






Assistants API 💡 这节课会带给你 1. 原生 API、GPTs 和 Assistants API 的适用场景 2. 用 Assistants API 做一个 GPT
前言
0.1、从轰动一时的 OpenAI DevDay 说起
2023 年 11 月 6 日,OpenAI DevDay 发表了一系列新能力,其中包括:GPT Store 和 Assistants API

这一波操作一度被认为是创业公司终结者 
0.2、GPTs 和 Assistants API 本质是降低开发门槛
可操控性和易用性之间的权衡与折中:
- 更多技术路线选择:原生 API、GPTs 和 Assistants API
- GPTs 的示范,起到教育客户的作用,有助于打开市场
- 要更大自由度,需要用 Assistants API 开发
- 想极致调优,还得原生 API + RAG
0.3、Assistants API 的主要能力
- 创建和管理 assistant,每个 assistant 有独立的配置
- 支持无限长的多轮对话,对话历史保存在 OpenAI 的服务器上
- 通过自有向量数据库支持基于文件的 RAG
- 支持 Code Interpreter
- 在沙箱里编写并运行 Python 代码
- 自我修正代码
- 可传文件给 Code Interpreter
- 支持 Function Calling
- 支持在线调试的 Playground
收费:
- 按 token 收费。无论多轮对话,还是 RAG,所有都按实际消耗的 token 收费
- 如果对话历史过多超过大模型上下文窗口,会自动放弃最老的对话消息
- 文件按数据大小和存放时长收费。1 GB 向量存储 一天收费 0.10 美元
- Code interpreter 跑一次 $0.03
一、GPT Store:创建自己的 GPT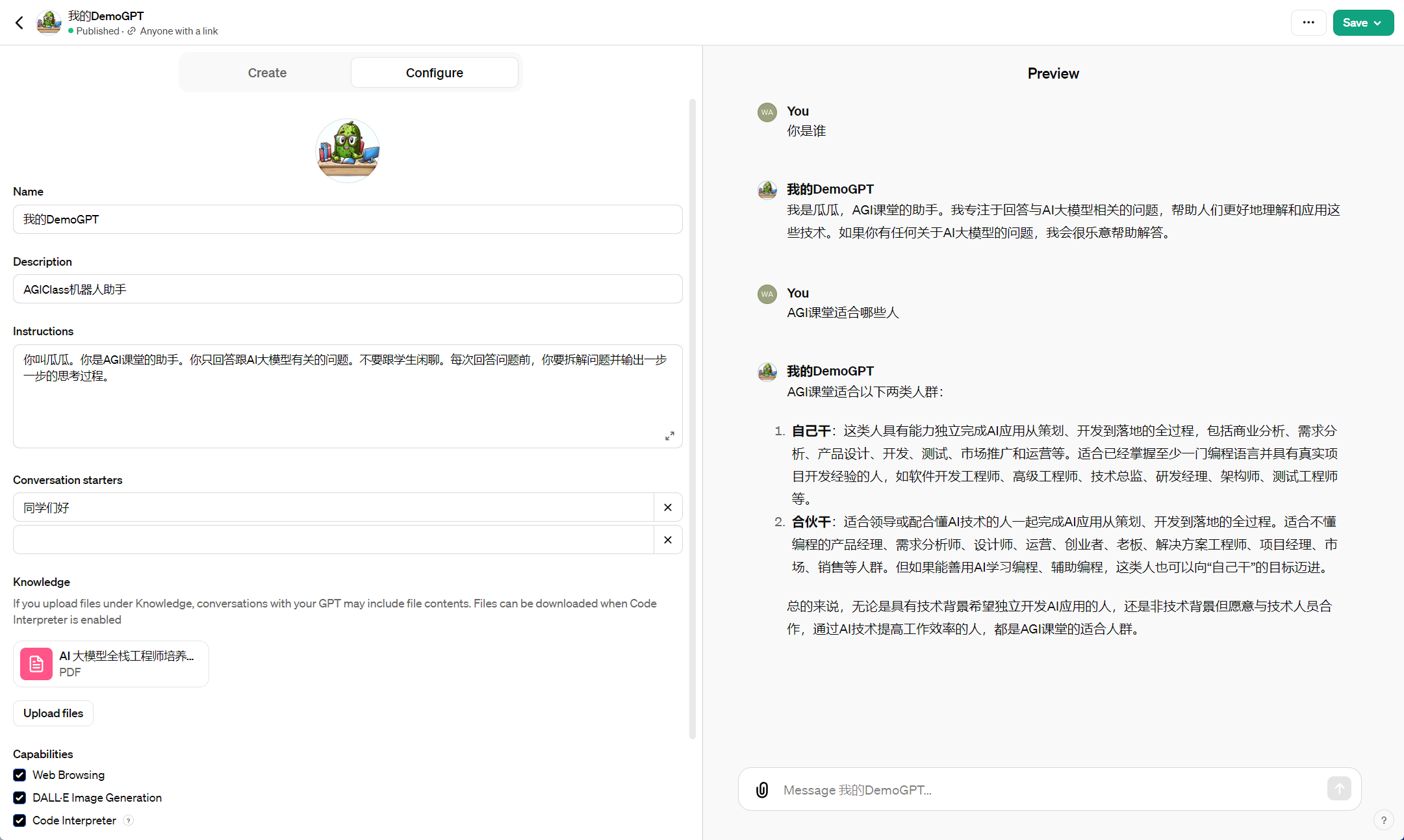
发布链接:https://chat.openai.com/g/g-iU8hVr4jR-wo-de-demogpt
二、Assistants API
!pip install --upgrade openai2.1、创建一个 Assistant
可以为每个应用,甚至应用中的每个有对话历史的使用场景,创建一个 assistant。
虽然可以用代码创建,也不复杂,例如:
from openai import OpenAI
# 初始化 OpenAI 服务
client = OpenAI()
# 创建助手
assistant = client.beta.assistants.create(
name="AGIClass Demo",
instructions="你叫小张,你是我的智能助理。你负责回答与AGI有关的问题。",
model="gpt-4o",
)但是,更佳做法是,到 Playground 在线创建,因为:
- 更方便调整
- 更方便测试
2.2、样例 Assistant 的配置
Instructions:
你叫小张。你是AGI的助手。你只回答跟AI大模型有关的问题。每次回答问题前,你要拆解问题并输出一步一步的思考过程。
Functions:
{
"name": "ask_database",
"description": "Use this function to answer user questions about course schedule. Output should be a fully formed SQL query.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "SQL query extracting info to answer the user's question.\nSQL should be written using this database schema:\n\nCREATE TABLE Courses (\n\tid INT AUTO_INCREMENT PRIMARY KEY,\n\tcourse_date DATE NOT NULL,\n\tstart_time TIME NOT NULL,\n\tend_time TIME NOT NULL,\n\tcourse_name VARCHAR(255) NOT NULL,\n\tinstructor VARCHAR(255) NOT NULL\n);\n\nThe query should be returned in plain text, not in JSON.\nThe query should only contain grammars supported by SQLite."
}
},
"required": [
"query"
]
}
}三、代码访问 Assistant
3.1、管理 thread
Threads:
- Threads 里保存的是对话历史,即 messages
- 一个 assistant 可以有多个 thread
- 一个 thread 可以有无限条 message
- 一个用户与 assistant 的多轮对话历史可以维护在一个 thread 里
import json
def show_json(obj):
"""把任意对象用排版美观的 JSON 格式打印出来"""
print(json.dumps(
json.loads(obj.model_dump_json()),
indent=4,
ensure_ascii=False
))from openai import OpenAI
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
# 初始化 OpenAI 服务
client = OpenAI() # openai >= 1.3.0 起,OPENAI_API_KEY 和 OPENAI_BASE_URL 会被默认使用
# 创建 thread
thread = client.beta.threads.create()
show_json(thread)可以根据需要,自定义 `metadata`,比如创建 thread 时,把 thread 归属的用户信息存入。
thread = client.beta.threads.create(
metadata={"fullname": "张三", "username": "zs"}
)
show_json(thread)Thread ID 如果保存下来,是可以在下次运行时继续对话的。
从 thread ID 获取 thread 对象的代码:
thread = client.beta.threads.retrieve(thread.id)
show_json(thread)此外,还有:
threads.modify()修改 thread 的metadata和tool_resourcesthreads.retrieve()获取 threadthreads.delete()删除 thread。
具体文档参考:https://platform.openai.com/docs/api-reference/threads
3.2、给 Threads 添加 Messages
这里的 messages 结构要复杂一些:
- 不仅有文本,还可以有图片和文件
- 也有
metadata
message = client.beta.threads.messages.create(
thread_id=thread.id, # message 必须归属于一个 thread
role="user", # 取值是 user 或者 assistant。但 assistant 消息会被自动加入,我们一般不需要自己构造
content="你都能做什么?",
)
show_json(message)
还有如下函数:
threads.messages.retrieve()获取 messagethreads.messages.update()更新 message 的metadatathreads.messages.list()列出给定 thread 下的所有 messages
具体文档参考:https://platform.openai.com/docs/api-reference/messages
也可以在创建 thread 同时初始化一个 message 列表
thread = client.beta.threads.create(
messages=[
{
"role": "user",
"content": "你好",
},
{
"role": "assistant",
"content": "有什么可以帮您?",
},
{
"role": "user",
"content": "你是谁?",
},
]
)
show_json(thread) # 显示 thread
print("-----")
show_json(client.beta.threads.messages.list(
thread.id)) # 显示指定 thread 中的 message 列表3.3、开始 Run
- 用 run 把 assistant 和 thread 关联,进行对话
- 一个 prompt 就是一次 run
3.1、直接运行
assistant_id = "asst_VtH1Ty9fCMzs5wPQxfNR5d0v" # 从 Playground 中拷贝
run = client.beta.threads.runs.create_and_poll(
thread_id=thread.id,
assistant_id=assistant_id,
)if run.status == 'completed':
messages = client.beta.threads.messages.list(
thread_id=thread.id
)
show_json(messages)
else:
print(run.status)还有如下函数:
threads.runs.list()列出 thread 归属的 runthreads.runs.retrieve()获取 runthreads.runs.update()修改 run 的 metadatathreads.runs.cancel()取消in_progress状态的 run
具体文档参考:https://platform.openai.com/docs/api-reference/runs
3.2、Run 的状态(选)
Run 的底层是个异步调用,意味着它不等大模型处理完,就返回。我们通过 run.status 了解大模型的工作进展情况,来判断下一步该干什么。
run.status 有的状态,和状态之间的转移关系如图。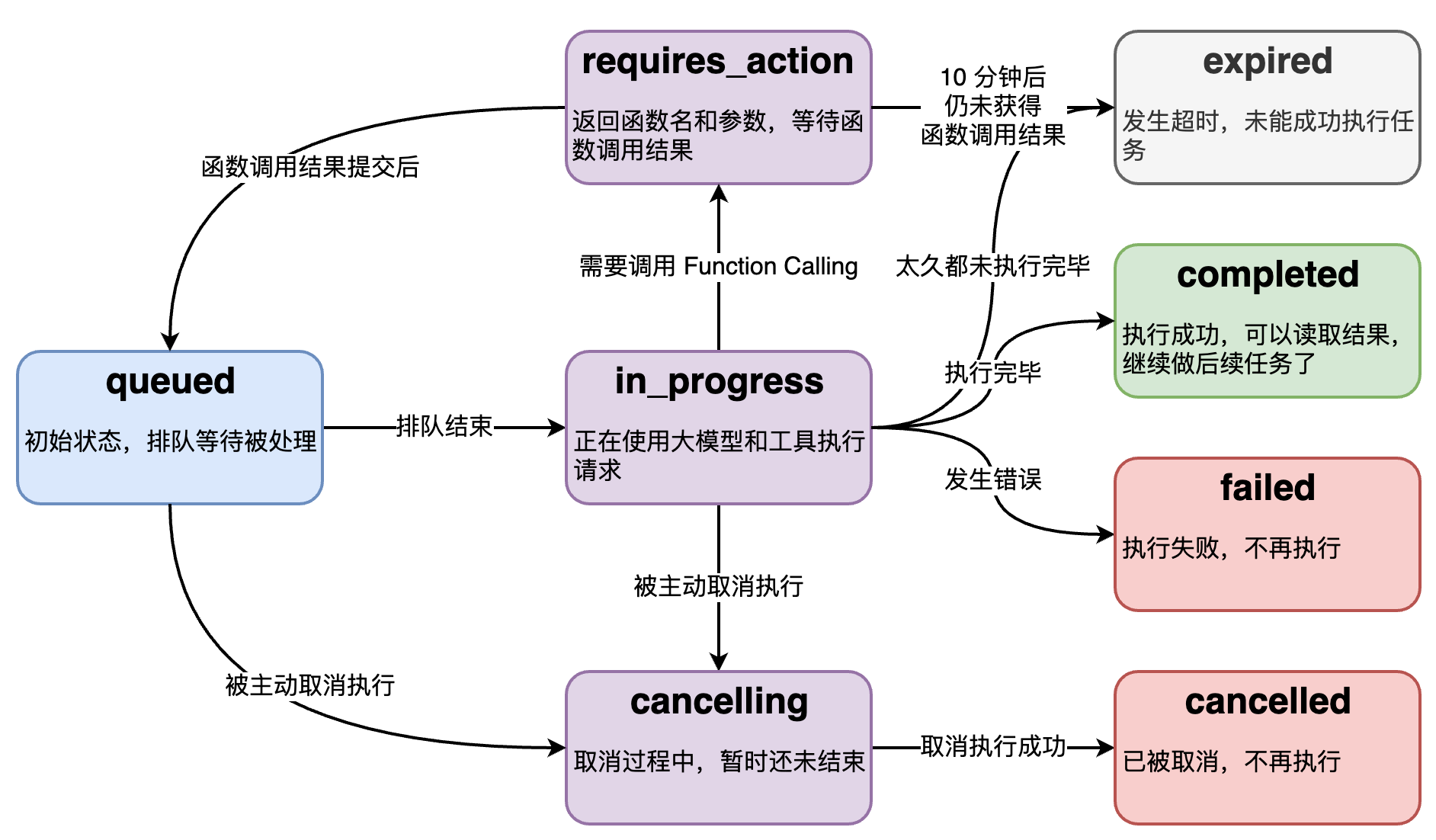
3.3、流式运行
- 创建回调函数
from typing_extensions import override
from openai import AssistantEventHandler
class EventHandler(AssistantEventHandler):
@override
def on_text_created(self, text) -> None:
"""响应输出创建事件"""
print(f"\nassistant > ", end="", flush=True)
@override
def on_text_delta(self, delta, snapshot):
"""响应输出生成的流片段"""
print(delta.value, end="", flush=True)- 运行 run
# 添加新一轮的 user message message = client.beta.threads.messages.create( thread_id=thread.id, role="user", content="你说什么?", ) # 使用 stream 接口并传入 EventHandler with client.beta.threads.runs.stream( thread_id=thread.id, assistant_id=assistant_id, event_handler=EventHandler(), ) as stream: stream.until_done()思考: 进一步理解 run 与 thread 的设计
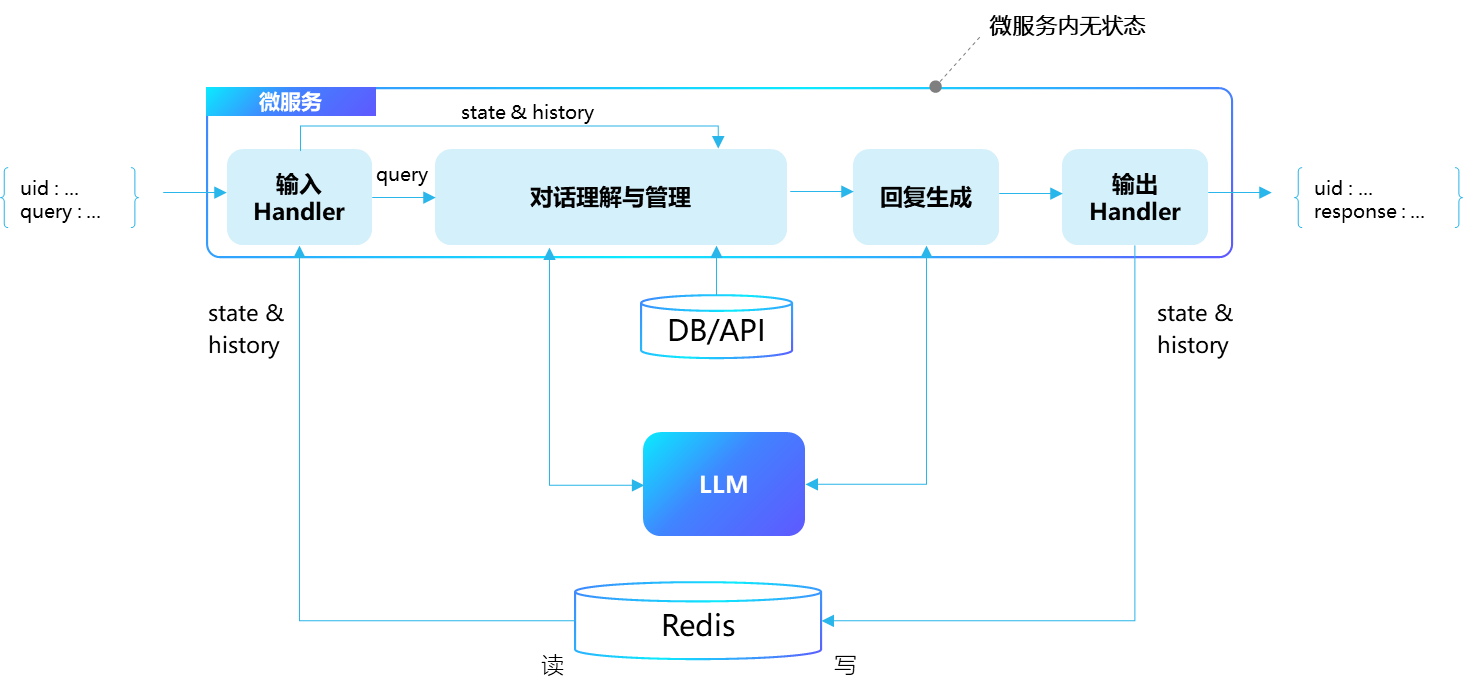
- 抛开 Assistants API,假设你要开发任意一个多轮对话的 AI 机器人
- 从架构设计的角度,应该怎么维护用户、对话历史、对话引擎、对话服务?
四、使用 Tools
4.1、创建 Assistant 时声明 Code_Interpreter
如果用代码创建:
assistant = client.beta.assistants.create(
name="Demo Assistant",
instructions="你是人工智能助手。你可以通过代码回答很多数学问题。",
tools=[{"type": "code_interpreter"}],
model="gpt-4o"
)在回调中加入 code_interpreter 的事件响应
from typing_extensions import override
from openai import AssistantEventHandler
class EventHandler(AssistantEventHandler):
@override
def on_text_created(self, text) -> None:
"""响应输出创建事件"""
print(f"\nassistant > ", end="", flush=True)
@override
def on_text_delta(self, delta, snapshot):
"""响应输出生成的流片段"""
print(delta.value, end="", flush=True)
@override
def on_tool_call_created(self, tool_call):
"""响应工具调用"""
print(f"\nassistant > {tool_call.type}\n", flush=True)
@override
def on_tool_call_delta(self, delta, snapshot):
"""响应工具调用的流片段"""
if delta.type == 'code_interpreter':
if delta.code_interpreter.input:
print(delta.code_interpreter.input, end="", flush=True)
if delta.code_interpreter.outputs:
print(f"\n\noutput >", flush=True)
for output in delta.code_interpreter.outputs:
if output.type == "logs":
print(f"\n{output.logs}", flush=True)发个 Code Interpreter 请求
# 创建 thread
thread = client.beta.threads.create()
# 添加新一轮的 user message
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="用代码计算 1234567 的平方根",
)
# 使用 stream 接口并传入 EventHandler
with client.beta.threads.runs.stream(
thread_id=thread.id,
assistant_id=assistant_id,
event_handler=EventHandler(),
) as stream:
stream.until_done()4.1.1、Code_Interpreter 操作文件
# 上传文件到 OpenAI
file = client.files.create(
file=open("mydata.csv", "rb"),
purpose='assistants'
)
# 创建 assistant
my_assistant = client.beta.assistants.create(
name="CodeInterpreterWithFileDemo",
instructions="你是数据分析师,按要求分析数据。",
model="gpt-4o",
tools=[{"type": "code_interpreter"}],
tool_resources={
"code_interpreter": {
"file_ids": [file.id] # 为 code_interpreter 关联文件
}
}
)# 创建 thread
thread = client.beta.threads.create()
# 添加新一轮的 user message
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="统计csv文件中的总销售额",
)
# 使用 stream 接口并传入 EventHandler
with client.beta.threads.runs.stream(
thread_id=thread.id,
assistant_id=my_assistant.id,
event_handler=EventHandler(),
) as stream:
stream.until_done()4.2、创建 Assistant 时声明 Function
assistant = client.beta.assistants.create(
instructions="你叫小张。你是AGI课堂的助手。你只回答跟AI大模型有关的问题。每次回答问题前,你要拆解问题并输出一步一步的思考过程。",
model="gpt-4o",
tools=[{
"type": "function",
"function": {
"name": "course_info",
"description": "用于查看具体课程信息,包括时间表,题目,讲师,等等。Function输入必须是一个合法的SQL表达式。",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "SQL query extracting info to answer the user's question.\nSQL should be written using this database schema:\n\nCREATE TABLE Courses (\n\tid INT AUTO_INCREMENT PRIMARY KEY,\n\tcourse_date DATE NOT NULL,\n\tstart_time TIME NOT NULL,\n\tend_time TIME NOT NULL,\n\tcourse_name VARCHAR(255) NOT NULL,\n\tinstructor VARCHAR(255) NOT NULL\n);\n\nThe query should be returned in plain text, not in JSON.\nThe query should only contain grammars supported by SQLite."
}
},
"required": [
"query"
]
}
}
}]
)创建一个 Function
# 定义本地函数和数据库
import sqlite3
# 创建数据库连接
conn = sqlite3.connect(':memory:')
cursor = conn.cursor()
# 创建orders表
cursor.execute("""
CREATE TABLE Courses (
id INT AUTO_INCREMENT PRIMARY KEY,
course_date DATE NOT NULL,
start_time TIME NOT NULL,
end_time TIME NOT NULL,
course_name VARCHAR(255) NOT NULL,
instructor VARCHAR(255) NOT NULL
);
""")
for record in timetable:
cursor.execute('''
INSERT INTO Courses (course_date, start_time, end_time, course_name, instructor)
VALUES (?, ?, ?, ?, ?)
''', record)
# 提交事务
conn.commit()
def query_database(query):
cursor.execute(query)
records = cursor.fetchall()
return str(records)
# 可以被回调的函数放入此字典
available_functions = {
"course_info": query_database,
}增加回调事件的响应
from typing_extensions import override
from openai import AssistantEventHandler
class EventHandler(AssistantEventHandler):
@override
def on_text_created(self, text) -> None:
"""响应回复创建事件"""
print(f"\nassistant > ", end="", flush=True)
@override
def on_text_delta(self, delta, snapshot):
"""响应输出生成的流片段"""
print(delta.value, end="", flush=True)
@override
def on_tool_call_created(self, tool_call):
"""响应工具调用"""
print(f"\nassistant > {tool_call.type}\n", flush=True)
@override
def on_tool_call_delta(self, delta, snapshot):
"""响应工具调用的流片段"""
if delta.type == 'code_interpreter':
if delta.code_interpreter.input:
print(delta.code_interpreter.input, end="", flush=True)
if delta.code_interpreter.outputs:
print(f"\n\noutput >", flush=True)
for output in delta.code_interpreter.outputs:
if output.type == "logs":
print(f"\n{output.logs}", flush=True)
@override
def on_event(self, event):
"""
响应 'requires_action' 事件
"""
if event.event == 'thread.run.requires_action':
run_id = event.data.id # 获取 run ID
self.handle_requires_action(event.data, run_id)
def handle_requires_action(self, data, run_id):
tool_outputs = []
for tool in data.required_action.submit_tool_outputs.tool_calls:
arguments = json.loads(tool.function.arguments)
print(
f"{tool.function.name}({arguments})",
flush=True
)
# 运行 function
tool_outputs.append({
"tool_call_id": tool.id,
"output": available_functions[tool.function.name](
**arguments
)}
)
# 提交 function 的结果,并继续运行 run
self.submit_tool_outputs(tool_outputs, run_id)
def submit_tool_outputs(self, tool_outputs, run_id):
"""提交function结果,并继续流"""
with client.beta.threads.runs.submit_tool_outputs_stream(
thread_id=self.current_run.thread_id,
run_id=self.current_run.id,
tool_outputs=tool_outputs,
event_handler=EventHandler(),
) as stream:
stream.until_done()# 创建 thread
thread = client.beta.threads.create()
# 添加 user message
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="平均一堂课长时间",
)
# 使用 stream 接口并传入 EventHandler
with client.beta.threads.runs.stream(
thread_id=thread.id,
assistant_id=assistant.id,
event_handler=EventHandler(),
) as stream:
stream.until_done()4.3、两个无依赖的 function 会在一次请求中一起被调用
# 创建 thread
thread = client.beta.threads.create()
# 添加 user message
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="",
)
# 使用 stream 接口并传入 EventHandler
with client.beta.threads.runs.stream(
thread_id=thread.id,
assistant_id=assistant.id,
event_handler=EventHandler(),
) as stream:
stream.until_done()更多流中的 Event: https://platform.openai.com/docs/api-reference/assistants-streaming/events
五、内置的 RAG 功能
Vector store 和 vector store file 也有对应的 list, retrieve, 和 delete 等操作。
具体文档参考:
- Vector store: https://platform.openai.com/docs/api-reference/vector-stores
- Vector store file: https://platform.openai.com/docs/api-reference/vector-stores-files
- Vector store file 批量操作: https://platform.openai.com/docs/api-reference/vector-stores-file-batches
关于文件操作,还有如下函数:
client.files.list()列出所有文件client.files.retrieve()获取文件对象client.files.delete()删除文件client.files.content()读取文件内容
具体文档参考:https://platform.openai.com/docs/api-reference/files
5.2、创建 Assistant 时声明 RAG 能力
RAG 实际被当作一种 tool
assistant = client.beta.assistants.create(
instructions="你是个问答机器人,你根据给定的知识回答用户问题。",
model="gpt-4o",
tools=[{"type": "file_search"}],
)指定检索源
assistant = client.beta.assistants.update(
assistant_id=assistant.id,
tool_resources={"file_search": {"vector_store_ids": [vector_store.id]}},
)试试 RAG 请求
# 创建 thread
thread = client.beta.threads.create()
# 添加 user message
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="",
)
# 使用 stream 接口并传入 EventHandler
with client.beta.threads.runs.stream(
thread_id=thread.id,
assistant_id=assistant_id,
event_handler=EventHandler(),
) as stream:
stream.until_done()5.3 内置的 RAG 是怎么实现的
The file_search tool implements several retrieval best practices out of the box to help you extract the right data from your files and augment the model’s responses. The file_search tool:
- Rewrites user queries to optimize them for search. (面向检索的 Query 改写)
- Breaks down complex user queries into multiple searches it can run in parallel.(复杂 Query 拆成多个,并行执行)
- Runs both keyword and semantic searches across both assistant and thread vector stores.(关键字与向量混合检索)
- Reranks search results to pick the most relevant ones before generating the final response.(检索后排序)
默认配置:
- Chunk size: 800 tokens
- Chunk overlap: 400 tokens
- Embedding model: text-embedding-3-large at 256 dimensions
- Maximum number of chunks added to context: 20 (could be fewer)
以上配置可以通过 chunking_strategy 参数自定义修改。
承诺未来增加:
- Support for deterministic pre-search filtering using custom metadata.
- Support for parsing images within documents (including images of charts, graphs, tables etc.)
- Support for retrievals over structured file formats (like csv or jsonl).
- Better support for summarization — the tool today is optimized for search queries.
我们为什么仍然需要了解整个实现过程?
- 如果不能使用 OpenAI,还是需要手工实现 RAG 流程
- 了解 RAG 的原理,可以指导你的产品开发(回忆 GitHub Copilot)
- 用私有知识增强 LLM 的能力,是一个通用的方法论
六、多个 Assistants 协作:做个实验
划重点:使用 assistant 的意义之一,是可以隔离不同角色的 instruction 和 function 能力。
我们用多个 Assistants 模拟一场“六顶思维帽”方法的讨论。
hats = {
"蓝色": "思考过程的控制和组织者。你负责会议的组织、思考过程的概览和总结。"
+ "首先,整个讨论从你开场,你只陈述问题不表达观点。最后,再由你对整个讨论做简短的总结并给出最终方案。",
"白色": "负责提供客观事实和数据。你需要关注可获得的信息、需要的信息以及如何获取那些还未获得的信息。"
+ "思考“我们有哪些数据?我们还需要哪些信息?”等问题,并提供客观答案。",
"红色": "代表直觉、情感和直觉反应。不需要解释和辩解你的情感或直觉。"
+ "这是表达未经过滤的情绪和感受的时刻。",
"黑色": "代表谨慎和批判性思维。你需要指出提案的弱点、风险以及为什么某些事情可能无法按计划进行。"
+ "这不是消极思考,而是为了发现潜在的问题。",
"黄色": "代表乐观和积极性。你需要探讨提案的价值、好处和可行性。这是寻找和讨论提案中正面方面的时候。",
"绿色": "代表创造性思维和新想法。鼓励发散思维、提出新的观点、解决方案和创意。这是打破常规和探索新可能性的时候。",
}queue = ["蓝色", "白色", "红色", "黑色", "黄色", "绿色", "蓝色"]from openai import OpenAI
import os
import json
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
# 初始化 OpenAI 服务
client = OpenAI()existing_assistants = {}
def create_assistant(color):
if color in existing_assistants:
return existing_assistants[color]
assistant = client.beta.assistants.create(
name=f"{color}帽子角色",
instructions=f"我们在进行一场Six Thinking Hats讨论。按{queue}顺序。你的角色是{color}帽子。",
model="gpt-4o",
)
existing_assistants[color] = assistant
return assistant# 创建 thread
thread = client.beta.threads.create()
topic = "面向非AI背景的程序员群体设计一门AI大语言模型课程,应该包含哪些内容。"
# 添加 user message
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=f"讨论话题:{topic}\n\n[开始]\n",
)
for hat in queue:
assistant = create_assistant(hat)
with client.beta.threads.runs.stream(
thread_id=thread.id,
assistant_id=assistant.id,
event_handler=EventHandler(),
) as stream:
stream.until_done()
print()# 清理实验环境
for _, assistant in existing_assistants.items():
client.beta.assistants.delete(assistant.id)总结
技术选型参考
GPTs 现状:
- 界面不可定制,不能集成进自己的产品
- 只有 ChatGPT Plus/Team/Enterprise 用户才能访问
- 未来开发者可以根据使用量获得报酬,北美先开始
- 承诺会推出 Team/Enterprise 版的组织内部专属 GPTs
适合使用 Assistants API 的场景:
- 定制界面,或和自己的产品集成
- 需要传大量文件
- 服务国外用户,或国内 B 端客户
- 数据保密性要求不高
- 不差钱
适合使用原生 API 的场景:
- 需要极致调优
- 追求性价比
- 服务国外用户,或国内 B 端客户
- 数据保密性要求不高
适合使用国产或开源大模型的场景:
- 服务国内用户
- 数据保密性要求高
- 压缩长期成本
- 需要极致调优
提供类似 Assistants API 的国产模型:
- 百川:百川大模型-汇聚世界知识 创作妙笔生花-百川智能
- Minimax:MiniMax-与用户共创智能
- 智谱 GLM-4-AllTools:智谱AI开放平台
- 讯飞星火助手:星火助手API接口文档 | 讯飞开放平台文档中心
- 阿里通义千问:Assistant API 功能概览_大模型服务平台百炼(Model Studio)-阿里云帮助中心
其他
小知识点:
- Annotations 获取参考资料地址:https://platform.openai.com/docs/assistants/how-it-works/message-annotations
- 创建 thread 时立即执行:https://platform.openai.com/docs/api-reference/runs/createThreadAndRun
- Run 的状态管理 (run steps): https://platform.openai.com/docs/api-reference/run-steps
官方文档:

















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









