









1、简介
1.1、是什么
如今的搜索引擎都无法提供合适的工具,能够提供真实、明确且客观的答案,而无需用户为了完成特定的研究任务而不断点击和浏览多个网站。
GPT Researcher是一个自主代理,旨在对各种任务进行全面的在线研究。该代理可以生成详细、真实、且客观的研究报告,并提供自定义选项,以便用户专注于相关资源、提纲和经验教训。受"Plan-and-Solve"和"RAG"论文的启发,GPT Researcher解决了速度、确定性和可靠性问题,通过并行代理工作(而非同步操作)提供更稳定的性能和更高的速度。
官网: GPT Researcher - Official Page
官方文档: Documentation | GPT Researcher
1.2、核心功能
- 生成详细的研究报告:能够生成超过2000字的详细研究报告,涵盖研究大纲,资源和学习内容。
- 多源信息聚合:每次研究任务可整合超过20个网络来源,从而形成客观、事实性的结论。
- 多格式报告导出:支持将研究报告导出为PDF、Word等多种格式,便于分享和存档。
- JavaScript支持的网页抓取:支持动态网页抓取,确保获取的信息更加全面和准确。
- 上下文记忆与管理:在研究过程中,能够保持对已访问和使用过的资源的上下文跟踪。
- 本地文档研究:除了在线资源,还支持对本地文档(如PDF、Word、Excel等)的研究。
2、项目架构
目前,gpt-researcher在github上有21.3kstar,拥有超过150位贡献者,目前仍然在不断更新维护中。gpt-researcher的项目架构一开始是单智能体researcher,后来将researcher作为其中一个节点演变成了多智能体系统。
2.1、单智能体架构
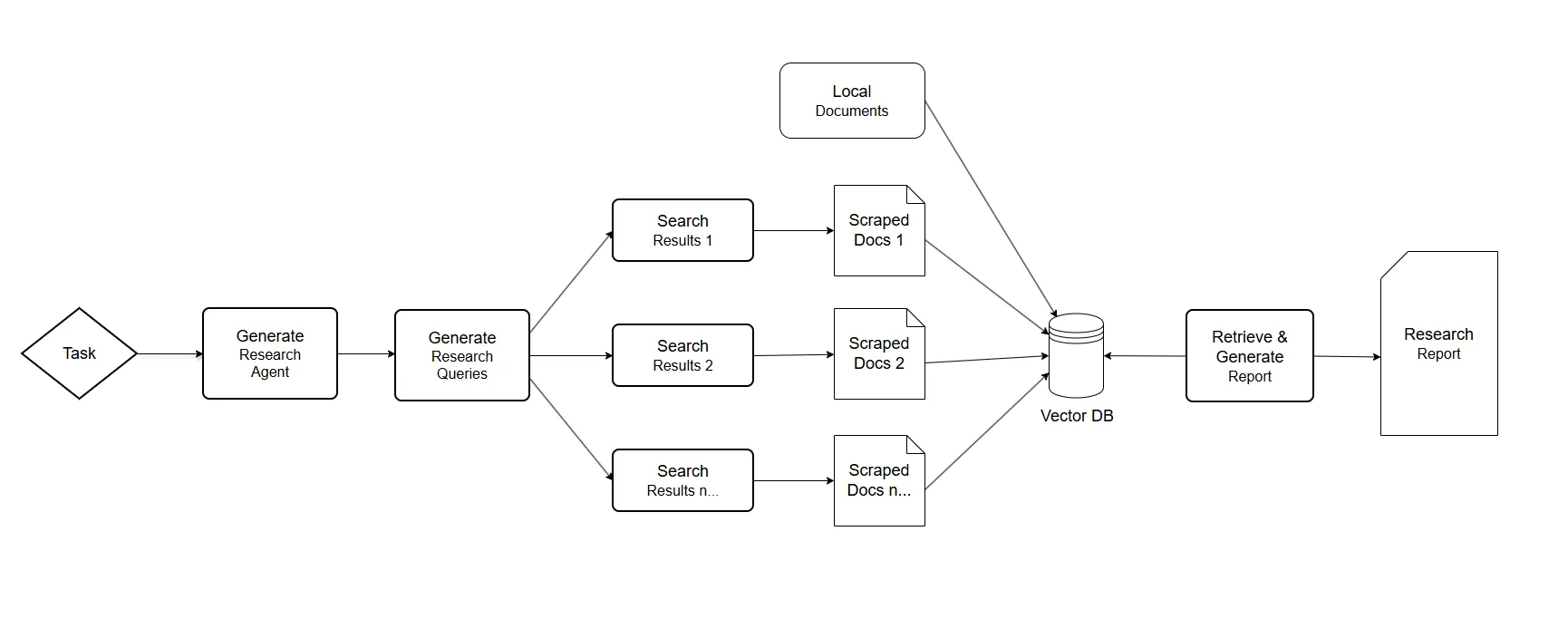
详细说明:
- 根据研究搜索或任务创建特定领域的代理。
- 生成一组研究问题,这些问题共同形成了对任何给定任务的调查意见的答案。
- 针对每个研究问题,触发一个爬虫代理,从在线资源中搜索与给定任务相关的信息。
- 针对每一个抓取的资源,根据相关信息进行汇总,并跟踪其来源。
- 最后,对所有汇总的资料来源进行过滤和汇总,并生成最终研究报告。
2.2、多智能体架构
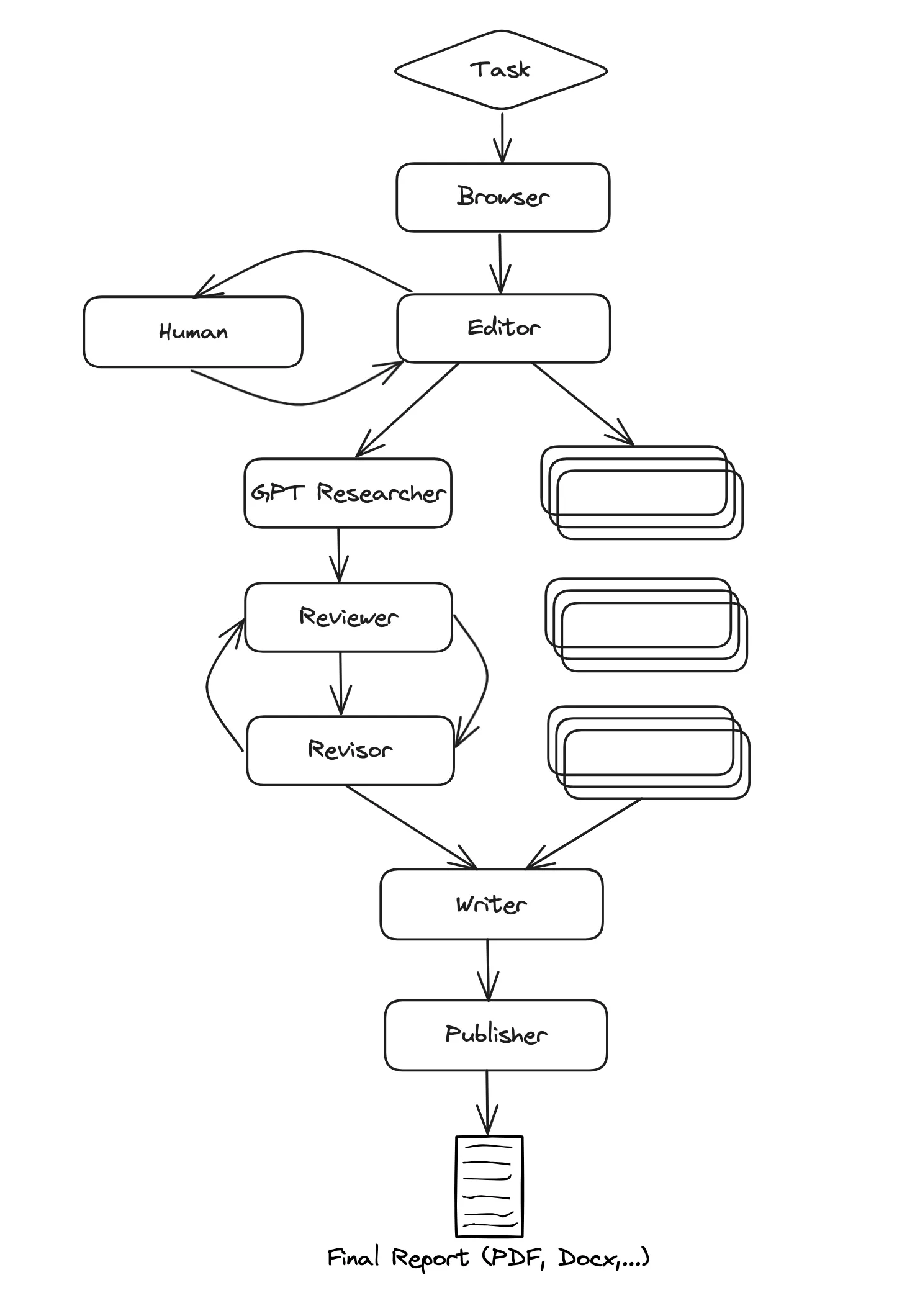
将gpt-researcher智能体作为多智能体系统中的一个节点,更具体地说,该过程如下:
- 浏览器(browser):根据给定的研究任务浏览互联网进行初步研究。
- 编辑者(editor):根据初步研究规划报告大纲和结构。
- 人(human):监督反馈报告大纲和结构是否符合要求。
- 对于每个大纲主题(并行):
- 研究员(gpt-researcher):对子主题进行深入研究并撰写草稿。
- 审阅者(reviewer):根据一组标准验证草稿的正确性并提供反馈。
- 修订者(revisor):根据审阅者的反馈,对草稿进行修订,直到满意为止。
- 作者(writer):根据给定的研究结果,编写并撰写最终报告,包括引言、结论和参考文献部分。
- 发布者(publisher):将最终报告发布为PDF、Docx、Markdown等多种格式。
根据开发者所说:多智能体系统在最后生成报告的质量上比单智能体系统提升了百分之三十。
作者访谈地址:https://www.youtube.com/watch?v=SEapgNU6th0
3、项目文件说明
前端用户界面使用 Next.js、TypeScript 和 Tailwind CSS 构建,位于 '/frontend'
- 静态 FastAPI 版本用于轻量级部署
- Next.js 版本用于生产使用,具有增强功能
后端服务系统使用LangChain,位于'/backend'
- 问答智能体
- 系统记忆
- 报告类型
- 系统服务
多代理研究系统使用 LangChain 和 LangGraph,位于 '/multi_agents'
- 浏览器、编辑器、研究者、审阅者、修订者、撰写者和发布者代理
- 任务配置和代理协调
GPT Researcher 核心功能位于 '/gpt_researcher'
- 网络抓取和内容聚合
- 研究计划和执行
- 来源验证和跟踪
- 查询处理和响应生成
测试基础设施位于 '/tests'
- 单元测试针对各个组件
- 集成测试针对代理交互
- 端到端研究工作流测试
- 测试用的模拟数据和固定装置
4、项目debug运行
准备工作:根据项目文档安装好依赖,配置好.env文件中的参数。
因为每个人的运行环境不同,这里不过多介绍如何安装依赖和配置项目。我的大语言模型和向量化模型都采用的ollma服务,搜索引擎采用tavily(需要去tavily官网申请api key,有很多免费额度)。
.env文件示例:
RETRIEVER="tavily"
TAVILY_API_KEY=""
OLLAMA_BASE_URL=
FAST_LLM="ollama:qwen2.5:7b"
SMART_LLM="ollama:qwen2.5:7b"
STRATEGIC_LLM="ollama:qwen2.5:7b"
EMBEDDING="ollama:nomic-embed-text:latest"如果对安装依赖和项目配置有疑问可以评论区留言或者上网查询。
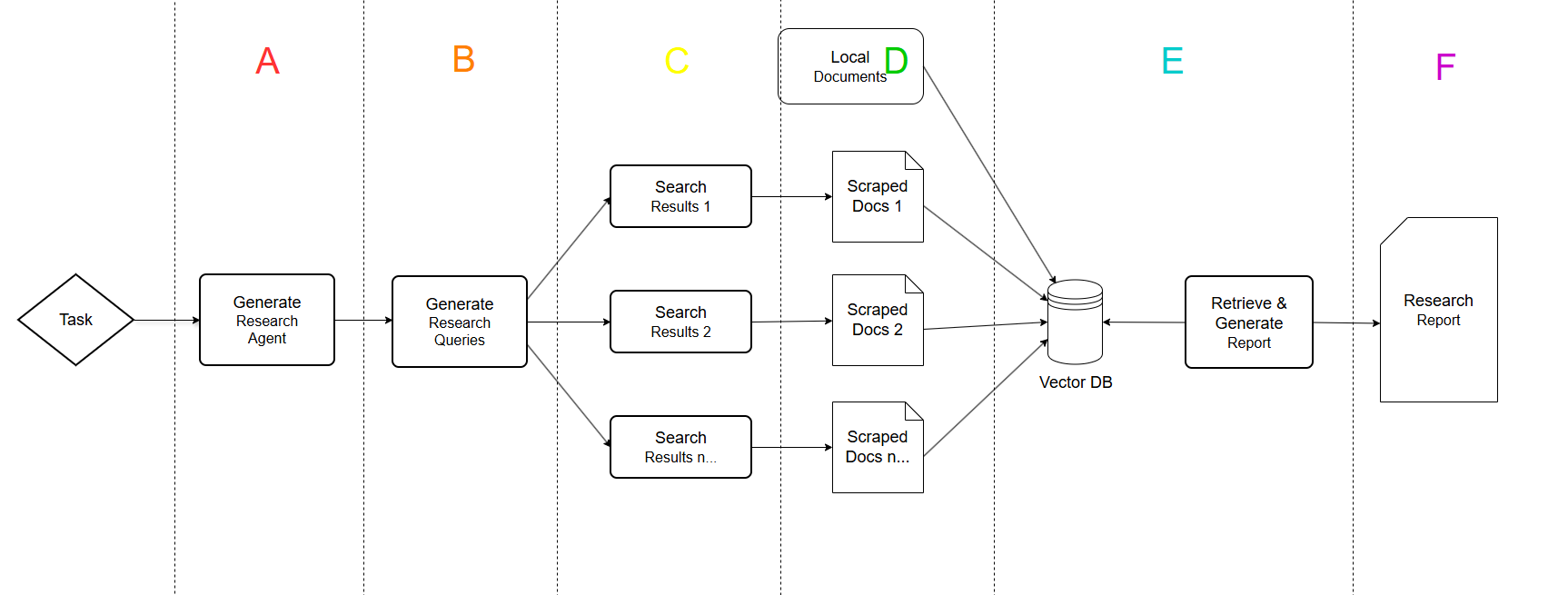
为了更好地说明程序的运行流程,我将单智能体架构图从左到右分为了A、B、C、D、E、F六个阶段,我将跟大家一起通过debug运行的方式逐步剖析每个阶段中gpt-researcher干了什么。
4.1、阶段A:创建研究智能体
启动项目:默认前端页面运行在本机的8000端口,填写好你想要研究的问题,以"what is deepseek?"为例,点击"Research"。根据谷歌浏览器的抓包工具,可以看到前端页面只请求了一个后端接口。
在/backend/server/server.py中找到"/ws"对应的接口函数,打上断点作为程序debug的入口。在/main.py文件中找到主函数,选择debug模式运行,程序进入到我们上面打的断点。
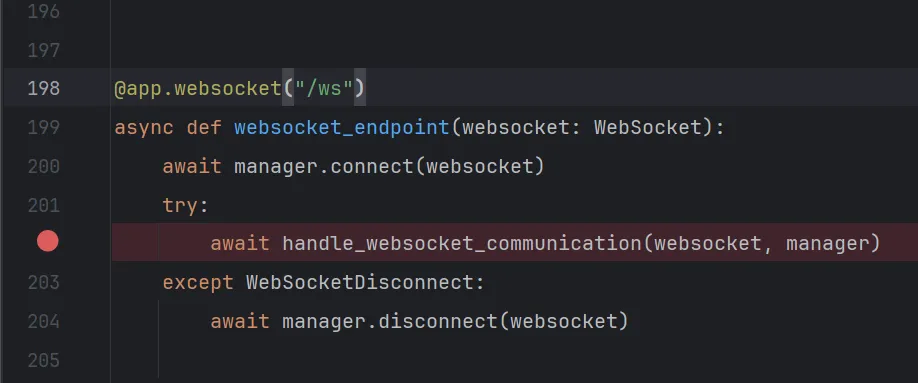
点击step over,让程序执行下一步语句。程序来到了/backend/report_type/basic_report/basic_report.py中的第138行,我们打上断点方便下次跟踪。
程序首先创建了一个BasicReport实例,然后调用了该实例的run方法。
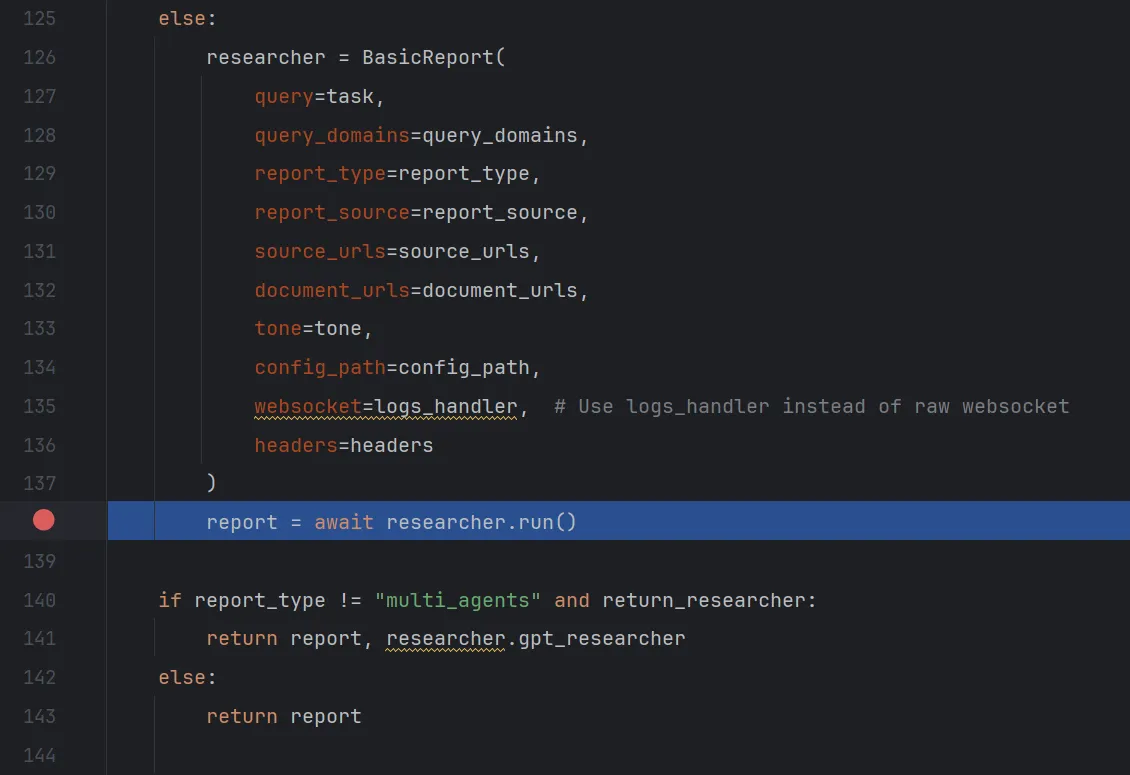
点击step into进入这个函数,可以看到这个run函数中调用了两个主要的函数。conduct_research()和write_report()

进入conduct_research()函数看看,点击step into
日志函数先忽略,点击step over到if条件判断语句。这里有个方法可以查看条件判断语句的值,选中条件
点击选中Evaluate Expression,点击Evaluate
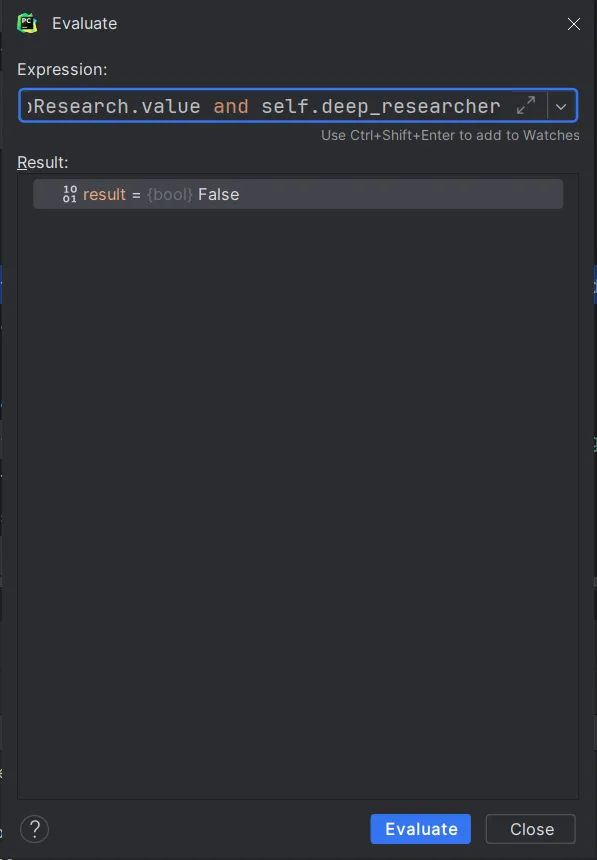
可以看到结果是False,说明该条件判断下面的语句不执行
继续step over,检查下一个条件判断语句的结果,结果为True
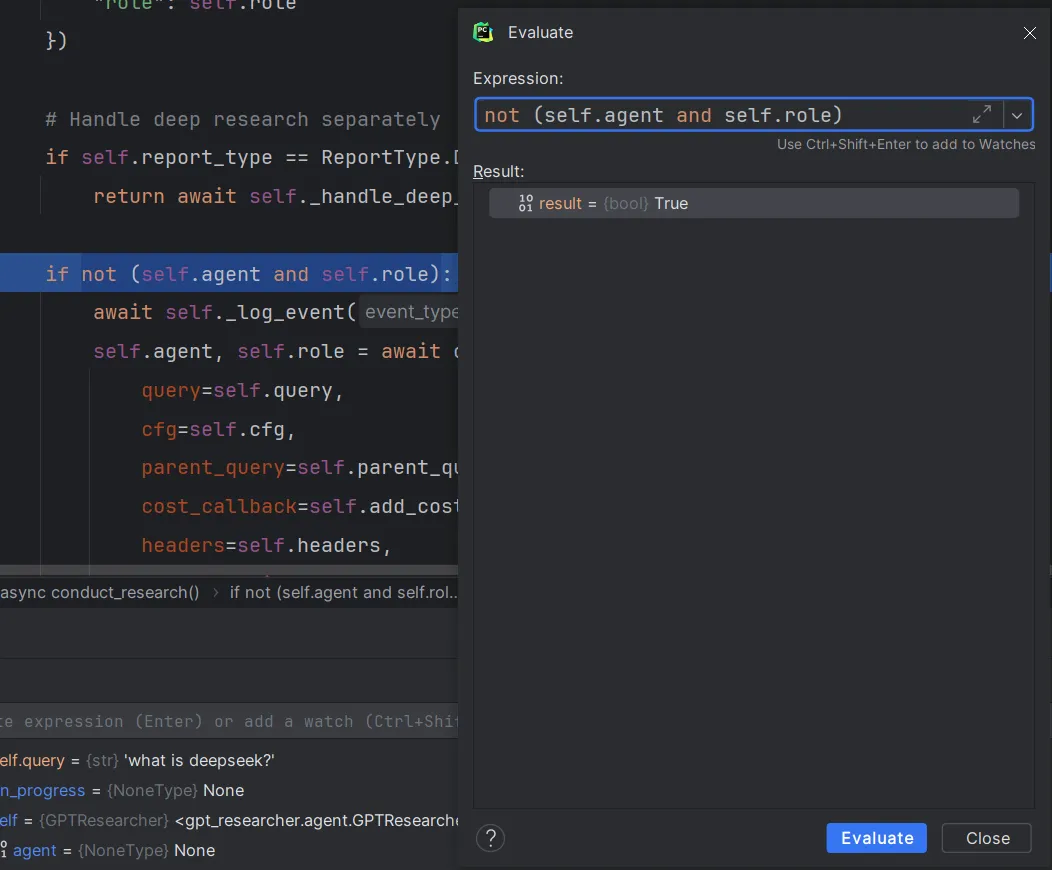
说明程序进入到该条件判断语句中,检查下方的Threads&Variables窗口,发现此时的agent和role变量都为None,说明agent和role变量都是通过choose_agent函数赋值的,让我们来看看这个函数里面做了什么。点击step into后我们来到了/gpt_researcher/actions/agent_creator.py中的choose_agent函数,该函数功能是自动选择一个agent,也就是单智能体架构图中的"Generate Research Agent"节点。
继续step over,程序调用了一次大语言模型。我们关注提示词部分,其中user提示词中的query变量很容易知道,我们看一下system提示词,同样使用Evaluate Expression功能。
提示词如下:
This task involves researching a given topic, regardless of its complexity or the availability of a definitive answer. The research is conducted by a specific server, defined by its type and role, with each server requiring distinct instructions.
Agent
The server is determined by the field of the topic and the specific name of the server that could be utilized to research the topic provided. Agents are categorized by their area of expertise, and each server type is associated with a corresponding emoji.examples:
task: "should I invest in apple stocks?"
response:
{
"server": "💰 Finance Agent",
"agent_role_prompt: "You are a seasoned finance analyst AI assistant. Your primary goal is to compose comprehensive, astute, impartial, and methodically arranged financial reports based on provided data and trends."
}
task: "could reselling sneakers become profitable?"
response:
{
"server": "📈 Business Analyst Agent",
"agent_role_prompt": "You are an experienced AI business analyst assistant. Your main objective is to produce comprehensive, insightful, impartial, and systematically structured business reports based on provided business data, market trends, and strategic analysis."
}
task: "what are the most interesting sites in Tel Aviv?"
response:
{
"server": "🌍 Travel Agent",
"agent_role_prompt": "You are a world-travelled AI tour guide assistant. Your main purpose is to draft engaging, insightful, unbiased, and well-structured travel reports on given locations, including history, attractions, and cultural insights."
}
该提示词的功能是根据你的原始问题,让大模型生成一个对应的角色和角色提示词。
继续step over,可以看到choose_agent函数返回了生成的"server"和"agent_role_prompt"字段。
问题"what is deepseek?"生成的字段如下:
{'server': '🔍 Information Retrieval Agent', 'agent_role_prompt': 'You are an advanced AI information retrieval specialist. Your primary role is to provide detailed, accurate, and unbiased explanations or definitions of complex terms, concepts, or technologies based on available data sources.'}
4.2、阶段B:创建研究问题
这个函数看完了,我们点击step out 跳出该函数,现在我们又来到了/gpt_researcher/agent.py中的conduct_research函数。点击step over暂时忽略一下日志操作,来到了下一个重要的语句
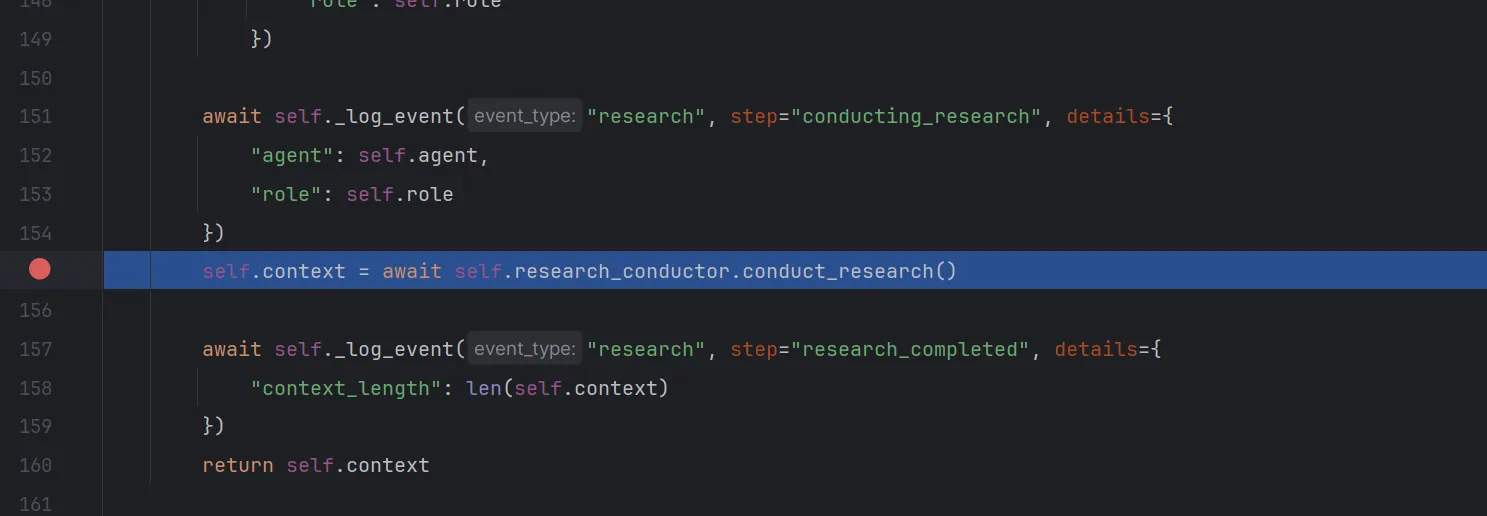
我们看到该函数返回self.context,context是什么?我们点击step into进入该函数看看
如何检查条件判断语句的值不再赘述,这里补充一个小tip:在线搜索资源的任务中,如何确保访问过的网页链接不再访问?
该项目是通过在线研究过程中维护两个数组visited_urls和source_urls实现的

一直step over,直到
research_data = await self._get_context_by_web_search(self.researcher.query, [], self.researcher.query_domains)
看下research_data是怎么被赋值的,点击step into进入_get_context_by_web_search函数
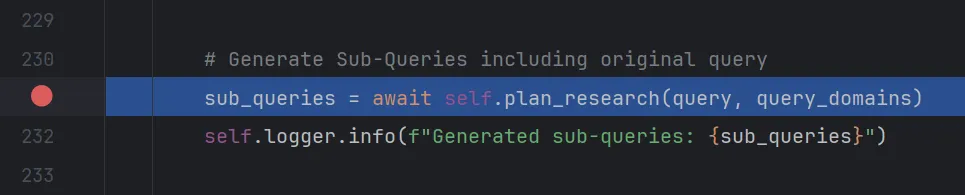
点击step over到第231行,sub_queries变量接收plan_research函数的返回值,我们点击step into进入该函数。
来到了/gpt_researcher/skills/researcher.py中的plan_research方法
点击step over,跳过日志部分,来到第32行。

程序用问题"what is deepseek?"调用了一次搜索引擎(tavily),拿到了十条结果。
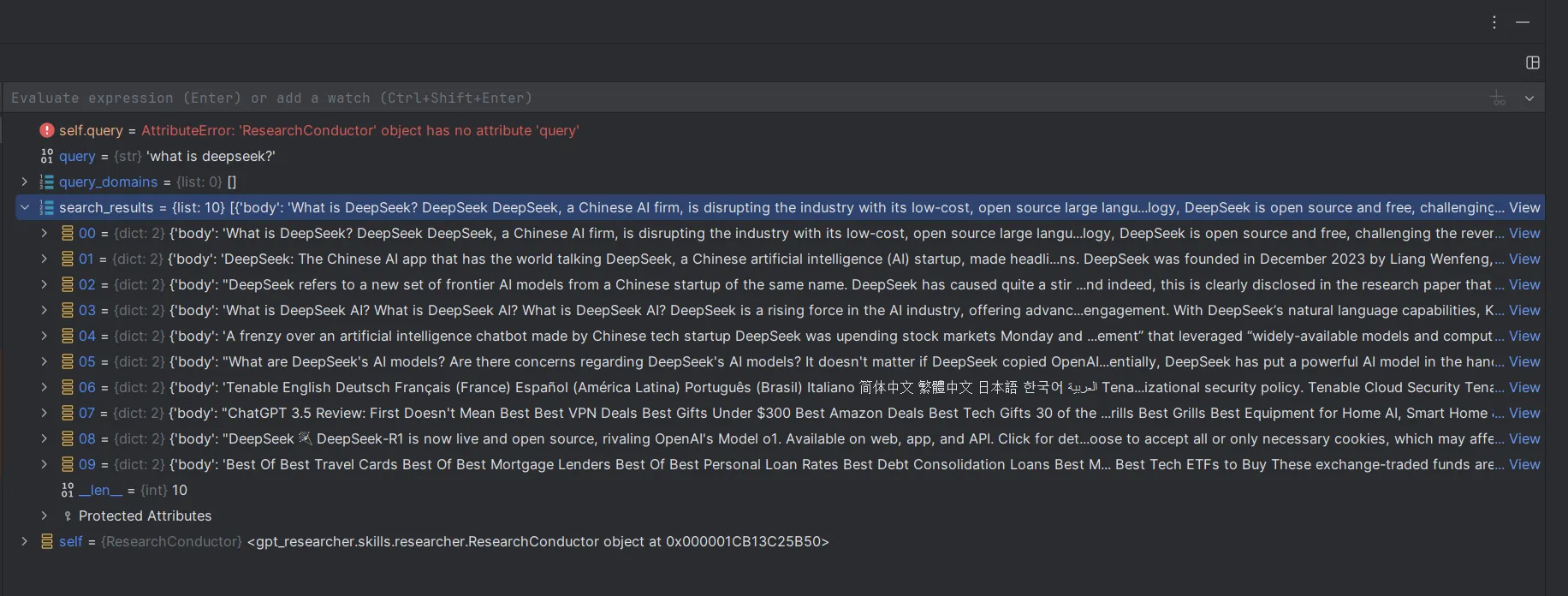
继续step over,看下函数的返回值outline是什么。
我们来到了/gpt_researcher/actions/query_processing.py下的plan_research_outline函数
将query和上次搜索得到的结果列表search_results传递给该函数
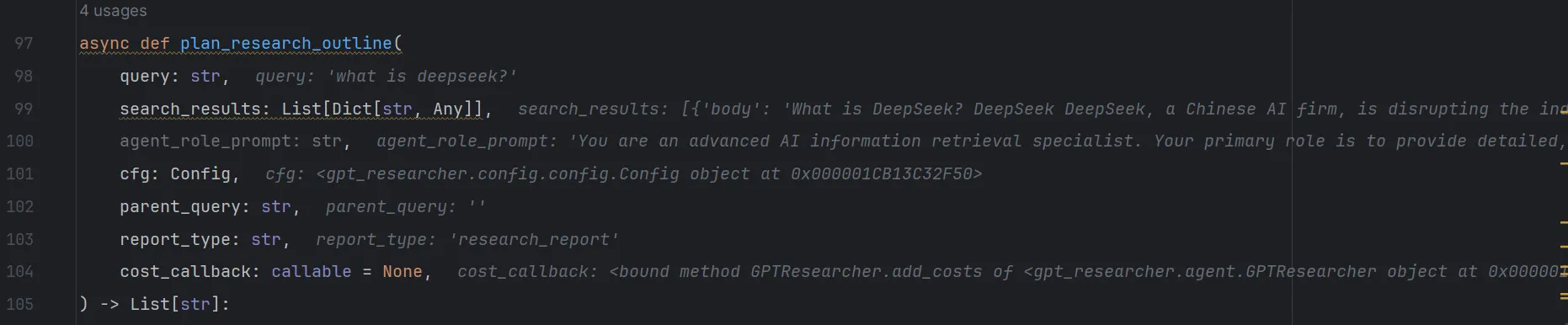
继续看下sub_queries是如何生成的,选中step into来到/gpt_researcher/actions/query_processing.py脚本中的generate_sub_queries函数。
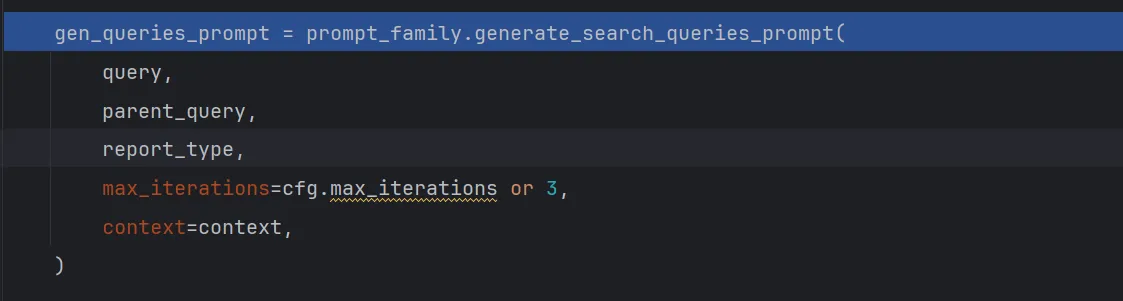
通过Evaluate Expression功能查看到gen_queries_prompt为
Write 3 google search queries to search online that form an objective opinion from the following task: "what is deepseek?"
Assume the current date is May 09, 2025 if required.
You are a seasoned research assistant tasked with generating search queries to find relevant information for the following task: "what is deepseek?".
Context: [{'href': 'https://www.techtarget.com/WhatIs/feature/DeepSeek-explained-Everything-you-need-to-know', 'body': "What is DeepSeek? DeepSeek DeepSeek, a Chinese AI firm, is disrupting the industry with its low-cost, open source large language models, challenging U.S. tech giants. What is DeepSeek? DeepSeek focuses on developing open source LLMs. The company's first model was released in November 2023. DeepSeek In a research paper, DeepSeek outlines the multiple innovations it developed as part of the R1 model, including the following: Since the company was created in 2023, DeepSeek has released a series of generative AI models. The low-cost development threatens the business model of U.S. tech companies that have invested billions in AI. In contrast with OpenAI, which is proprietary technology, DeepSeek is open source and free, challenging the revenue model of U.S. companies charging monthly fees for AI services."}, ......]Use this context to inform and refine your search queries. The context provides real-time web information that can help you generate more specific and relevant queries. Consider any current events, recent developments, or specific details mentioned in the context that could enhance the search queries.
You must respond with a list of strings in the following format: ["query 1", "query 2", "query 3"].
The response should contain ONLY the list.
其中的'href'和'body'参数都取自tavily搜索引擎返回的结果列表。
根据原研究问题生成一些新的问题,一般是让大语言模型直接生成,而这里将原问题在线搜索的结果列表作为参考信息和原问题一起送给大模型,并说明:"使用此上下文来通知和优化您的搜索查询。上下文提供实时网络信息,可以帮助您生成更具体和相关的查询。考虑上下文中提到的任何当前事件、最新发展或具体细节,以增强搜索查询问题。"
一直step out回到outline被赋值的部分,此时我们已经知道,outline就是包含子问题的问题列表。
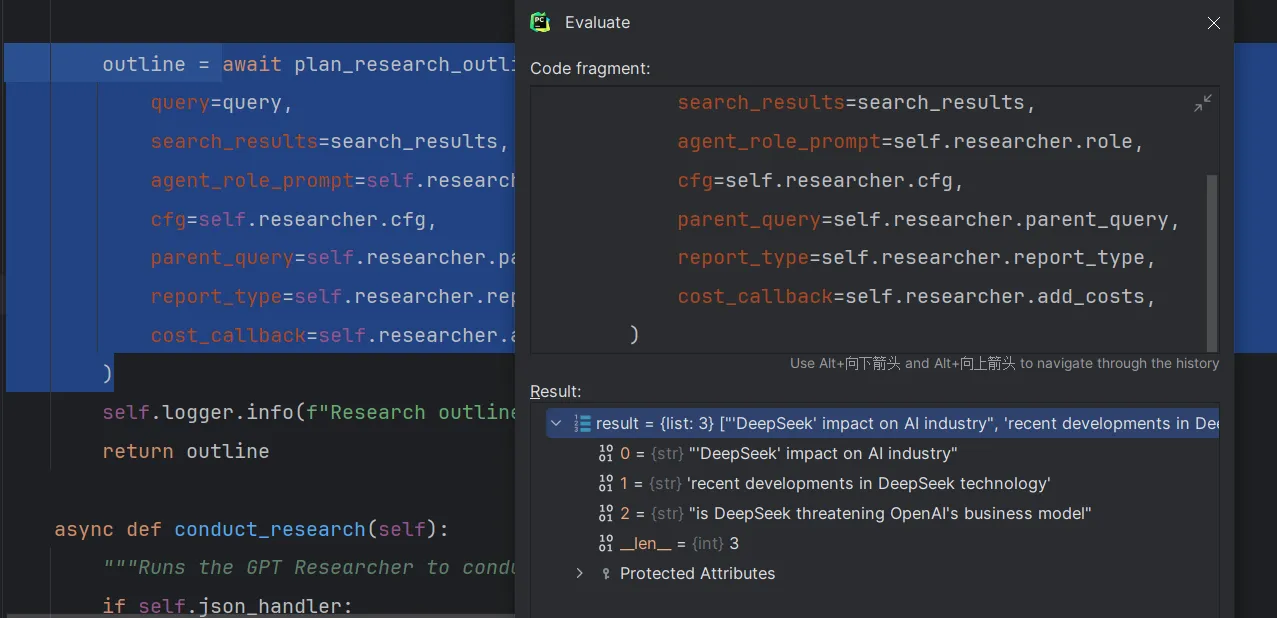
继续step out一直到sub_queries接收到返回的子问题列表后,再点击step over
4.3、阶段C:搜索研究任务
开始异步处理这些子问题:
进入_process_sub_query函数,函数注释为:接收一个子查询,根据它抓取网址并收集上下文。
一直step over,来到/gpt_researcher/skills/researcher.py

选择step into进入_scrape_data_by_urls函数,函数的参数是需要搜索的子问题,返回值是爬取内容结果列表。

再进入_search_relevant_source_urls函数
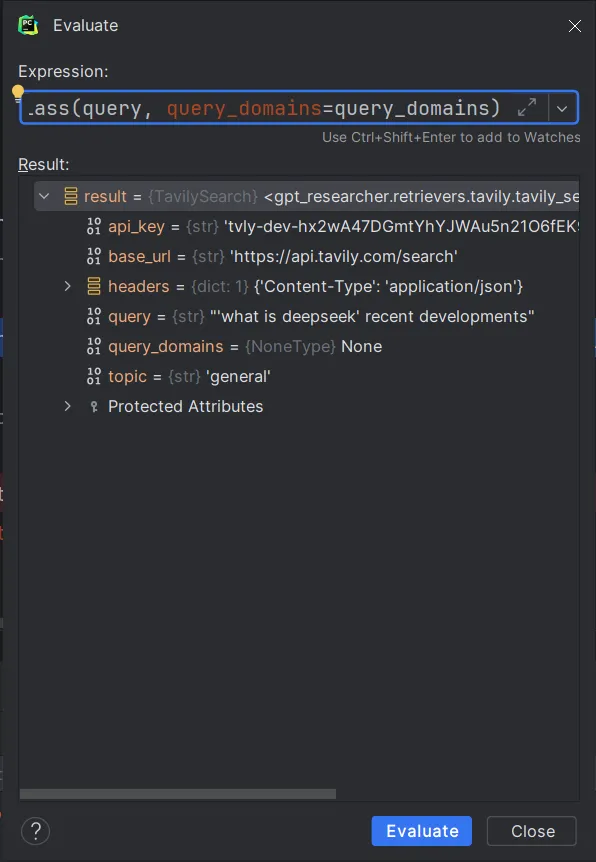
请关注下述代码
# 遍历所有检索器
for retriever_class in self.researcher.retrievers:
# 使用子查询实例化检索器
retriever = retriever_class(query, query_domains=query_domains)
# 使用当前检索器执行搜索
search_results = await asyncio.to_thread(
retriever.search, max_results=self.researcher.cfg.max_search_results_per_query
)
#从搜索结果中添加新URL
search_urls = [url.get("href") for url in search_results]
new_search_urls.extend(search_urls)实例化的检索器为:
其中最关键的是使用当前检索器执行搜索得到的search_results是什么?
使用Evaluate Expression功能可以看到,search_results变量的值为json对象数组
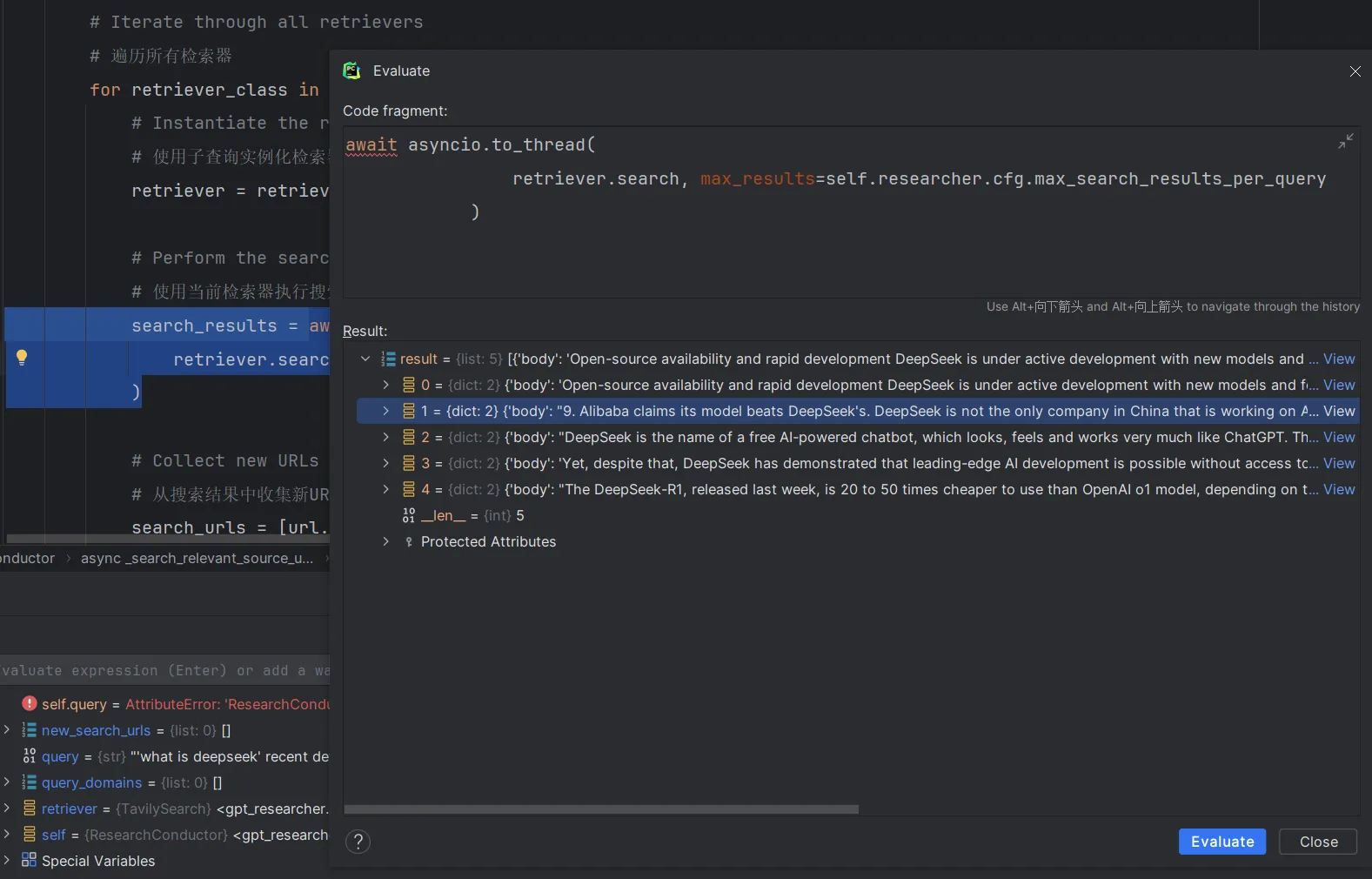
每个json对象格式为
{'href': 'https://www.computerworld.com/article/3815603/deepseek-latest-news-and-insights.html', 'body': 'Open-source availability and rapid development DeepSeek is under active development with new models and features being released regularly. Models are often available for public download (on'}
该对象是针对tavily搜索引擎api的返回值列表进行了二次封装构建的,'href'是网页地址,'body'是tavily搜索引擎提供的对网页内容的摘要。
将每个json对象的"href"属性值添加到new_search_urls列表中,然后再对该列表中的链接元素进行去重和判断是否已经访问过。
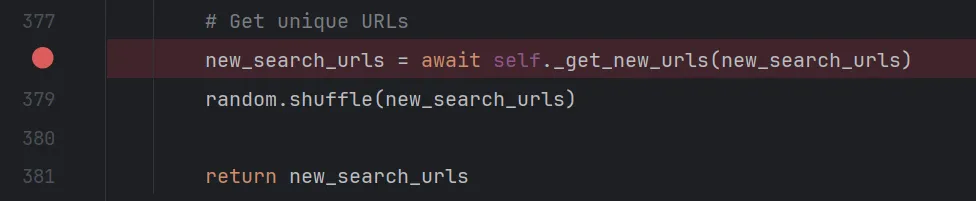
进入_get_new_urls函数,函数注释为从给定的url集合中获取新的url,代码意思是只要输入的url集合中的元素不在visited_urls数组中,就认为是新的未访问过的url。
代码为:
async def _get_new_urls(self, url_set_input):
"""Gets the new urls from the given url set.
Args: url_set_input (set[str]): The url set to get the new urls from
Returns: list[str]: The new urls from the given url set
"""
new_urls = []
for url in url_set_input:
if url not in self.researcher.visited_urls:
self.researcher.visited_urls.add(url)
new_urls.append(url)
if self.researcher.verbose:
await stream_output(
"logs",
"added_source_url",
f"✅ Added source url to research: {url}\n",
self.researcher.websocket,
True,
url,
)
return new_urls选中step out跳出到/gpt_researcher/skills/researcher.py中的_scrape_data_by_urls函数的408行,来到从url中爬取数据的地方
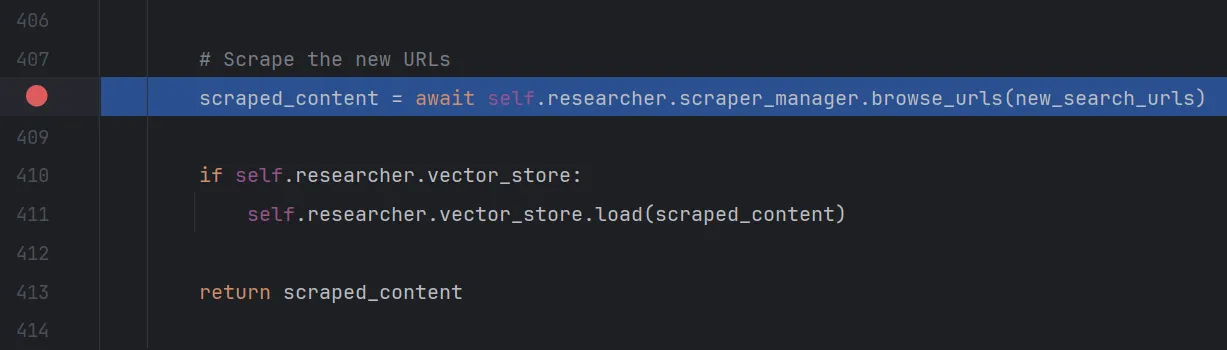
进入browse_urls函数,step over来到
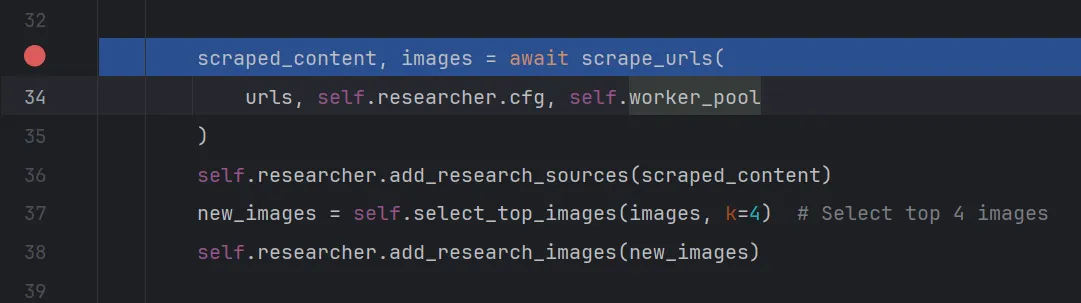
使用Evaluate Expression功能看一下此处的scraped_content,images是什么结构
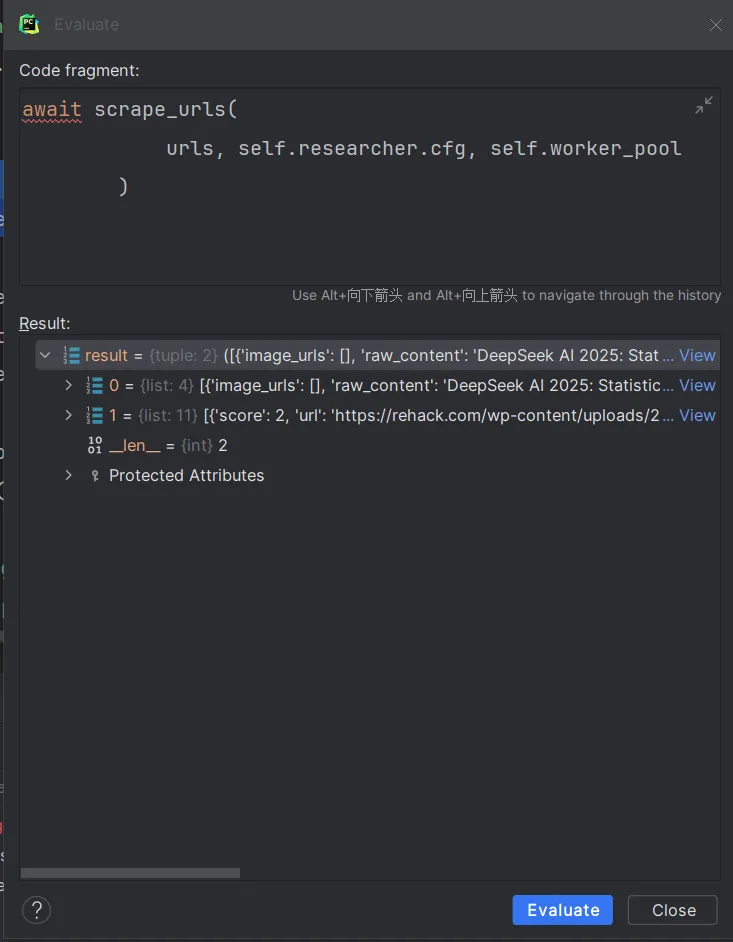
让我们step into进入看一看
来到了\gpt_researcher\actions\web_scraping.py下的scrape_urls函数,函数解释为爬取url链接页面的数据,返回包含两个列表的元组
step over到
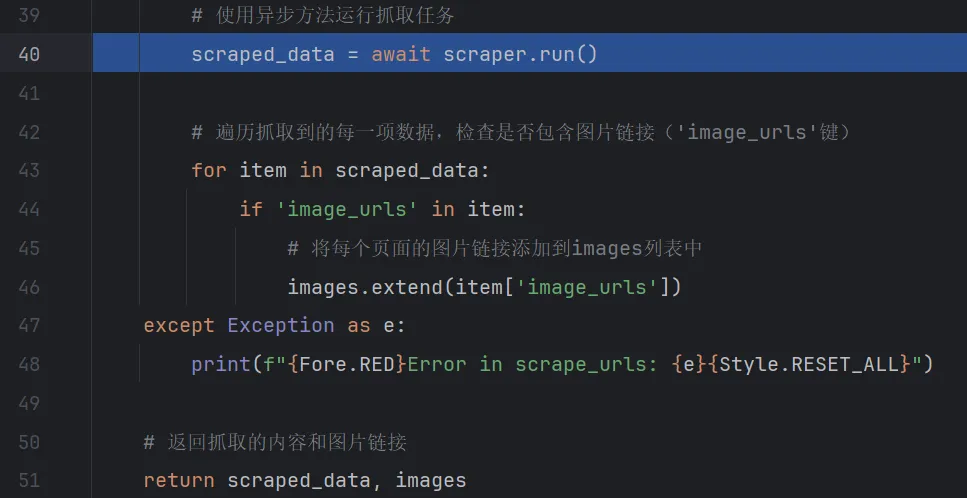
step into进去看一下,来到了\gpt_researcher\scraper\scraper.py脚本下的run函数
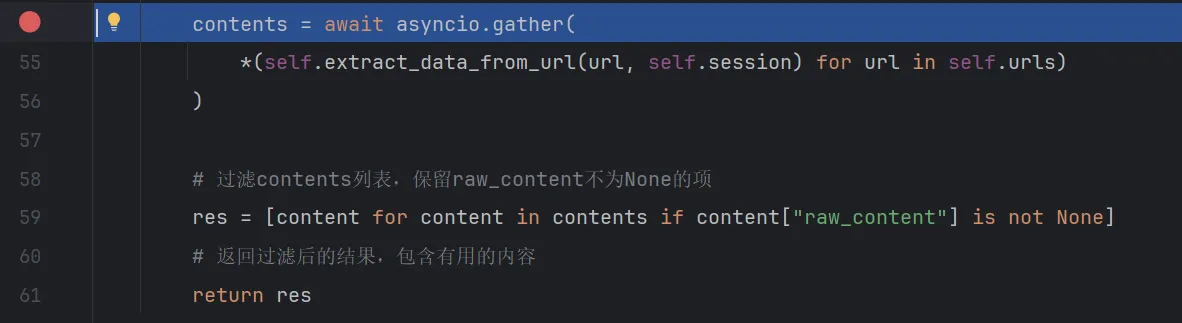
继续step into进入extract_data_from_url函数,这个函数比较难进,需要来到\gpt_researcher\scraper\scraper.py脚本下的117行或者124行打上断点,点击resume program进入。
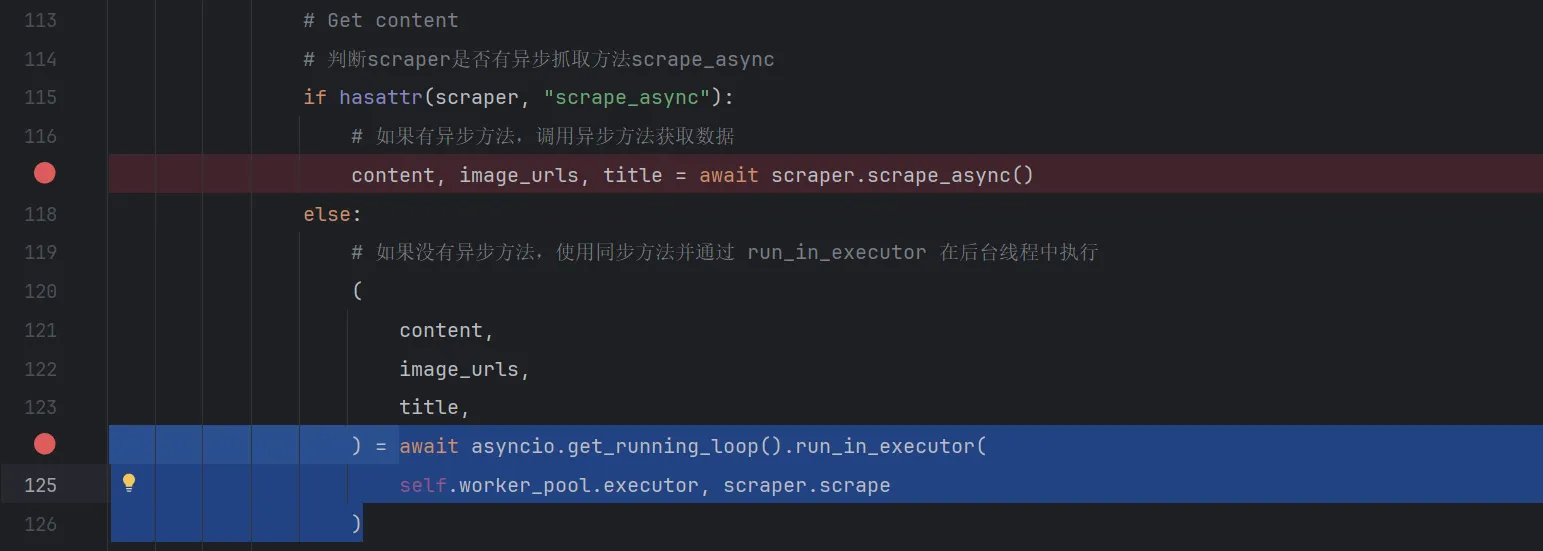
程序进入了124行的断点处,使用Evaluate Expression功能看一下该函数返回了什么
一个包含了三个元素的元组。
网页源码:
What Is DeepSeek AI and How Will It Impact the AI Industry? - ReHack
Skip to content
Search
×
AI
What Is DeepSeek AI and How Will It Impact the AI Industry?
May 8, 2025 •
April Miller
Advertisements
Artificial intelligence (AI) is evolving at an incredible pace, with breakthroughs emerging constantly. One of the latest players making waves is DeepSeek AI, a company taking a unique approach to AI development. Unlike many AI companies that keep their models private, DeepSeek is making its technology open-source — giving developers, researchers and businesses worldwide the chance to build on its work.
So, what exactly is DeepSeek AI, and why should you care? Whether you’re a tech enthusiast, a developer or just curious about where AI is headed, explore what DeepSeek is, how it works and how it could reshape the AI industry.
What Is DeepSeek AI?
DeepSeek AI is an AI research company based in China. It was
founded in 2023 by Liang Wenfeng
to advance artificial general intelligence (AGI). What sets it apart from other AI companies is its commitment to making powerful AI models accessible to everyone. Instead of keeping its technology locked behind closed doors, DeepSeek open-sources its AI models, allowing anyone to use, modify and improve them.
By focusing on efficiency, DeepSeek AI is proving that cutting-edge AI can be developed without the massive costs typically associated with big tech companies. That means more developers, businesses and researchers — including you — can tap into AI’s potential without needing a billion-dollar budget.
Key Features of DeepSeek AI
Before diving into how DeepSeek AI could impact the industry, it’s important to understand what makes it special. Here are some standout features:
Open-source AI:
Unlike companies like OpenAI and Google DeepMind, which keep their AI models private, DeepSeek AI makes its models publicly available. That means you can access, modify and build on its technology for free.
Powerful language models:
DeepSeek’s flagship model, DeepSeek-V3, is a massive
Mixture-of-Experts language model with 671 billion
parameters. It’s designed for high-level reasoning, coding and language processing, competing with some of the best AI models on the market.
Cost-efficient AI training:
AI models typically require enormous computing power, making them expensive to develop. DeepSeek has optimized its training process to be more affordable, proving that you don’t need unlimited resources to create top-tier AI.
Focus on AGI:
While many AI companies are focused on specialized models for specific tasks, DeepSeek is working toward AGI — AI that can perform a wide range of functions at a human-like level.
Versatile applications:
DeepSeek’s AI isn’t just for chatbots. You can use it for coding assistance, content generation, data analysis and more.
How Will DeepSeek AI Impact the AI Industry?
The rise of DeepSeek AI is shaking up the AI industry in several ways. Whether you’re a developer, entrepreneur or AI enthusiast, these changes will likely affect how you interact with and use AI.
AI Development Will Become More Accessible
Traditionally, only large companies with deep pockets could afford to train and deploy advanced AI models. DeepSeek AI is changing that by open-sourcing its technology, making it easier for smaller developers and businesses to create powerful AI applications. Here are three ways DeepSeek AI makes AI development more accessible to everyone:
Lowering barriers to entry:
With access to DeepSeek’s models, you don’t need to build AI from scratch, saving time and money.
Encouraging collaboration:
Open-source AI fosters a community-driven approach where developers worldwide can share improvements and innovations.
Challenging proprietary models:
As more companies embrace open-source AI, big tech firms may have to rethink their closed-off approach to AI development.
AI Will Become More Affordable
Another reason AI is becoming more affordable is the rise of foundation models like DeepSeek AI. While traditional AI models focus on specific tasks, foundation models
have a more generalized understanding
, allowing them to apply knowledge across multiple domains and functions.
This means businesses no longer need to develop separate AI models for every use case, reducing costs and making AI adoption more practical across different industries. Here’s what could happen:
More startups can enter the AI space:
With reduced costs, smaller companies have a better chance of competing with big tech firms.
Lower AI service prices:
As more affordable models become available, AI-powered services — such as chatbots, automation tools and AI writing assistants — could become cheaper for consumers.
Greater AI adoption:
With lower costs, businesses across industries can integrate AI into their operations without breaking the bank.
AI Competition Will Intensify
DeepSeek AI is adding pressure to the already competitive AI landscape, especially in China, where multiple companies are racing to become leaders in AI. This means you can expect faster advancements, more AI innovations and better AI tools in the coming years. Below are some predictions:
Big tech firms will need to innovate faster:
Companies like OpenAI, Google DeepMind and Anthropic will likely push harder to improve their AI models.
China’s AI industry will expand:
DeepSeek AI is helping China become a stronger player in AI, increasing global competition.
AI regulations may evolve:
As AI technology spreads, governments may introduce new policies to address ethics, safety and data privacy concerns.
AI Investments Will Shift Toward Practical Applications
AI investors are becoming more selective, focusing on companies that can apply AI effectively rather than just develop expensive models. That means you’ll likely see more AI-powered products and solutions hitting the market soon. Here’s how this shift in investment priorities could shape the future of AI:
More funding for AI startups:
Startups that create useful AI applications — such as AI-driven healthcare tools or automation software — will attract more investors.
Greater focus on AI’s real-world impact:
Investors will prioritize AI solutions that solve real problems instead of just funding AI research.
Shift away from purely experimental AI projects:
Investors will look for AI companies with clear business models and practical use cases.
AI Will Expand into More Industries
With DeepSeek AI lowering the cost and accessibility of AI, you’ll see more AI-powered solutions across different industries. Whether you’re in tech, healthcare, finance or education, AI will likely play a bigger role in your field through improvements like:
AI-assisted coding:
If you’re a developer, AI models like DeepSeek can help you write, debug and optimize code more efficiently.
Content generation:
If you’re in marketing or content creation, AI can help you generate text, summaries and creative ideas.
Healthcare advancements:
AI
can help with drug discovery
, medical research and diagnostics, revolutionizing the industry.
AI in education:
Personalized learning experiences could improve students’ and professionals’ learning of new skills.
What DeepSeek AI Means for You
DeepSeek AI is redefining how AI is developed, making it more open, affordable and accessible. Whether you’re a developer looking for new AI tools, a business owner exploring AI solutions or just someone fascinated by tech, you’re going to see AI evolve faster than ever before.
The biggest question now is — how will you take advantage of these changes? With AI becoming more available, the opportunities to create, innovate and transform industries are endless. Now is the time to explore, experiment and embrace the future of AI.
Post Views:
90
Recent Stories
AI
What Is DeepSeek AI and How Will It Impact the AI Industry?
May 8, 2025 •
April Miller
Cybersecurity
,
Data Security
Why Cyber Resilience is Critical for the Future of Remote Work
May 6, 2025 •
April Miller
Apps
,
Culture
You’re Not Going Crazy: YouTube Ads Are out of Control
May 1, 2025 •
Zachary Amos
Follow Us On
Get the latest tech stories and news in seconds!
Sign up for our newsletter below to receive updates about technology trends
!
Subscribe
Something went wrong. Please check your entries and try again.
Similar Content
AI
What Is DeepSeek AI and How Will It Impact the AI Industry?
May 8, 2025 •
April Miller
AI
Top Generative AI Examples Making Waves in Education
April 24, 2025 •
Zachary Amos
AI
,
Cybersecurity
,
Data Security
,
Privacy
AI Scams: How To Protect Yourself and Your Loved Ones
March 13, 2025 •
Devin Partida
AI
An Introduction to Apple Intelligence: Release, Rollout and Reveals
March 12, 2025 •
Zachary Amos
Scroll To Top
图片地址:
[{'url': 'https://rehack.com/wp-content/uploads/2025/01/jacob-mindak-FSYciNwhrSI-unsplash-1.jpg', 'score': 2}, {'url': 'https://rehack.com/wp-content/uploads/2024/12/gilles-lambert-pb_lF8VWaPU-unsplash-1-1.jpg', 'score': 2}, {'url': 'https://rehack.com/wp-content/uploads/2025/01/An-Introduction-to-Apple-Intelligence-Release-Rollout-and-Reveals.jpg', 'score': 2}, {'url': 'https://rehack.com/wp-content/uploads/2025/03/gertruda-valaseviciute-xMObPS6V_gY-unsplash-1-1-1024x682.jpg', 'score': 1}, {'url': 'https://rehack.com/wp-content/uploads/2020/09/bg-pamplet-2.png', 'score': 1}]
网页标题:
What Is DeepSeek AI and How Will It Impact the AI Industry? - ReHack
我们按住ctrl点进scraper.scrape函数,我们来到了/gpt_researcher/scraper/beautiful_soup/beautiful_soup.py中的scrape函数。该函数通过向网页地址发送get请求,获得网页源码数据。然后通过beautifulsoup从中解析出内容、图片地址和标题。
注意:此处很有可能因为无法访问外网或者访问的网站具有反爬机制导致获取网页源码内容失败。也就意味着你使用Evaluate Expression功能时,不一定能看到上述结果。
在/gpt_researcher/scraper文件夹下有很多不同类型的爬虫脚本,可以供大家参考研究。
4.4、阶段D、E:向量检索研究内容
此时我们根据子问题获取到了对应的scraped_data,我们看程序接下来如何处理。到/gpt_researcher/skills/researcher.py中的第289行。注意:此时需要把/gpt_researcher/scraper/scraper.py
中的第117行和124行的断点去除再重新运行debug程序,一直点击Resume Peogram到达此处。

我们进入get_similar_content_by_query函数,函数接收query和pages
step over来到第24行,创建ContextCompressor对象,用于压缩和处理文档上下文
step over来到第30行,step into到async_get_context函数中,来到了/gpt_researcher/context/compression.py中的第74行。
step over来到第78行,异步地在单独的线程中调用invoke方法,执行查询并获取相关文档。按住ctrl点进invoke函数。函数注释如下:
"""Invoke the retriever to get relevant documents.
Main entry point for synchronous retriever invocations.
Args:
input: The query string. 字符串类型,表示查询的内容。
config: Configuration for the retriever. Defaults to None. 可选参数,表示检索器的配置,默认为 None。
kwargs: Additional arguments to pass to the retriever. 任意额外的关键字参数,用于传递给检索器的其他配置或选项。Returns:
List of relevant documents. 返回一个 Document 类型的列表,表示与查询相关的文档。
"""
来到第266行,按住ctrl进入_get_relevant_documents函数。
这是一个langchain中的抽象方法
主要应用了langchain框架的向量检索器模块,主要代码如下:
@override
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun, **kwargs: Any
) -> list[Document]:
_kwargs = self.search_kwargs | kwargs
if self.search_type == "similarity":
docs = self.vectorstore.similarity_search(query, **_kwargs)
elif self.search_type == "similarity_score_threshold":
docs_and_similarities = (
self.vectorstore.similarity_search_with_relevance_scores(
query, **_kwargs
)
)
docs = [doc for doc, _ in docs_and_similarities]
elif self.search_type == "mmr":
docs = self.vectorstore.max_marginal_relevance_search(query, **_kwargs)
else:
msg = f"search_type of {self.search_type} not allowed."
raise ValueError(msg)
return docs我们再回到/gpt_researcher/skills/researcher.py脚本中的_process_sub_query函数,我们现在将查询得到的文档进行了向量压缩存储,并且根据问题获取到了相关的文档列表,也就是此处的content

content的结构示例为
Source: https://www.techtarget.com/WhatIs/feature/DeepSeek-explained-Everything-you-need-to-know
Title: DeepSeek explained: Everything you need to know
Content: What is DeepSeek?
DeepSeek is an AI development firm based in Hangzhou, China. The company was founded by Liang Wenfeng, a graduate of Zhejiang University, in May 2023. Wenfeng also co-founded High-Flyer, a China-based quantitative hedge fund that owns DeepSeek. Currently, DeepSeek operates as an independent AI research lab under the umbrella of High-Flyer. The full amount of funding and the valuation of DeepSeek have not been publicly disclosed.
DeepSeek focuses on developing open source LLMs. The company's first model was released in November 2023. The company has iterated multiple times on its core LLM and has built out several different variations. However, it wasn't until January 2025 after the release of its R1 reasoning model that the company became globally famous.
The company provides multiple services for its models, including a web interface, mobile application and
API
access.
OpenAI vs. DeepSeekSource: https://ai.nd.edu/news/deepseek-explained-what-is-it-and-is-it-safe-to-use/
Title: DeepSeek Explained: What Is It and Is It Safe To Use? | News | AI@ND | University of Notre Dame
Content: DeepSeek-v3 is a general-purpose chat model similar to ChatGPT 4o.
DeepSeek has also created DeepSeek Math and DeepSeek Coder, models specializing in mathematics and programming, respectively, as well as DeepSeek-VL, a model that can interpret images.......
此时,/backend/report_type/basic_report/basic_report.py中的run函数中的47行终于运行完毕了。接下来我们看该函数中第二个重要的部分:报告是如何生成的。
4.5、阶段F:编写研究报告

选择step into进入write_report函数
首先来到了/gpt_researcher/agent.py脚本下的write_report函数
我们接下来的任务就是理解这个report是怎么得到的,就大功告成了。
选择step into进入write_report函数,我们step over,来看一下context。
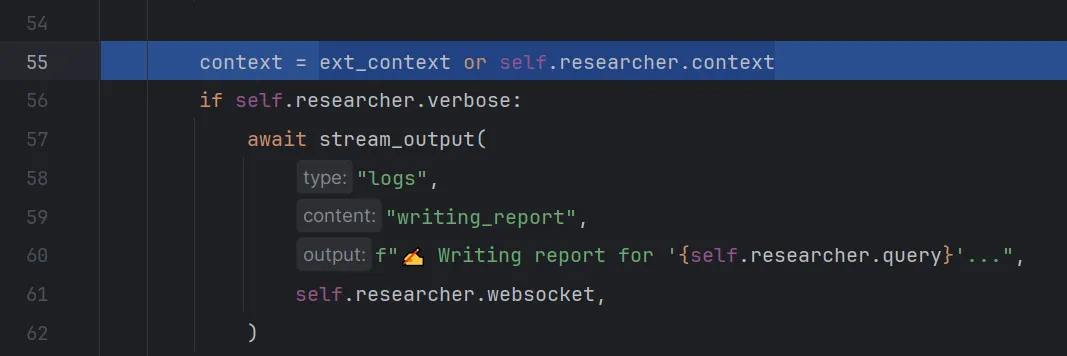
此时的context为
Source: https://interestingengineering.com/innovation/deepseek-vs-openai-whos-copying-who
Title: DeepSeek vs. OpenAI: who’s copying who?
Content: What is DeepSeek, and how does it compare to ChatGPT?
At first glance,
DeepSeek
may appear to be China’s version of ChatGPT, but as Alfredo points out, there’s more beneath the surface. “DeepSeek is an open-source model. Any developer can see, modify, and run it. That’s a massive difference from OpenAI, which is quite closed,” he explained.
This open-source nature is a key distinction. Unlike OpenAI, which has gradually moved toward a closed model, DeepSeek allows developers to tinker with its architecture, potentially accelerating global AI innovation outside the dominance of American tech giants.
But does that mean it’s as powerful as GPT-4? “DeepSeek uses a ‘mixture of experts’ approach, which only activates certain parts of the model depending on the query. This makes it computationally efficient, but whether it outperforms GPT-4 depends on the task,” Alfredo added.
DeepSeek: a major headache for NVIDIA?Source: https://www.euclea-b-school.com/deepseek-ai-vs-open-ai-a-comprehensive-comparison/
Title: Deepseek AI Vs Open AI: A Comprehensive Comparison - EUCLEA Business School
Content: Deepseek AI
, while a newer entrant, has quickly gained recognition for its innovative approach to AI.
Deepseek focuses on building modular and transparent AI solutions, with a strong emphasis on explainability and adaptability.
This makes Deepseek particularly well-suited for industries like healthcare and finance, where understanding the reasoning behind AI decisions is crucial. Deepseek’s R1 model, for instance, leverages a hybrid training approach combining reinforcement learning with supervised fine-tuning, leading to impressive performance in reasoning-heavy tasks.
Key Features and Capabilities
Both Deepseek AI and OpenAI offer a range of powerful features, but their strengths lie in different areas:
OpenAI excels in:
Natural Language Processing (NLP):
GPT models are known for their advanced NLP capabilities, enabling them to understand and generate human-like text with remarkable accuracy.
Creative Content Generation:......
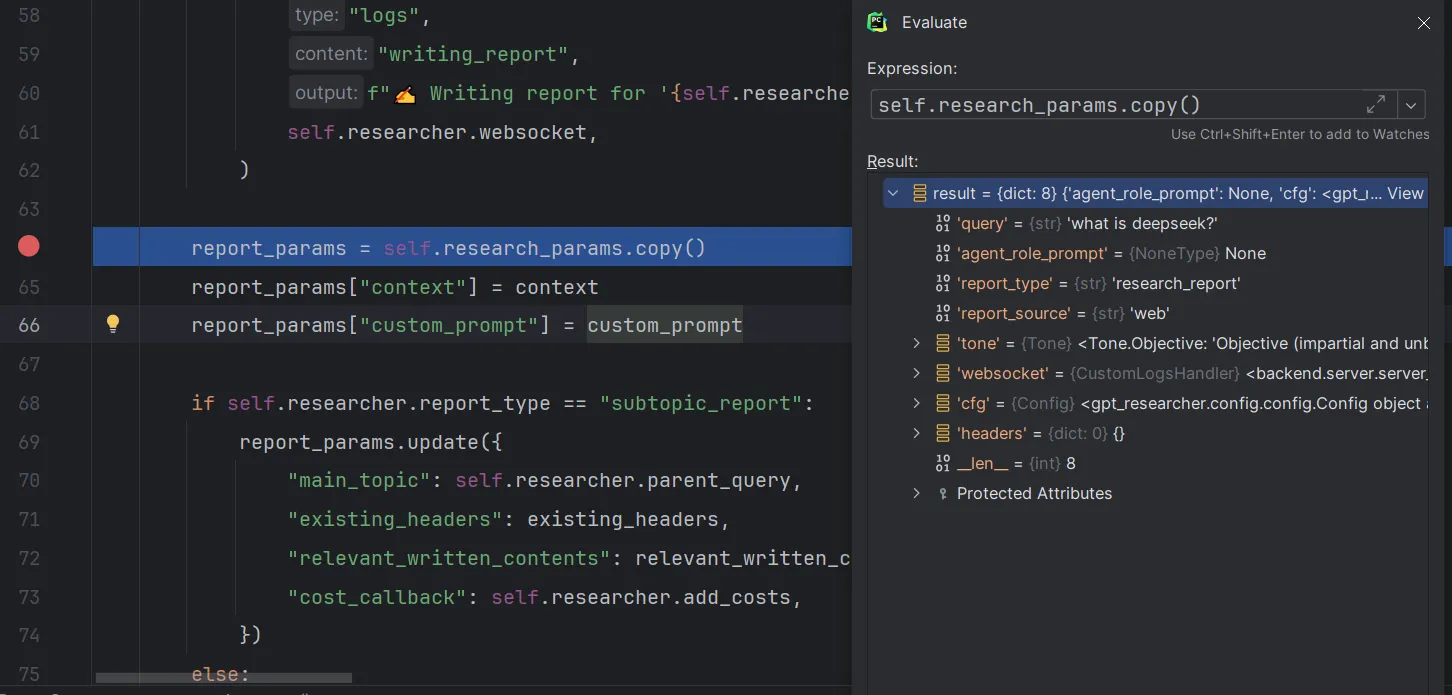
继续step over,获取report_params对象
继续step over来到关键的位置
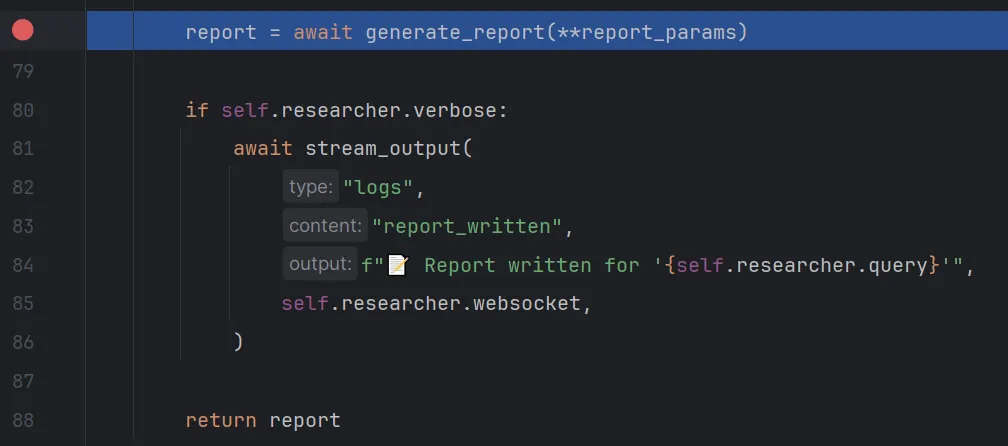
选择step into进入generate_report函数,函数解释为生成最终的报告。
选择step over来到第246行,使用Evaluate Expression功能查看一下此时content的值,格式化后是一段编写研究报告的提示词:
Information: "{context}"
---
Using the above information, answer the following query or task: "what is deepseek?" in a detailed report --
The report should focus on the answer to the query, should be well structured, informative,
in-depth, and comprehensive, with facts and numbers if available and at least 1200 words.
You should strive to write the report as long as you can using all relevant and necessary information provided.Please follow all of the following guidelines in your report:
- You MUST determine your own concrete and valid opinion based on the given information. Do NOT defer to general and meaningless conclusions.
- You MUST write the report with markdown syntax and APA format.
- Use markdown tables when presenting structured data or comparisons to enhance readability.
- You MUST prioritize the relevance, reliability, and significance of the sources you use. Choose trusted sources over less reliable ones.
- You must also prioritize new articles over older articles if the source can be trusted.
- You MUST NOT include a table of contents. Start from the main report body directly.
- Use in-text citation references in APA format and make it with markdown hyperlink placed at the end of the sentence or paragraph that references them like this: ([in-text citation](url)).
- Don't forget to add a reference list at the end of the report in APA format and full url links without hyperlinks.
-
You MUST write all used source urls at the end of the report as references, and make sure to not add duplicated sources, but only one reference for each.
Every url should be hyperlinked: [url website](url)
Additionally, you MUST include hyperlinks to the relevant URLs wherever they are referenced in the report:eg: Author, A. A. (Year, Month Date). Title of web page. Website Name. [url website](url)
- Write the report in a Objective (impartial and unbiased presentation of facts and findings) tone.
You MUST write the report in the following language: english.
Please do your best, this is very important to my career.
Assume that the current date is 2025-05-10.
然后调用一次大语言模型,获得报告
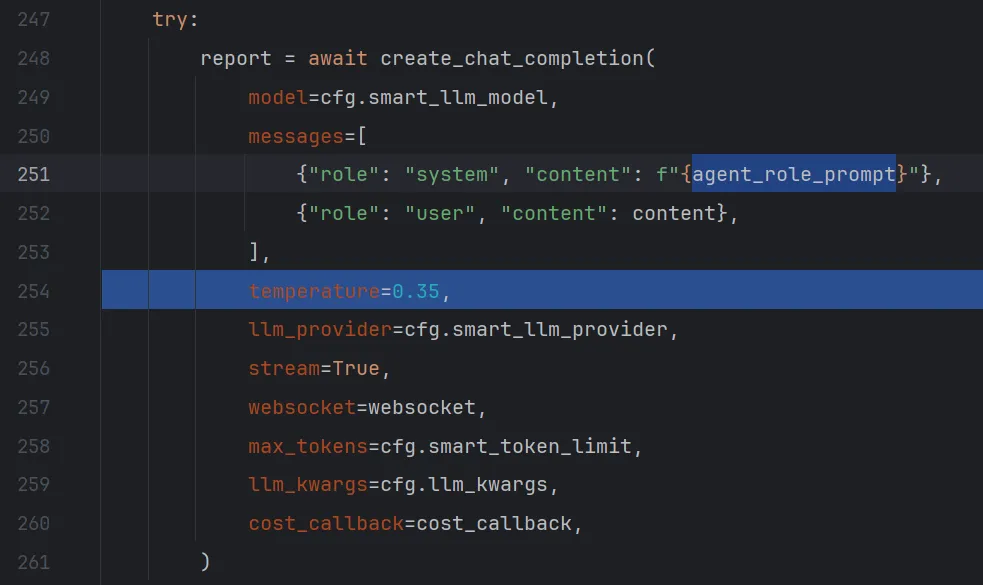
最后选择step out 逐层跳出函数

来到了/backend/server/websocket_manager.py脚本中的start_streaming函数
这段代码是一个异步方法,主要用于启动流式输出。它会初始化一些参数,调用一个名为 run_agent 的方法来生成报告,并且创建一个新的 ChatAgentWithMemory 对象用于根据报告内容回答用户的后续提问。
async def start_streaming(self, task, report_type, report_source, source_urls, document_urls, tone, websocket, headers=None, query_domains=[]):
"""Start streaming the output."""
tone = Tone[tone]
# 设置自定义的 JSON 配置文件路径,当前是默认配置 "default"
config_path = "default"
# 调用异步函数 `run_agent` 来生成报告。这个函数将会返回生成的报告对象。
report = await run_agent(task, report_type, report_source, source_urls, document_urls, tone, websocket, headers=headers, query_domains=query_domains, config_path=config_path)
# 创建一个新的 `ChatAgentWithMemory` 实例,用于处理生成的报告。这里传入报告对象 `report` 和其他配置。
# `ChatAgentWithMemory` 是一个自定义的类,它可能会结合报告内容和历史记忆进行进一步的操作。
self.chat_agent = ChatAgentWithMemory(report, config_path, headers)
# 返回生成的报告对象
return report继续step out 来到了/backend/server/server_utils.py中的handle_start_command函数,用于初始化文件路径,将report保存到文件中。

step into到generate_report_files函数看一下
该函数将生成的报告保存为pdf、docx、md三种格式的文件。
5、总结
到目前为止,该项目单智能体架构主要的程序流程我们已经研究完毕。当然,还有很多的代码细节我们没有讨论到。比如:程序是如何选择爬虫脚本的?程序是不是将整个网页内容进行一次向量化存储?等等。本篇文章仅仅作为一个debug研究项目的操作示例供大家参考。如果对大家有帮助,十分荣幸,你的点赞和收藏是我创作的最大动力。

















 1410
1410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









