






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。当哲学课上老师问你什么是科学,什么是电的时候,不要觉得这些问题搞笑。哲学是科学之母,哲学就是追究终极问题,寻找那些不言自明只有小孩子会问的但是你却回答不出来的问题。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能让人胸中升起一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它居然给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
摘要:
顺序可能性一维聚类与动态 η 是 Fuzzy C-Means(FCM)的延伸,它放弃了成员资格之和为一的约束。在该方法中,每个聚类都是独立的,可以独立处理。因此,提出了顺序可能性一维聚类(SP1M),通过运行 P1M C 次来按顺序找到聚类。PCM 和 SP1M 中一个关键问题是如何确定参数 η。为了允许 η 在迭代过程中发生变化,开发了带自适应 η 的顺序可能性一维聚类(SP1M-AE)。本文介绍了一种新的动态调整机制,用于每个聚类中参数 η,并将其应用到 SP1M 中。结果算法称为具有动态 η 的顺序可能性一维聚类(SP1M-DE),在确定正确聚类结果方面表现优越于 PCM、SP1M 和 SP1M-AE。
FCM [1] 和 PCM [2] 是数据集中查找聚类的两种基于模糊集的最广泛使用的方法。FCM 通常效果良好,但已知对异常值和噪声敏感 [4]。PCM 被报道对异常值和噪声更稳健,但可能会产生重合的聚类 [5],[6]。PCM 聚类可以独立找到,因此 PCM 可以使用 c 个独立的 Possibilistic One-Means(P1M)[3] 实例来实现。然后基于 P1M 提出了 SP1M 通过使用聚类排斥来解决重合的聚类中心问题。但是在 SP1M 中的参数 η 是手动选择的,有时很难估计。提出了抗干扰和噪声的噪声聚类 [8],[9],它有一个参数 δ2,具有类似参数 K 的效果,但在具有许多聚类的数据集中对单个聚类的 δ2 估计也比较粗糙。随后提出了具有自适应 η 的 SP1M(SP1M-AE)[10] 通过在每次迭代中使用分区矩阵的 alpha 切割来解决 η 选择问题。但 SP1M-AE 引入了另一个参数,α- 切割水平- 这也需要由人指定,并因不同数据集而异。在本文中,我们为每个聚类引入了一种新的动态参数 η 的调整机制。在本方法中,我们还对加快 SP1M 算法的速度进行了一些改进,使其对用户输入更具稳健性。
📚2 运行结果
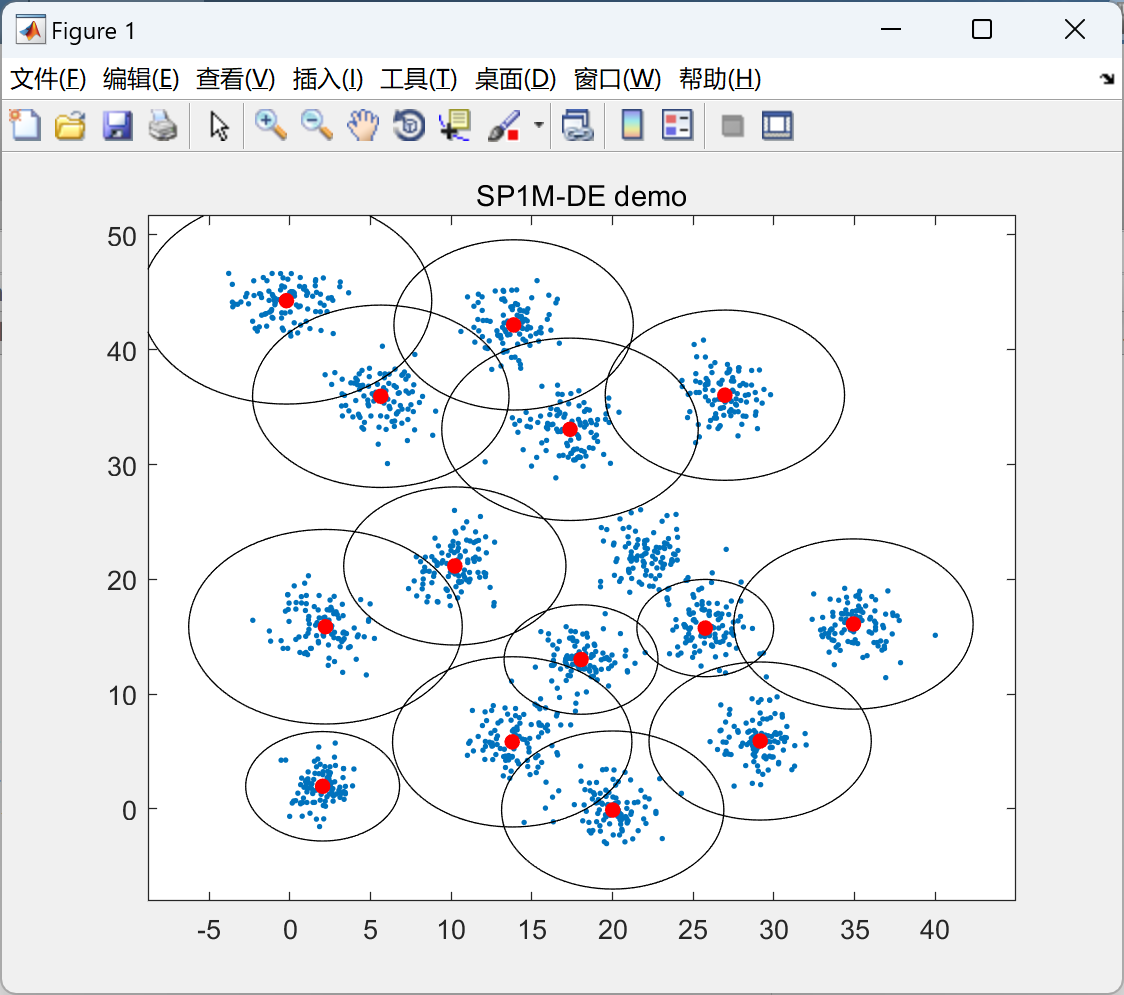
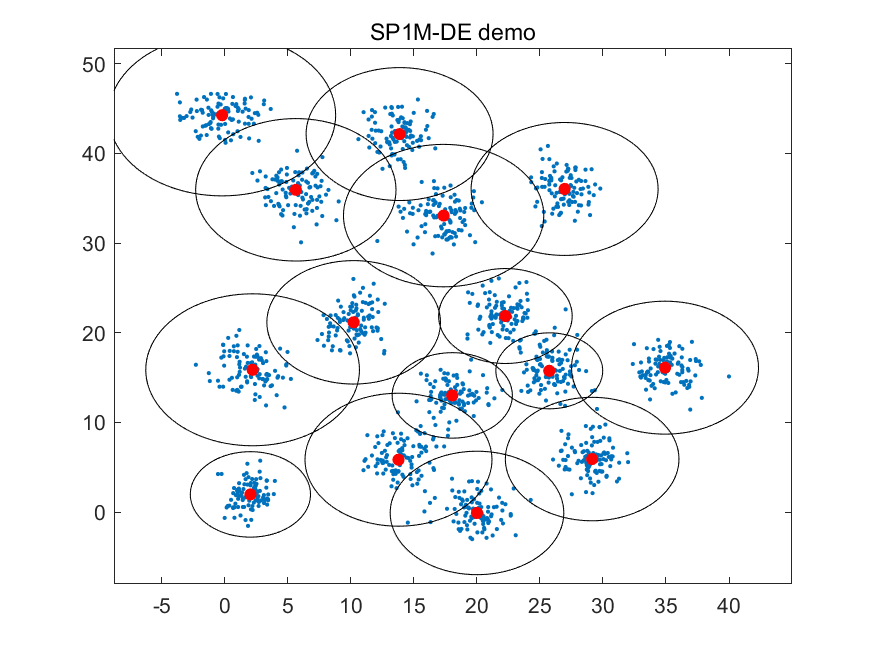
部分代码:
function [ Uall, Vall] = sp1m( data )
% Sequential Possibilistic One-Means Clustering with Dynamic Eta (SP1M-DE)
%% some hyper-parameters
[N,d]=size(data); % data number and dimension
C=100; % numbers of clusters, could be infinite, take some time to stop
fzr=1.5; % fuzzifier
epsilon=0.01; % epsilon threshold
Uall=[]; % membership matrix
Vall=[]; % cluster center
%%
% This part is only for 2 dimension
r1=max(data(:,1))-min(data(:,1));
r2=max(data(:,2))-min(data(:,2));
eta_max=sqrt(r1^2+r2^2); % the max radius of the data range
steps=100; % the number of eta steps
eta_base=eta_max/steps;
eta=zeros(1,C)*inf; % initial the eta
U_count=zeros(1,C);
stop_count=0;
stop_code=0;
seed=2018; % random seed number
%%
% the main loop
for iter=1:C
%-------------------------loop 2---------------------------------------
while(1)
% propabilities to choose cluster center
seed=seed+1;
selected_v = random_select(data, iter, Uall, seed);
v(iter, :) = selected_v;
%---------------------------loop 1 < P1M >------------------
while(1)
% compute d
for m=1:N
d(iter,m)=pdist2(data(m,:),v(iter,:))^2;
end
% dynamic eta processing
eta_tmp=zeros(1,steps);
u_avg=zeros(1,steps); % define the average membership
u_avg_sum=zeros(1,steps);
u_avg_count=zeros(1,steps);
u_avg_diff=zeros(1,steps-1);
found=true;
% dynamic eta loop
for eta_step=1:steps
eta_tmp(eta_step)=eta_base*eta_step; % the current eta value
% % Uncomment this part if you want to see the middle process
% figure(1); r=sqrt(eta_tmp(eta_step));
% increasingCircle=rectangle('Position',[v(iter,1)-r,v(iter,2)-r,2*r,2*r],'Curvature', [1 1]);
% movingClusterCenter=plot(v(iter,1),v(iter,2),'or','MarkerSize',5);drawnow;
% delete(increasingCircle);
% compute u(v,X)
for m=1:N
u(iter,m)=1/(1+(d(iter,m)/eta_tmp(eta_step))^(1/(fzr-1)));
end
% calculate the membership in the circle
for m=1:N
if u(iter,m)>0 % this could be alpha cut (adaptive eta)
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









