






每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

随着大型语言模型(LLM)深入各类应用场景,其安全性问题也日益凸显。其中,“通用越狱”(Universal Jailbreaks)已成为重大挑战——黑客利用特定提示技巧绕过模型安全机制,从而获取受限信息。这类漏洞可能被用于非法活动,如合成违禁物质或规避网络安全措施。AI技术在不断进步的同时,攻击手段也在同步升级,因此,需要一种既能确保安全性,又不影响实际可用性的防御机制。
Anthropic的“宪法分类器”登场
为应对这一问题,Anthropic研究团队推出了**“宪法分类器”(Constitutional Classifiers),这是一种结构化框架,旨在提升LLM的安全性。该分类器基于符合“宪法原则”的合成数据**进行训练,能够明确划分允许与受限内容,从而提供更灵活的安全防护,并能适应不断演变的攻击策略。
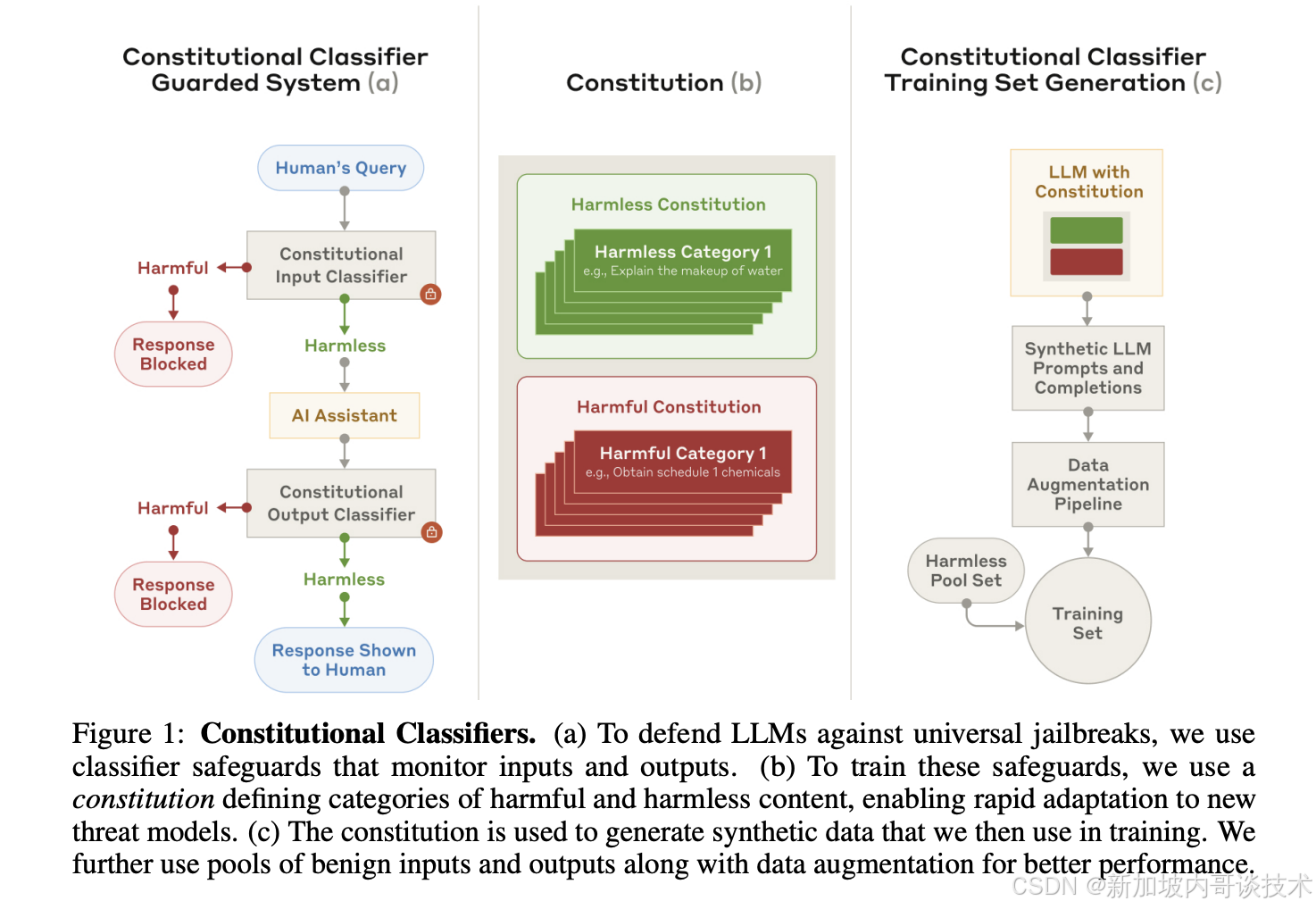
与传统的静态规则过滤或人工审核不同,宪法分类器直接将伦理和安全考量嵌入模型,使其在保证安全性的同时,依然具备良好的用户体验和扩展性。
如何运作?有哪些优势?
Anthropic的宪法分类器围绕以下三大核心展开:
✅ 对抗越狱攻击的鲁棒性:分类器基于宪法规则生成的合成数据进行训练,大幅提升识别和拦截有害内容的能力。
✅ 实用性与低成本部署:该框架引入的推理开销仅为23.7%,确保其在真实环境中的可行性。
✅ 适应性强:由于宪法规则可以更新,系统能及时应对新的安全挑战,保持长期有效性。
分类器在输入端和输出端均发挥作用。
🔹 输入端分类器:对用户输入的提示词进行审查,阻止潜在有害请求进入模型。
🔹 输出端分类器:实时评估模型生成的内容,确保其符合安全规则,必要时进行拦截。
这种逐个token实时评估的机制,在确保安全性的同时,兼顾了用户体验,避免模型“过度防御”导致实用性下降。
实验测试:能否真正防住通用越狱?
Anthropic团队进行了超过3000小时的红队攻击测试,共有405名安全研究员和AI专家参与,结果如下:
🚫 零成功的通用越狱:测试过程中,没有发现任何能稳定绕过防御的“万能越狱”方法。
🔒 95%拦截率:宪法分类器成功阻止了95%的越狱尝试,而未防护模型的拒绝率仅14%,防御能力显著提升。
🎯 极低误杀率:分类器在真实应用中仅额外增加了**0.38%**的拒绝率,表明其不会过度屏蔽正常用户请求。
📌 攻击者主要手法:实验发现,攻击者更倾向于微调措辞或调整回答长度,而非利用系统漏洞进行真正的突破。
尽管没有任何安全系统是100%无懈可击的,但这些实验数据表明,宪法分类器确实显著降低了通用越狱的风险。
结论:AI安全的新范式
Anthropic的宪法分类器为LLM安全性提供了一种更灵活、更可扩展的解决方案。通过围绕明确的宪法原则构建安全机制,该方法既提升了对越狱攻击的防御能力,又避免了传统安全策略中过度限制用户使用的弊端。
随着攻击技术的不断进化,这一框架仍需持续优化,以保持长期有效性。然而,从当前实验结果来看,宪法分类器已经证明了适应性安全防护的可行性,成为AI安全领域的一次重要突破。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









