







前言
集成DeepSeek到本地私有化环境,可以为企业或个人带来多方面的优势,尤其是在数据安全、定制化需求以及性能优化等方面。以下是几个关键点:
数据隐私与安全性
- 完全控制数据:通过本地部署,用户能够完全掌控自己的数据,确保敏感信息不会泄露给第三方服务提供商
- 合规性:对于需要遵守特定行业标准和法律法规(如GDPR、HIPAA等)的企业来说,本地部署可以更容易满足这些要求。
性能与效率
- 减少延迟:在本地运行AI模型可以显著减少网络传输带来的延迟,这对于实时应用至关重要
- 资源优化:根据实际需求灵活调整硬件资源,实现最佳性能表现。
定制化与灵活性
- 高度定制:可以根据企业的具体业务场景进行深度定制,开发出最适合自身需求的应用程序
- 快速迭代:本地部署使得开发团队能够更快地测试新功能和算法改进,加速产品迭代周期。
例如,在金融领域,银行可能会利用本地部署的DeepSeek模型来处理客户数据,进行风险评估或是欺诈检测,这样既能保证数据的安全性又能高效处理复杂的计算任务。又比如医疗行业,医院可以通过本地部署来分析患者的医疗记录,同时保护患者隐私,这在处理涉及个人健康信息的数据时尤为重要。
综上所述,将DeepSeek这样的先进技术集成到本地私有化环境中,不仅能提供强大的数据分析能力和智能决策支持,还能有效保障数据安全,满足个性化需求,并带来可观的成本效益。然而,在做出决定之前,应充分考虑自身的实际情况和技术储备,以确保顺利实施
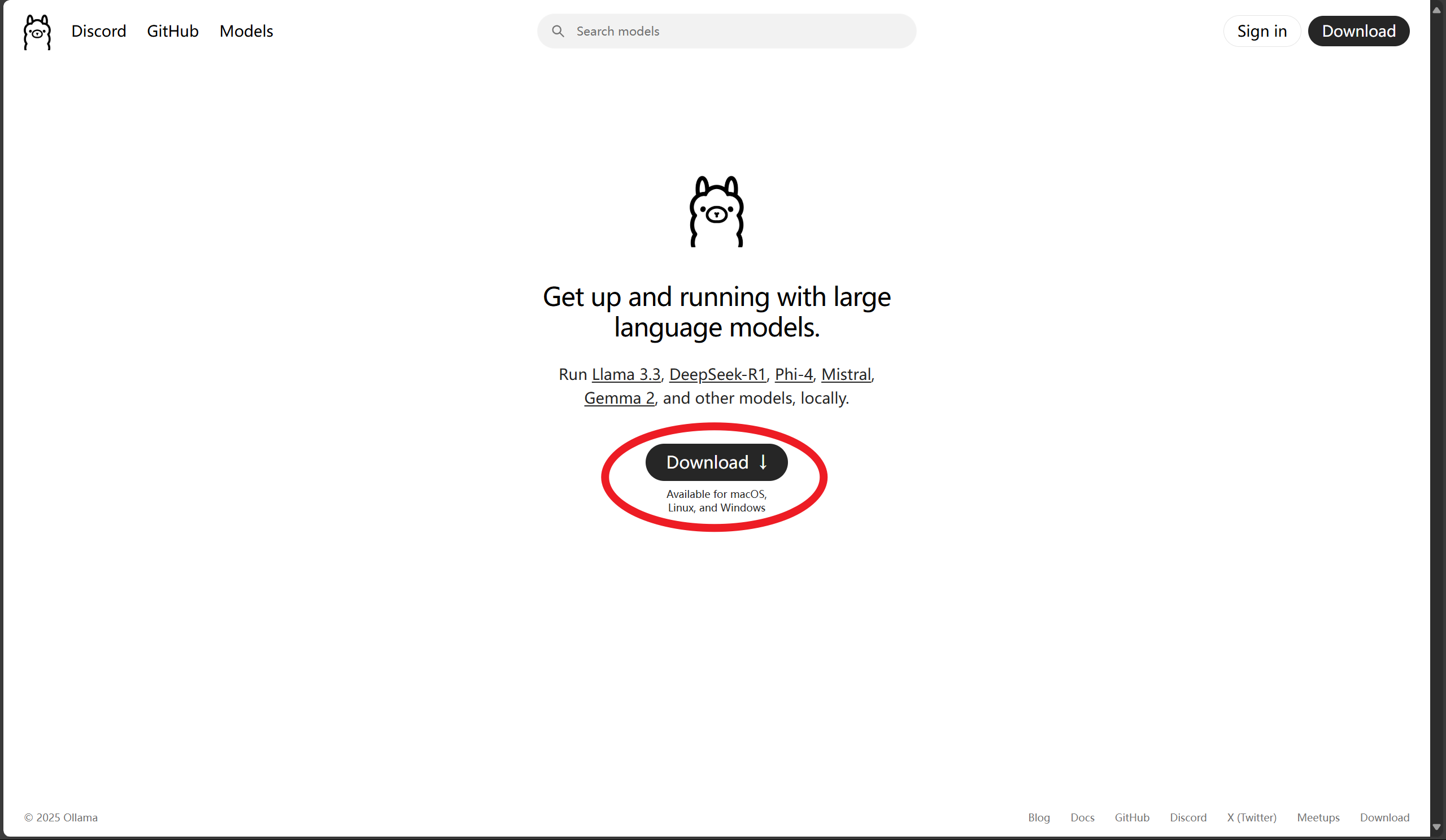
1.安装ollama
首先我们需要安装 Ollama(Ollama),它可以在本地运行和管理大模型
2.下载Deepseek
接下来点击 Ollama 官网左上方的 “Models” 按钮,会列出支持的各种模型,目前最火的 DeepSeek-R1 排在显眼位置,点击进入主题页面
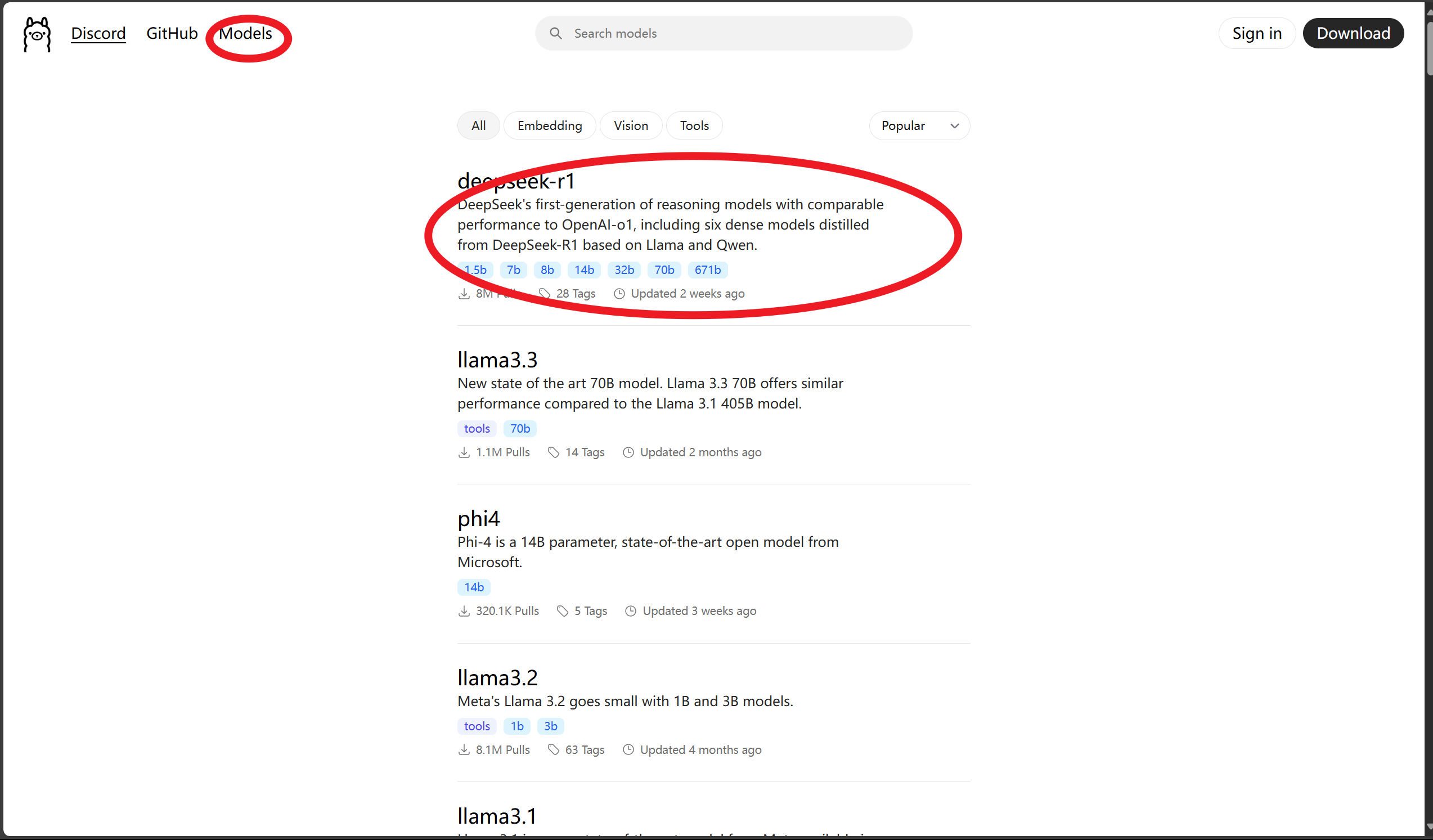
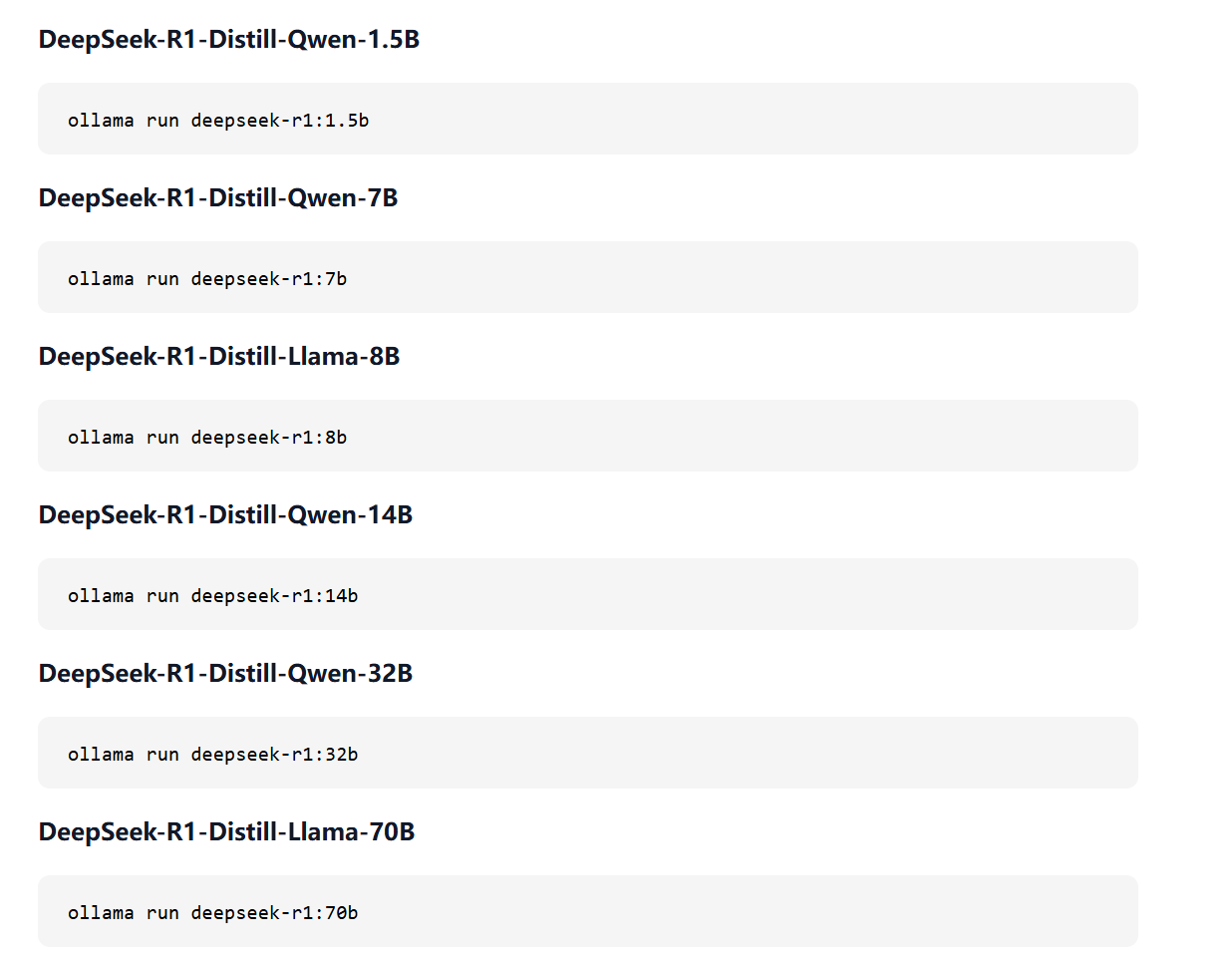
点击进去后,查看各个模型,不同模型执行的命令不同,最后部分看你选择的参数模型。
7b命令:ollama run deepseek-r1:7b
1.5b命令:ollama run deepseek-r1:1.5bDeepSeek R1 提供多个版本,参数量越大,模型通常越强大,但也需要更多的计算资源,比如 1.5B 代表有 15 亿个参数。
具体选择哪一个看你硬件设备了。
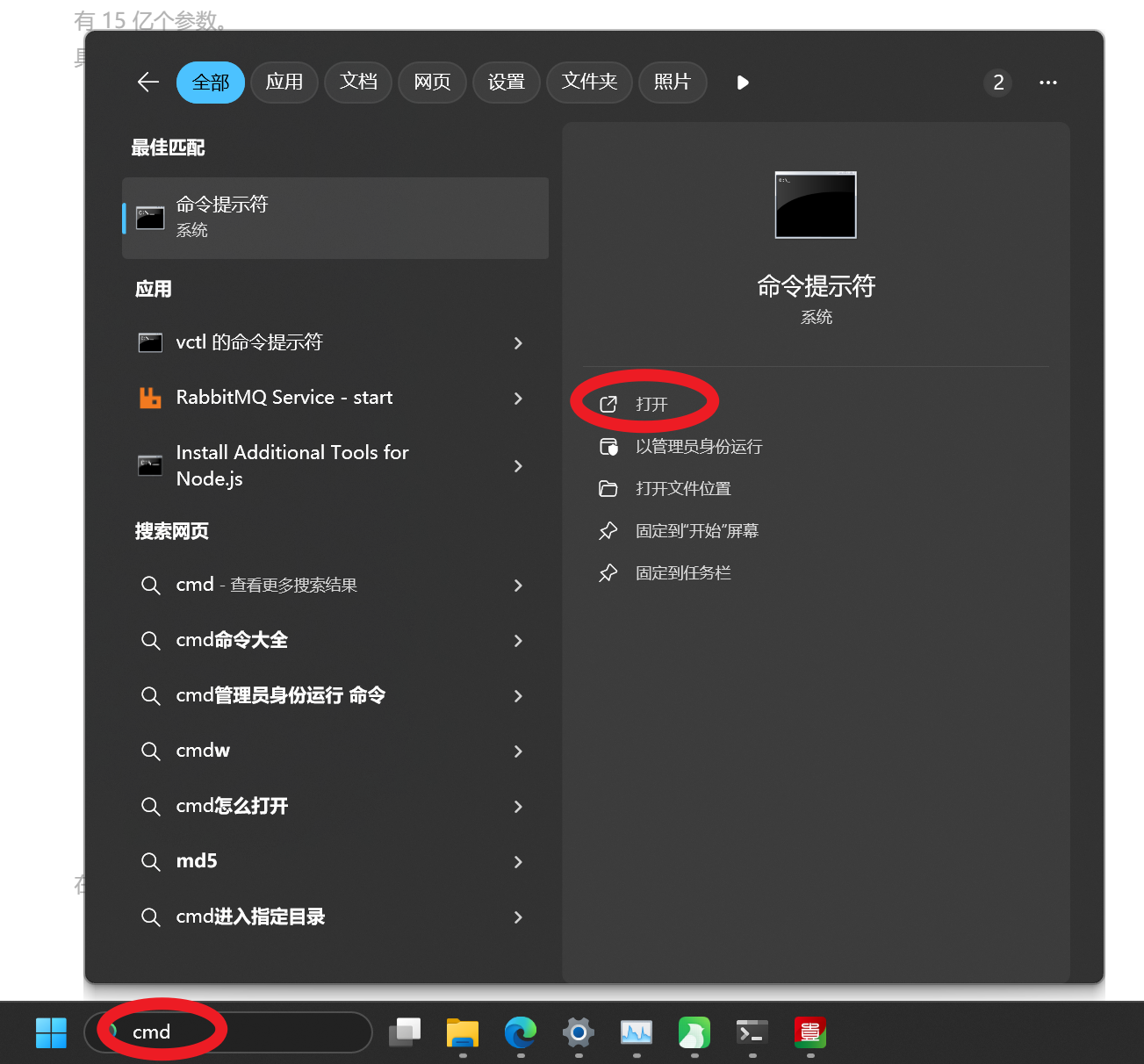
在 Windows 搜索栏输入 “cmd” 回车,唤出命令行窗口:
黏贴运行刚才复制的命令,开始下载请保持网络畅通:

网络可能比较慢,可能会出现下载失败的现象,可以切换国内镜像源
# 设置镜像地址
export OLLAMA_MIRROR="https://mirror.example.com"
# 清理旧缓存
ollama rm deepseek-r1:7b
# 重新下载
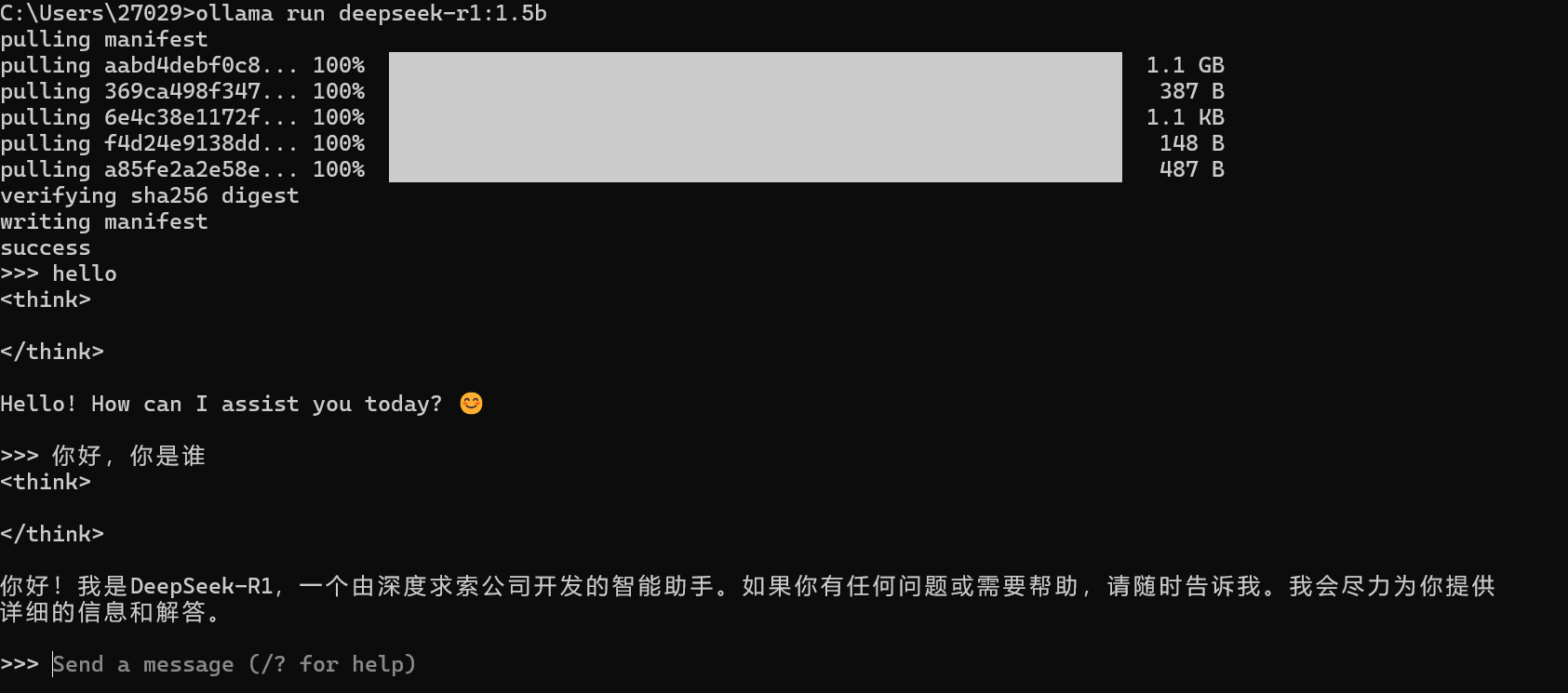
ollama run deepseek-r1:7b当界面出现 success 显示安装成功。输入 “你是谁”,看到 deepseek 的回答。
3.AnythingLLM、Open-WebUI 简介
AnythingLLM
- 定位:将本地文档或数据源整合进一个可检索、可对话的知识库,让 AI 助手 “懂你” 的资料。
主要功能:
- 文档管理:将 PDF、Markdown、Word 等多格式文件索引进系统。
- 智能检索:可基于向量数据库搜
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3217
3217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









