






filebeat轻量级日志采集器
ansibe剧本:实现es的批量部署
ELK集群

kibana安装filebeat
上传filebeat
解压,改名
vi filebeat.yml
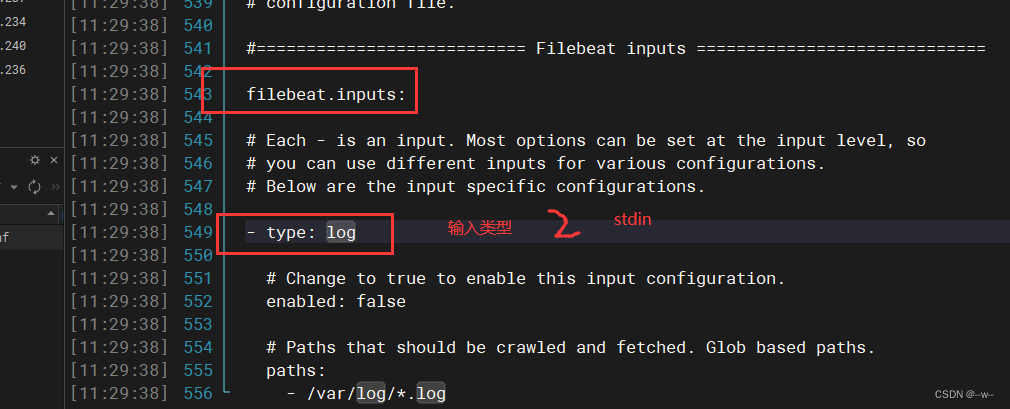
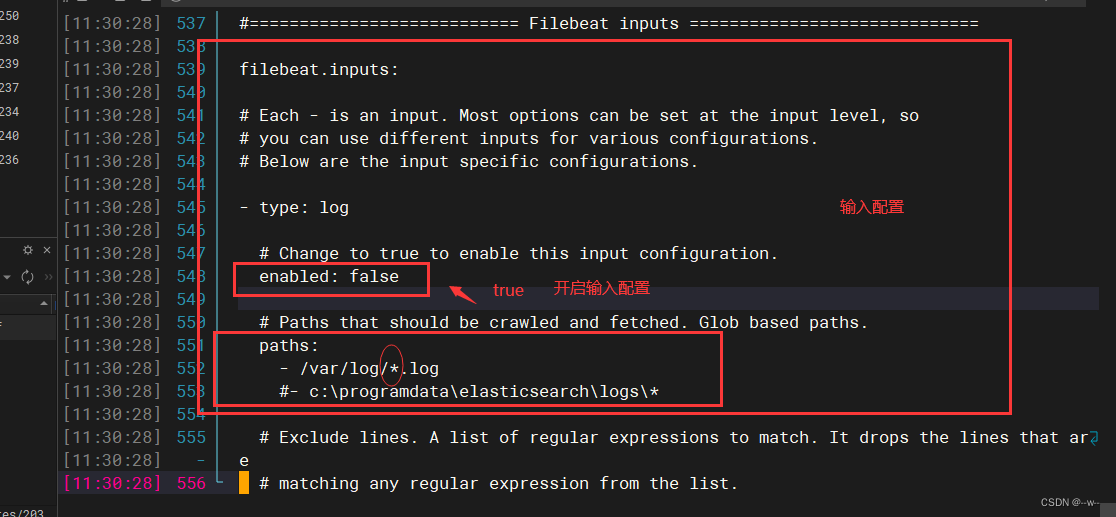
修改配置
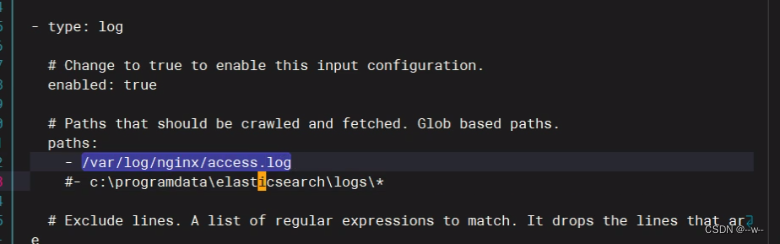
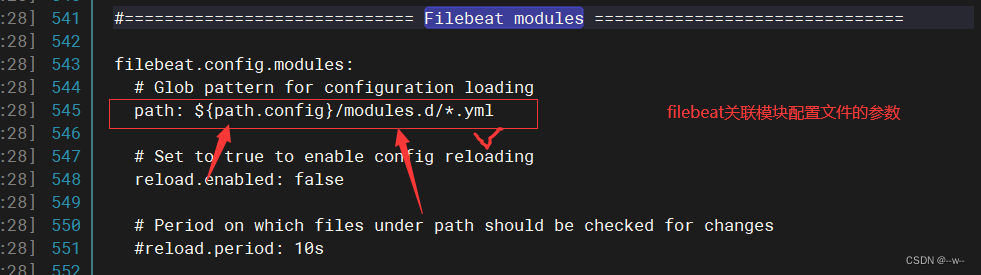
修改


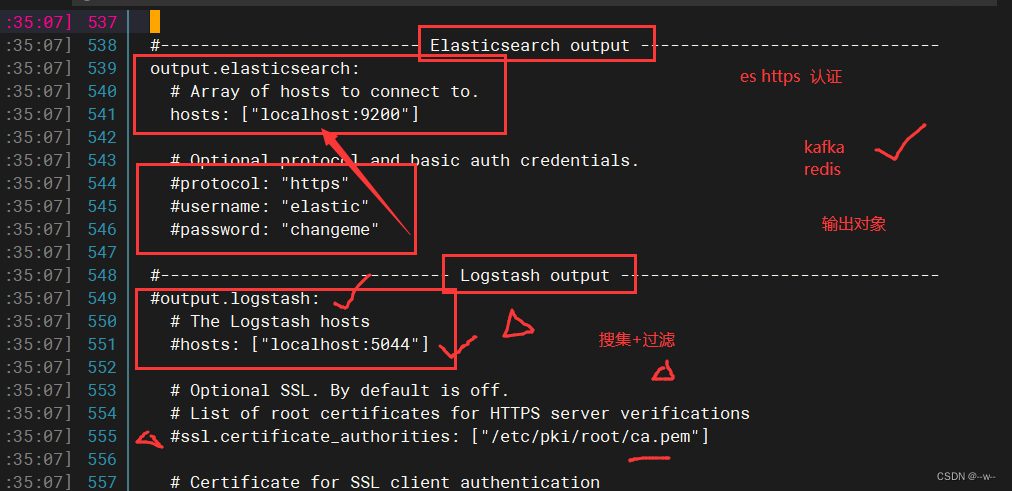
添加

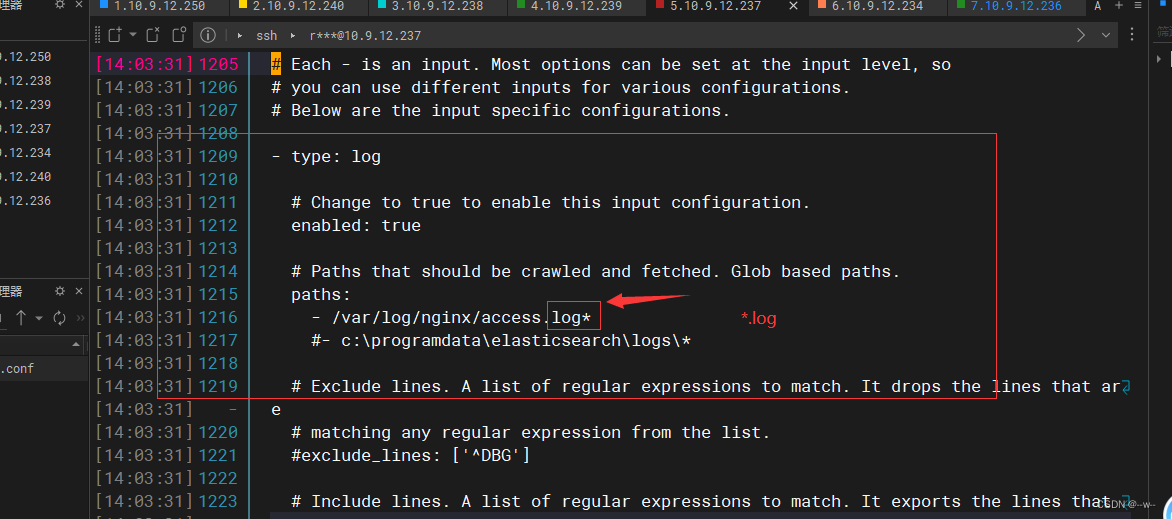
注意:不加*会出不来但不报错
运行

案例:搜集nginx的日志:metricbeat(要搜集哪台服务器的日志就安装在哪,这台有nginx)
kibana服务器
上传meticbeat
参考官方文档
vi /etc/metricbeat/metricbeat.yml
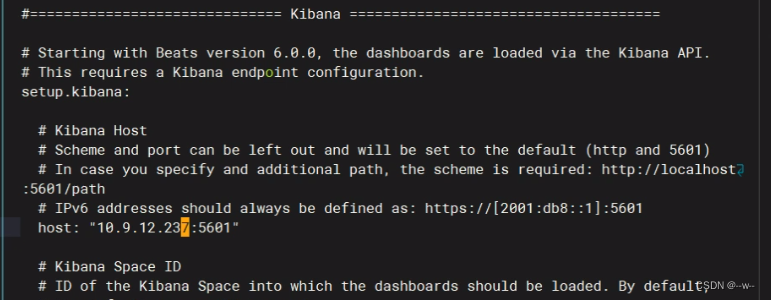
ls /etc/metricbeat/modules.d
参考官方文档的下一步
vi /etc/metricbeat/modules.d/nginx.yml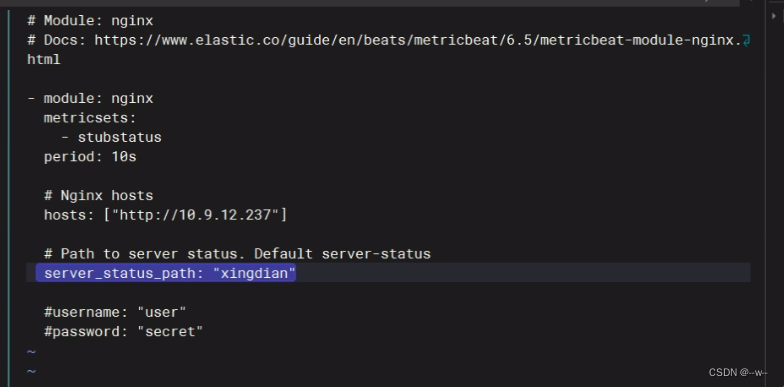
vi /etc/nginx/nginx.conf
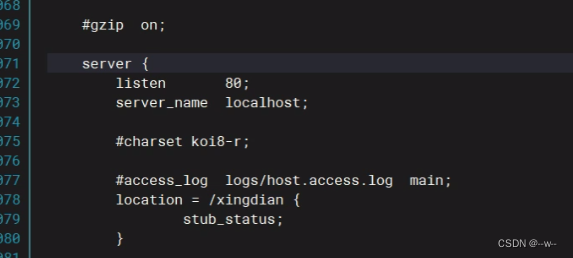
nginx -t
nginx -s reload
官方文档的下一步
浏览器访问:kibana的ip地址:xingdian
根据官方文档启动metricbeat
cd /var/log/metricbeat
cat metricbeat
Kafka
Kafka的特性:
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consumer操作。
- 可扩展性:kafka集群支持热扩展
- 可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
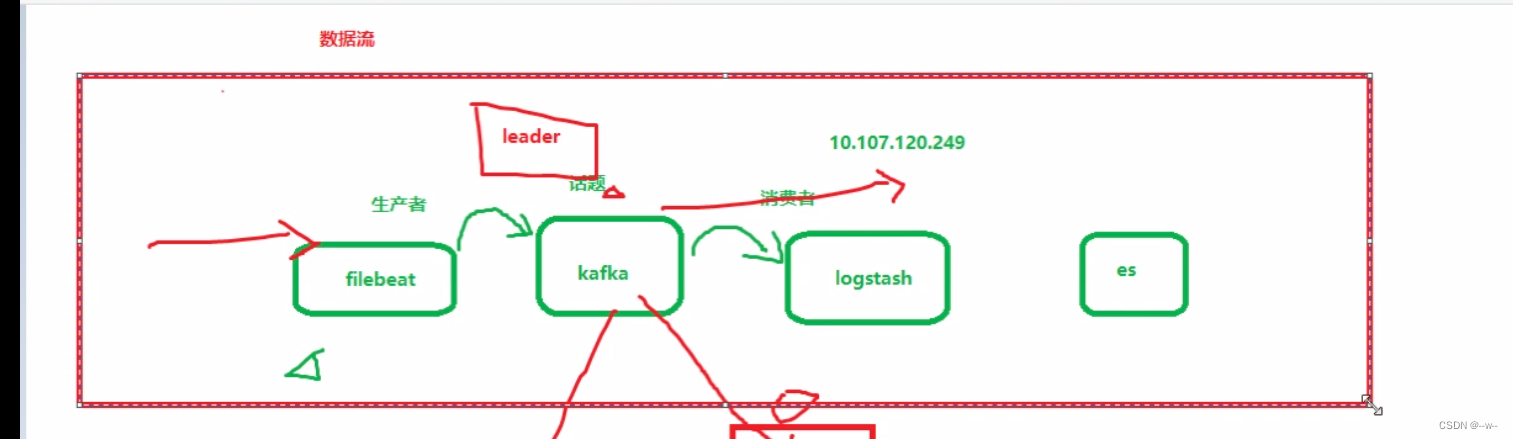
Kafka部署
本地解析
scp .... kafaka-2:/etc/hosts
kafka-1,kafka-2,kafka-3
三台kafka节点:
安装jdk
解压
vi /etc/profile
source /etc/profile
java -version
上传kafka安装包
安装kafka(解压即安装)

将配置文件中的内容都添加为注释

修改配置文件
vi /usr/local/kafka/config/zookeeper.properties
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
server.1=kafka-1:2888:3888 //kafka集群IP:Port
server.2=kafka-2:2888:3888
创建data、log目录
mkdir -p /opt/data/zookeeper/{data,logs}
创建myid文件
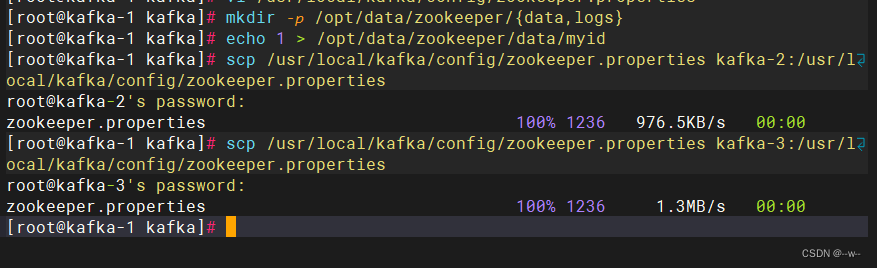

4.配置kafka
vi /usr/local/kafka/config/server.properties
broker.id=1
listeners=PLAINTEXT://kafka-1:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/data/kafka/logs
num.partitions=6
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=300000
zookeeper.connect=kafka-1:2181,kafka-2:2181 //改
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
创建log目录

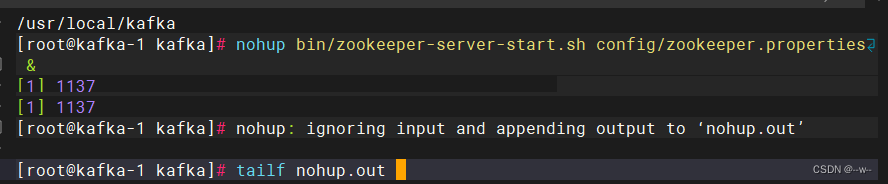
先运行zookeeper(两个节点都运行)
cd /usr/local/kafka
安装nc命令
yum provides nc
yum -y install
验证:
echo conf | nc 127.0.0.1 2181
echo stat | nc 127.0.0.1 2181 //返回zookeeper的相关信息
启动kafka(两个节点都启动)

ss -antpl : 可以看到端口9092和2181
以上是已经创建好的集群框架
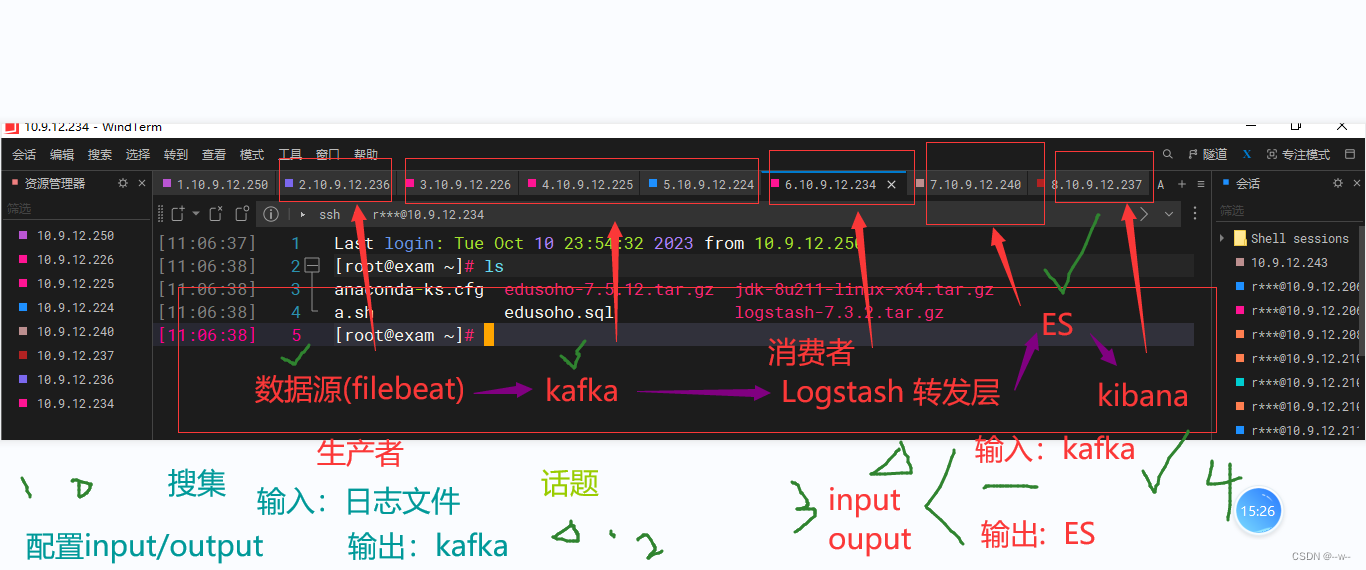
验证kafka:
创建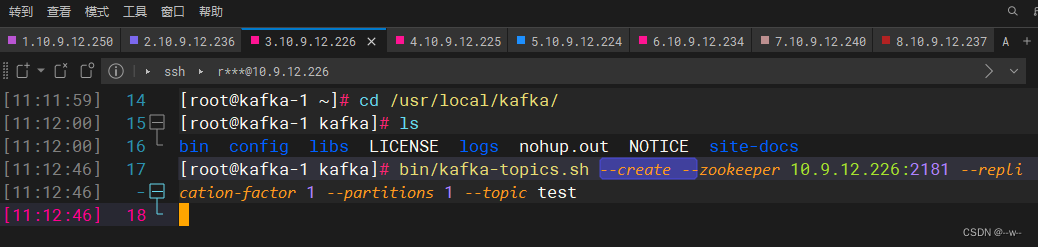
在kafka第3个节点(任何一个终端)查看
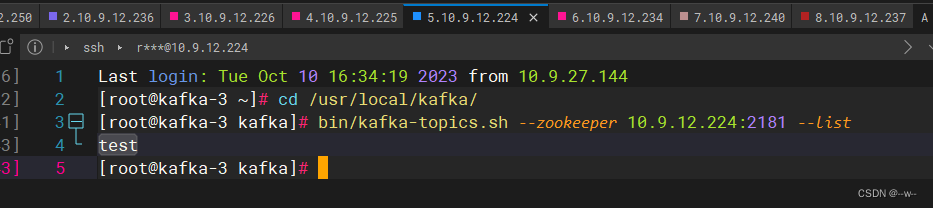
节点1模拟生产者产生数据:给话题test写入数据

生产者产生数据
输入hello
节点3消费者获取数据

filebeat部署
cd /etc/filebeat
配置

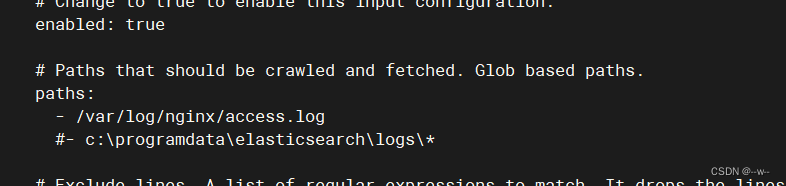
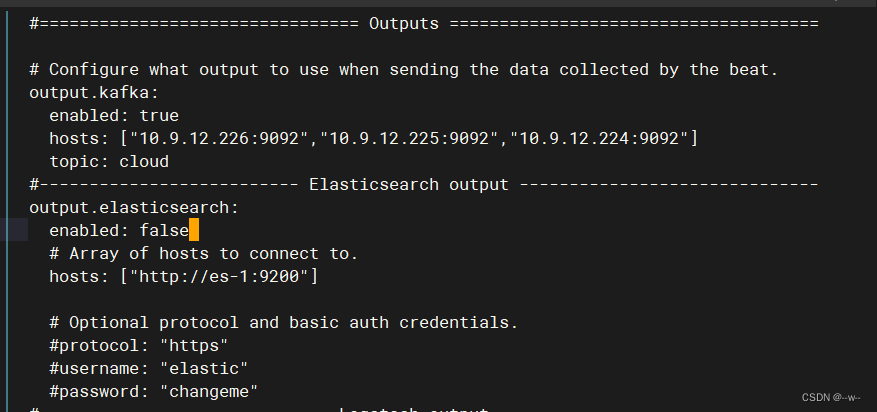
关掉nginx模块

kafka端:创建话题

排错:查看已有话题

logstash端:创建输入输出
vi /opt/kafak.conf
排错:删掉consumer消费者线程数、类型、auto
es-1改为ip地址
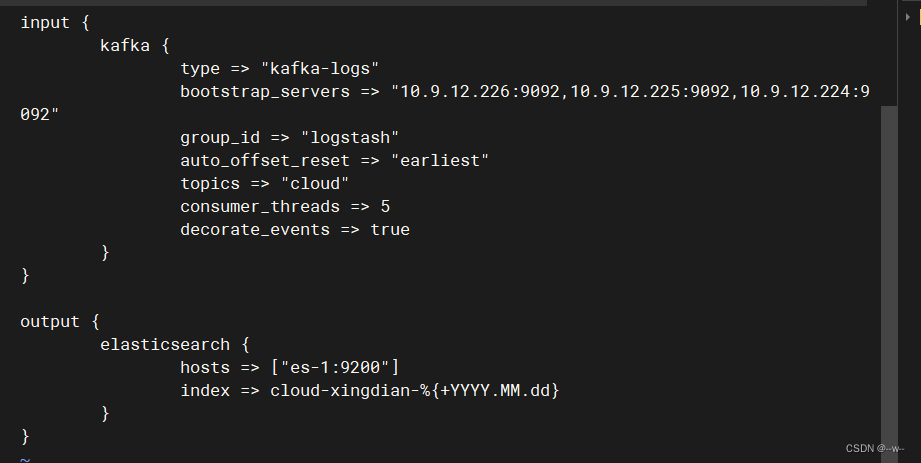
![]()
排错:pkill -9 杀掉正在运行的
先启动logstash,再启动filebeat

排错:更换logstash版本
在filebeat上加上kafka本地解析 
清理环境:cd /usr/local/logstash/data
ll -a
rm -rf .lock

然后,运行filebeat

执行filebeat.yml文件
./filebeat -c filebeat.yml
刷新elasticsearch插件出现cloud-xingdain的索引就成功运行,并传入数据成功
kibana的web界面,创建索引cloud-xingdain
为什么用filebeat作为搜集日志,而不选logstash?
logstash占用大量资源,而filebeat是轻量级
logstash数据过滤----grok插件
官网:elasti.co----->文档
案例:
停掉logstash和filebeat
filebeat端:
 kafka端:创建话题
kafka端:创建话题

回到filebeat
vi filebeat.yml
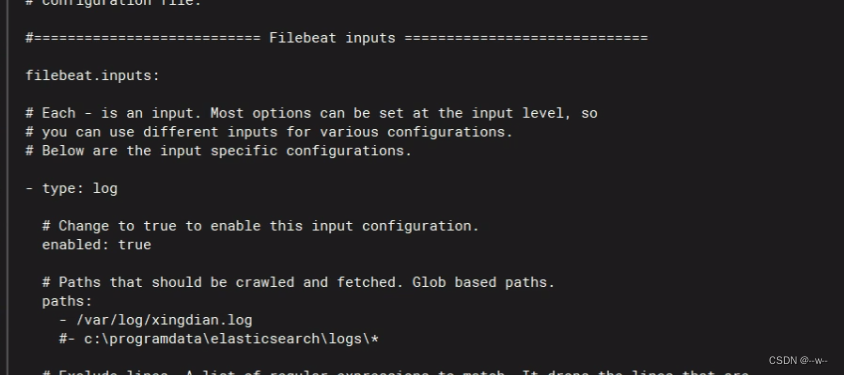
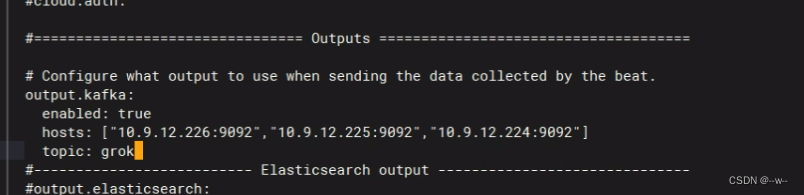

vi /opt/grok.conf
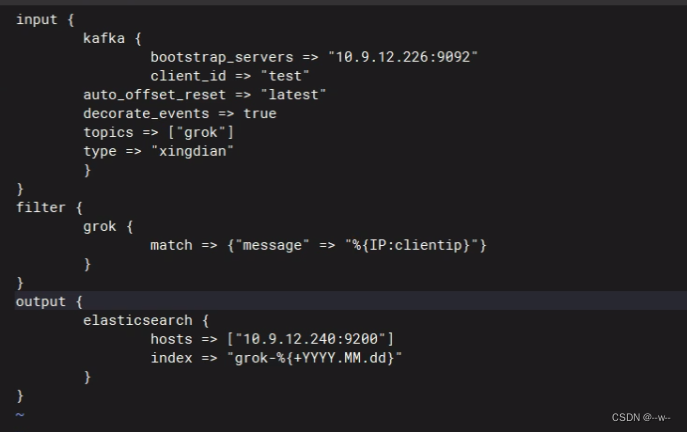
运行logstash:

filebeat端:
启动filebeat
模拟数据

el插件中刷新,出现grok的索引
查看日志:
![]()
模拟数据
 kibana的web界面,创建索引grok
kibana的web界面,创建索引grok
查看10.9.12.222的访问量
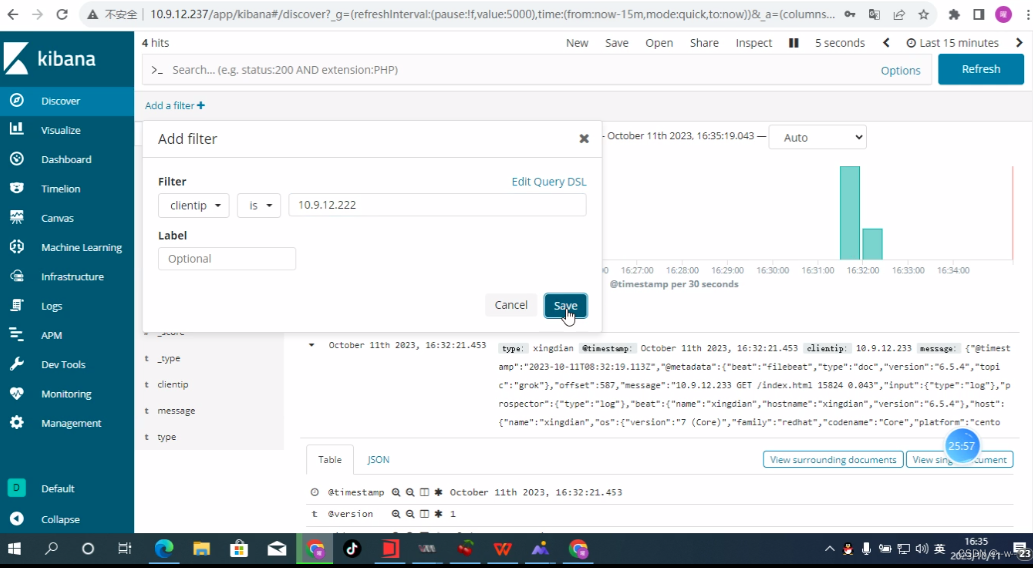
















 197
197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









