






每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

近年来,大型语言模型(LLMs)迅速崛起,推动了机器学习任务中对GPU高效利用的需求。然而,研究人员在准确评估GPU性能时面临着一个关键问题:常用的GPU利用率(通过nvidia-smi或集成监控工具访问)并不能可靠地反映实际计算效率。令人惊讶的是,仅仅通过读写内存就能达到100%的GPU利用率,而无需进行任何实际计算。这一发现促使学术界重新审视性能评估指标和方法,呼吁研究人员寻找更准确的GPU性能衡量方式,以优化LLM训练和推理任务的GPU使用。
为了克服GPU利用率的局限性,研究人员提出了替代指标。其中一个广为人知的方法是谷歌在PaLM论文中介绍的模型FLOPS利用率(MFU)。MFU衡量系统在理论最大FLOPS下的实际吞吐量比例,更准确地反映了GPU的计算效率。然而,MFU的计算复杂性较高,且依赖于具体的参数和框架。尽管如此,MFU揭示了GPU利用率和计算效率之间的巨大差异。比如,有些LLM训练虽然显示出100%的GPU利用率,但MFU仅为20%,远低于大多数LLM训练中常见的35-45%的范围,突显了对GPU性能指标更深层次理解的必要性。
研究人员通过应用如数据加载器参数调整、混合精度训练和融合优化器等常用的PyTorch性能优化技术,成功实现了100%的GPU利用率和显著的功耗增长。然而,为了更全面地了解计算效率,他们计算了训练任务的MFU,认识到仅依赖GPU利用率作为性能指标的局限性。

GPU架构的复杂性是理解GPU利用率作为性能指标局限性的关键。GPU由多个核心和多处理管理器组成,如NVIDIA的SM或AMD的CU。尽管NVIDIA的GPU利用率定义模糊,但它更多反映的是GPU的活动性,而非计算效率。因此,研究人员转向使用PyTorch Profiler对模型训练循环进行剖析,发现Softmax内核虽然显示高GPU利用率,但SM效率却很低,说明存在潜在的执行效率问题。
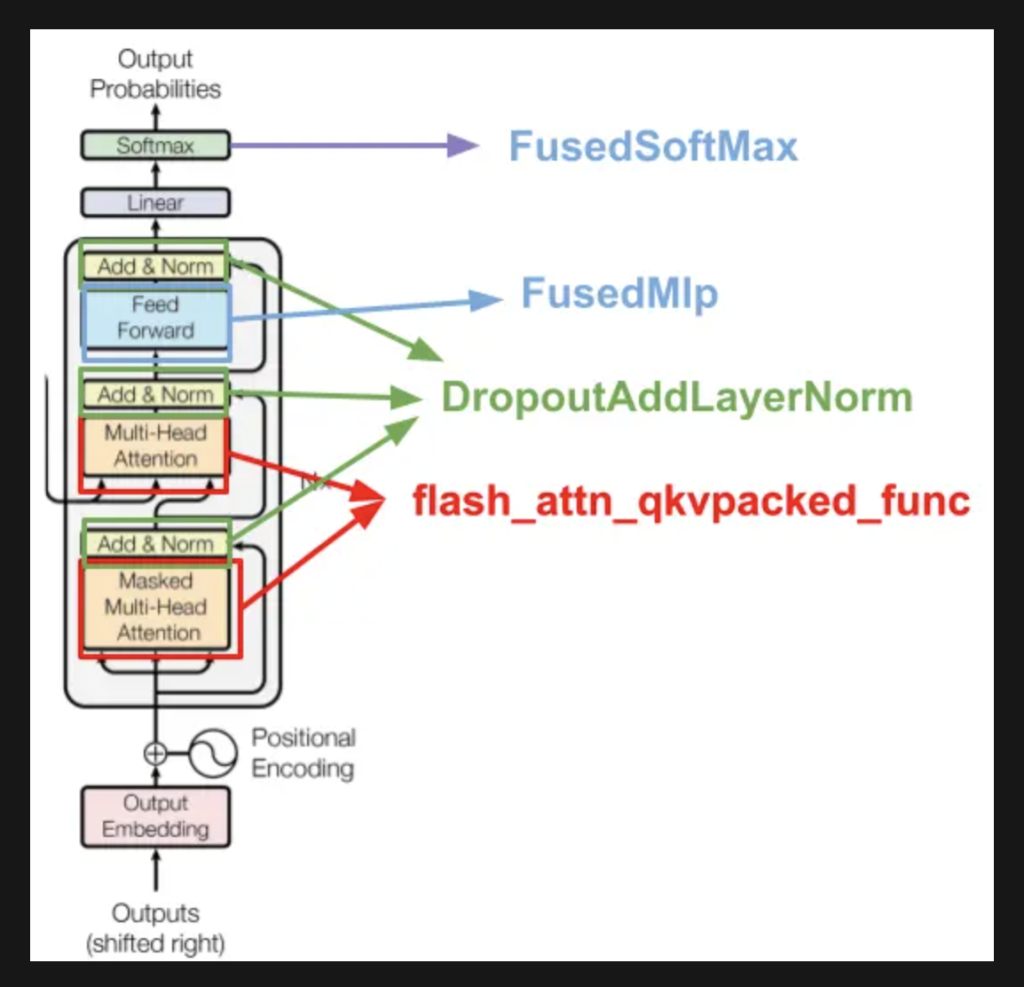
通过融合内核技术,研究人员成功提升了LLM训练的SM效率。最终,LLM训练效率大幅提升,MFU从20%增长至38%,训练时间缩短了四倍。研究人员建议,在GPU集群中同时追踪SM效率和GPU利用率,以准确评估性能,优化LLM训练的效率。















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









