






假设配置:
计算资源:20-30台物理服务器,每台配置为8-16核CPU,32-64GB内存
网络资源:内部10Gbps核心网络,到互联网的冗余链路(2个100Mbps专线)
给定公司的物理服务器集群上部署的虚拟机上的服务A,公司的物理服务器集群上部署的虚拟机上的服务B,请你对每一种情况分别回答:7.1 服务A和服务B在以下几种情况下的数据交换怎么进行? 7.2 他们是否称得上是微服务治理?为什么?
<情况1 服务A部署在服务器1上的虚拟机1,服务B部署在服务器1上的虚拟机2/>/<情况2 服务A部署在服务器1上的虚拟机1,服务B部署在服务器2上的虚拟机2/> //<情况3 服务A部署在服务器1上的虚拟机1,需要把非敏感数据存储到云端/> //<情况4 服务A部署在服务器1上的虚拟机1,服务B部署在云端/>
情况1:同一服务器上的不同虚拟机服务通信
当服务A部署在服务器1的虚拟机1,服务B部署在同一服务器1的虚拟机2时,数据交换可以:
1.1 虚拟网络通信
这是最常见的通信方式,类似于办公大楼里的内部电话系统。
- VMware vSphere等虚拟化平台会创建虚拟交换机(vSwitch)
- 虚拟机各自拥有虚拟网卡(vNIC)连接到这个虚拟交换机
- 数据包不会实际离开物理服务器,但会经过虚拟化层的网络栈处理
性能特点: 延迟极低(通常<1ms),带宽高(受限于虚拟化平台而非物理网卡)零数据包丢失风险(不受外部网络波动影响)
1.2 共享内存机制
某些虚拟化平台支持VM间共享内存区域,这就像两个应用程序共用电脑上的一块"白板"。
- 虚拟化平台预留一块物理内存区域
- 多个虚拟机可以映射并访问这块内存
- 数据写入后立即对其他VM可见,无需经过网络栈
性能优势: 超低延迟(微秒级),极高吞吐量,减少CPU开销(避免了网络协议栈处理)
1.3 API调用
服务间通过HTTP/HTTPS、gRPC等协议进行通信。服务A准备请求数据,通过HTTP客户端发送请求到服务B的IP:端口,请求通过虚拟网络到达服务B,服务B处理请求并返回响应,响应通过相同路径返回到服务A
// 服务A中调用服务B的示例代码
RestTemplate restTemplate = new RestTemplate();
ResponseEntity<String> response = restTemplate.getForEntity(
"http://虚拟机2IP:端口/api/资源", String.class);
String responseBody = response.getBody();
1.4 消息队列方式,使用如RabbitMQ、Kafka等中间件实现异步通信。
- 消息队列中间件部署在第三个虚拟机或与服务共存
- 服务A发送消息到队列
- 服务B从队列订阅并消费消息类。似于两个部门通过公司内部邮件系统交流。小王不直接找小李,而是把文件放入公共邮箱,小李定期检查邮箱并处理收到的文件。
仅仅部署在不同虚拟机上并不足以构成微服务治理。更像是初步的服务隔离而非微服务。这就像把两个办公室的同事分开坐,但没有建立正式的沟通流程和规范。微服务治理通常需要包含以下几个核心要素:
-
服务注册与发现机制:通常缺失。服务地址往往是硬编码的
-
负载均衡:单一服务实例意味着无负载均衡,缺少弹性扩展,也没有熔断、限流、降级机制
-
服务监控与健康检查:通常依赖于虚拟机级别的监控,缺少服务级别的细粒度
-
API版本管理与网关:缺少统一的API管理层
情况2:不同服务器上的虚拟机服务通信
当服务A部署在服务器1的虚拟机1,服务B部署在服务器2的虚拟机2时,数据交换必须穿越物理网络:
2.1 物理网络通信
数据包从虚拟机虚拟网卡发出,经过服务器虚拟交换机转发到服务器物理网卡,通过物理网络传输到服务器2,经服务器物理网卡和虚拟交换机,最终到达虚拟机2。就像两个人在不同的建筑物内打电话。即使双方使用的是内部电话系统,通话信号也必须经过总机、地下电缆,再到达对方的位置。
性能特征::额外的网络延迟(通常为微秒到毫秒级),受物理网络带宽限制(根据题目是10Gbps),存在网络拥塞和丢包可能性
2.2 最常见的是使用HTTP/HTTPS、gRPC、自定义TCP协议等进行通信。
HTTP/REST示例:
// 服务A调用服务B的REST API
@Service
public class ServiceBClient {
private final RestTemplate restTemplate;
private final String serviceBUrl = "http://服务器2-IP:8080/api";
public ServiceBClient(RestTemplate restTemplate) {
this.restTemplate = restTemplate;
}
public DataObject getDataFromServiceB(String id) {
return restTemplate.getForObject(serviceBUrl + "/data/" + id, DataObject.class);
}
}
gRPC示例:
// 使用gRPC进行更高效的服务间通信
ManagedChannel channel = ManagedChannelBuilder
.forAddress("服务器2-IP", 9090)
.usePlaintext() // 生产环境应使用TLS
.build();
ServiceBGrpc.ServiceBBlockingStub stub = ServiceBGrpc.newBlockingStub(channel);
ServiceBResponse response = stub.getData(ServiceBRequest.newBuilder()
.setId("requestId")
.build());
2.3 跨服务器部署消息队列中间件(如Kafka)实现异步通信。
消息队列服务部署在专用服务器或集群,服务A作为生产者,服务B作为消费者,类似于两个不同城市的办公室通过总部的邮件分拣中心进行文件交换。
2.4 分布式环境中,需要服务发现机制来定位服务实例。
服务启动时向注册中心(如Eureka、Consul)注册自己,客户端查询注册中心获取目标服务的位置, 使用获得的地址进行直接通信
示例代码:
// 使用Spring Cloud服务发现
@SpringBootApplication
@EnableDiscoveryClient
public class ServiceAApplication {
public static void main(String[] args) {
SpringApplication.run(ServiceAApplication.class, args);
}
}
@Service
public class ServiceBClient {
@Autowired
private DiscoveryClient discoveryClient;
public String callServiceB() {
List<ServiceInstance> instances = discoveryClient.getInstances("SERVICE-B");
if (instances != null && !instances.isEmpty()) {
ServiceInstance serviceInstance = instances.get(0);
String url = serviceInstance.getUri().toString() + "/api/endpoint";
// 使用动态发现的URL调用服务B
return new RestTemplate().getForObject(url, String.class);
}
return null;
}
}
具有微服务治理的部分特征,但不一定是完整的微服务治理实现。 跨物理服务器通信面临更多分布式系统挑战,会自然地引入一些微服务治理所需的组件:
-
服务发现需求增强
- 不同物理服务器上的服务地址可能更频繁变化
- 更可能实现动态服务发现机制
-
网络弹性策略
- 由于跨物理服务器通信,需要考虑网络故障
- 可能实现重试、熔断等机制
-
监控和追踪
- 跨服务器通信问题排查复杂度提高
- 可能引入分布式追踪系统(如Zipkin、Jaeger)
不足:可能仍缺少完整的服务治理框架,服务仓整通常是手动配置而非自动化,横向扩展能力有限。这就像是两个不同办公楼的部门需要协作,已经建立了一些沟通渠道和规范(如公文格式、传递方式),但可能还没有完整的流程管理体系和专职的流程优化团队。
情况3:本地服务与云端存储通信
当服务A部署在本地服务器1的虚拟机1,需要将非敏感数据存储到云端时:
3.1 最常见的方式是通过云服务提供商提供的API接口存取数据。
服务A调用云服务商提供的SDK或REST API,请求通过公司的互联网专线(题中提到有专线)发送到云服务,云存储服务处理请求并返回结果。
AWS S,储示例:
// 使用AWS SDK存储数据到S3
public class CloudStorageService {
private final AmazonS3 s3Client;
public CloudStorageService() {
// 配置访问凭证
AWSCredentials credentials = new BasicAWSCredentials(
"ACCESS_KEY", "SECRET_KEY");
// 创建客户端
s3Client = AmazonS3ClientBuilder
.standard()
.withCredentials(new AWSStaticCredentialsProvider(credentials))
.withRegion(Regions.US_EAST_1)
.build();
}
3.2 用专门为云环境设计的同步工具,如AWS DataSync、Azure File Sync等。
在本地部署同步代理或网关,配置同步策略(如同步间隔、文件过滤器),代理自动将指定数据同步到云端。类似于雇佣专职快递员,他定期检查你办公室的特定文件夹,将新增或修改的文件自动送到远程仓库保存,无需你手动操作每个文件。
3.3 数据库复制与同步
如果存储的是结构化数据,可以使用数据库的复制功能。
工作原理:
- 本地数据库配置为主库
- 云端数据库配置为只读副本
- 数据变更自动从主库同步到云端副本
MySQL复制示例配置:
# 主数据库配置 (本地)
[mysqld]
server-id=1
log-bin=mysql-bin
binlog-format=ROW
# 在云端数据库执行
CHANGE MASTER TO
MASTER_HOST='本地服务器公网IP',
MASTER_USER='replication_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=4;
START SLAVE;
3.4 混合云连接服务
使用云厂商提供的专用连接服务,如AWS Direct Connect、Azure ExpressRoute。
工作原理:
- 建立从企业网络到云提供商的专用连接
- 避开公共互联网,提供更高安全性和性能
- 通过此连接传输数据,就像云服务是本地网络的延伸
通俗解释:
想象公司与云服务商建立了一条专用高速公路,只有你的公司可以使用,避开了拥挤的公共道路(互联网),提供更快速、安全的运输通道。
不是微服务治理。这种场景主要涉及的是数据管理策略,而非服务间通信的治理,因此不属于微服务治理的核心范畴。像是办公室与档案馆之间建立文件传递机制,而非不同部门之间的协作流程管理。虽然档案管理很重要,但它不是组织治理架构的核心部分。
针对"服务A存储数据到云端"这个场景:
- 不完全是微服务架构。这描述的更多是一个数据存储模式而非微服务架构。
- 单个服务使用云存储只是描述了该服务的一个技术实现细节,不足以定义整个架构。
微服务架构中,数据管理是一个重要部分,但它关注的是:每个服务管理自己的数据库(数据去中心化)+ 服务间通过API而非共享数据库进行通信
-
关注点不同
- 微服务治理关注的是"服务"之间的交互和管理
- 本场景关注的是"服务与存储"之间的交互
-
数据管理vs服务管理
- 这更适合被称为"混合云数据管理策略"
- 缺少服务发现、治理、编排等微服务核心要素
-
技术差异
- 使用的技术栈多是针对数据存储和传输
- 缺少服务网格、API网关等微服务治理组件
情况4:本地服务与云端服务通信
当服务A部署在本地服务器1的虚拟机1,服务B部署在云端时:
4.1 最基本的方式是通过互联网进行API调用。就像公司总部(本地服务)需要与远程办事处(云服务)通过公共电话网络通话。虽然可行,但面临信号质量、安全性和可靠性的挑战。
服务A通过HTTP/HTTPS协议向云端服务B的公网地址发起请求,请求通过公司的互联网出口(题中提到的100Mbps专线)到达云服务提供商。云服务提供商路由请求到服务B实例,服务B处理请求并返回响应。
**安全考虑:**必须使用TLS/SSL加密,应实施互相认证(mTLS),需要API密钥或OAuth等授权机制
示例代码:
@Service
public class CloudServiceClient {
private final RestTemplate restTemplate;
private final String cloudServiceUrl = "https://api.cloud-service.com/v1";
public CloudServiceClient(RestTemplateBuilder builder) {
// 配置超时、重试策略和SSL
this.restTemplate = builder
.setConnectTimeout(Duration.ofSeconds(5))
.setReadTimeout(Duration.ofSeconds(30))
.build();
}
public ResponseData callCloudService(RequestData request) {
HttpHeaders headers = new HttpHeaders();
// 添加认证信息
headers.set("Authorization", "Bearer " + getAuthToken());
headers.setContentType(MediaType.APPLICATION_JSON);
HttpEntity<RequestData> entity = new HttpEntity<>(request, headers);
return restTemplate.exchange(
cloudServiceUrl + "/endpoint",
HttpMethod.POST,
entity,
ResponseData.class).getBody();
}
private String getAuthToken() {
// 获取认证令牌的逻辑
// ...
}
}
4.2 使用VPN或专用网络连接建立更安全的通信通道。就像两个办公室之间安装了一条加密的专用电话线,只有授权人员才能使用,通话内容不会被外界窃听,也不受公共电话网络拥堵的影响。
在本地网络与云网络之间建立VPN隧道或专线连接,流量通过加密隧道传输,避开公共互联网,服务A和服务B可以像在同一内部网络一样通信
4.3 部署API网关来管理与云服务的通信。
在本地部署API网关(如Kong、NGINX)。本地服务A通过API网关进行通信,API网关处理认证、限流、缓存等横切关注点,API网关将请求转发到云端服务B
+---------------+ +------------+ 互联网 +-------------+
| 本地服务A |----->| API网关 |-------------->| 云端服务B |
| (虚拟机1) |<-----| (本地) |<--------------| (云服务商) |
+---------------+ +------------+ +-------------+
示例配置(NGINX作为API网关):
server {
listen 80;
server_name api.internal.company.com;
location /service-b/ {
# 限流配置
limit_req zone=api burst=5;
# 添加认证头
proxy_set_header Authorization "Bearer $internal_token";
# 转发到云服务
proxy_pass https://api.cloud-service.com/;
proxy_ssl_verify on;
# 缓存配置
proxy_cache api_cache;
proxy_cache_valid 200 10m;
}
}
4.4 使用跨越本地和云端的消息队列系统实现异步通信。类似于两地办公室使用自动同步的邮箱系统。你在总部放入的邮件会自动复制到分部的邮箱中,即使两地网络暂时断开,也能在恢复后自动完成同步。
部署支持混合云模式的消息队列系统(如RabbitMQ、Kafka),本地和云端各自有队列节点。节点间通过安全通道进行消息同步, 服务A发布消息到本地队列,自动同步到云端,云端服务B从本地队列的云端镜像消费消息
是否称得上微服务治理?部分是,但需要配合其他治理组件才能构成完整的微服务治理,可以视为微服务治理的一部分。
-
为什么是:发现需要能识别云端和本地服务,需要统一的配置管理跨越不同环境,监控系统需要整合本地和云端数据
-
真正的微服务,就像是一家公司在两个城市设有办公室,为了有效协作,建立了统一的通信标准、共享的项目管理系统和规范的工作流程。不同办公室的团队可以无缝协作,就像在同一个办公室一样。如果实施了以下组件,则可视为微服务治理:
- 统一的服务注册中心(如Eureka、Consul跨云部署)
- 边缘服务网关(处理进出云环境的流量)
- 分布式追踪系统(如Zipkin、Jaeger)
- 自适应负载均衡(感知网络状况)
- 断路器模式(处理云服务不可用情况)
真正的微服务的典型治理架构
+-------------------+ +-------------------+
| 本地环境 | | 云环境 |
| | | |
| +-------------+ | | +-------------+ |
| | 服务注册中心 |<-----专线/VPN连接------>| | 服务注册中心 | |
| +-------------+ | | +-------------+ |
| ^ | | ^ |
| | | | | |
| v | | v |
| +-------------+ | | +-------------+ |
| | 本地服务A | | | | 云端服务B | |
| +-------------+ | | +-------------+ |
| ^ | | ^ |
| | | | | |
| v | | v |
| +-------------+ | | +-------------+ |
| | API网关 |<-----专线/VPN连接------>| | API网关 | |
| +-------------+ | | +-------------+ |
+-------------------+ +-------------------+
最佳实践
-
服务通信策略选择
- 同一服务器上的虚拟机:优先考虑共享内存或虚拟网络通信
- 不同服务器的虚拟机:利用高速内部网络,配合轻量级协议如gRPC
- 混合云环境:专线连接、消息队列等更可靠的通信方式
-
合理的服务发现机制
// 使用服务发现而不是硬编码地址 @LoadBalanced @Bean public RestTemplate restTemplate() { return new RestTemplate(); } @Service public class ServiceCaller { private final RestTemplate restTemplate; public ServiceCaller(RestTemplate restTemplate) { this.restTemplate = restTemplate; } public Response callService(String serviceId, String endpoint) { // 使用服务ID而非具体IP地址 return restTemplate.getForObject( "http://" + serviceId + "/" + endpoint, Response.class); } } -
弹性通信模式
- 实施断路器模式(Circuit Breaker)
- 添加超时和重试策略
- 实现请求缓存减少重复调用
@HystrixCommand(fallbackMethod = "fallbackMethod", commandProperties = { @HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "1000"), @HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "5"), @HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "50"), @HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds", value = "5000") }) public String callRemoteService() { return restTemplate.getForObject("http://remote-service/api/data", String.class); } public String fallbackMethod() { return "Fallback response"; } -
统一监控和追踪
- 实施分布式追踪(如Zipkin、Jaeger)
- 集中式日志管理(ELK栈)
- 服务健康监控和告警机制
// 添加追踪ID传播 @Bean public RestTemplate restTemplate(RestTemplateBuilder builder) { return builder.additionalInterceptors( (request, body, execution) -> { request.getHeaders().add( "X-Trace-ID", MDC.get("traceId")); return execution.execute(request, body); }).build(); } -
混合云最佳实践
- 使用云服务商提供的混合连接服务
- 实施一致的身份认证和授权机制
- 采用边缘计算模式减少数据传输
-
服务粒度与职责划分
- 基于业务能力而非技术层次划分服务
- 遵循"单一职责原则"确定服务边界
- 避免服务之间的紧耦合依赖
微服务
核心概念:微服务是一种架构风格,将应用程序拆分为松耦合的、可独立部署的小型服务单元。关键在于系统的架构设计是否符合微服务的原则,而不仅仅是使用了某种特定工具,或是 服务 AND/OR 数据部署位置。微服务的核心特征包括:
- 服务自治:每个服务可以独立开发、部署和扩展
- 边界清晰:围绕业务能力构建,有明确的职责边界
- 分布式通信:服务之间通过轻量级协议通信
- 去中心化:分散式的数据管理和治理策略。技术选型自治,避免单一技术栈限制
- 单一职责:每个服务专注于解决一个特定的业务问题
- 独立部署:可以独立开发、部署和升级
- 故障隔离:一个服务的失败不会导致整个系统崩溃
- 自动化:依赖CI/CD实现快速迭代和部署
常见误区
-
“虚拟机隔离就是微服务” 应用拆分到不同虚拟机,就实现了微服务
- 实际:微服务是一种架构风格,需要服务独立部署、自治和解耦,而不仅是物理隔离
-
用REST API实现服务间通信就实现了微服务
- 实际:微服务通信需要考虑发现、弹性、监控等多方面,不只是简单的API调用
-
“同一数据中心内不同服务器上服务足够可靠,不需要严格的服务治理,比如API网关”
- 实际:即使在同一数据中心,服务故障、网络延迟等问题也会发生
-
“云原生等同于微服务” 将应用部署到云端就等同于实现了微服务
- 实际:云原生是一种部署和运维理念,微服务是一种架构风格,二者可结合但不等同
服务部署位置 和 是否微服务 没有关系
微服务与服务部署环境(本地或云端)没有必然联系。微服务完全可以全部部署在本地,也可以全部部署在云端,或者混合部署。
微服务与数据存储位置(本地或云端)没有必然联系。单纯从"本地服务存储数据到云端"这个操作本身,不足以判断这是微服务架构,见上面情况3:云数据管理
关键是服务间的关系模式(松耦合、API通信、自治),而非部署位置。可以
- 全本地部署:所有微服务都在本地数据中心运行,这仍然是微服务架构
- 全云部署:所有微服务都在云环境运行
- 混合部署:部分在本地,部分在云端
API网关,服务网格,注册中心等工具 和 是否微服务 没有关系
使用服务网格或API网关并不自动使系统成为微服务架构,反之亦然。这些是不同的概念:
微服务是一种架构风格。
服务网格是一种基础设施层,用于处理服务间通信,提供服务发现、负载均衡、故障恢复、指标收集等功能。
API网关是一种服务,作为系统的单一入口点,负责请求路由、组合、协议转换等。
微服务架构可以不使用服务网格或API网关,尤其是在早期或简单场景下。当微服务数量增加,复杂度提高时,服务网格和API网关能帮助管理这种复杂性。单体应用也可以使用API网关,尤其是需要对外暴露API时
服务注册中心是实现微服务架构的重要工具,但不是唯一标准:
- 使用服务注册中心不一定就是微服务:单体应用也可以使用服务注册中心进行服务发现。
- 微服务不一定必须使用统一的服务注册中心:虽然大多数微服务架构会使用服务注册中心,但也可以使用其他方式实现服务发现,如DNS、配置文件等。
- 服务注册中心的实现方式多样:不仅限于Spring Cloud Eureka或Kubernetes,还有Consul、ZooKeeper、etcd等多种实现。
- 单体应用也可以模拟服务注册中心的功能:通过配置文件或数据库存储服务地址信息,也能实现类似的服务发现功能,只是不够灵活和自动化。
1. 服务注册与发现
是微服务架构的基础功能,想象一个购物网站,有用户服务、商品服务和订单服务。在传统架构中,这些服务之间的调用关系是硬编码的:这种方式有个问题:如果订单服务的IP地址变了,或者部署了多个实例,代码就需要修改。
// 传统方式:硬编码服务地址
String orderServiceUrl = "http://192.168.1.100:8080/orders";
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(orderServiceUrl + "/create"))
.POST(HttpRequest.BodyPublishers.ofString(orderData))
.build();
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
而使用服务注册与发现后:
// 使用服务注册中心方式
// 1. 服务提供者(订单服务)在启动时注册自己
@SpringBootApplication
@EnableEurekaClient // 标记这是一个Eureka客户端,会自动注册到Eureka服务器
public class OrderServiceApplication {
public static void main(String[] args) {
SpringApplication.run(OrderServiceApplication.class, args);
}
}
// 2. 服务消费者(商品服务)调用订单服务
@Service
public class ProductService {
@Autowired
private RestTemplate restTemplate; // 这个RestTemplate已被配置为使用负载均衡
public void createOrder(Order order) {
// 直接使用服务名称而不是IP地址
String result = restTemplate.postForObject("http://ORDER-SERVICE/orders/create", order, String.class);
}
}
这里的关键变化是:
- 服务提供者(订单服务)在启动时向服务注册中心注册自己的位置和状态
- 服务消费者(商品服务)不再使用固定IP地址,而是通过服务名称(“ORDER-SERVICE”)来访问
- 服务注册中心负责维护服务名称到实际服务实例IP地址的映射
- 如果有多个订单服务实例,还可以自动实现负载均衡
这就是"服务消费"的含义:商品服务"消费"了订单服务提供的API,消费方不需要知道提供方的具体位置。
1.1 服务注册与发现的工作原理
服务注册:
- 服务启动时向注册中心注册自己的位置(IP地址、端口)和健康状态
- 定期发送心跳包更新自己的状态
- 服务关闭时从注册中心注销自己
服务发现:
- 服务需要调用其他服务时,向注册中心查询目标服务的位置
- 注册中心返回可用的服务实例列表
- 服务选择一个实例进行调用(通常结合负载均衡策略)
健康监测:
- 注册中心定期检查已注册服务的健康状态
- 移除不健康的服务实例,防止请求被路由到故障节点
常见的服务注册与发现工具:
- Eureka:Netflix开发的服务发现框架,Spring Cloud集成
- Consul:HashiCorp开发的服务发现和配置工具
- ZooKeeper:Apache的分布式协调服务,可用于服务发现
- etcd:CoreOS开发的分布式键值存储,Kubernetes使用它实现服务发现
- Kubernetes Service:Kubernetes内置的服务发现机制
3. API网关
3.0 谁是客户端?
客户端本质上是任何发起API请求的实体**,包括:
- 浏览器和移动应用(终端用户)
- 其他微服务(服务对服务)
- 外部系统(系统对系统)
- 终端用户客户端
- 运行JavaScript应用(如React/Angular/Vue)的浏览器
- 手机的移动APP
- 使用Electron构建的桌面软件。Electron用Node.js(作为后端)和Chromium的渲染引擎(作为前端)完成跨平台的桌面GUI应用程序的开发。
- 服务对服务客户端
- 内部微服务:系统内一个微服务调用另一个微服务的API
- 后台:定时任务、数据处理作业等调用其他服务
- API网关:前后端分离时,作为前端请求的代理,调用后端多个微服务
- 系统对系统客户端:外部合作系统,第三方集成如支付服务
混合云下,客户端有更特殊的含义:
-
跨环境客户端:云上服务访问本地数据,如云端分析服务请求访问本地患者数据,本地服务访问云资源,如本地应用上传数据到云存储
-
边缘计算客户端
- 边缘服务:部署在网络边缘的服务,同时与云和本地环境通信
- CDN客户端:内容分发网络接入点
- 特殊场景客户端
- 数据同步组件:负责在本地与云端同步数据的专用服务
- 混合身份提供者:跨环境的认证授权客户端
AWS S3代码示例,有两层客户端关系:
AmazonS3客户端:是AWS SDK提供的客户端,用于调用AWS S3服务的APICloudStorageService本身:对于使用它的其他服务来说,它也是一个客户端组件
public class CloudStorageService {
private final AmazonS3 s3Client;
// ...
public void uploadFile(String bucketName, String key, File file) {
s3Client.putObject(bucketName, key, file);
}
}
3.1 负载均衡器和API网关
负载均衡器的定位与作用
-
服务端组件 部署在服务提供方(被访问系统)侧,而非消费方。其核心目标是分散请求压力,防止后端服务器过载。
-
流量分发机制 当消费方发起请求时,流量首先到达负载均衡器。负载均衡器根据预设算法(如轮询、加权、最少连接等)将请求分发到多个后端服务器实例。例如,若API网关有3个实例,负载均衡器会将请求均匀分配到这3个实例,避免单点过载。
-
扩展性与容灾 水平扩展:通过增加服务器实例,配合负载均衡实现无缝扩容。故障转移:自动剔除宕机节点,将流量导向健康实例。
“负载均衡器保护消费方” 错误:消费方无需处理高并发,负载均衡器保护的是服务提供方。例外:若消费方是服务器(如服务间调用),则调用方也可能需要负载均衡。
3.2 API网关功能
万字讲解API网关的来龙去脉【珍藏】https://developer.aliyun.com/article/847511
用更加平白直接的话来说:假设你内部系统是多个微服务,而且你的系统不打算开放给外部人用,那么你可以选择仅仅使用服务注册中心,不用api网关。仅仅当需要去集成外部系统,也就是说把自己的api接口给别人用的时候才需要api网关(也可以一个个手动配,但是麻烦) Api网关类似于dns网关,是一张look up table,根据他,你能实现:只记住服务名,不用记住那个地址。除了look up table之外, API网关还提供负载均衡、认证授权、限流等高级功能。
补充:
- 纯内部系统,在以下情况也可能需要API网关:微服务数量超过20-30个时,集中管理会更方便,需要统一认证授权机制时,希望集中监控和控制所有API流量时
2.在完整的微服务架构中,通常服务注册中心与API网关配合使用的:服务注册中心:记录"哪些服务在哪里"(服务发现)API网关:决定"谁能访问什么服务"(请求路由+控制)
请求路由:
- 根据请求的URL、参数或头信息将请求路由到合适的后端服务
- 支持动态路由配置,无需修改代码即可调整路由规则
API组合:
- 聚合多个微服务的调用,减少客户端请求次数
- 例如,商品详情页可能需要调用商品服务、评论服务和推荐服务,API网关可以聚合这些调用
协议转换:
- 支持不同的协议和API风格,如REST、GraphQL、gRPC等
- 在前端友好的协议和后端高效的协议之间进行转换
认证授权:
- 集中处理身份验证和授权逻辑
- 支持多种认证机制,如OAuth、JWT、API密钥等
流量控制:
- 实现请求限流、熔断、超时控制等机制
- 防止后端服务过载,提高系统弹性
监控与分析:
- 收集API调用的指标和日志
- 提供实时监控和分析能力,帮助发现问题和优化性能
缓存:
- 缓存频繁请求的结果,减少对后端服务的调用
- 支持多级缓存策略,平衡性能和一致性
常见的API网关产品:
- Kong:基于Nginx的开源API网关
- Spring Cloud Gateway:Spring生态的API网关
- Zuul:Netflix开发的API网关
- Apigee:Google的API管理平台
- AWS API Gateway:亚马逊云的API管理服务
使用场景:
- 外部访问内部服务:作为系统对外的统一入口,隐藏内部实现细节,提供安全控制。
- 内部服务间通信:在某些需要统一管控的场景下,内部服务之间的通信也可以通过API网关进行。
- 调用外部服务:系统调用外部API时,可以通过API网关进行,便于集中管理认证信息、实现缓存等。
- 前后端分离:在前后端分离架构中,前端应用通过API网关访问后端服务。
- 多渠道服务:支持Web、移动端、合作伙伴等不同渠道的API需求。
API网关的核心价值在于:
- 请求路由:将请求转发到正确的服务
- 协议转换:支持不同的API协议和格式
- 安全控制:身份验证、授权、加密等
- 流量管理:限流、熔断、监控等
- 统一入口:简化客户端与后端的交互
万字讲解API网关的来龙去脉【珍藏】https://developer.aliyun.com/article/847511
这篇文章存在表述上的混淆!!我来明确解释一下:
去中心化架构:微服务之间通过服务注册中心直接进行通信,每个服务都可以被其他服务直接调用。优点是性能高,缺点是缺乏统一管控。
中心化架构:所有的API调用都必须通过API网关这个中心点,网关负责路由和处理所有请求。优点是统一管控,缺点是性能瓶颈。
微服务架构本身是去中心化的(服务间直接通信),但当需要对外提供服务时,通常会使用API网关作为中心化的入口点。所以这两种模式实际上是可以共存的:内部服务之间:使用服务注册中心进行去中心化的直接通信。外部访问内部服务:通过API网关进行中心化的访问控制
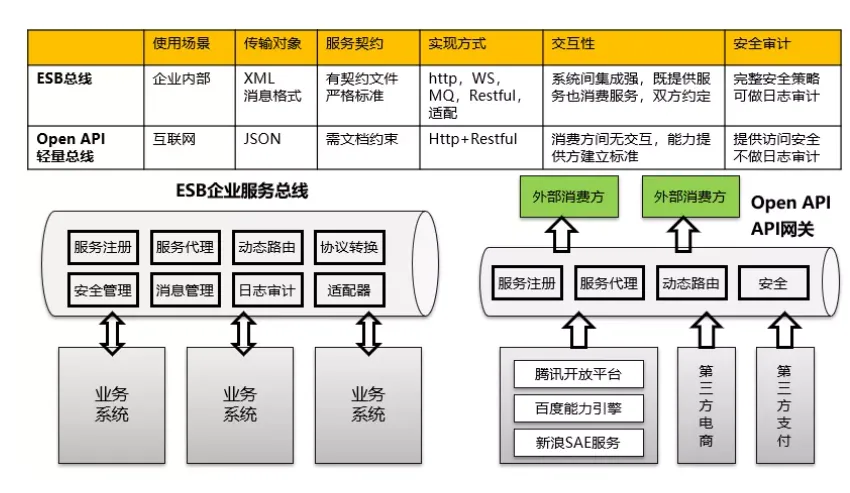
这张图展示了两种不同的集成架构模式对比:
ESB总线:主要用于企业内部系统集成
- 使用XML消息格式
- 采用严格标准化的通信协议(HTTP, WS, MQ, Restful等)
- 系统间需要紧密耦合,双方约定接口
- 提供完整的安全审计机制
Open API轻量总线:面向互联网场景
- 使用JSON数据格式
- 采用Http+Restful方式
- 通信更灵活,能够提供方满足标准
- 安全机制更侧重访问控制
图片下半部分展示了这两种架构的具体实现方式:
- 左侧是ESB企业服务总线:连接内部业务系统,提供服务注册、服务代理、动态路由等功能
- 右侧是Open API网关:连接外部消费方和提供方,包含服务注册、服务代理、动态路由和安全管理功能
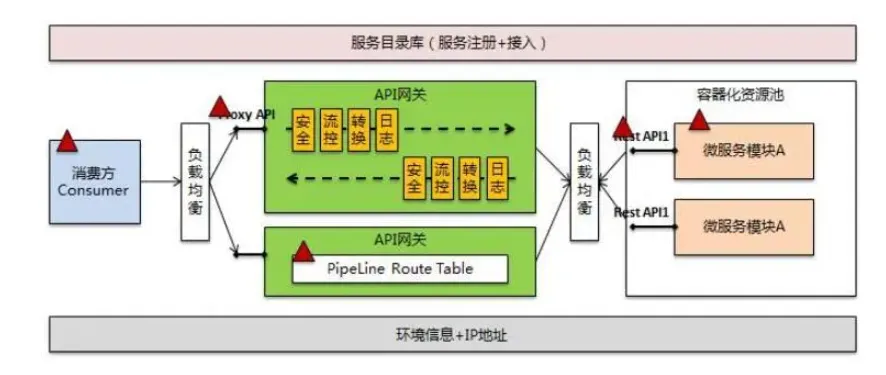
上面这张图展示了API网关的详细工作流程:
- 左侧的消费方(Consumer)通过负载均衡器访问API网关
- API网关提供多种功能模块:安全、流控、转换、日志等
- API网关将请求路由到右侧的微服务实例
- 整个过程基于环境信息和IP地址进行控制
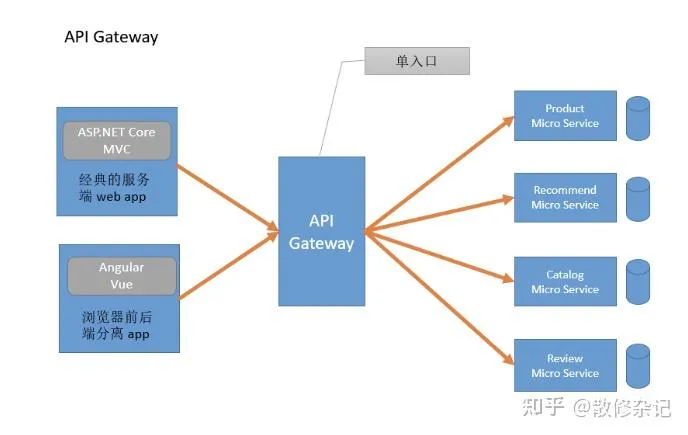
上面这张图展示了API网关的三种典型场景:
- 场景1:API网关直接连接到单个微服务实例的负载均衡
- 场景2:API网关通过负载均衡器(LB)连接到多个相同微服务实例
- 场景3:API网关通过Kubernetes(K8s)连接到微服务容器组
- 每个场景都展示了不同的网络地址和路由方式
3.3 API网关的不同模式
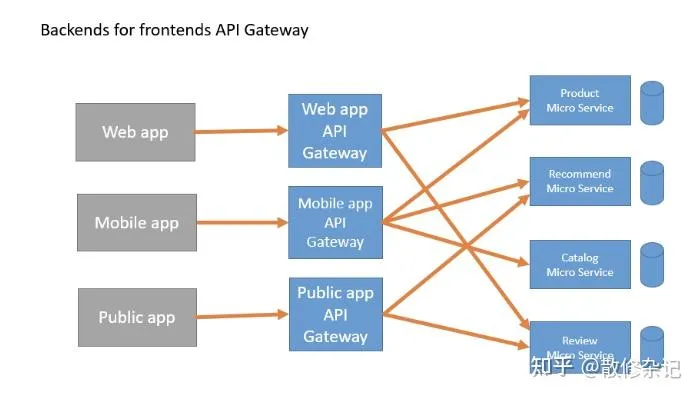
这张图展示了"前端的后端"(Backend For Frontend)模式:
- 左侧是不同类型的客户端应用:Web应用、移动应用、公共应用
- 中间是为每种前端专门定制的API网关
- 右侧是共享的微服务:产品服务、推荐服务、目录服务、评论服务。每个网关可以连接到任何需要的微服务
前端的后端(BFF)模式为特定的前端应用提供定制化的API接口。
工作原理:
- 为每种客户端类型(Web、移动、IoT等)创建专门的API层
- 这些API层调用后端微服务,并根据客户端需求聚合和转换数据
- 减少前端与所有微服务直接交互的复杂性
优势:
- 针对客户端优化的数据结构,减少不必要的数据传输
- 简化前端开发,前端开发者只需要与一个统一的API交互
- 不同客户端可以有不同的API演化路径
实现示例:
假设有一个电商应用,有Web和移动两个客户端:
// Web端BFF
@RestController
@RequestMapping("/web/products")
public class WebProductController {
@Autowired
private ProductService productService;
@Autowired
private ReviewService reviewService;
@GetMapping("/{id}")
public WebProductDetailDTO getProductDetail(@PathVariable Long id) {
Product product = productService.getProduct(id);
List<Review> reviews = reviewService.getTopReviews(id, 5); // Web端只需要5条评论
return new WebProductDetailDTO(product, reviews);
}
}
// 移动端BFF
@RestController
@RequestMapping("/mobile/products")
public class MobileProductController {
@Autowired
private ProductService productService;
@GetMapping("/{id}")
public MobileProductDTO getProductDetail(@PathVariable Long id) {
Product product = productService.getProduct(id);
// 移动端返回轻量级数据,忽略评论,添加移动端特有字段
return new MobileProductDTO(product.getId(), product.getName(),
product.getPrice(), product.getImageUrl());
}
}
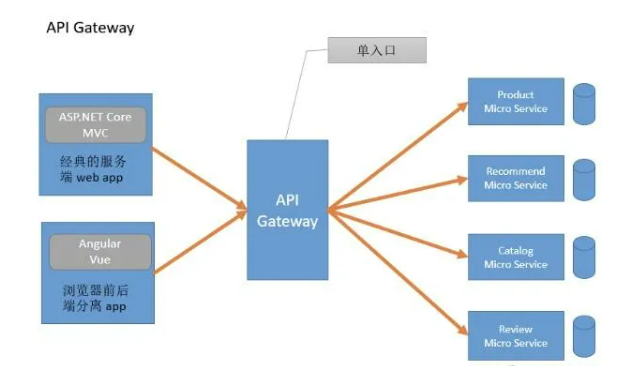
这张图展示了更简化的API网关架构:
- 左侧是不同类型的前端应用:ASP.NET Core MVC和Angular/Vue应用
- 中间是统一的API网关,作为单一入口点
- 右侧是各种微服务:产品、推荐、目录、评论等
3.4 服务网格(Service Mesh)
服务网格是管理服务间通信的专用基础设施层,通常通过一组轻量级网络代理(Sidecar)与应用代码一起部署。
核心组件:
- 数据平面:由与每个服务实例一起部署的Sidecar代理组成,负责处理服务间通信
- 控制平面:集中配置和管理所有Sidecar代理
主要功能:
- 服务发现与负载均衡
- 加密通信(mTLS)
- 请求重试和超时控制
- 断路器模式实现
- 分布式追踪
- 流量控制和路由
- A/B测试和金丝雀发布
与API网关的区别:
- API网关主要处理外部流量(南北向流量)
- 服务网格主要处理内部服务间通信(东西向流量)
常见实现:
- Istio:最受欢迎的开源服务网格,使用Envoy作为数据平面
- Linkerd:轻量级服务网格,专注于简单性和能性
- Consul Connect:HashiCorp的服务网格解决方案
4. 服务间通信模式
4.1 同步通信(请求-响应)服务A直接调用服务B的API并等待响应:简单直接,易于实现和理解。增加服务间耦合,可能导致调用链变长
// 同步调用示例
String result = restTemplate.getForObject("http://user-service/users/{id}", String.class, userId);
4.2 异步通信(消息队列):服务A发送消息到消息队列,服务B订阅并消费消息:解耦服务,提高系统弹性,支持削峰填谷。增加系统复杂性,需要处理消息重复和顺序问题
// 生产者示例
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendOrderEvent(Order order) {
kafkaTemplate.send("order-events", objectMapper.writeValueAsString(order));
}
// 消费者示例
@KafkaListener(topics = "order-events")
public void processOrderEvent(String orderJson) {
Order order = objectMapper.readValue(orderJson, Order.class);
// 处理订单事件
}
4.3 事件驱动架构:是一种设计模式,其中组件间通过事件的生产和消费进行通信,而不是直接调用。
核心组件:
- 事件生产者:检测状态变化并生成事件
- 事件处理器:接收和处理事件
- 事件总线/消息代理:传递事件的中间件
实现方式:
-
发布-订阅模式:
- 多个消费者可以订阅同一事件
- 事件发布者不需要知道谁会消费事件
-
事件溯源:
- 将状态变化存储为事件序列
- 通过重放事件重建系统状态
常见场景:
- 订单处理流程:订单创建→支付处理→库存更新→物流安排
- 用户活动跟踪:登录、浏览、购买等用户行为作为事件记录
- IoT数据处理:设备传感器数据作为事件流处理
实现示例:
// 生产者
@Service
public class OrderService {
@Autowired
private ApplicationEventPublisher eventPublisher;
public Order createOrder(OrderRequest request) {
Order order = // 创建订单逻辑
// 发布订单创建事件
eventPublisher.publishEvent(new OrderCreatedEvent(order));
return order;
}
}
// 消费者
@Component
public class InventoryEventHandler {
@EventListener
public void handleOrderCreated(OrderCreatedEvent event) {
// 更新库存逻辑
}
}
4.4 批处理数据传输:服务间定期批量传输数据,而不是实时交互:减少网络负载,提高效率。实时性差
5. 监控与可观测性
监控和可观测性至关重要,因为问题可能出现在多个分布式组件之间的交互中。
三大支柱:
-
日志(Logs):
- 记录事件和状态变化
- 集中式日志收集(ELK Stack, Graylog等)
- 结构化日志格式,便于搜索和分析
-
指标(Metrics):
- 量化系统行为和性能
- 关键指标:请求率、错误率、响应时间、资源使用率
- 时序数据库存储(Prometheus, InfluxDB等)
- 可视化仪表板(Grafana等)
-
追踪(Traces):
- 跟踪请求在服务间的完整路径
- 识别性能瓶颈和错误源
- 分布式追踪系统(Jaeger, Zipkin等)
实现策略:
// 使用Micrometer收集指标
@Configuration
public class MetricsConfig {
@Bean
MeterRegistryCustomizer<MeterRegistry> metricsCommonTags() {
return registry -> registry.config().commonTags("application", "order-service");
}
}
// 记录请求处理时间
@RestController
public class OrderController {
private final MeterRegistry meterRegistry;
public OrderController(MeterRegistry meterRegistry) {
this.meterRegistry = meterRegistry;
}
@GetMapping("/orders/{id}")
public Order getOrder(@PathVariable Long id) {
Timer.Sample sample = Timer.start(meterRegistry);
try {
return orderService.findById(id);
} finally {
sample.stop(meterRegistry.timer("order.get", "id", id.toString()));
}
}
}
告警策略:
- 设置多级阈值(警告、严重、紧急)
- 避免警报疲劳(过多不必要的警报)
- 实现自动化响应(例如自动扩展、重启)
6. 容器化与编排
提供了一致的开发和运行环境。
容器技术:
- 将应用及其依赖打包为标准化单元
- 提供隔离但资源开销低于虚拟机
- Docker是最常用的容器技术
容器编排:
- 自动化容器的部署、扩展和管理
- 处理容器间的服务发现和负载均衡
- 提供自我修复能力(重启失败的容器)
Kubernetes功能:
- Pod管理:Pod是最小部署单位,可包含一个或多个容器
- 服务发现:通过Service抽象提供稳定的网络端点
- 自动扩缩容:根据负载自动调整Pod数量
- 声明式API:描述期望状态,Kubernetes负责实现
- 滚动更新:无停机部署新版本
- 配置管理:通过ConfigMap和Secret管理配置
- 存储编排:支持不同类型的持久存储
使用示例:
# 部署一个微服务的Kubernetes配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: order-service
spec:
replicas: 3 # 运行3个实例
selector:
matchLabels:
app: order-service
template:
metadata:
labels:
app: order-service
spec:
containers:
- name: order-service
image: mycompany/order-service:v1.2
ports:
- containerPort: 8080
resources:
limits:
cpu: "0.5"
memory: "512Mi"
readinessProbe: # 健康检查
httpGet:
path: /health
port: 8080
---
apiVersion: v1
kind: Service
metadata:
name: order-service
spec:
selector:
app: order-service
ports:
- port: 80
targetPort: 8080
type: ClusterIP
容器 vs 虚拟机:
- 容器是一种轻量级的隔离技术,共享宿主机的操作系统内核
- 虚拟机是一种重量级的隔离技术,每个虚拟机都有自己的操作系统
- 容器启动更快,资源占用更少,更适合微服务部署
- 虚拟机隔离性更好,更适合需要完全隔离的场景
7. 服务实例
虚拟机(VM)vs 云实例:
- 虚拟机是在物理机上通过虚拟化技术创建的模拟计算机环境
- 云实例通常指的是云服务提供商提供的虚拟机实例
- 在大多数情况下,一个云实例就是一个虚拟机,只是术语上的区别
- 云实例强调了在云环境中的部署和管理特性
服务 vs 应用:
- 应用通常指的是一个完整的软件程序,可能包含多个功能模块
- 服务在微服务语境中,指的是实现特定业务功能的较小软件单元
- 一个传统应用可能被拆分为多个微服务
- 服务更强调对外提供的功能接口,而应用更强调用户体验和完整功能
服务实例 vs 虚拟机:
"单一服务实例"指的是一个服务程序的一个运行副本。这与虚拟机不一定是一一对应的关系:
-
一个虚拟机可以运行多个服务实例:例如,在同一台虚拟机上可以同时运行用户服务、订单服务等多个不同的服务,或者运行同一服务的多个副本(通过不同端口区分)。
-
一个服务实例也可以跨多个虚拟机:一些大型服务可能需要集群部署,一个逻辑上的服务实例实际上由多台虚拟机组成。
在现代微服务实践中,常见的部署模式是:使用容器(如Docker)将每个服务打包成独立单元,多个容器可以运行在同一台虚拟机上,实现资源的高效利用。容器编排平台(如Kubernetes)自动管理容器的部署、扩展和迁移
服务器进程 vs 个人电脑进程:
服务器上的进程与个人电脑上的进程在本质上是相同的操作系统概念,都是运行中的程序实例。不同之处在于用途和工作方式:
个人电脑进程:
- 通常服务于单一用户
- 往往具有用户界面
- 使用模式更加交互式
- 资源使用相对不稳定(根据用户操作变化大)
服务器进程:
- 通常服务于多个用户
- 很少有直接的用户界面
- 持续运行,少有交互
- 资源使用更加可预测和稳定
- 更注重吞吐量、可靠性和可用性
一个现代的商业应用服务器通常会运行多个进程:
- 一个或多个主应用进程
- 数据库进程
- 缓存进程
- 监控进程
- 日志收集进程等等
每个进程可能处理多个客户请求,通常是通过线程池来实现的。每个线程处理一个用户请求,而不是每个用户占用一个独立的进程。
8. 微服务与数据管理
8.1 微服务与数据库的关系
不一定要求每个服务管理自己的独立数据库,但这是一种推荐的做法,原因如下:
数据库共享的问题:
- 服务间耦合:共享数据库导致服务之间紧密耦合
- 扩展性限制:难以针对单个服务的需求来扩展数据库
- 架构腐化:容易导致服务绕过API直接访问数据,破坏封装
数据库独立的方案:
- 每个服务可以选择最适合其需求的数据库类型(关系型、文档型、图形数据库等)
- 服务之间通过API而非共享数据库进行通信
- 数据库结构变化不会影响其他服务
折中方案:
- 逻辑分离:在同一个物理数据库中使用不同的schema或collection
- 数据库视图:通过视图限制每个服务只能访问其所需数据
- 数据复制:关键数据在需要的服务中维护副本,通过事件同步保持一致
关于内存浪费的担忧:当今存储成本相对低廉,独立数据库带来的架构优势通常超过额外存储成本。此外,现代数据库提供了多种优化手段(如压缩、分片等)来减少资源使用。
8.2 数据一致性怎么保证
主要挑战:
- 数据分散在多个服务中,无法使用传统的ACID事务跨多个服务
- 数据复制导致的一致性问题
- 更新操作需要协调多个服务
解决方案:
-
最终一致性:接受系统在短时间内可能不一致的事实 通过异步事件确保最终达到一致状态
-
事件溯源:将状态变化存储为事件序列,通过重放事件重建一致状态
-
SAGA模式:将分布式事务拆分为一系列本地事务,每个本地事务有对应的补偿事务用于回滚
// SAGA模式示例
@Service
public class OrderSaga {
@Autowired
private OrderService orderService;
@Autowired
private PaymentService paymentService;
@Autowired
private InventoryService inventoryService;
public void processOrder(Order order) {
try {
// 步骤1:创建订单
orderService.createOrder(order);
try {
// 步骤2:处理支付
paymentService.processPayment(order);
try {
// 步骤3:更新库存
inventoryService.updateInventory(order);
} catch (Exception e) {
// 补偿事务:回滚支付
paymentService.refundPayment(order);
// 补偿事务:回滚订单
orderService.cancelOrder(order);
throw e;
}
} catch (Exception e) {
// 补偿事务:回滚订单
orderService.cancelOrder(order);
throw e;
}
} catch (Exception e) {
// 处理整体失败
throw new RuntimeException("Order processing failed", e);
}
}
}
-
两阶段提交:准备阶段:所有参与者准备事务并锁定资源,提交阶段:协调者指示所有参与者提交或回滚。适用于需要强一致性的场景,但性能开销大
-
共享数据库(在某些情况下):密切相关的服务可以共享同一个数据库
9. 安全性与合规
9.1 需要考虑哪些?
身份验证和授权:
- 集中式身份管理服务(如OAuth2.0、OpenID Connect)
- API网关层统一认证
- 服务间通信的认证(服务账户、JWT令牌等)
网络安全:
- 服务间通信加密(mTLS)
- 网络隔离和分段(如Kubernetes网络策略)
- 零信任安全模型
API安全:
- 输入验证和清理
- 速率限制和防DDoS措施
- API密钥管理
敏感数据处理:
- 数据加密(静态和传输中)
- 敏感信息(如密钥、证书)的安全存储
- 数据脱敏和匿名化
监控与审计:
- 全面的日志记录和审计跟踪
- 异常行为检测
- 安全事件响应
示例:服务间的安全通信:
// 使用OAuth2.0保护API
@Configuration
@EnableResourceServer
public class ResourceServerConfig extends ResourceServerConfigurerAdapter {
@Override
public void configure(HttpSecurity http) throws Exception {
http.authorizeRequests()
.antMatchers("/api/public/**").permitAll()
.antMatchers("/api/user/**").hasRole("USER")
.antMatchers("/api/admin/**").hasRole("ADMIN")
.anyRequest().authenticated();
}
}
// 服务调用时传递令牌
@Service
public class ServiceClient {
@Autowired
private OAuth2RestTemplate restTemplate;
public User getUser(Long id) {
// OAuth2RestTemplate自动添加认证令牌
return restTemplate.getForObject("http://user-service/users/{id}", User.class, id);
}
}
微服务治理框架要素与具体实现工具映射
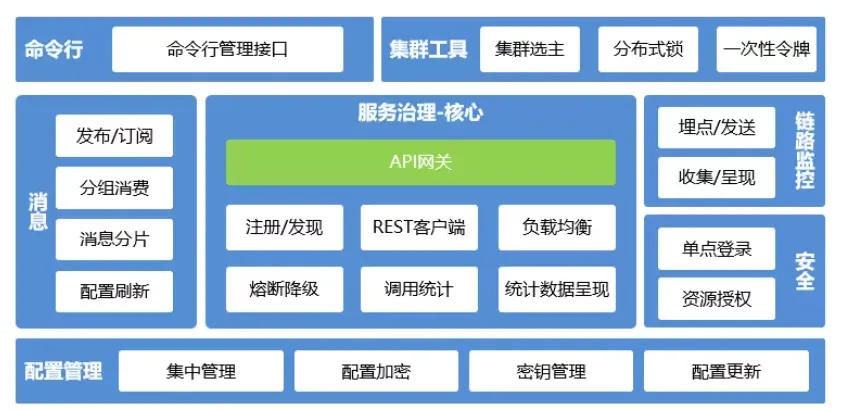
上面这张图展示了完整的服务治理框架结构:顶部模块:命令行、集群工具、分布式锁等基础设施
0. 微服务的拆分原则
按业务能力拆分:
- 根据业务职责划分服务边界
- 例如:用户管理、订单处理、库存管理等
按子域拆分(领域驱动设计):
- 识别业务中的不同领域和限界上下文
- 每个限界上下文成为一个潜在的微服务
考虑团队结构:
- 服务拆分应与组织结构匹配
- 康威定律:“系统设计反映组织结构”
数据关联度:
- 高内聚数据应该在同一个服务中
- 避免服务间过多的数据依赖
变更频率:
- 根据功能变更频率划分服务
- 频繁变更的功能可能需要单独的服务
过度拆分的危险信号:
- 服务间存在大量同步调用
- 分布式事务需求增加
- 代码重复严重
- 部署和测试变得极其复杂
1. 服务注册与发现
主流实现方案:
- Eureka:Netflix开发的服务注册中心,适合Java生态系统
- Consul:支持多种语言,提供健康检查、KV存储等多功能服务
- Nacos:阿里开发的动态服务发现与配置管理平台
- Kubernetes Service:基于容器编排平台的原生服务发现机制
- Zookeeper:分布式协调服务,可用于服务注册
使用关系:
- 这些工具通常选择其中一种作为服务注册中心使用
- 在Kubernetes环境中,可直接使用K8s Service机制,无需额外工具
- 选择考虑因素:技术栈兼容性、CAP特性偏好、团队经验
2. 负载均衡
主流实现方案:
-
客户端负载均衡:
- Ribbon:Netflix的客户端负载均衡器
- Spring Cloud LoadBalancer:Spring生态系统的负载均衡组件
-
服务端负载均衡:
- Nginx/Nginx Plus:高性能Web服务器和反向代理
- HAProxy:TCP/HTTP负载均衡器
- F5 BIG-IP:商业硬件负载均衡设备
-
API网关负载均衡:
- Kong:基于Nginx的API网关
- Spring Cloud Gateway:Spring生态系统的API网关
使用关系:
- 多层次负载均衡是常见的:外层使用Nginx/HAProxy,内层使用客户端负载均衡
- API网关通常处理南北向流量(外部访问),客户端负载均衡处理东西向流量(服务间)
- 可以组合使用,不是互斥关系
3. 熔断机制
主流实现方案:
-
应用层熔断:
- Hystrix:Netflix的熔断库(已进入维护模式)
- Resilience4j:轻量级熔断库,Hystrix的继任者
- Sentinel:阿里巴巴开发的流量控制组件
-
基础设施层熔断:
- Istio:服务网格提供的熔断功能
- Linkerd:轻量级服务网格
- Kong:API网关提供的熔断功能
使用关系:
- 可以在不同层次实现熔断:应用代码层面和网络基础设施层面
- 服务网格适合多语言环境,应用层熔断适合深度集成特定语言框架
- 两者可共存:服务网格处理通信层面熔断,应用框架处理业务层面熔断
4. 限流措施
主流实现方案:
-
应用级限流:
- Sentinel:阿里巴巴开发的流量控制框架
- Resilience4j:提供限流功能
- Guava RateLimiter:本地限流工具
- Bucket4j:基于令牌桶算法的Java限流库
-
分布式限流:
- Redis:基于Redis实现分布式限流
- Sentinel集群模式:全局限流
-
网关限流:
- Kong:API网关提供的限流功能
- NGINX Plus Rate Limiting:商业版Nginx的限流
- Spring Cloud Gateway:内置限流功能
使用关系:
- 通常在多个层次实现限流,形成梯度防护
- 网关层进行粗粒度限流(如按IP或API路径)
- 服务层实现细粒度限流(如按用户、业务维度)
- 两者是互补而非互斥关系
5. 配置管理
主流实现方案:
-
专用配置中心:
- Spring Cloud Config:Spring生态的配置服务
- Apollo:携程开发的配置中心,支持实时推送
- Nacos:阿里的动态配置服务
- Consul:提供KV存储功能
-
容器环境配置:
- Kubernetes ConfigMaps & Secrets:容器配置管理
-
配置即代码:
- HashiCorp Terraform:基础设施配置管理
- Ansible:自动化配置工具
使用关系:
- 专用配置中心和容器配置可以组合使用,处理不同层次配置
- 例如:K8s ConfigMap管理容器环境配置,Apollo管理应用业务配置
- 这是分层次互补使用,而非二选一关系
6. 分布式追踪
主流实现方案:
-
开源追踪系统:
- Zipkin:Twitter开发的分布式追踪系统
- Jaeger:Uber开发的分布式追踪平台
- SkyWalking:Apache开源的APM工具和分布式追踪系统
-
标准和协议:
- OpenTelemetry:观测性标准,整合了OpenTracing和OpenCensus
- W3C Trace Context:跨服务追踪上下文标准
-
商业APM解决方案:
- Dynatrace:全栈监控平台
- New Relic:应用性能监控
- Elastic APM:基于ELK的应用性能监控
使用关系:
- 可以使用OpenTelemetry作为数据收集标准,然后选择一个实现作为后端
- 追踪工具通常与其他监控工具集成,而不是孤立使用
- 组合使用模式:应用集成OpenTelemetry SDK → 导出追踪数据 → Jaeger存储和可视化
7. 日志聚合
主流实现方案:
-
日志收集:
- Filebeat:轻量级日志收集器
- Fluentd/Fluent Bit:统一日志层
- Logstash:日志处理管道
-
日志存储:
- Elasticsearch:分布式搜索和分析引擎
- Loki:Grafana开发的日志聚合系统
- ClickHouse:用于日志分析的列式数据库
-
日志可视化:
- Kibana:Elasticsearch的可视化界面
- Grafana:通用可视化平台
使用关系:
- 典型的日志处理流水线:收集 → 处理 → 存储 → 可视化
- ELK/EFK是完整堆栈组合(Elasticsearch + Logstash/Fluentd + Kibana)
- 这些组件需要组合使用而非单独使用
8. 监控告警
主流实现方案:
-
指标收集:
- Prometheus:拉模式指标收集
- Telegraf:推模式指标收集
- StatsD:应用指标收集系统
-
监控平台:
- Grafana:指标可视化平台
- Prometheus AlertManager:告警管理
- Zabbix:企业级监控系统
-
商业监控:
- Datadog:SaaS监控平台
- New Relic:端到端监控
- Dynatrace:全堆栈监控平台
使用关系:
- 监控通常分层实现:基础设施监控、容器监控、应用监控、业务监控
- Prometheus+Grafana是常见组合,负责系统和应用指标
- APM工具(如SkyWalking)与基础监控工具互补使用
9. 自动化(补充)
主流实现方案:
-
CI/CD工具:
- Jenkins:传统自动化服务器
- GitLab CI:源码管理集成CI/CD
- GitHub Actions:GitHub提供的工作流自动化
- ArgoCD:Kubernetes的GitOps工具
-
代码质量工具:
- SonarQube:代码质量和安全扫描
- Checkstyle/PMD/FindBugs:Java代码静态分析
-
制品管理:
- Nexus:制品仓库管理器
- JFrog Artifactory:通用制品管理平台
使用关系:
- CI/CD工具构建完整流水线:代码提交 → 测试 → 构建 → 部署
- 代码质量工具集成进CI流程,而不是独立使用
- 典型组合:GitLab(代码) + Jenkins(CI/CD) + SonarQube(质量) + Artifactory(制品) + K8s(部署)
10. 安全管理(补充)
主流实现方案:
-
身份认证授权:
- Keycloak:开源身份和访问管理
- OAuth2/OIDC:认证和授权标准
- Spring Security:应用级安全框架
-
密钥和证书管理:
- HashiCorp Vault:秘密管理工具
- Cert-Manager:Kubernetes证书管理
- Let’s Encrypt:自动证书颁发
-
API安全:
- API网关安全控制(Kong、APISIX)
- WAF:Web应用防火墙
- OWASP ZAP:安全漏洞扫描
使用关系:
- 安全工具通常是分层次配合使用:网络层、API层、应用层、数据层
- 身份认证系统(如Keycloak)负责认证,API网关负责授权和访问控制
- 两者是互补关系,不是二选一
混合云环境下的医疗信息管理平台架构
设计一个中等规模医疗信息管理平台,满足以下要求:
- 敏感医疗数据和核心服务部署在本地数据中心
- 非敏感数据和部分服务部署在云端
- 基于微服务架构,实现全面的服务治理
系统架构图
+-------------------------------------+ +----------------------------------------+
| 本地数据中心 | | 云端环境 |
| | | |
| +-------------+ +-------------+ | | +-------------+ +----------------+ |
| | 核心医疗服务 |<->| API网关(内部)| | | | 患者门户服务 |<->| API网关(外部) | |
| +-------------+ +-------------+ | | +-------------+ +----------------+ |
| | 电子病历 | | ^ | | | 预约系统 | | ^ |
| | 处方管理 | | | | | | 知识库服务 | | | |
| | 医疗影像 | | | | | | 统计分析 | | | |
| +------------+ v | | | +------------+ v | |
| +--------+ | | +--------+ |
| +-------------+ | 服务网格|<---|----|-------------------> | 服务网格| |
| | 安全服务 |<-->+--------+ | | +--------+ |
| +-------------+ | | | | |
| | 认证授权 | v | | v |
| | 审计日志 | +--------+ | | +--------+ |
| +------------+ | 服务注册|<---|----|-------------------> | 服务注册| |
| +--------+ | | +--------+ |
| | | | | |
| +-------------+ v | | +-------------+ v |
| | 本地数据库 | +------------+ | | | 云数据库 | +------------+ |
| +-------------+ | 监控告警 |<--|----|--->| 监控告警 | | 数据同步 | |
| | 患者记录 | +------------+ | | +-------------+ +------------+ |
| | 医疗影像 | | | | | 匿名数据 | ^ |
| | 敏感日志 | v | | | 配置信息 | | |
| +------------+ +------------+ | | +------------+ | |
| | 日志聚合 |<--|----|--->| 日志聚合 | | |
| +------------+ | | +------------+ | |
+-------------------------------------+ +----------------------------------------+
^ ^
| |
| +----------------------+ |
+------->| 专线/VPN安全连接 |<----------+
+----------------------+
| 加密通道 |
| 流量控制 |
| 访问控制 |
+----------------------+
数据流程图
- 患者预约流程
+----------------+
| 患者使用门户 |
| 发起预约请求 |
+-------+--------+
|
v
+--------------------+ +---+----------+
| 云端服务记录预约 |--->| 预约服务 |
| 基本信息 | | (云端) |
+--------------------+ +---+----------+
|
v
+--------------------+ +---+----------+
| 认证网关验证 |--->| API网关 |
| 请求合法性 | | (云端) |
+--------------------+ +---+----------+
|
安全VPN连接 |
| |
v v
+--------------------+ +---+----------+
| 查询患者记录 |--->| 患者信息服务 |
| 可用时段 | | (本地) |
+--------------------+ +---+----------+
|
v
+--------------------+ +---+----------+
| 确认并记录 |--->| 预约确认 |
| 预约信息 | | (返回云端) |
+--------------------+ +---+----------+
|
v
+--------------------+ +---+----------+
| 通知患者 |--->| 通知服务 |
| 预约结果 | | (云端) |
+--------------------+ +----------------+
- 医疗记录查询
+-----------------------+ +------------------+
| 医生通过本地系统 |--->| 医疗记录查询服务 |
| 查询患者医疗记录 | | (本地) |
+-----------------------+ +--------+---------+
|
v
+-----------------------+ +--------+---------+
| 验证医生权限 |--->| 认证授权服务 |
| 记录访问日志 | | (本地) |
+-----------------------+ +--------+---------+
|
v
+-----------------------+ +--------+---------+
| 从本地数据库 |--->| 电子病历服务 |
| 获取完整医疗记录 | | (本地) |
+-----------------------+ +--------+---------+
|
v
+-----------------------+ +--------+---------+
| 检查是否需要 |--->| 医疗影像服务 |
| 获取影像数据 | | (本地) |
+-----------------------+ +--------+---------+
|
v
+-----------------------+ +--------+---------+
| 整合信息并返回 |--->| 数据集成服务 |
| 给医生查看 | | (本地) |
+-----------------------+ +------------------+
服务治理实现架构
- 服务注册与发现
本地数据中心: 云环境:
+----------------+ +----------------+
| Consul集群 |<---联邦----->| Kubernetes |
| (服务注册中心) | | Service |
+-------+--------+ +-------+--------+
^ ^
| |
+-------v--------+ +-------v--------+
| 本地微服务 | | 云端微服务 |
| 注册健康检查 | | 自动服务发现 |
+----------------+ +----------------+
实现细节:
- 本地使用Consul集群作为服务注册中心
- 云端利用Kubernetes Service机制实现服务发现
- Consul与K8s通过联邦机制实现跨环境服务发现
- 健康检查周期:10秒,服务下线阈值:3次检查失败
- API网关与负载均衡
外部访问: 内部服务间调用:
+----------------+ +----------------+
| NGINX + Kong | | Spring Cloud |
| (公网访问层) | | LoadBalancer |
+-------+--------+ +-------+--------+
| |
v v
+-------+--------+ +-------+--------+
| Kong API网关 | | Resilience4j |
| 路由、认证 | | 客户端负载均衡 |
+-------+--------+ +----------------+
|
v
+-------+--------+
| 微服务集群 |
+----------------+
实现细节:
- 外部流量通过NGINX进行初步负载均衡
- Kong API网关处理路由、认证、限流
- 服务间调用使用Spring Cloud LoadBalancer
- 支持多种负载策略:加权轮询、最少连接数、响应时间加权
- 熔断与限流
+----------------+ +----------------+ +----------------+
| API网关层 | | 服务层 | | 数据库层 |
| Kong限流器 | | Resilience4j | | 连接池限制 |
+----------------+ +----------------+ +----------------+
| - 每IP限流 | | - 服务熔断 | | - 最大连接数 |
| - API级别限流 | | - 请求重试 | | - 语句超时 |
| - 服务限流 | | - 舱壁模式 | | - 读写分离 |
+----------------+ +----------------+ +----------------+
实现细节:
- Kong限流规则:关键API 50请求/秒,普通API 200请求/秒
- Resilience4j熔断配置:50%错误率触发熔断,15秒重试窗口
- 数据库连接池:每服务最大20连接,超时设置3秒
- 监控与告警
+----------------+ +----------------+
| Prometheus |<---联邦----->| Prometheus |
| (本地监控) | | (云端监控) |
+-------+--------+ +-------+--------+
| |
v v
+-------+--------+ +-------+--------+
| Grafana面板 |<---------------| 统一监控门户 |
| 本地可视化 | | 全局视图 |
+----------------+ +----------------+
|
v
+-------+--------+
| AlertManager |
| 告警管理 |
+----------------+
实现细节:
- 本地和云端各自部署Prometheus实例
- 通过Prometheus联邦机制整合监控数据
- 设置三级告警机制:
- 信息级:仅记录日志与控制台通知
- 警告级:邮件与企业微信通知
- 紧急级:短信、电话通知相关负责人
- 分布式追踪
+----------------+ +----------------+
| Jaeger后端 |<-------------+| OpenTelemetry |
| 追踪数据存储 | | 收集器 |
+-------+--------+ +-------+--------+
^ ^
| |
+-------+--------+ +-------+--------+
| 本地服务集成 | | 云端服务集成 |
| OpenTelemetry | | OpenTelemetry |
| SDK | | SDK |
+----------------+ +----------------+
实现细节:
- 所有微服务集成OpenTelemetry SDK
- 使用W3C Trace Context标准传递上下文
- 采样策略:关键业务流程100%采样,其他5%采样
- 通过追踪ID关联日志与监控数据
安全架构
+----------------+ +----------------+
| Keycloak |<-------------+| API网关 |
| 统一认证中心 | | 访问控制 |
+-------+--------+ +-------+--------+
| |
v v
+-------+--------+ +-------+--------+
| OAuth2/OIDC | | mTLS加密通信 |
| 身份认证 | | 服务间通信 |
+----------------+ +----------------+
| |
v v
+-------+--------+ +-------+--------+
| 细粒度权限 | | Vault密钥管理 |
| RBAC+ABAC | | 证书与密钥 |
+----------------+ +----------------+
实现细节:
- 采用OAuth2/OIDC协议进行身份认证
- 服务间通信使用mTLS相互认证
- 数据传输全程TLS 1.3加密
- 敏感数据加密存储,使用Vault管理加密密钥
总结
通过本文的详细解释,我们已经全面了解了API网关、微服务架构及相关概念的核心要点:
- 服务注册与发现是微服务架构的基础,使服务能够动态定位和调用其他服务。
- API网关作为系统的统一入口点,提供路由、安全控制、流量管理等功能,是对外提供服务的重要组件。
- 微服务架构强调将应用拆分为小型、松耦合的服务,每个服务专注于单一职责,可以独立开发和部署。
- 服务通信可以采用同步(REST API)或异步(消息队列)方式,不同场景选择不同的通信策略。
- 数据管理在微服务中是一大挑战,需要在独立性和一致性之间找到平衡。
- 容器和编排技术(如Docker和Kubernetes)为微服务提供了一致的运行环境和自动化管理能力。
- 服务治理包括熔断、限流、监控等机制,确保微服务系统的可靠性和弹性。
- 安全性需要在多个层面考虑,包括身份验证、授权、加密通信等。
- 微服务拆分需要按业务能力、团队结构和数据关联度等因素综合考虑。
- 监控和可观测性是微服务架构中必不可少的组成部分,帮助理解和诊断分布式系统。
混合身份提供者的定义与工作机制
混合身份提供者指的是能够跨越本地数据中心和云环境提供统一身份管理、认证和授权的系统。它不仅仅是类似OAuth的授权协议或PKI的证书基础设施,而是更全面的身份管理解决方案。
混合身份提供者通常包含以下功能:
- 身份信息同步(在本地目录和云端目录间保持用户信息一致)
- 单点登录(SSO)跨越本地和云端应用
- 统一的身份生命周期管理
- 集中的访问策略制定与执行
- 多因素认证整合
与OAuth和PKI的关系:
- OAuth:混合身份提供者可能使用OAuth作为授权协议的一部分,但它还处理身份联合、目录同步等OAuth不涉及的问题
- PKI:可能作为底层安全基础设施,提供证书颁发和验证,但混合身份提供者额外管理用户身份、权限分配和策略执行
在医疗混合云环境中的实例:
- 医院部署Azure AD Connect,在本地Active Directory与Azure AD之间同步医护人员账户
- 使用Okta作为身份提供者,允许医生使用同一账户访问本地电子病历系统和云端医学影像分析平台
- IBM Security Verify(原IBM Cloud Identity)管理医护人员在院内系统和远程医疗平台的访问权限
问题:“如果企业的软件系统中有一部分数据在云端,想访问云端数据,还能统一使用内部PKI验证吗?”
是的,企业可以在混合云环境中使用内部PKI(如Microsoft AD CS)进行统一身份验证,但需要适当的架构设计:
常见的实现方式:
-
PKI扩展模式:
- 在本地部署根CA(最高信任级别)
- 在云端部署从属CA(由根CA签发证书)
- 云端服务使用从属CA颁发的证书
- 所有系统信任根CA,从而建立完整信任链
-
PKI联合模式:
- 本地和云端各自维护独立的PKI
- 通过交叉认证建立互信关系
- 适用于安全要求特别高的场景
-
混合访问模式:
- 本地PKI仅管理内部证书
- 使用VPN/专线确保云服务能安全连接到本地PKI
- 适用于规模较小的混合部署
实际考量:
- 网络可靠性:如果云端服务完全依赖本地PKI,当本地数据中心不可用时可能导致验证失败
- 延迟影响:跨环境证书验证可能增加延迟,影响性能
- 安全政策:某些组织可能出于安全考虑,不允许将PKI私钥相关操作扩展到云环境
在医疗行业的实际做法通常是:使用本地PKI作为根信任源,同时在云环境部署中间CA,以平衡安全需求和运行效率。证书验证路径会回溯到本地根CA,但日常证书操作(如签发、更新)可以在云端完成,减少对本地基础设施的依赖。

















 7685
7685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









