合适的存储空间
+ 指令并行化:VLIW处理器的编译器可以进行指令的并行化
6.5.多核多线程
- 并行计算
- 任务划分:不同线程执行不同的逻辑代码
- 数据划分:不同线程执行同一逻辑代码处理不同数据
- 数据流划分:任务分节拍,每个线程处理一个节拍,循环形成流水
- Amdahl’s Law:程序执行总会有串行执行的部分,并行计算的效率取决于:可并行部分占总过程的比例;并行的程度
- 多线程编程
- 操作系统提供了线程库,让程序员能方便地使用线程,如Linux的POSIX Thread(PThread)和Windows下的Win 32 Thread
- 线程同步、锁
- 线程间的负载均衡、公平性
- 多线程的可扩展性
- OpenMIP库:并行编程框架
#pragma omp paralle num\_threads(8) // 设置8个线程数
#pragma omp paralle for // 将下面的循环分到8个线程中执行
for(int i=0;i<1024;i++) c[i] = a[i] + b[i];
7.SOC
7.1.SOC
片上系统SOC(System On Chip)是将一整个系统做在一块芯片上。一块只包含同一种类型的处理器内核的芯片被称为处理器,SOC通常包含不同类的处理器内核或是处理器+硬件加速器的结构(如CPU内核集成内存控制器、GPU内核,已不再需要北桥芯片了)
集成电路、软硬件技术、仿真技术的发展使SOC得以实现
7.2.IP
- IP的概念
- Intellectual Property:无形资产,如专利、版权
- 半导体领域中,IP是指一块独立的逻辑或电路设计(由代码描述和维护),如处理器核、存储器核等。IP是SOC的基本组成部分,SOC就是将一些IP通过互联网络连接起来。如手机中的应用处理器Application Processor:类似于PC中的处理器+显卡+南北桥
- 半导体产业
- 示例:IP设计公司设计IP核 → 代工厂生产IP核 → 半导体公司连接SOC芯片 → 设备商组装设备 → 终端用户。
- 不少半导体公司是从通信公司中分离出来的,半导体是通信、IT、嵌入式等行业的基石
- IP核分类
- CPU IP:面向通用型的应用,最容易编程,x86、ARM、MIPS、PowerPC都可以叫做CPU
- DSP IP:手机中常有,负责无线通信的基带处理器,也叫Modem调制解调器,负责语音信号的编解码和无线信号的处理
- GPU:硬件化的图形加速设备,最适合图形算法
- nVidia 1.0:提供固定功能的图形产品
- nVidia 2.0:提供可编程GPU
- nVidia 3.0:转型到并行计算公司
- Video Engine:是一种硬件加速器,专门做某种工作的电路,不能编程,只能通过配置完成某几种功能。计算能力强,功耗很低,IP核的面积小。CPU和手机的应用处理器中都集成有该核,用于视频的编解码加速
8.芯片原理与设计制造
8.1.逻辑电路基础
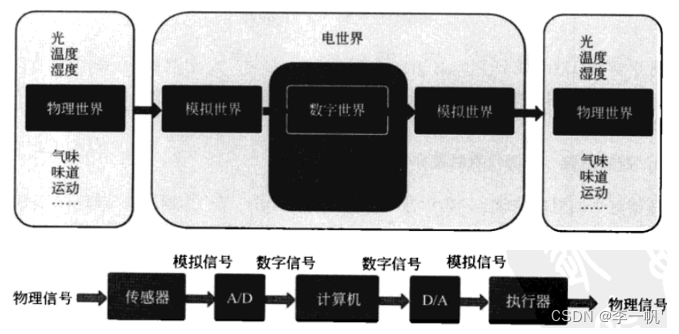
- 物理信号、模拟信号、数字信号
-
人类只能感受物理信号,计算机只能处理器数字电信号
-
物理信号(光、气味、震动等)通过传感器可以变成电信号,这时的电信号是以模拟信号的形式存在的,取值连续,经过A/D转换器就可以转变为数字信号。数字信号经计算机处理后,经过D/A转换器转换为模拟信号,模拟信号经过执行器被重新转换为物理信号,就可以被人类感知了
-
A/D(Analog/Digital)转换器
- 采样:在时间上的离散化
- 量化:幅值上离散化
- 编码:量化后数值的二进制化

-
逻辑与电路:用逻辑来抽象电路,逻辑上的电路与电路的物理实现不同
- 数字电路中只逻辑取0、1分别表示高低电平,电压在0-
V
l
V_l
Vl之间表示逻辑0,在
V
l
−
V
d
V_l-V_d
Vl−Vd之间表示逻辑1,电压在
V
d
−
V
h
V_d-V_h
Vd−Vh之间为禁止区域,电压值不应在此范围
- 数字电路相对于模拟电平具备更大的噪声容限,信号在传输时,不可避免地引入较大的噪声,对于模拟信号,若引入了噪声,则很难完全消除
- 数字电路并不是和模拟电路完全对立的电路,数字电路中的电压值也是连续的,不过它进行了逻辑抽象,正是这种抽象简化了电路的分析

-
数字电路的构成
-
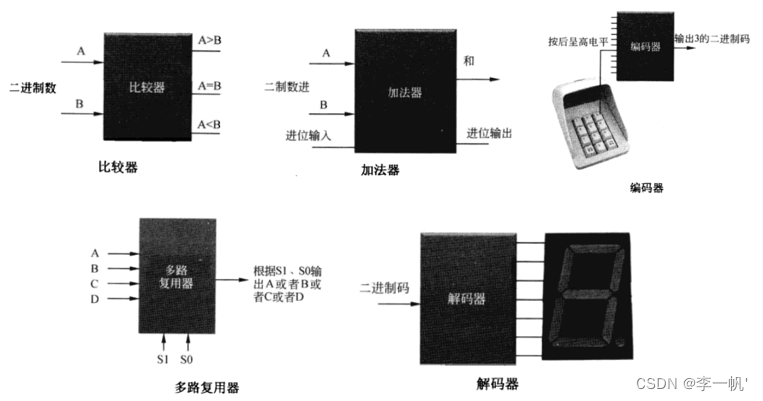
组合逻辑电路:输入发生变化,输出立即发生变化
- 比较器:输入A、B为二进制码,实际为32根线,表示32bit的数据。A>B第一根输出线呈高电平,其他两根线为低电平
- 加法器:数字电路中最重要的模块,是其他所有运算(减法、乘法、除法等)的基础。多位的加法也是通过一位加法实现的,逐位相加保留进位
- 编码器、解码器:输入输出的二进制编解码
- 多路复用器:从多个输入源选择一个输入到输出端
-
时序电路:输出除了和输入有关还和电路当前的状态有关。
- 一个时序电路包括一个组合逻辑电路和一个能保留状态的寄存器,该寄存器是由触发器实现的,一个触发器可以存储1bit的数据,32bit的寄存器就是由32个触发器及其周围电路组成的
- 触发器只在每个时钟周期的上升沿或下降沿触发

-
实际的数字电路是组合逻辑电路和时序电路的组合。下图中每个节拍就是一个逻辑组合电路,寄存器缓存了每个节拍的输出结果,每个节拍的执行时间要小于时钟周期。数字电路是天然的流水线结构,通过划分节拍能够提高电路的工作频率,可以减短时钟周期
-
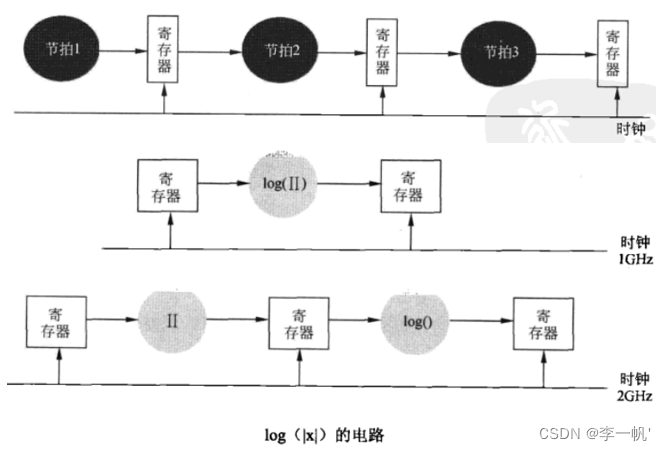
8.2.微电子技术
- 晶体管(半导体建筑用砖)
- 电路中的两种基本元件:二极管、三极管
- 二极管:可以控制电流的方向,允许电流朝一个方向移动,禁止向另一方向移动
- 三极管:在二极管中加入了被称为控制栅的第三级,可以用来实现开关电路(用于数字电路)和放大电路(用于模拟电路)
- 物质根据导电性可分为3类:良导体、绝缘体、半导体,最常见的半导体材料为硅和锗,它们本身不导电,不过在掺入其他元素(硼、磷等)使它们只在一个方向导电。硅是地球上除了氧外含量最高的元素,可以从沙子(氧化硅)中提炼

- 集成电路
将电路的所有元件都集成到一块半导体之上。集成电路制程工艺的发展,使得晶体管越来越小,晶体管的集成度越来越高,晶体管的工作速度也越来越快
8.3.芯片设计
- 人类如何解决复杂问题:抽象、分层、规范化、模块化
- 电子设计自动化EDA:是电路领域的计算机辅助设计CAD,设计者能在EDA软件平台上完成集成电路的全套设计,直至将设计交给工厂流片
- 芯片设计流程
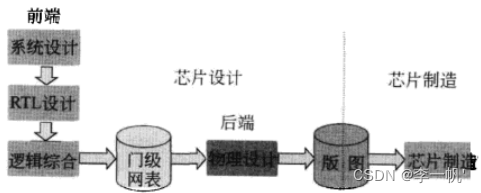
+ 前端逻辑设计,输出门级网表
- 硬件描述语言HDL:VHDL和Verilog是业界主流的两种硬件描述语言,其中Verilog使用较多。硬件描述语言与软件描述语言相比,需要关注更多实现细节,如控制通道、并行和时序
- 建模层次

* 行为级建模:描述电路的功能,不关心电路的具体结构,只关注算法,主要用于建模和仿真
* RTL建模(主要):描述电路的结构,寄存器传输级,可以使用Verilog语言实现
```
module half_clk(clr,clk,q);
intput clk,clr;
output [3:0]q;
reg [3:0]q;
always @(negedge clk or posedge clr)
begin
if(clr) q=0;
else q=q+1;
end
endmodule
```
* 门级:描述门级电路
* 电路级
- 逻辑综合:Verilog源代码被编译成具体的电路,综合过程中也会对电路进行优化,也会平衡效率和电路规模

- 门级网表:HDL代码综合出来的结果也是前端设计的结果,描述了电路的门级结构,以与、非门等为基础
+ 后端物理设计,输出版图。将前端生成的门级网表通过EDA工具进行布局布线和物理验证,最终生成供制造用的版图文件,以GDS Ⅱ格式存储,它描述了集成电路的物理结构。集成电路的基本元件都和连线都是在硅片上一层一层的腐刻出来的。版图描述了电路结构,即哪些地方该腐刻,哪些地方该保留
+ 流片:芯片制造,一般交由代工厂制造
- 芯片制造的工艺相当精密(精密制造),世界上最大的芯片制造代工厂是台积电
- 芯片制造流程:成本非常高,每一步都需要精密的工具,在严苛的环境下进行
* 前端(晶圆厂)
+ 晶圆是芯片电路的载体,一块晶圆可以做出多片芯片,它是一个圆形的硅晶体。晶圆所使用的单晶硅纯度很高,厚度很薄,大部分晶圆材料来源于日本
+ 洁净室:芯片制造过程中的空气纯度要求很高,粒子附着在芯片上就可能导致芯片出现瑕疵而不能使用。半导体的洁净室比医院的手术室还要干净1000倍
+ 晶圆加工:集成电路版图被印在掩膜上,经过光刻、掺杂、腐蚀等步骤,在晶圆上形成晶体管,再注入铜粒子,形成导线,完成了集成电路的制造
+ 晶圆测试
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
的物理结构。集成电路的基本元件都和连线都是在硅片上一层一层的腐刻出来的。版图描述了电路结构,即哪些地方该腐刻,哪些地方该保留
+ 流片:芯片制造,一般交由代工厂制造
- 芯片制造的工艺相当精密(精密制造),世界上最大的芯片制造代工厂是台积电

- 芯片制造流程:成本非常高,每一步都需要精密的工具,在严苛的环境下进行
* 前端(晶圆厂)
+ 晶圆是芯片电路的载体,一块晶圆可以做出多片芯片,它是一个圆形的硅晶体。晶圆所使用的单晶硅纯度很高,厚度很薄,大部分晶圆材料来源于日本
+ 洁净室:芯片制造过程中的空气纯度要求很高,粒子附着在芯片上就可能导致芯片出现瑕疵而不能使用。半导体的洁净室比医院的手术室还要干净1000倍
+ 晶圆加工:集成电路版图被印在掩膜上,经过光刻、掺杂、腐蚀等步骤,在晶圆上形成晶体管,再注入铜粒子,形成导线,完成了集成电路的制造
+ 晶圆测试
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中…(img-5jdbua71-1713371218800)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









