







while(bucket[i]-->0)
a[j++] = i;
}
}
#### 15、排序后最大相邻数差值问题
即n个数,则准备n+1个桶,最后一个桶放最大值max,其他min~(max-1)的数在前n个桶桑平分。比如说数i,它放在哪个桶中就取决于:((i-min)/(max-min))\*n。
如果说有一个桶为空,则其左边第一个不为空的桶的最大值a,与其右边第一个不为空的桶的最小值b,这两个数在排序后一定是相邻的,且他们的差值比每个桶内的差值都大。所以只需要记录这些每个桶内的max和min,比较相邻的前后非空桶的min-max与桶内的max-min的差值大小即可。
所以准备三个n+1大小的数组,一个数组记录这个桶是否为空,另外两个数组分别记录这个桶内的max和min。
int maxgap(vectora)
{
if(a.size()<2)
return 0;
int imax = INT_MIN;
int imin = INT_MAX;
for(int i=0;i<a.size();i++)
{
imax = a[i]>imax?a[i]:imax;
imin = a[i]<imin?a[i]:imin;
}
if(imin==imax)
return 0;
vectorisempty(a.size()+1);
vectoramax(a.size()+1);
vectoramin(a.size()+1);
int index=0;
for(int i=0;i<a.size();i++)
{
index = (a[i]-imin)* a.size()/(imax-imin);
amax[index] = amax[index]?max(amax[index], a[i]):a[i];
amin[index] = amin[index]?min(amin[index],a[i]):a[i];
isempty[index] = true;
}
int gap = isempty[0]?amax[0]-amin[0]:0;
int lastmax = amax[0];
for (int i=1;i<isemppty.size();i++)
{
if(isempty[i])
{
gap = max(gap, amin[i]-lastmax);
lastmax = amax[i];
}
}
return gap;
}
#### 16、KMP算法
想看详细介绍,请参见博客:
<http://blog.csdn.net/liuxiao214/article/details/78026473>
字符串匹配问题,字符串p是否是字符串s的子串,是的话,返回p在s中的起始位置,否的话返回-1。
暴力的方法是p与s的第一个字符比较,相等就继续比较,不相等就换s的第二个字符继续比较,这样做的话,遍历s的指针i会发生回溯,导致时间复杂度为O(N^2)。
那最好是i指针不用发生回溯。这里就用到了字符串的最大公共前缀后缀。
首先是找字符串p的最大公共前缀后缀,比如ABCAB,其最大公共前缀后缀就是AB,长度是2。这样当我们发生不匹配时,直接按照其最大公共前缀后缀长度移动字符串p就可以。
当然我们不直接使用最大相同公共前缀后缀,我们使用的是next数组,这个数组中的数是不包含当前字符的最大前缀后缀的长度,如图:
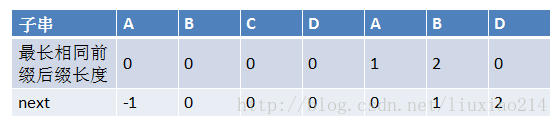
然后这样字符串匹配时,如果发生不匹配,遍历字符串s的指针i不必回溯,只需移动字符串p即可,即更改遍历p的指针j,j变为其next数组中的值。
求next数组利用递归。直接上代码:
vector getnext(string s)
{
vectornext(s.length());
next[0] = -1;
if (s.length()<2)
return next;
next[1] = 0;
int cn = 0;
int i = 2;
while(i<s.length())
{
if(s[i-1]s[cn])
next[i++] = ++cn;
else if(cn>0)
cn = next[cn];
else
next[i++] = 0;
}
}
int kmp(string s, string p)
{
if(s.length()<p.length() || s.length0 || p.length0)
return -1;
int i = 0;
int j = 0;
vectornext=getnext§;
while(i<s.length() && j<p.length())
{
if(s[i]p[j])
{
i++;
j++;
}
else if(next[j]-1)
i++;
else
j = next[j];
}
return jp.length()?i-j:-1;
}
### 三、第三次课(2017.11.18)
#### 17、KMP算法应用:最大重合的新串
给定一个字符串str1,只能往str1的后面添加字符变成str2。
要求:str2中必须包含两个str1,即两个str1可以有重合,但不能是同一位置开头,即完全重合;且str2尽量短。
利用next数组,找到str1的最大公共前缀后缀,然后向str1尾部添加从前缀后开始到str1原尾部的字符。
如:str1=abracadabra,则str2=abracadabra+cadabra
int getnext(string s)
{
vectornext(s.length()+1);
next[0]=-1;
if (s.length()<2)
retrun -1;
next[1] = 0;
int cn = 0;
int i = 2;
while(i<s.length()+1)
{
if(s[i-1]==s[cn])
next[i++] = ++cn;
else if(cn>0)
cn = next[cn];
else
next[i++] = -1;
}
return next[s.length()];
}
string gettwo(string s)
{
if (s.length()==0)
return “”;
if (s.length()==1)
return s+s;
if (s.length()==2)
return s[0]==s[1]?s+s.substr(1):s+s;
return s + s.substr(getnext(s));
}
#### 18、KMP算法应用:两个二叉树是否子树匹配
给定两个二叉树T1,T2,返回T1的某个子树结构是否与T2相等。
常规解法是遍历头节点,看其子树结构是否与T2相等。
这里将二叉树T1与T2都转换为字符串,是否匹配就看T2是否是T1的子串。
如何转换呢?每一个节点的值后面都加一个特殊符号,比如“\_”,空节点用另一个特殊符号表示,如“#”。序列化要按照同样的遍历方式,比如前序遍历。
3
1 2
2 3
上图中序列化后为“3 \_ 1 \_ 2 \_ # \_ #\_ 3 \_ # \_ # \_ 2 \_ # \_ # \_”
struct TreeNode
{
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x):val(x),left(NULL),right(NULL){}
};
string tree2string(TreeNode *root)
{
if(rootNULL)
return “#_”;
string str = to_string(root->val) + “_”;
return str + tree2string(root->left) + tree2string(root->right);
}
vector getnext(string s)
{
vectornext(s.length());
next[0] = -1;
if (s.length()<2)
return s;
next[1] = 0;
int cn = 0;
int i = 2;
while(i<s.length())
{
if(s[i-1][cn])
next[i++] = ++cn;
else if (cn>0)
cn = next[cn];
else
next[i++] = -1;
}
return next;
}
int kmp(string s, string p)
{
if(s.length() < p.length() || s.length()==0 || p.length()==0)
return -1;
vectornext = getnext§;
int i = 0;
int j = 0;
while(i<s.length() && j<p.length())
{
if(s[i] == p[j])
{
i++;
j++;
}
else if (next[j]>0)
j = next[j];
else
i++:
}
return j == p.length() ? i-j : -1;
}
bool issubtree(TreeNode *root1, TreeNode *root2)
{
string s = tree2string(root1);
string p = tree2string(root2);
return kmp(s, p) != -1;
}
#### 19、Manacher算法及其扩展(添加新串使回文且最短)
##### 19.1 Manacher:找出字符串str最大的回文子串
首先解决奇回文和偶回文的问题。
我们在判断字符串是否回文时,是根据一个字符(奇回文)或空(偶回文)来判断的,这样需要分情况讨论,比较麻烦,所以最好统一一下。
添加辅助字符,(随便哪个字符都可以,不会影响原有字符匹配就可以),如“#”,在字符与字符之间、开头和结尾各添加“#”,这个“#”就相当于一个虚轴,虚轴只会和虚轴匹配。这样就可以统一奇回文和偶回文了。
传统方法是从str的每个字符开始,向两边扩,找到最大回文子串,复杂度为O(N^2)。
首先是将字符串转换为添加特殊字符后的新字符串。然后进行查找最大回文子串。
首先规定几个概念:
* 回文最右边界R
* 回文最右边界R的回文中心C
* 回文半径数组radius,记录每个字符以其为中心的回文半径。
* 最大回文半径与最大回文半径中心。
一共分为四种情况讨论。
1、当遍历到i时,如果字符i在最右边界R的右边,只能采用暴力匹配方式,向两边扩。
2、如果i在最右边界R的左边,则找到i关于R的对称点i’,如果i’的回文左边界在R的回文边界中,则i的回文边界也在R的回文边界中,不会再向外扩。
3、如果i’的回文左边界不在R的回文边界中,则i的回文右边界刚好与R重合,也不会扩。
4、如果i’的回文左边界刚好在R的回文左边界上,则i的回文半径至少到了R,至于R之后会不会扩,只能暴力匹配了。
那么在上述四种情况下,2、3的回文边界就不用暴力匹配了,直接去radiux[2C-i](即i’的回文半径)与R-i的小值就可以了。
string get_newstring(stirng s)
{
string ss = “#”;
for (int i=0;i<s.length();i++)
ss = ss + s[i] + “#”;
return ss;
}
string manacher(string s)
{
if(s.length()<2)
return “”;
string news = get_newstring(s);
vectorradius(news.length(), 0);
int C = -1;
int R = -1;
int rmax = INT_MIN;
int rc = 0;
for(int i=0; i<news.length(); i++)
{
radius[i] = 1;
radius[i] = R>i ? min(R-i, radius[2*C-i]) : radius[i];
while( i - radius[i] >= 0 && i + radius[i] < news.length())
{
if(news[i - radius[i]] == news[i + radius[i]])
radius[i]++;
else
break;
}
if(i+raidus[i]>R)
{
R = i + radius[i];
C = i;
}
if(radius[i]>rmax)
{
rmax = radius[i];
rc = i;
}
}
rmax–;
return s.substr((ic-imax)/2, imax);
}
##### 19.2 给定str1,在其后添加字符使得新字符串是回文字符串且最短
找到包含最后一个字符的最大回文子串,然后将这个回文子串之前的字符反向贴在str1的后面即可。
如“abc12321”,即将“abc”反向贴在后面即可,“abc12321cba”
string get_newstring(string s)
{
string news = “#”;
for(int i=0; i<s.length(); i++)
news = news + s[i] + “#”;
return news;
}
int manacher(string s)
{
string news = get_newstring(s);
vectorradius(news.length());
int C = -1;
int R = -1;
for(int i=0; i<news.length(); i++)
{
radius[i] = R>i ? min(R-i, radius[2*C-i]) : 1;
while(i - radius[i] >=0 && i + radius[i] < news.length())
{
if(news[i-radius[i]] == news[i+radius[i]])
radius[i]++;
}
if(i+radius[i]>R)
{
R = i+ radius[i];
C = i;
if (R == news.length())
return radius[i]-1;//包含最后一个字符的最大回文子串的长度
}
}
}
string getmaxstring(string s)
{
int r = manacher(s);
string ss = s;
for(int i= s.length()-r-1; i>=0; i–)
ss = ss + s[i];
return ss;
}
#### 20、BFPRT算法:求第K小/大的数
利用快排中的partition过程。如果求第K小,就是求排序后数组中下标为k-1的值。如果k-1属于partition后的等于区,则可直接返回等于区的数,如果,在大于区,则递归调用大于区,在小于区,则递归调用小于区。
到那时BFPRT又做了优化,即在选取partition的划分值时不再是随机选取,而是有策略的选取。
如何选呢?首先,将数组5个一组进行划分,不足5个自动一组。
然后分别组内排序(可用插入排序),求出每个组内的中位数,将这些中位数组成新的数组mediumarray。
然后递归调用这个BFPRT的函数,得到这个中位数数组的上中位数。这个值就是进行partition的划分值。
vector partition(vector&a, int l, int r, int value)
{
int less = l-1;
int more = r+1;
while(l<more)
{
if(a[l]<value)
a[++less]=a[l++};
else if (a[l]>value)
a[–more]=a[l];
else
l++;
}
vectorp;
p.push_back(less+1);
p.push_back(more-1);
}
void insert_sort(vector&a, int start, int end)
{
if(start==end)
return ;
for(int i=start+1;i<=end;i++)
{
for(int j=i-1;j>=start;j–)
{
if(a[j+1]<a[j])
swap(a[j+1],a[j]);
}
}
}
int getmedium(vector&a, int start, int end)
{
insert_sort(a, start, end);
return a[strat + (end-start)/2];
}
int get_medium_of_medium(vector&a, int start, int end)
{
int num = end-start+1;
int flag = num%5 == 0 ? 0 : 1;
vectormediums(num/5+flag);
for(int i=0; i< mediums.size(0; i++)
{
int istart = start + i*5;
int iend = istart + 4;
mediums[i] = getmedium(a, istart, min(iend, end));
}
return findk(mediums, 0, mediums.size()-1, (mediums.size()-1)/2);
}
int findk(vector&a, int start, int end, int k)
{
if(start==end)
return a[strat];
int pvalue = get_medium_of_medium(a, start, end);
vectorp = partition(a, start, end, pvalue);
if(k>=p[0] && k<=p[1])
return pvalue;
else if(k<p[0])
return findk(a, start, p[0]-1, k);
else
returun findk(a, p[1]+1, end, k);
}
int mink(vectora, int k)
{
if(k<1 || k>a.size())
return NULL;
return findk(a, 0, a.size()-1, k-1);
}
#### 21、基数排序
找到最大数的位数,并准备10个桶(0-9)。从个位数到高位数依次排序,按照其位上的数的大小依次入桶,顺序要保持一致,保持先进先出。
int maxbit(vectora)
{
int imax = INT_MIN;;
for(int i=0; i<a.size() && imax<a[i]; i++)
imax = a[i];
int digit = 0;
while(imax>0)
{
imax /= 10;
digit++;
}
return digit;
}
int getnum(int x, int digit)
{
return (x/(pow(10, digit-1))) % 10;
}
void radix(vector&a, int start, int end, int digit)
{
vectorhelp(end-start+1);
int num;
for(int d=1; d<=digit; d++)
{
vectorcount(10,0);
for(int i=0; i<a.size(); i++)
{
num = getnum(a[i], d);
count[num]++;
}
fot(int i=1; i<10; i++)
count[i] += count[i-1];
for(int i=end; i>=start; i–)
{
num = getnum(a[i], d);
help[count[num]-1] = a[i];
count[num]–;
}
for(int i=0; i<help.size(); i++)
a[start + i]=help[i];
}
}
void radix_sort(vectora)
{
if(a.size()<2)
return ;
radix(a, 0 ,a.size()-1, maxbits(a));
}
#### 22、希尔排序
设置步长,每次选一个步长来进行排序,做很多遍,最终落在步长为1的排序上。大步长调整完基本有序,则小步长不必调整过多。
插入排序就是步长为1的希尔排序。
12 3 1 9 4 8 2 6 (未排序)
选择步长为4
4 3 1 6 12 8 2 9
选择步长为2
1 3 2 6 4 8 12 9
选择步长为1
1 2 3 4 6 8 9 12
#### 23、实现特殊栈,O(1)实现getmin()
进栈、出栈、返回栈顶这些都与原来的栈的操作保持一致,主要是加了怎样在O(1)时间下得到栈内最小值。
两种方法,不过都要准备两个栈,一个数据栈data存放数据,一个help栈,存放最小值。
方法一:help栈存放最小值,每次data栈压栈时,help也压栈,不过help要保持最小的栈顶,即如果data新进的数如果比help栈顶小,则这个数可以压栈入help,否则将help栈顶的那个数再一次压入help栈中。
压栈的时候同步压,出栈同步出。
方法二:当压入data栈的数小于等于help栈顶时,可以向help压入,否则不压。当要弹出data栈的数时,如果这个数与help的栈顶值相等,则help也弹出,否则help不弹出。
则help的栈顶一直是当前栈内最小的数。
#### 24、用数组结构实现大小固定的队列和栈
##### 24.1 实现栈
维护一个size(初始为0),代表栈的大小,当push时,数直接放在a[size]上,size++,当pop时,直接取a[size-1]]的值,size–。
struct array_stack
{
vectorastack;
int size;
array_stack(int initsize)
{
if(initsize<0)
cout<<“请输入一个大于0的数,以保证栈不为空”<<endl;
astack=vector(initsize);
size = 0;
}
int top()
{
if(size0)
{
cout<<“the stack is empty”<<endl;
return NULL;
}
return a[size-1];
}
void push(int x)
{
if(sizeastack.size())
{
cout<<“the stack is full”<<endl;
return ;
}
astack[size++] = x;
}
int pop()
{
if(size==0)
{
cout<<“the stack is empty”<<endl;
return NULL;
}
return astack[–size];
}
};
##### 24.2 实现队列
维护start、end、size三个指针,size表示队列的大小(约束start与end的关系)。当push时,end++,pop时,start++,用start去追end,谁先触底,则回到开始位置。
struct array_queue
{
vectoraqueue;
int size;
int start;
int end;
aqueue(int initsize)
{
if(initsize<0)
cout<<“请输入一个大于0的数,以保证队列不为空”<<endl;
aqueue = vector(initsize);
size = 0;
start = 0;
end = 0;
}
int top()
{
if(size == 0)
return null;
return aqueue[start];
}
void push(int x)
{
if(size == aqueue.size())
{
cout<<“the queue is full”<<endl;
return ;
}
aqueue[end] = x;
size ++;
end = end==aqueu.size()-1?0:end+1;
}
int pop()
{
if(size == 0)
{
cout<<“the queue is empty”<<endl;
return NULL;
}
size–;
int temp = start;
start = start == aqueue.size()-1?0:start+1;
return aqueue[temp];
}
}
#### 25、用栈实现队列、用队列实现栈
##### 25.1 用栈实现队列
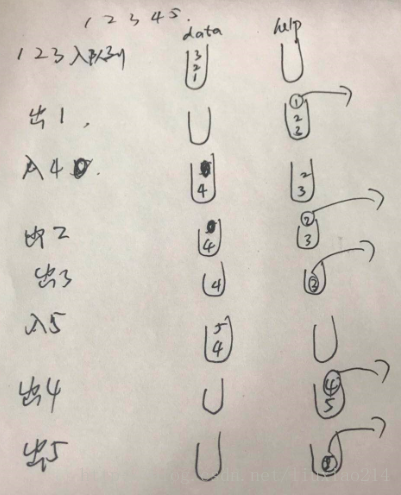
准备两个栈,一个数据栈data,一个辅助栈help,数据栈负责入队列,如果需要出队列,就把数据栈中的当前所有数据倒入辅助栈help中。然后从help中出队列。
注意两点:如果help栈不为空,data栈不要向help栈倒数据;data栈倒数据时,一次要全倒完。
struct stack2queue
{
stackdata;
stackhelp;
stack2queue()
{
data = new stack();
help = new stack();
}
int top()
{
if(data.empty() && help.empty())
{
cout<<“the queue is empty”<<endl;
return NULL;
}
else if(help.empty())
{
while(!data.empty())
help.push(data.pop());
}
return help.top();
}
void push(int x)
{
data.push(x);
}
int pop()
{
if(data.empty() && help.empty())
{
cout<<“the queue is empty”<<endl;
return NULL;
}
else if(help.empty())
{
while(!data.empty())
help.push(data.pop());
}
return help.pop();
}
};
##### 25.2 用队列实现栈
准备两个队列A和B,两个队列互相配合,称为数据队列和缓存队列。当进栈时,向数据队列中入,当出栈时,将目前的那个数据栈除最后一个元素外全部出队列,并进入到缓存队列,此时数据队列只剩那个要出栈的元素,可出。
此数据队列变为空,为缓存队列,缓存队列为数据队列。
struct queue2stack
{
queuedata;
queuehelp;
queue2stack()
{
data = new queue();
help = new queue();
}
int top()
{
if(data.empty())
{
cout<<“the stack is empty”<<endl;
return NULL;
}
while(data.size()!=1)
help.push(data.pop());
int temp = data.pop();
help.push(temp);
swap();
return temp;
}
void push(int x)
{
data.push(x);
}
int pop()
{
if(data.empty())
{
cout<<“the stack is empty”<<endl;
return NULL;
}
while(data.size()!=1)
help.push(data.pop());
int temp = data.pop();
swap();
return temp;
}
void swap()
{
queuetemp = data;
data = help;
help = data;
}
};
#### 26、猫狗队列
有三个类,宠物类、猫类、狗类。
实现一种猫狗队列结构,要求:
1、用户可以调用add方法将cat类或dog类的实例放入队列中。
2、pollall函数:按照先进先出原则,依次弹出所有实例。
3、polldag函数:先进先出弹出dog实例。
4、pollcat函数:先进先出弹出cat实例。
5、isempty函数:检查队列中是否还有实例。
6、isdogempty函数:检查队列中是否还有dog结构。
7、iscatempty函数:检查队列中是否还有cat结构。
方法:维护一个index,用来记录每个类是第几个进入队列的,在poll哪个类的index小,就先poll谁。
### 四、第四次课(2017.11.19)
#### 27、哈希表和哈希函数
哈希函数:
* 输入域是无穷大的,输出域是有限的。
* 当输入参数一旦确定,参数固定,则返回值是相同的,不同的输入可能对应同一个输出。
* 所有的输入值均匀地对应到输出上。
一致性哈希、缓存结构、负责均衡。
已有3台机器,但现在要添加1台,进行数据迁移,则取模的信息变了,如何解决?
引入一致性哈希,既能负载均衡,又能自由删减机器。
这个后面再去看,暂且放着
另:
1、如何构造散列函数:
* 直接定址法:h(key)=a\*key+b,取线性函数值作为散列地址。
* 除留余数法:散列表表长为m,取不大于m但最接近m的质数p,h(key)=key%p。
* 数字分析法:设关键字是r进制数,选取数码均匀的若干位作为散列地址。
* 平方取中法:取关键字平方值的中间几位作为散列地址。
* 折叠法:将关键字分割成位数相同的几部分,取这几部分的重叠和作为散列地址。
2、处理冲突的问题
* 开放定址法:线性探测法、平方探测法、再散列法、伪随机序列法
* 拉链法:将所有同义词存储在一个线性链表中,由散列地址唯一标识。
* 散列查找法:取决于散列函数,处理冲突的方法和装填因子。
#### 28、设计RandomPool结构
设计一种结构,在该结构中有如下三种功能:
* insert(key):将某个key加入到该结构中,做到不重复加入。
* delete(key):将原本在结构中的某个key移除。
* getRandom(key):等概率随机返回结构中的任何一个key。
准备两张hash表。用size记录是第几个进来的。进则size++,删则size–。
如果要删除某个记录,将最后一行记录放入改记录中,删除最后一行记录,size–。
在等概论返回时,即可只返回当前size大小内的随机值所对应的key。rand()(size)。
#### 29、转圈打印矩阵、转90度打印矩阵
##### 29.1 转圈打印矩阵
要求额外空间复杂度为O(1)。
从左上角开始,列++,加到边后,行++,到边后,列- -,到边后,行- -。
重复上面四个过程。注意边界条件。
void print_one(vector<vector>a, int tr, int tc, int dr, int tc)
{
if(tcdc)
{
for(int i=tr;i<=dr;i++)
cout<<a[i][tc]<<endl;
}
else if(trdr)
{
for(int i=tc;i<=dc;i++)
cout<<a[tr][i]<<endl;
}
else
{
int curr=tr;
int curc=tc;
while(curc < dc)
cout<<a[tr][curc++]<<" “;
while(curr < dr)
cout<<a[curr++][dc]<<” “;
while(curc>tc)
cout<<a[dr][curc–]<<” “;
while(curr>tr)
cout<<a[curr–][tc]<<” ";
}
}
void printmatrix(vetcor<vetcor>a)
{
int tr = 0;
int tc = 0;
int dr = a.size() - 1;
int dc = a[0].size() - 1;
while(tr<=dr && tc<=dc)
print_one(a, tr++, tc++, dr–, dc–);
}
##### 29.2 转90度打印矩阵
类似于转圈打印,原地调整。
主要内容的伪代码为:
int temp = a[tr][tc+i] //temp = 列+i
a[tr][tc+i] = a[tr+i][dc] //列+i=行+i
a[tr+i][dc] = a[dr][dc-i] //行+i = 列-i
a[dr][dc-i] = a[dr-i][tc] //列-i = 行 - i
a[dr-i][tc] = temp //行-i = temp
#### 30、之字型打印矩阵
一直找对角线,从左上角开始。
准备两个点a,b,作为记录对角线的两个端点位置。
a点从左上角开始,向右走,走到矩阵边界后就向下走。
b点从左上角开始,向下走,走到矩阵边界后就向右走。
每次a,b都各走一步,然后打印以a,b为端点的对角线上的元素。每次用一个bool值记录打印的方向,用来标记方向交替。
#### 31、在行列有序的矩阵中找数
时间复杂度为O(M+N)。
从右上角开始,如果要查找得数x比右上角这个数大,则继续向下找,否则就向左找。
直到走到边界,可判断这个数是否在矩阵中。
bool if_find(vecotr<vector>a, int x)
{
int i=0;
int j=a[0].size()-1;
while(i<a.size() && j>=0)
{
if(a[i][j] == x)
return true;
else if(a[i][j] > x)
j–;
else
i++;
}
return false;
}
#### 32、打印两个有序链表的公共部分
#### 33、判断一个链表是否是回文结构
#### 34、将单向链表按照某值划分为左边小、中间相等、右边大结构,且内部保持原有顺序
#### 35、复制含有随机指针节点的链表
#### 36、两个单链表相交的一系列问题
#### 37、反转单向、双向链表
### 五、第五次课(2017.11.25)
#### 38、随时找到数据流的中位数
#### 39、金条切块
#### 40、求收益问题
#### 41、折纸问题
#### 42、二叉树的前序、中序、后序遍历的递归与非递归实现
##### 42.1 前序
递归写法:
void preOrder(TreeNode *root)
{
if(root==NULL)
return ;
cout<val<<" ";
preOrder(root->left);
preOrder(root->right);
}
非递归:
利用栈,将头节点放入栈中,弹出并打印。然后将右节点和左节点依次入栈。重复弹出栈顶并打印,右、左依次入栈的过程。
void oreOrder(TreeNode *root)
{
if(root==NULL)
return ;
stack<TreeNode*>s;
s.push(root);
TreeNode *p = root;
while(!s.empty())
{
p = s.pop();
cout<val<<" ";
if(p->right!=NULL)
s.push(p->right);
if(p->left!=NULL)
s.push(p->left);
}
}
##### 42.2 中序
递归:
void inOrder(TreeNode *root)
{
if(root==NULL)
return ;
inOrder(root->left);
cout<val<<" ";
inOrder(root->right);
}
非递归:
利用栈,如果头节点不为空,则入栈,头节点等于其左孩子。一直到头节点为空,则弹出栈顶,并且将栈顶右孩子入栈。
void inOrder(TreeNode *root)
{
if(root==NULL)
return ;
stack<TreeNode *>s;
s.push(root);
TreeNode *p=root;
while(!s.empty() || p!=NULL)
{
if(p!=NULL)
{
p = p->left;
s.push§;
}
else
{
p = s.pop();
cout<val<<" ";
p = p->right;
}
}
}
##### 42.3 后序
递归:
void postOrder(TreeNode *root)
{
if(root==NULL)
return ;
postOrder(root->left);
postOrder(root->right);
cout<val<<" ";
}
非递归:
利用栈和前序的非递归遍历,前序是头节点入栈,弹出并打印,右左节点依次入栈,重复弹出栈顶打印。
这样得到的是中左右,我们可以得到中右左,就是按照前序非递归方法,头节点入栈,弹出并打印,左右节点依次入栈,重复弹出栈顶打印。
这样得到中右左后,逆序后就是左右中,即后序遍历。
需要准备两个栈。
void postOrder(TreeNode *root)
{
if(root==NULL)
return ;
stcak<TreeNode *>help;
stcak<TreeNode *>s;
help.push(root);
TreeNode *p=root;
while(!help.empty())
{
p = help.pop();
s.push§;
if(p->left)
help.push(p->left);
if(p->right)
help.push(p->right);
}
while(!s.empty())
{
p = s.pop()
cout<val<<" ";
}
}
#### 43、较为直观的打印二叉树
先从最右边开始打印。
#### 44、在二叉树中找到一个节点的后继节点
后继节点:对二叉树进行中序遍历后,一个节点的后一个节点就是后继节点。即树的最右边的那个节点(中序遍历最后一个节点)是没有后继节点的。
建立一个新型二叉树,有val、左节点、右节点、父节点。
对于节点s,
如果有右子树,则后继节点为右子树上最左的节点。
如果没有右子树,但是是父亲的左孩子,则父亲节点就是后继节点;如果是父亲的右孩子,则继续向上找。
TreeNode *getleftnode(NodeTree *root)
{
if (rootNULL)
return NULL;
while(root->left!=NULL)
root = root->left;
return root;
}
TreeNode *getnode(NodeTree *root)
{
if(rootNULL)
return NULL;
if(root->right!=NULL)
return getleft(root->right;)
else
{
TreeNode *parent = root.parent;
while(parent != NULL && parent->left != NULL)
parent = parent->parent;
return parent;
}
}
#### 45、并查集
#### 46、布隆过滤器
### 六、第六次课(2017.11.26)
#### 47、二分搜索
#### 48、前缀树及其六个应用
前缀树是字典树,没有左右孩子之分,是多叉树。
例如,将abc、bcd、abd、bck生成共同前缀树,则为:
o
a/ \b
o o
b/ \c
o o
c/ \d d/ \k
o o o o
从空节点开始,用边来表示字符,有这个边的话,就共用,没有就加边。
##### 48.1 找B数组中哪些串是A数组中串的前缀
##### 48.2 查找某个字符串是否在数组中
**自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。**
**深知大多数网络安全工程师,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。**






**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上网络安全知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注网络安全获取)**

### 给大家的福利
**零基础入门**
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
网络安全面试题
绿盟护网行动
还有大家最喜欢的黑客技术
**网络安全源码合集+工具包**

**所有资料共282G**,朋友们如果有需要全套《网络安全入门+黑客进阶学习资源包》,可以扫描下方二维码领取(如遇扫码问题,可以在评论区留言领取哦)~
**一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**

)]
[外链图片转存中...(img-LBnwpuPp-1713041522449)]
[外链图片转存中...(img-omBgEIHO-1713041522449)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上网络安全知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注网络安全获取)**
[外链图片转存中...(img-YP3EHgx0-1713041522450)]
### 给大家的福利
**零基础入门**
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
网络安全面试题

绿盟护网行动

还有大家最喜欢的黑客技术

**网络安全源码合集+工具包**


**所有资料共282G**,朋友们如果有需要全套《网络安全入门+黑客进阶学习资源包》,可以扫描下方二维码领取(如遇扫码问题,可以在评论区留言领取哦)~
**一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
[外链图片转存中...(img-4TP5kyfi-1713041522450)]















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









