






LangGraph 核⼼组件: Graphs, State, Nodes, Edges
LangGraph ⚡ 以图的⽅式构建语⾔代理 ⚡
官⽅⽂档地址:LangGraph是⼀个⽤于构建具有 LLMs 的有状态、多⻆⾊应⽤程序的库,⽤于创建代理和多代理 ⼯作流。与其他 LLM 框架相⽐,它提供了以下核⼼优势:循环、可控性和持久性。 LangGraph 允许您定义涉及循环的流程,这对于⼤多数代理架构⾄关重要。作为⼀种⾮常底层的 框架,它提供了对应⽤程序的流程和状态的精细控制,这对创建可靠的代理⾄关重要。此外, LangGraph 包含内置的持久性,可以实现⾼级的“⼈机交互”和内存功能。 LangGraph 的灵感来⾃ Pregel 和 Apache Beam。公共接⼝借鉴了 NetworkX。 LangGraph 由 LangChain In(LangChain 的创建者)构建,但可以在没有 LangChain 的情况 下使⽤。 循环和分⽀:在您的应⽤程序中实现循环和条件语句。 持久性:在图中的每个步骤之后⾃动保存状态。在任何时候暂停和恢复图执⾏以⽀持错误恢 复、“⼈机交互”⼯作流、时间旅⾏等等。 “⼈机交互”:中断图执⾏以批准或编辑代理计划的下⼀个动作。 流⽀持:在每个节点产⽣输出时流式传输输出(包括令牌流式传输)。 与 LangChain 集成:LangGraph 与 LangChain 和 LangSmith ⽆缝集成(但不需要它 们)。
安装
pip install -U langgraph示例
LangGraph 的⼀个核⼼概念是状态。每次图执⾏都会创建⼀个状态,该状态在图中的节点执⾏时 传递,每个节点在执⾏后使⽤其返回值更新此内部状态。图更新其内部状态的⽅式由所选图类型或 ⾃定义函数定义。 让我们看⼀个可以使⽤搜索⼯具的简单代理示例。
pip install langchain-openaisetx OPENAI_BASE_URL "https://api.openai.com/v1"
setx OPENAI_API_KEY "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"可以选择设置 LangSmith 以实现最佳的可观察性。
setx LANGSMITH_TRACING "true"
setx LANGSMITH_API_KEY "xxxxxxxxxxxxxxxx"from typing import Literal
from langchain_core.messages import HumanMessage
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
# pip install -U langgraph
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import END, StateGraph, MessagesState
from langgraph.prebuilt import ToolNode
# 定义工具函数,用于代理调用外部工具
@tool
def search(query: str):
"""模拟一个搜索工具"""
if "上海" in query.lower() or "Shanghai" in query.lower():
return "现在30度,有雾."
return "现在是35度,阳光明媚。"
# 将工具函数放入工具列表
tools = [search]
# 创建工具节点
tool_node = ToolNode(tools)
# 1.初始化模型和工具,定义并绑定工具到模型
model = ChatOpenAI(model="gpt-4o", temperature=0).bind_tools(tools)
# 定义函数,决定是否继续执行
def should_continue(state: MessagesState) -> Literal["tools", END]:
messages = state['messages']
last_message = messages[-1]
# 如果LLM调用了工具,则转到“tools”节点
if last_message.tool_calls:
return "tools"
# 否则,停止(回复用户)
return END
# 定义调用模型的函数
def call_model(state: MessagesState):
messages = state['messages']
response = model.invoke(messages)
# 返回列表,因为这将被添加到现有列表中
return {"messages": [response]}
# 2.用状态初始化图,定义一个新的状态图
workflow = StateGraph(MessagesState)
# 3.定义图节点,定义我们将循环的两个节点
workflow.add_node("agent", call_model)
workflow.add_node("tools", tool_node)
# 4.定义入口点和图边
# 设置入口点为“agent”
# 这意味着这是第一个被调用的节点
workflow.set_entry_point("agent")
# 添加条件边
workflow.add_conditional_edges(
# 首先,定义起始节点。我们使用`agent`。
# 这意味着这些边是在调用`agent`节点后采取的。
"agent",
# 接下来,传递决定下一个调用节点的函数。
should_continue,
)
# 添加从`tools`到`agent`的普通边。
# 这意味着在调用`tools`后,接下来调用`agent`节点。
workflow.add_edge("tools", 'agent')
# 初始化内存以在图运行之间持久化状态
checkpointer = MemorySaver()
# 5.编译图
# 这将其编译成一个LangChain可运行对象,
# 这意味着你可以像使用其他可运行对象一样使用它。
# 注意,我们(可选地)在编译图时传递内存
app = workflow.compile(checkpointer=checkpointer)
# 6.执行图,使用可运行对象
final_state = app.invoke(
{"messages": [HumanMessage(content="上海的天气怎么样?")]},
config={"configurable": {"thread_id": 42}}
)
# 从 final_state 中获取最后一条消息的内容
result = final_state["messages"][-1].content
print(result)
final_state = app.invoke(
{"messages": [HumanMessage(content="我问的那个城市?")]},
config={"configurable": {"thread_id": 42}}
)
result = final_state["messages"][-1].content
print(result)
# 将生成的图片保存到文件
graph_png = app.get_graph().draw_mermaid_png()
with open("langgraph_hello.png", "wb") as f:
f.write(graph_png)
现在,当我们传递相同的 "thread_id" 时,对话上下⽂将通过保存的状态(即存储的消息列 表)保留下来。
final_state = app.invoke(
{"messages": [HumanMessage(content="我问的那个城市?")]},
config={"configurable": {"thread_id": 42}}
)
result = final_state["messages"][-1].content
print(result)
逐步分解
1. 初始化模型和⼯具
我们使⽤ ChatOpenAI 作为我们的 LLM。注意:我们需要确保模型知道可以使⽤哪些 ⼯具。我们可以通过将 LangChain ⼯具转换为 OpenAI ⼯具调⽤格式来完成此操作,⽅法是使⽤ .bind_tools() ⽅法。 我们定义要使⽤的⼯具——在本例中是搜索⼯具。创建⾃⼰的⼯具⾮常容易——请参阅此 处的⽂档了解如何操作此处。
2. ⽤状态初始化图
我们通过传递状态模式(在本例中为 MessagesState )来初始化图( StateGrap h )。 MessagesState 是⼀个预构建的状态模式,它具有⼀个属性,⼀个 LangChain Mes sage 对象列表,以及将每个节点的更新合并到状态中的逻辑。
3. 定义图节点
我们需要两个主要节点 agent 节点:负责决定采取什么(如果有)⾏动。 调⽤⼯具的 tools 节点:如果代理决定采取⾏动,此节点将执⾏该⾏动。
4. 定义⼊⼝点和图边
⾸先,我们需要设置图执⾏的⼊⼝点—— agent 节点。 然后,我们定义⼀个普通边和⼀个条件边。条件边意味着⽬的地取决于图状态( MessageStat e )的内容。在本例中,⽬的地在代理(LLM)决定之前是未知的。 条件边:调⽤代理后,我们应该要么 a. 如果代理说要采取⾏动,则运⾏⼯具 b. 如果代理没有要求运⾏⼯具,则完成(回复⽤户)。 普通边:调⽤⼯具后,图应该始终返回到代理以决定下⼀步操作。
5. 编译图
当我们编译图时,我们将其转换为 LangChain Runnable,这会⾃动启⽤使⽤您的输⼊调 ⽤ .invoke() 、 .stream() 和 .batch() 。 我们还可以选择传递检查点对象以在图运⾏之间持久化状态,并启⽤内存、“⼈机交互”⼯ 作流、时间旅⾏等等。在本例中,我们使⽤ MemorySaver ——⼀个简单的内存中检查点。
6. 执⾏图
a. LangGraph 将输⼊消息添加到内部状态,然后将状态传递给⼊⼝点节点 "agent" 。
b. "agent" 节点执⾏,调⽤聊天模型。
c. 聊天模型返回 AIMessage 。LangGraph 将其添加到状态中。
d. 图循环以下步骤,直到 AIMessage 上不再有 tool_calls 。 如果 AIMessage 具有 tool_calls ,则 "tools" 节点执⾏。 "agent" 节点再次执⾏并返回 AIMessage 。
e. 执⾏进度到特殊的 END 值,并输出最终状态。因此,我们得到所有聊天消息的列表作 为输出。
Graph(图)
LangGraph 的核⼼是将代理⼯作流建模为图。你可以使⽤三个关键组件来定义代理的⾏为 1. 状态:⼀个共享的数据结构,表示应⽤程序的当前快照。它可以是任何 Python 类型,但通常 是 TypedDict 或 Pydantic BaseModel 。 2. 节点:编码代理逻辑的 Python 函数。它们接收当前 状态 作为输⼊,执⾏⼀些计算或副作 ⽤,并返回⼀个更新的 状态 。 3. 边:Python 函数,根据当前 状态 确定要执⾏的下⼀个 节点 。它们可以是条件分⽀或固 定转换。 通过组合 节点 和 边 ,你可以创建复杂的循环⼯作流,随着时间的推移发展 状态 。但是, 真正的⼒量来⾃于 LangGraph 如何管理 状态 。需要强调的是: 节点 和 边 不过是 Python 函数——它们可以包含 LLM 或简单的 Python 代码。 简⽽⾔之:节点完成⼯作。边指示下⼀步要做什么。 LangGraph 的底层图算法使⽤ 消息传递 来定义⼀个通⽤程序。当⼀个节点完成其操作时,它会 沿着⼀条或多条边向其他节点发送消息。这些接收节点然后执⾏其函数,将结果消息传递给下⼀组 节点,并且该过程继续进⾏。受到 Google 的 Pregel 系统的启发,该程序以离散的“超级步骤”进⾏。
超级步骤可以被认为是图节点上的单个迭代。并⾏运⾏的节点属于同⼀个超级步骤,⽽顺序运⾏的 节点则属于不同的超级步骤。在图执⾏开始时,所有节点都处于 inactive 状态。当节点在任 何传⼊边(或“通道”)上收到新消息(状态)时,它将变为 active 状态。然后,活动节点运 ⾏其函数并响应更新。在每个超级步骤结束时,没有传⼊消息的节点通过将其标记为 inactiv e 来投票 halt 。当所有节点都处于 inactive 状态且没有消息在传输中时,图执⾏终⽌。
StateGraph
StateGraph 类是使⽤的主要图类。它由⽤户定义的 状态 对象参数化。
from langgraph.graph import StateGraph
from typing_extensions import TypedDict
class MyState(TypedDict)
...
graph = StateGraph(MyState)
基类: 图 ⼀个图,其节点通过读取和写⼊共享状态进⾏通信。每个节点的签名是 State -> Partial. 每个状态键可以选择性地使⽤⼀个 reducer 函数进⾏注释,该函数将⽤于聚合从多个节点接收到 的该键的值。reducer 函数的签名是 (Value, Value) -> Value。 参数 state_schema ( 类型[任何] , 默认值: None ) – 定义状态的模式类。 config_schema ( 可选[类型[任何]] , 默认值: None ) – 定义配置的模式类。使⽤此⽅法在您的 API 中公开可配置参数。
示例:
# 从langgraph.graph模块导入START和StateGraph
from langgraph.graph import START, StateGraph
# 定义一个节点函数my_node,接收状态和配置,返回新的状态
def my_node(state, config):
return {"x": state["x"] + 1,"y": state["y"] + 2}
# 创建一个状态图构建器builder,使用字典类型作为状态类型
builder = StateGraph(dict)
# 向构建器中添加节点my_node,节点名称将自动设置为'my_node'
builder.add_node(my_node) # node name will be 'my_node'
# 添加一条边,从START到'my_node'节点
builder.add_edge(START, "my_node")
# 编译状态图,生成可执行的图
graph = builder.compile()
print(graph)
# 调用编译后的图,传入初始状态{"x": 1}
print(graph.invoke({"x": 1,"y":2}))
Compiling your graph(编译你的图)
要构建你的图,你⾸先定义状态,然后添加节点和边,最后进⾏编译。编译图究竟是什么,为什么 需要它? 编译是⼀个⾮常简单的步骤。它对图的结构进⾏⼀些基本检查(没有孤⽴的节点等等)。它也是你 可以指定运⾏时参数的地⽅,例如检查点和断点。你只需调⽤.compile⽅法即可编译你的图。
#你必须在使⽤图之前编译它。
graph = graph_builder.compile(...)
State(状态)
定义图时,你做的第⼀件事是定义图的 状态 。 状态 包含图的 模式 以及 归约器函数,它们指 定如何将更新应⽤于状态。 状态 的模式将是图中所有 节点 和 边 的输⼊模式,可以是 Ty pedDict 或者 Pydantic 模型。所有 节点 将发出对 状态 的更新,这些更新然后使⽤指 定的 归约器 函数进⾏应⽤。
Schema(模式)
指定图模式的主要⽂档化⽅法是使⽤ TypedDict 。但是,我们也⽀持 使⽤ Pydantic BaseModel 作为你的图状态,以添加默认值和其他数据验证。 默认情况下,图将具有相同的输⼊和输出模式。如果你想更改这⼀点,你也可以直接指定显式输⼊和输出模式。当你有许多键,其中⼀些是显式⽤于输⼊,⽽另⼀些是⽤于输出时,这很有⽤。查看此笔记本,了解如何使⽤。 默认情况下,图中的所有节点都将共享相同的状态。这意味着它们将读取和写⼊相同的状态通道。 可以在图中创建节点写⼊私有状态通道,⽤于内部节点通信——查看 此笔记本,了解如何执⾏此操作。
Reducers(归约器)
归约器是理解节点更新如何应⽤于 状态 的关键。 状态 中的每个键都有其⾃⼰的独⽴归约器函 数。如果未显式指定归约器函数,则假设对该键的所有更新都应该覆盖它。存在⼏种不同类型的归 约器,从默认类型的归约器开始
Default Reducer(默认归约器)
这两个示例展示了如何使⽤默认归约器
from typing import TypedDict, List, Dict, Any
class State(TypedDict):
foo: int
bar: List[str]
def update_state(current_state: State, updates: Dict[str, Any]) -> State:
# 创建一个新的状态字典
new_state = current_state.copy()
# 更新状态字典中的值
new_state.update(updates)
return new_state
# 初始状态
state: State = {"foo": 1, "bar": ["hi"]}
# 第一个节点返回的更新
node1_update = {"foo": 2}
state = update_state(state, node1_update)
print(state) # 输出: {'foo': 2, 'bar': ['hi']}
# 第二个节点返回的更新
node2_update = {"bar": ["bye"]}
state = update_state(state, node2_update)
print(state) # 输出: {'foo': 2, 'bar': ['bye']}
在此示例中,没有为任何键指定归约器函数。假设图的输⼊是 {"foo": 1, "bar": ["h i"]} 。然后,假设第⼀个 节点 返回 {"foo": 2} 。这被视为对状态的更新。请注意, 节 点 不需要返回整个 状态 模式——只需更新即可。应⽤此更新后, 状态 则变为 {"foo": 2, "bar": ["hi"]} 。如果第⼆个节点返回 {"bar": ["bye"]} ,则 状态 则变为 {"foo": 2, "bar": ["bye"]}
Nodes(节点)
在 LangGraph 中,节点通常是 Python 函数(同步或 async ),其中第⼀个位置参数是状态, (可选地),第⼆个位置参数是“配置”,包含可选的可配置参数(例如 thread_id )。 类似于 NetworkX ,您可以使⽤add_node⽅法将这些节点添加到图形中
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, START
from langgraph.graph import END
# 初始化 StateGraph,状态类型为字典
graph = StateGraph(dict)
# 定义节点
def my_node(state: dict, config: RunnableConfig):
print("In node: ", config["configurable"]["user_id"])
return {"results": f"Hello, {state['input']}!"}
def my_other_node(state: dict):
return state
# 将节点添加到图中
graph.add_node("my_node", my_node)
graph.add_node("other_node", my_other_node)
# 连接节点以确保它们是可达的
graph.add_edge(START, "my_node")
graph.add_edge("my_node", "other_node")
graph.add_edge("other_node", END)
# 编译图
print(graph.compile())
app = graph.compile();
# 将生成的图片保存到文件
graph_png = app.get_graph().draw_mermaid_png()
with open("node_case.png", "wb") as f:
f.write(graph_png)在幕后,函数被转换为RunnableLambda,它为您的函数添加了批处理和异步⽀持,以及本地跟 踪和调试。 如果您在没有指定名称的情况下将节点添加到图形中,它将被赋予⼀个默认名称,该名称等同于函 数名称。
graph.add_node(my_node)
# You can then create edges to/from this node by referencing it as `"my_nod
e"`
START 节点
START 节点是⼀个特殊节点,它代表将⽤户输⼊发送到图形的节点。引⽤此节点的主要⽬的是 确定哪些节点应该⾸先被调⽤。
from langgraph.graph import START
graph.add_edge(START, "my_node")
graph.add_edge("my_node", "other_node")END 节点
END 节点是⼀个特殊节点,它代表⼀个终端节点。当您想要指定哪些边在完成操作后没有动作 时,会引⽤此节点。
from langgraph.graph import END
graph.add_edge("other_node", END)
Edges(边)
边定义了逻辑如何路由以及图形如何决定停⽌。这是您的代理如何⼯作以及不同节点如何相互通信 的重要部分。有⼀些关键类型的边 普通边:直接从⼀个节点到下⼀个节点。 条件边:调⽤⼀个函数来确定下⼀个要转到的节点。 ⼊⼝点:⽤户输⼊到达时⾸先调⽤的节点。 条件⼊⼝点:调⽤⼀个函数来确定⽤户输⼊到达时⾸先调⽤的节点。⼀个节点可以有多个输出边。如果⼀个节点有多个输出边,则所有这些⽬标节点将在下⼀个超级步 骤中并⾏执⾏。
普通边
如果您总是想从节点 A 到节点 B,您可以直接使⽤add_edge⽅法。
#示例:edges_case.py
graph.add_edge("node_a", "node_b")条件边
如果您想选择性地路由到⼀个或多个边(或选择性地终⽌),您可以使⽤add_conditional_edges ⽅法。此⽅法接受节点的名称和⼀个“路由函数”,该函数将在该节点执⾏后被调⽤
graph.add_conditional_edges("node_a", routing_function)
类似于节点, routing_function 接受图形的当前 state 并返回⼀个值。 默认情况下,返回值 routing_function ⽤作要将状态发送到下⼀个节点的节点名称(或节点 列表)。所有这些节点将在下⼀个超级步骤中并⾏运⾏。 您可以选择提供⼀个字典,该字典将 routing_function 的输出映射到下⼀个节点的名称。
graph.add_conditional_edges("node_a", routing_function, {True: "node_b", Fa
lse: "node_c"})
⼊⼝点
⼊⼝点是图形启动时运⾏的第⼀个节点。您可以从虚拟的START节点使⽤add_edge⽅法到要执⾏ 的第⼀个节点,以指定进⼊图形的位置。
from langgraph.graph import START
graph.add_edge(START, "my_node")
条件⼊⼝点
条件⼊⼝点允许您根据⾃定义逻辑从不同的节点开始。您可以从虚拟的START节点使⽤ add_conditional_edges来实现这⼀点。
from langgraph.graph import START
graph.add_conditional_edges(START, routing_function)
您可以选择提供⼀个字典,该字典将 routing_function 的输出映射到下⼀个节点的名称。
graph.add_conditional_edges(START, routing_my,{True: "my_node", False: "oth
er_node"})
edges.case.py:
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, START, END
# 初始化 StateGraph,状态类型为字典
graph = StateGraph(dict)
# 定义节点
def my_node(state: dict, config: RunnableConfig):
print("In node: ", config["configurable"]["user_id"])
return {"results": f"Hello, {state['input']}!"}
def other_node(state: dict):
return state
def node_a(state: dict):
return {"result": "This is node B"}
def node_b(state: dict):
return {"result": "This is node B"}
def node_c(state: dict):
return {"result": "This is node C"}
# 将节点添加到图中
graph.add_node("my_node", my_node)
graph.add_node("other_node", other_node)
graph.add_node("node_a", node_a)
graph.add_node("node_b", node_b)
graph.add_node("node_c", node_c)
# 普通边
graph.add_edge("my_node", "other_node")
graph.add_edge("other_node", "node_a")
# 条件边和条件路由函数
def routing_function(state: dict):
# 假设我们根据 state 中的某个键值来决定路由
# 如果 state 中有 'route_to_b' 且其值为 True,则路由到 node_b,否则路由到 node_c
return state.get('route_to_b', False)
graph.add_edge("node_b", END)
graph.add_edge("node_c", END)
#条件边
graph.add_conditional_edges("node_a", routing_function, {True: "node_b", False: "node_c"})
graph.add_edge(START, "my_node")
#条件入口点
#graph.add_conditional_edges(START, routing_function, {True: "node_b", False: "node_c"})
#条件入口点
def routing_my(state: dict):
# 假设我们根据 state 中的某个键值来决定路由
# 如果 state 中有 'route_to_b' 且其值为 True,则路由到 node_b,否则路由到 node_c
return state.get('route_to_my', False)
# 条件入口点
# graph.add_conditional_edges(START, routing_my,{True: "my_node", False: "other_node"})
# 编译图
app = graph.compile()
# 将生成的图片保存到文件
graph_png = app.get_graph().draw_mermaid_png()
with open("edges_case.png", "wb") as f:
f.write(graph_png)
LangGraph 实现:持久化, Human-in-the-loop Persistence(持久化) 添加持久性内存
checkpointer(检查点)
LangGraph 具有⼀个内置的持久化层,通过检查点实现。当您将检查点与图形⼀起使⽤时,您可 以与该图形的状态进⾏交互。当您将检查点与图形⼀起使⽤时,您可以与图形的状态进⾏交互并管 理它。检查点在每个超级步骤中保存图形状态的检查点,从⽽实现⼀些强⼤的功能
⾸先,检查点通过允许⼈类检查、中断和批准步骤来促进⼈机交互⼯作流⼯作流。检查点对于这些 ⼯作流是必需的,因为⼈类必须能够在任何时候查看图形的状态,并且图形必须能够在⼈类对状态 进⾏任何更新后恢复执⾏。 其次,它允许在交互之间进⾏“记忆”。您可以使⽤检查点创建线程并在图形执⾏后保存线程的状 态。在重复的⼈类交互(例如对话)的情况下,任何后续消息都可以发送到该检查点,该检查点将 保留对其以前消息的记忆。 许多 AI 应⽤程序需要内存来跨多个交互共享上下⽂。在 LangGraph 中,通过 检查点 为任何 StateGraph 提供内存。 在创建任何 LangGraph ⼯作流时,您可以通过以下⽅式设置它们以持久保存其状态 1. ⼀个 检查点,例如 MemorySaver 2. 在编译图时调⽤ compile(checkpointer=my_checkpointer) 。 示例
# 导入所需的类型注解和模块
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph.message import add_messages
# 定义一个状态类,包含一个消息列表,消息列表带有 add_messages 注解
class State(TypedDict):
messages: Annotated[list, add_messages]
# 从 langchain_core.tools 导入工具装饰器
from langchain_core.tools import tool
# 定义一个名为 search 的工具函数,用于模拟网络搜索
@tool
def search(query: str):
"""Call to surf the web."""
# 这是实际实现的占位符
return ["The answer to your question lies within."]
# 将工具函数存入列表
tools = [search]
from langgraph.prebuilt import ToolNode
# 创建一个 ToolNode 实例,传入工具列表
tool_node = ToolNode(tools)
# 从 langchain_openai 导入 ChatOpenAI 模型
from langchain_openai import ChatOpenAI
# 创建一个 ChatOpenAI 模型实例,设置 streaming=True 以便可以流式传输 tokens
model = ChatOpenAI(temperature=0, streaming=True)
# 将工具绑定到模型上
bound_model = model.bind_tools(tools)
# 导入 Literal 类型
from typing import Literal
# 定义一个函数,根据状态决定是否继续执行
def should_continue(state: State) -> Literal["action", "__end__"]:
"""Return the next node to execute."""
last_message = state["messages"][-1]
# 如果没有函数调用,则结束
if not last_message.tool_calls:
return "__end__"
# 否则继续执行
return "action"
# 定义一个函数调用模型
def call_model(state: State):
response = model.invoke(state["messages"])
# 返回一个列表,因为这将被添加到现有列表中
return {"messages": response}
# 从 langgraph.graph 导入 StateGraph 和 START
from langgraph.graph import StateGraph, START
# 定义一个新的图形工作流
workflow = StateGraph(State)
# 添加两个节点,分别是 agent 和 action
workflow.add_node("agent", call_model)
workflow.add_node("action", tool_node)
# 设置入口点为 agent
workflow.add_edge(START, "agent")
# 添加条件边,根据 should_continue 函数决定下一个节点
workflow.add_conditional_edges(
"agent",
should_continue,
)
# 添加从 action 到 agent 的普通边
workflow.add_edge("action", "agent")
# 从 langgraph.checkpoint.memory 导入 MemorySaver
from langgraph.checkpoint.memory import MemorySaver
# 创建一个 MemorySaver 实例
memory = MemorySaver()
# 编译工作流,生成一个 LangChain Runnable
app = workflow.compile(checkpointer=memory)
# 将生成的图片保存到文件
graph_png = app.get_graph().draw_mermaid_png()
with open("persistence_case.png", "wb") as f:
f.write(graph_png)
# 从 langchain_core.messages 导入 HumanMessage
from langchain_core.messages import HumanMessage
# 设置配置参数
config = {"configurable": {"thread_id": "2"}}
# 创建一个 HumanMessage 实例,内容为 "hi! I'm bob"
input_message = HumanMessage(content="hi! I'm bob")
# 在流模式下运行应用程序,传入消息和配置,逐个打印每个事件的最后一条消息
for event in app.stream({"messages": [input_message]}, config, stream_mode="values"):
event["messages"][-1].pretty_print()
# 创建一个 HumanMessage 实例,内容为 "what is my name?"
input_message = HumanMessage(content="what is my name?")
# 在流模式下运行应用程序,传入消息和配置,逐个打印每个事件的最后一条消息
for event in app.stream({"messages": [input_message]}, config, stream_mode="values"):
event["messages"][-1].pretty_print()
# 创建一个 HumanMessage 实例,内容为 "what is my name?"
input_message = HumanMessage(content="what is my name?")
# 在流模式下运行应用程序,传入消息和新的配置,逐个打印每个事件的最后一条消息
for event in app.stream(
{"messages": [input_message]},
{"configurable": {"thread_id": "3"}},
stream_mode="values",
):
event["messages"][-1].pretty_print()
# 创建一个 HumanMessage 实例,内容为 "You forgot?"
input_message = HumanMessage(content="You forgot??")
# 在流模式下运行应用程序,传入消息和原来的配置,逐个打印每个事件的最后一条消息
for event in app.stream(
{"messages": [input_message]},
{"configurable": {"thread_id": "2"}},
stream_mode="values",
):
event["messages"][-1].pretty_print()
这适⽤于 StateGraph 及其所有⼦类,例如 MessageGraph。 以下是⼀个示例。
注意
在本操作指南中,我们将从头开始创建我们的代理,以保持透明度(但冗⻓)。您可以使⽤ cre ate_react_agent(model, tools=tool, checkpointer=checkpointer) (API ⽂档) 构造函数完成类似的功能。如果您习惯使⽤ LangChain 的 AgentExecutor 类,这可能更合适。
设置
⾸先,我们需要安装所需的软件包
%pip install --quiet -U langgraph langchain_openai接下来,我们需要设置 OpenAI(我们将使⽤的 LLM)和 Tavily(我们将使⽤的搜索⼯具)的 API 密钥 可选地,我们可以设置 LangSmith 跟踪 的 API 密钥,这将为我们提供⼀流的可观察性。
设置状态
状态是所有节点的接⼝。 我们⾸先将定义要使⽤的⼯具。对于这个简单的示例,我们将创建⼀个占位符搜索引擎。但是,创 建⾃⼰的⼯具⾮常容易 - 请参阅 此处 的⽂档了解如何操作。
# 导⼊所需的类型注解和模块
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph.message import add_messages
# 定义⼀个状态类,包含⼀个消息列表,消息列表带有 add_messages 注解
class State(TypedDict):
messages: Annotated[list, add_messages]
设置工具
我们⾸先将定义要使⽤的⼯具。对于这个简单的示例,我们将创建⼀个占位符搜索引擎。
# 从 langchain_core.tools 导⼊⼯具装饰器
from langchain_core.tools import tool
# 定义⼀个名为 search 的⼯具函数,⽤于模拟⽹络搜索
@tool
def search(query: str):
"""Call to surf the web."""
# 这是实际实现的占位符
return ["The answer to your question lies within."]
# 将⼯具函数存⼊列表
tools = [search]现在我们可以创建我们的 ToolNode。此对象实际上运⾏LLM 要求使⽤的⼯具(即函数)。
from langgraph.prebuilt import ToolNode
# 创建⼀个 ToolNode 实例,传⼊⼯具列表
tool_node = ToolNode(tools)
设置模型
现在我们需要加载 聊天模型 来为我们的代理提供动⼒。对于以下设计,它必须满⾜两个条件 1. 它应该与消息⼀起使⽤(因为我们的状态包含聊天消息列表) 2. 它应该与 ⼯具调⽤ ⼀起使⽤。
注意
这些模型要求不是使⽤ LangGraph 的⼀般要求 - 它们只是此特定示例的要求。
# 从 langchain_openai 导⼊ ChatOpenAI 模型
from langchain_openai import ChatOpenAI
# 创建⼀个 ChatOpenAI 模型实例,设置 streaming=True 以便可以流式传输 tokens
model = ChatOpenAI(temperature=0, streaming=True)
完成此操作后,我们应该确保模型知道它可以使⽤这些⼯具。我们可以通过将 LangChain ⼯具转 换为 OpenAI 函数调⽤格式,然后将其绑定到模型类来实现这⼀点。
# 将⼯具绑定到模型上
bound_model = model.bind_tools(tools)
定义图
现在我们需要在我们的图中定义⼏个不同的节点。在 langgraph 中,节点可以是函数或 可运 ⾏的。我们需要为此定义两个主要节点 1. 代理:负责决定要采取哪些(如果有)操作。 2. ⼀个⽤于调⽤⼯具的函数:如果代理决定采取操作,则此节点将执⾏该操作。 我们还需要定义⼀些边。其中⼀些边可能是条件的。它们是条件的原因是,基于节点的输出,可能 会采⽤⼏种路径之⼀。在运⾏该节点之前,⽆法知道要采⽤哪条路径(LLM 决定)。 1. 条件边:在调⽤代理后,我们应该:a. 如果代理说要采取操作,则应调⽤调⽤⼯具的函数 b. 如果代理说它已完成,则应完成 2. 普通边:在调⽤⼯具后,它应该始终返回到代理以决定下⼀步要做什么 让我们定义节点,以及⼀个函数来决定如何采取哪些条件边。
# 导⼊ Literal 类型
from typing import Literal
# 定义⼀个函数,根据状态决定是否继续执⾏
def should_continue(state: State) -> Literal["action", "__end__"]:
"""Return the next node to execute."""
last_message = state["messages"][-1]
# 如果没有函数调⽤,则结束
if not last_message.tool_calls:
return "__end__"
# 否则继续执⾏
return "action"
# 定义⼀个函数调⽤模型
def call_model(state: State):
response = model.invoke(state["messages"])
# 返回⼀个列表,因为这将被添加到现有列表中
return {"messages": response}
现在我们可以将所有内容放在⼀起并定义图!
# 从 langgraph.graph 导⼊ StateGraph 和 START
from langgraph.graph import StateGraph, START
# 定义⼀个新的图形⼯作流
workflow = StateGraph(State)
# 添加两个节点,分别是 agent 和 action
workflow.add_node("agent", call_model)
workflow.add_node("action", tool_node)
# 设置⼊⼝点为 agent
workflow.add_edge(START, "agent")
# 添加条件边,根据 should_continue 函数决定下⼀个节点
workflow.add_conditional_edges(
"agent",
should_continue,
)
# 添加从 action 到 agent 的普通边
workflow.add_edge("action", "agent")
持久性
要添加持久性,我们在编译图时传⼊⼀个检查点
# 从 langgraph.checkpoint.memory 导⼊ MemorySaver
from langgraph.checkpoint.memory import MemorySaver
# 创建⼀个 MemorySaver 实例
memory = MemorySaver()
# 编译⼯作流,⽣成⼀个 LangChain Runnable
app = workflow.compile(checkpointer=memory)
注意
如果您使⽤的是 LangGraph Cloud,则⽆需在编译图时传递检查点,因为它会⾃动完成。
# 将⽣成的图⽚保存到⽂件
graph_png = app.get_graph().draw_mermaid_png()
with open("persistence_case.png", "wb") as f:
f.write(graph_png) 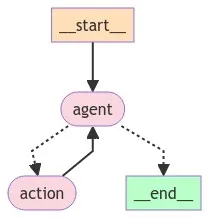
与代理交互
现在我们可以与代理进⾏交互,并看到它会记住以前的消息!
# 从 langchain_core.messages 导⼊ HumanMessage
from langchain_core.messages import HumanMessage
# 设置配置参数
config = {"configurable": {"thread_id": "2"}}
# 创建⼀个 HumanMessage 实例,内容为 "hi! I'm bob"
input_message = HumanMessage(content="hi! I'm bob")
# 在流模式下运⾏应⽤程序,传⼊消息和配置,逐个打印每个事件的最后⼀条消息
for event in app.stream({"messages": [input_message]}, config, stream_mode
="values"):
event["messages"][-1].pretty_print()
# 创建⼀个 HumanMessage 实例,内容为 "what is my name?"
input_message = HumanMessage(content="what is my name?")
# 在流模式下运⾏应⽤程序,传⼊消息和配置,逐个打印每个事件的最后⼀条消息
for event in app.stream({"messages": [input_message]}, config, stream_mode
="values"):
event["messages"][-1].pretty_print()
如果我们想开始新的对话,可以传⼊不同的线程 ID。瞧!所有的记忆都消失了!
# 创建⼀个 HumanMessage 实例,内容为 "what is my name?" input_message = HumanMessage(content="what is my name?") # 在流模式下运⾏应⽤程序,传⼊消息和新的配置,逐个打印每个事件的最后⼀条消息 for event in app.stream( {"messages": [input_message]}, {"configurable": {"thread_id": "3"}}, stream_mode="values", ): event["messages"][-1].pretty_print()所有检查点都将持久保存到检查点,因此您可以随时恢复以前的线程
# 创建⼀个 HumanMessage 实例,内容为 "You forgot??"
input_message = HumanMessage(content="You forgot??")
# 在流模式下运⾏应⽤程序,传⼊消息和原来的配置,逐个打印每个事件的最后⼀条消息
for event in app.stream(
{"messages": [input_message]},
{"configurable": {"thread_id": "2"}},
stream_mode="values",
):
event["messages"][-1].pretty_print()
Human-in-the-loop(⼈机交互)
添加断言
在某些节点执⾏之前或之后设置断点通常很有⽤。这可以⽤来在继续之前等待⼈⼯批准。当您“编 译”图形时,可以设置这些断点。您可以在节点执⾏之前(使⽤ interrupt_before )或节点 执⾏之后(使⽤ interrupt_after )设置断点。 使⽤断点时,您必须使⽤检查点。这是因为您的图形需要能够恢复执⾏。 为了恢复执⾏,您可以使⽤ None 作为输⼊调⽤您的图。
# Initial run of graph
graph.invoke(inputs, config=config)
# Let's assume it hit a breakpoint somewhere, you can then resume by passin
g in None
graph.invoke(None, config=config)⼈机交互 (HIL) 在 代理系统 中⾄关重要。 断点 是⼀种常⻅的 HIL 交互模式,允许图在特定步骤 停⽌并寻求⼈为批准后再继续执⾏(例如,对于敏感操作)。 断点建⽴在 LangGraph 检查点 之上,检查点在每个节点执⾏后保存图的状态。 检查点保存在 线 程 中,这些线程保存图状态,并且可以在图执⾏完成后访问。 这使得图执⾏可以在特定点暂停, 等待⼈为批准,然后从最后⼀个检查点恢复执⾏。
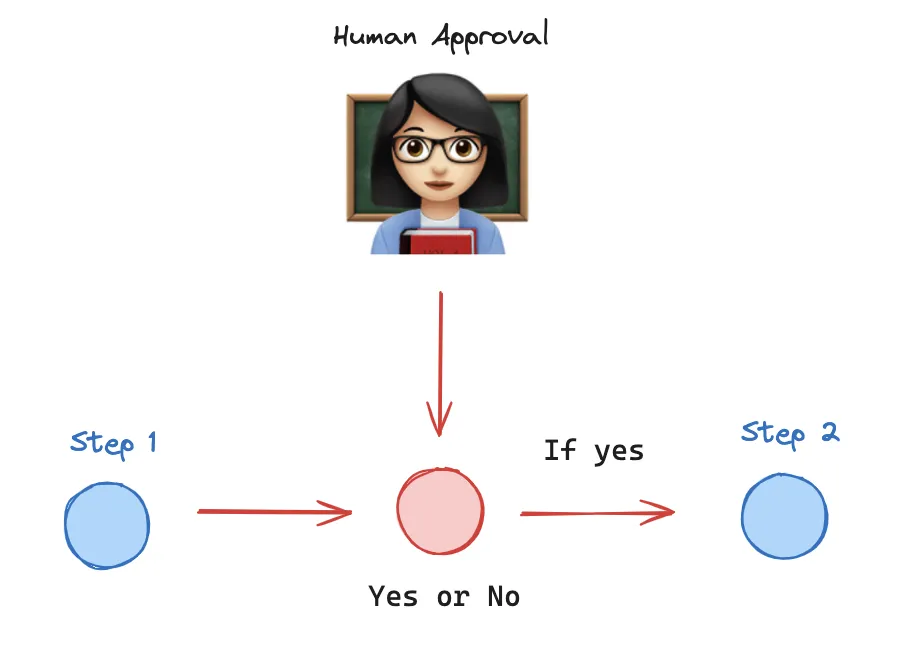
让我们看看它的基本⽤法。 下⾯,我们做两件事 1. 我们使⽤ interrupt_before 指定步骤,来指定 断点。 2. 我们设置⼀个检查点来保存图的状态。
from typing import TypedDict
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph, START, END
class State(TypedDict):
input: str
def step_1(state):
print("---Step 1---")
pass
def step_2(state):
print("---Step 2---")
pass
def step_3(state):
print("---Step 3---")
pass
builder = StateGraph(State)
builder.add_node("step_1", step_1)
builder.add_node("step_2", step_2)
builder.add_node("step_3", step_3)
builder.add_edge(START, "step_1")
builder.add_edge("step_1", "step_2")
builder.add_edge("step_2", "step_3")
builder.add_edge("step_3", END)
# Set up memory
memory = MemorySaver()
# Add
graph = builder.compile(checkpointer=memory, interrupt_before=["step_3"])
# Input
initial_input = {"input": "hello world"}
# Thread
thread = {"configurable": {"thread_id": "1"}}
# 运行graph,直到第一次中断
for event in graph.stream(initial_input, thread, stream_mode="values"):
print(event)
user_approval = input("Do you want to go to Step 3? (yes/no): ")
if user_approval.lower() == "yes":
# If approved, continue the graph execution
for event in graph.stream(None, thread, stream_mode="values"):
print(event)
else:
print("Operation cancelled by user.")
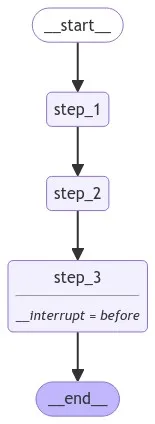
我们为检查点创建⼀个 线程 ID。 我们运⾏到步骤 3,如 interrupt_before 中定义。 在⽤户输⼊/批准后,我们恢复执⾏,⽅法是⽤ None 调⽤图。
Agent 使⽤案例: Multi-Agent Systems, Planning Agent
Multi-Agent Systems(多代理系统)
协作
单个代理通常可以使⽤少量⼯具在⼀个域内有效地运⾏,但即使使⽤像 gpt-4 这样的强⼤模 型,它在使⽤许多⼯具时也可能效率较低。 解决复杂任务的⼀种⽅法是使⽤“分⽽治之”的⽅法:为每个任务或域创建⼀个专⻔的代理,并将 任务路由到正确的“专家”。 此笔记本(受 Wu 等⼈撰写的论⽂ AutoGen:通过多代理对话实现下⼀代 LLM 应⽤ 的启发)展 示了⼀种使⽤ LangGraph 进⾏此操作的⽅法。 ⽣成的图将类似于以下图
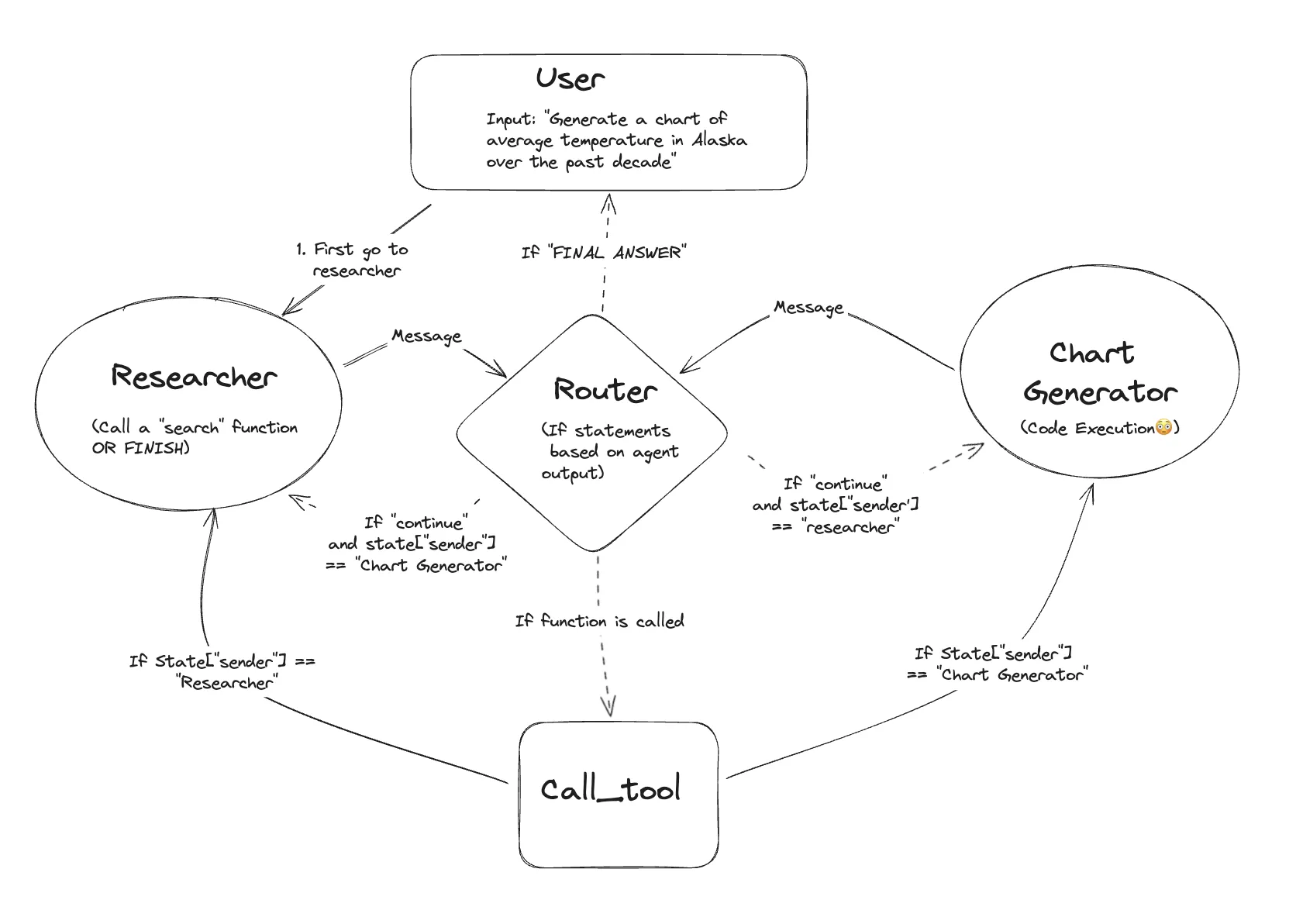
在我们开始之前,快速说明⼀下:以下展示如何在 LangGraph 中实现某些设计模式。如果模式适 合您的需求
%pip install -U langchain langchain_openai langsmith pandas langchain_exper
imental matplotlib langgraph langchain_coresetx TAVILY_API_KEY ""
# Optional, add tracing in LangSmith
setx LANGCHAIN_TRACING_V2 "true"
setx LANGCHAIN_API_KEY ""
创建代理
以下辅助函数将帮助创建代理。这些代理将成为图中的节点。 如果您只想查看图的外观,可以跳过此步骤。完整代码如下:
# 导入基本消息类、用户消息类和工具消息类
from langchain_core.messages import (
BaseMessage,
HumanMessage,
ToolMessage,
)
# 导入聊天提示模板和消息占位符
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# 导入状态图相关的常量和类
from langgraph.graph import END, StateGraph, START
# 定义一个函数,用于创建代理
def create_agent(llm, tools, system_message: str):
"""创建一个代理。"""
# 创建一个聊天提示模板
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你是一个有帮助的AI助手,与其他助手合作。"
" 使用提供的工具来推进问题的回答。"
" 如果你不能完全回答,没关系,另一个拥有不同工具的助手"
" 会接着你的位置继续帮助。执行你能做的以取得进展。"
" 如果你或其他助手有最终答案或交付物,"
" 在你的回答前加上FINAL ANSWER,以便团队知道停止。"
" 你可以使用以下工具: {tool_names}。\n{system_message}",
),
# 消息占位符
MessagesPlaceholder(variable_name="messages"),
]
)
# 传递系统消息参数
prompt = prompt.partial(system_message=system_message)
# 传递工具名称参数
prompt = prompt.partial(tool_names=", ".join([tool.name for tool in tools]))
# 绑定工具并返回提示模板
return prompt | llm.bind_tools(tools)
# 导入注解类型
from typing import Annotated
# 导入Tavily搜索工具
from langchain_community.tools.tavily_search import TavilySearchResults
# 导入工具装饰器
from langchain_core.tools import tool
# 导入Python REPL工具
from langchain_experimental.utilities import PythonREPL
# 创建Tavily搜索工具实例,设置最大结果数为5
tavily_tool = TavilySearchResults(max_results=5)
# 警告:这会在本地执行代码,未沙箱化时可能不安全
# 创建Python REPL实例
repl = PythonREPL()
# 定义一个工具函数,用于执行Python代码
@tool
def python_repl(
code: Annotated[str, "要执行以生成图表的Python代码。"],
):
"""使用这个工具来执行Python代码。如果你想查看某个值的输出,
应该使用print(...)。这个输出对用户可见。"""
try:
# 尝试执行代码matplotlib
result = repl.run(code)
except BaseException as e:
# 捕捉异常并返回错误信息
return f"执行失败。错误: {repr(e)}"
# 返回执行结果
result_str = f"成功执行:\n```python\n{code}\n```\nStdout: {result}"
return (
result_str + "\n\n如果你已完成所有任务,请回复FINAL ANSWER。"
)
"""
result_str 值如下
成功执行:
```python
import matplotlib.pyplot as plt
# Data
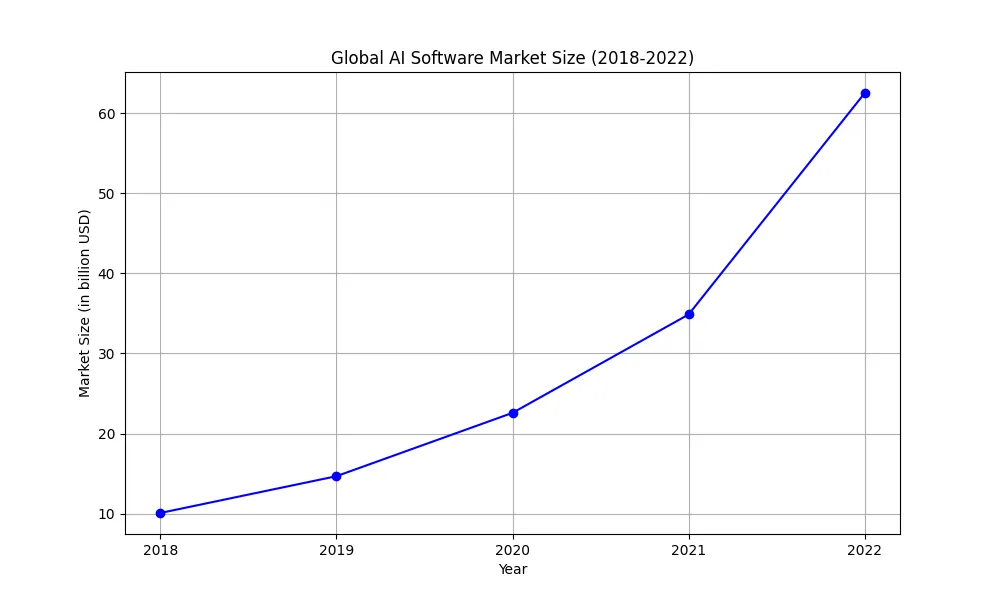
years = ["2018", "2019", "2020", "2021", "2022"]
market_size = [10.1, 14.69, 22.59, 34.87, 62.5]
# Create the plot
plt.figure(figsize=(10, 6))
plt.plot(years, market_size, marker='o', linestyle='-', color='b')
# Adding titles and labels
plt.title("Global AI Software Market Size (2018-2022)")
plt.xlabel("Year")
plt.ylabel("Market Size (in billion USD)")
plt.grid(True)
# Display the plot
plt.show()
```
Stdout:
"""
# 导入操作符和类型注解
import operator
from typing import Annotated, Sequence, TypedDict
# 导入OpenAI聊天模型
from langchain_openai import ChatOpenAI
# 定义一个对象,用于在图的每个节点之间传递
# 我们将为每个代理和工具创建不同的节点
class AgentState(TypedDict):
# messages字段用于存储消息的序列,并且通过 Annotated 和 operator.add 提供了额外的信息,解释如何处理这些消息。
messages: Annotated[Sequence[BaseMessage], operator.add]
# sender 用于存储当前消息的发送者。通过这个字段,系统可以知道当前消息是由哪个代理生成的。
sender: str
# 导入functools模块
import functools
# 导入AI消息类
from langchain_core.messages import AIMessage
# 辅助函数,用于为给定的代理创建节点
def agent_node(state, agent, name):
# 调用代理
result = agent.invoke(state)
# 检查 result 是否是 ToolMessage 类型的实例
if isinstance(result, ToolMessage):
pass
else:
#将 tavily result 转换为 AIMessage 类型,并且将 name 作为发送者的名称附加到消息中。
result = AIMessage(**result.dict(exclude={"type", "name"}), name=name)
return {
"messages": [result],
# 由于我们有一个严格的工作流程,我们可以
# 跟踪发送者,以便知道下一个传递给谁。
"sender": name,
}
# 创建OpenAI聊天模型实例
llm = ChatOpenAI(model="gpt-4o")
# 研究代理和节点
research_agent = create_agent(
llm,
[tavily_tool],
system_message="你应该提供准确的数据供chart_generator使用。",
)
# 创建一个检索节点,部分应用函数(partial function)
# 其中 agent 参数固定为 research_agent,name 参数固定为 "Researcher"。
research_node = functools.partial(agent_node, agent=research_agent, name="Researcher")
# 图表生成器
chart_agent = create_agent(
llm,
[python_repl],
system_message="你展示的任何图表都将对用户可见。",
)
# 创建图表生成节点
chart_node = functools.partial(agent_node, agent=chart_agent, name="chart_generator")
# 导入预构建的工具节点
from langgraph.prebuilt import ToolNode
# 定义工具列表
tools = [tavily_tool, python_repl]
# 创建工具节点
tool_node = ToolNode(tools)
# 任一代理都可以决定结束
from typing import Literal
# 定义路由器函数
def router(state) -> Literal["call_tool", "__end__", "continue"]:
# 这是路由器
messages = state["messages"]
last_message = messages[-1]
# 检查 last_message 是否包含工具调用(tool calls)
if last_message.tool_calls:
return "call_tool"
#如果已经获取到最终答案,则返回结束节点
if "FINAL ANSWER" in last_message.content:
# 任何代理决定工作完成
return "__end__"
return "continue"
# 创建状态图实例
workflow = StateGraph(AgentState)
# 添加研究员节点
workflow.add_node("Researcher", research_node)
# 添加图表生成器节点
workflow.add_node("chart_generator", chart_node)
# 添加工具调用节点
workflow.add_node("call_tool", tool_node)
# 添加条件边
workflow.add_conditional_edges(
"Researcher",
router,
{"continue": "chart_generator", "call_tool": "call_tool", "__end__": END},
)
workflow.add_conditional_edges(
"chart_generator",
router,
{"continue": "Researcher", "call_tool": "call_tool", "__end__": END},
)
# 添加条件边
workflow.add_conditional_edges(
"call_tool",
# 这个 lambda 函数的作用是从状态中获取sender名称,以便在条件边的映射中使用。
# 如果 sender 是 "Researcher",工作流将转移到 "Researcher" 节点。
# 如果 sender 是 "chart_generator",工作流将转移到 "chart_generator" 节点。
lambda x: x["sender"],
{
"Researcher": "Researcher",
"chart_generator": "chart_generator",
},
)
# 添加起始边
workflow.add_edge(START, "Researcher")
# 编译工作流图
graph = workflow.compile()
# 将生成的图片保存到文件
graph_png = graph.get_graph().draw_mermaid_png()
with open("collaboration.png", "wb") as f:
f.write(graph_png)
# 事件流
events = graph.stream(
{
"messages": [
HumanMessage(
content="获取过去5年AI软件市场规模,"
" 然后绘制一条折线图。"
" 一旦你编写好代码,完成任务。"
)
],
},
# 图中最多执行的步骤数
{"recursion_limit": 150},
)
# 打印事件流中的每个状态
for s in events:
print(s)
print("----")
定义⼯具
我们还将定义⼀些代理将在未来使⽤的⼯具
# 导⼊注解类型
from typing import Annotated
# 导⼊Tavily搜索⼯具
from langchain_community.tools.tavily_search import TavilySearchResults
# 导⼊⼯具装饰器
from langchain_core.tools import tool
# 导⼊Python REPL⼯具
from langchain_experimental.utilities import PythonREPL
# 创建Tavily搜索⼯具实例,设置最⼤结果数为5
tavily_tool = TavilySearchResults(max_results=5)
# 警告:这会在本地执⾏代码,未沙箱化时可能不安全
# 创建Python REPL实例
repl = PythonREPL()
# 定义⼀个⼯具函数,⽤于执⾏Python代码
@tool
def python_repl(
code: Annotated[str, "要执⾏以⽣成图表的Python代码。"],
):
"""使⽤这个⼯具来执⾏Python代码。如果你想查看某个值的输出,
应该使⽤print(...)。这个输出对⽤户可⻅。"""
try:
# 尝试执⾏代码
result = repl.run(code)
except BaseException as e:
# 捕捉异常并返回错误信息
return f"执⾏失败。错误: {repr(e)}"
# 返回执⾏结果
result_str = f"成功执⾏:\n```python\n{code}\n```\nStdout: {result}"
return (
result_str + "\n\n如果你已完成所有任务,请回复FINAL ANSWER。"
)
创建图
现在我们已经定义了⼯具并创建了⼀些辅助函数,将在下⾯创建各个代理,并告诉他们如何使⽤ LangGraph 相互交流。
定义状态
我们⾸先定义图的状态。这只是⼀个消息列表,以及⼀个⽤于跟踪最新发送者的键
# 导⼊操作符和类型注解
import operator
from typing import Annotated, Sequence, TypedDict
# 导⼊OpenAI聊天模型
from langchain_openai import ChatOpenAI
# 定义⼀个对象,⽤于在图的每个节点之间传递
# 我们将为每个代理和⼯具创建不同的节点
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], operator.add]
sender: str
定义代理的节点。
现在我们需要定义节点。⾸先,让我们定义代理的节点。
# 导⼊functools模块
import functools
# 导⼊AI消息类
from langchain_core.messages import AIMessage
# 辅助函数,⽤于为给定的代理创建节点
def agent_node(state, agent, name):
# 调⽤代理
result = agent.invoke(state)
# 将代理输出转换为适合附加到全局状态的格式
if isinstance(result, ToolMessage):
pass
else:
result = AIMessage(**result.dict(exclude={"type", "name"}), name=n
ame)
return {
"messages": [result],
# 由于我们有⼀个严格的⼯作流程,我们可以
# 跟踪发送者,以便知道下⼀个传递给谁。
"sender": name,
}
# 创建OpenAI聊天模型实例
llm = ChatOpenAI(model="gpt-4o")
# 研究代理和节点
research_agent = create_agent(
llm,
[tavily_tool],
system_message="你应该提供准确的数据供chart_generator使⽤。",
)
# 创建研究节点
research_node = functools.partial(agent_node, agent=research_agent, name
="Researcher")
# 图表⽣成器
chart_agent = create_agent(
llm,
[python_repl],
system_message="你展示的任何图表都将对⽤户可⻅。",
)
# 创建图表⽣成节点
chart_node = functools.partial(agent_node, agent=chart_agent, name="chart_
generator")
定义图
我们现在可以将所有内容整合在⼀起,并定义图!
# 创建状态图实例
workflow = StateGraph(AgentState)
# 添加研究员节点
workflow.add_node("Researcher", research_node)
# 添加图表⽣成器节点
workflow.add_node("chart_generator", chart_node)
# 添加⼯具调⽤节点
workflow.add_node("call_tool", tool_node)
# 添加条件边
workflow.add_conditional_edges(
"Researcher",
router,
{"continue": "chart_generator", "call_tool": "call_tool", "__end__": E
ND},
)
workflow.add_conditional_edges(
"chart_generator",
router,
{"continue": "Researcher", "call_tool": "call_tool", "__end__": END},
)
# 添加条件边
workflow.add_conditional_edges(
"call_tool",
# 每个代理节点更新'sender'字段
# ⼯具调⽤节点不更新,这意味着
# 该边将路由回调⽤⼯具的原始代理
lambda x: x["sender"],
{
"Researcher": "Researcher",
"chart_generator": "chart_generator",
},
)
# 添加起始边
workflow.add_edge(START, "Researcher")
# 编译⼯作流图
graph = workflow.compile()
# 将⽣成的图⽚保存到⽂件
graph_png = graph.get_graph().draw_mermaid_png()
with open("collaboration.png", "wb") as f:
f.write(graph_png)
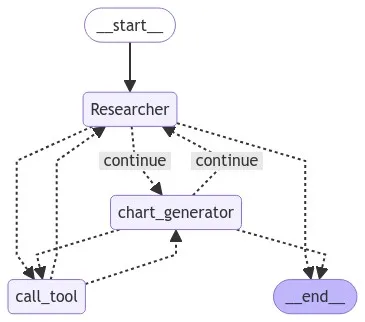
调用
图创建完毕后,您可以调⽤它!让我们让它为我们绘制⼀些统计数据。
# 事件流
events = graph.stream(
{
"messages": [
HumanMessage(
content="获取过去5年AI软件市场规模,"
" 然后绘制⼀条折线图。"
" ⼀旦你编写好代码,完成任务。"
)
],
},
# 图中最多执⾏的步骤数
{"recursion_limit": 150},
)
# 打印事件流中的每个状态
for s in events:
print(s)
print("----")
结果:
Planning Agent
Plan-and-Execute(计划并执⾏)
下⾯展示了如何创建⼀个“计划并执⾏”⻛格的代理。 这在很⼤程度上借鉴了 计划和解决 论⽂以 及 Baby-AGI 项⽬。 核⼼思想是先制定⼀个多步骤计划,然后逐项执⾏。 完成⼀项特定任务后,您可以重新审视计划 并根据需要进⾏修改。⼀般的计算图如下所示
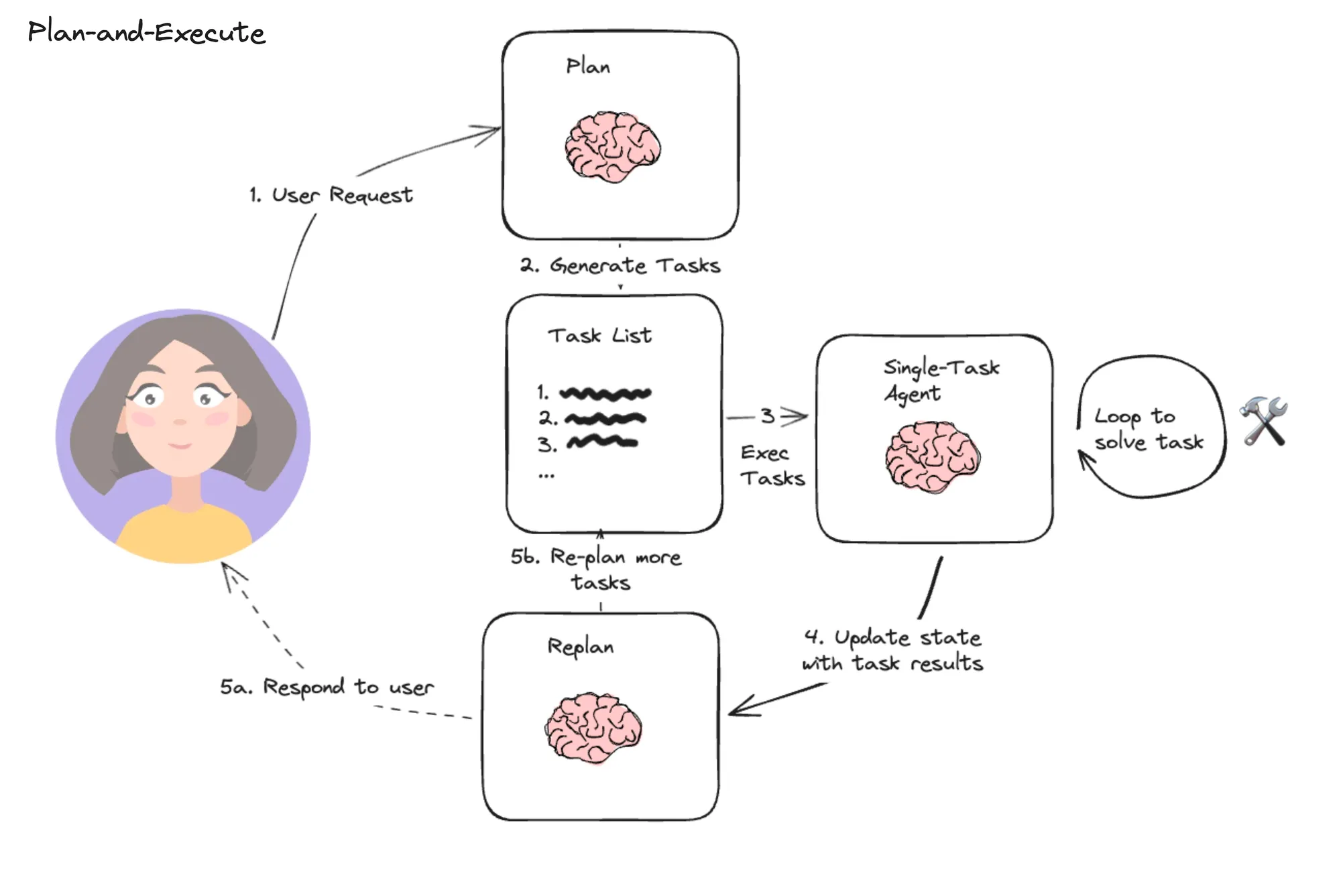
这与典型的 ReAct ⻛格的代理进⾏了⽐较,在该代理中,您⼀次思考⼀步。 这种“计划并执⾏”⻛ 格代理的优势在于 1. 明确的⻓期规划(即使是真正强⼤的 LLM 也可能难以做到) 2. 能够使⽤更⼩/更弱的模型来执⾏步骤,仅在规划步骤中使⽤更⼤/更好的模型 以下演练演示了如何在 LangGraph 中实现这⼀点。 ⽣成的代理将留下类似以下示例的轨迹: (LangSmith).
设置
⾸先,我们需要安装所需的软件包。
%pip install --quiet -U langgraph langchain-community langchain-openai tavi
ly-python
接下来,我们需要为 OpenAI(我们将使⽤的 LLM)和 Tavily(我们将使⽤的搜索⼯具)设置 API 密钥 可以选择设置 LangSmith 跟踪的 API 密钥,这将为我们提供⼀流的可观察性。
setx TAVILY_API_KEY ""
# Optional, add tracing in LangSmith
setx LANGCHAIN_TRACING_V2 "true"
setx LANGCHAIN_API_KEY ""
定义工具
我们将⾸先定义要使⽤的⼯具。 对于这个简单的示例,我们将使⽤ Tavily 内置的搜索⼯具。
完整代码如下:
from langchain_community.tools.tavily_search import TavilySearchResults
# 创建TavilySearchResults工具,设置最大结果数为1
tools = [TavilySearchResults(max_results=1)]
from langchain import hub
from langchain_openai import ChatOpenAI
import asyncio
from langgraph.prebuilt import create_react_agent
# 从LangChain的Hub中获取prompt模板,可以进行修改
prompt = hub.pull("wfh/react-agent-executor")
prompt.pretty_print()
# 选择驱动代理的LLM,使用OpenAI的ChatGPT-4o模型
llm = ChatOpenAI(model="gpt-4o")
# 创建一个REACT代理执行器,使用指定的LLM和工具,并应用从Hub中获取的prompt
agent_executor = create_react_agent(llm, tools, messages_modifier=prompt)
# 调用代理执行器,询问“谁是美国公开赛的冠军”
#agent_executor.invoke({"messages": [("user", "谁是美国公开赛的获胜者")]})
import operator
from typing import Annotated, List, Tuple, TypedDict
# 定义一个TypedDict类PlanExecute,用于存储输入、计划、过去的步骤和响应
class PlanExecute(TypedDict):
input: str
plan: List[str]
past_steps: Annotated[List[Tuple], operator.add]
response: str
from pydantic import BaseModel, Field
# 定义一个Plan模型类,用于描述未来要执行的计划
class Plan(BaseModel):
"""未来要执行的计划"""
steps: List[str] = Field(
description="需要执行的不同步骤,应该按顺序排列"
)
from langchain_core.prompts import ChatPromptTemplate
# 创建一个计划生成的提示模板
planner_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""对于给定的目标,提出一个简单的逐步计划。这个计划应该包含独立的任务,如果正确执行将得出正确的答案。不要添加任何多余的步骤。最后一步的结果应该是最终答案。确保每一步都有所有必要的信息 - 不要跳过步骤。""",
),
("placeholder", "{messages}"),
]
)
# 使用指定的提示模板创建一个计划生成器,使用OpenAI的ChatGPT-4o模型
planner = planner_prompt | ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(Plan)
# 调用计划生成器,询问“当前澳大利亚公开赛冠军的家乡是哪里?”
#planner.invoke({"messages": [("user", "现任澳网冠军的家乡是哪里?")]})
from typing import Union
# 定义一个响应模型类,用于描述用户的响应
class Response(BaseModel):
"""用户响应"""
response: str
# 定义一个行为模型类,用于描述要执行的行为。该类继承自 BaseModel。
# 类中有一个属性 action,类型为 Union[Response, Plan],表示可以是 Response 或 Plan 类型。
# action 属性的描述为:要执行的行为。如果要回应用户,使用 Response;如果需要进一步使用工具获取答案,使用 Plan。
class Act(BaseModel):
"""要执行的行为"""
action: Union[Response, Plan] = Field(
description="要执行的行为。如果要回应用户,使用Response。如果需要进一步使用工具获取答案,使用Plan。"
)
# 创建一个重新计划的提示模板
replanner_prompt = ChatPromptTemplate.from_template(
"""对于给定的目标,提出一个简单的逐步计划。这个计划应该包含独立的任务,如果正确执行将得出正确的答案。不要添加任何多余的步骤。最后一步的结果应该是最终答案。确保每一步都有所有必要的信息 - 不要跳过步骤。
你的目标是:
{input}
你的原计划是:
{plan}
你目前已完成的步骤是:
{past_steps}
相应地更新你的计划。如果不需要更多步骤并且可以返回给用户,那么就这样回应。如果需要,填写计划。只添加仍然需要完成的步骤。不要返回已完成的步骤作为计划的一部分。"""
)
# 使用指定的提示模板创建一个重新计划生成器,使用OpenAI的ChatGPT-4o模型
replanner = replanner_prompt | ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(Act)
from typing import Literal
# 定义一个异步主函数
async def main():
# 定义一个异步函数,用于生成计划步骤
async def plan_step(state: PlanExecute):
plan = await planner.ainvoke({"messages": [("user", state["input"])]})
return {"plan": plan.steps}
# 定义一个异步函数,用于执行步骤
async def execute_step(state: PlanExecute):
plan = state["plan"]
plan_str = "\n".join(f"{i + 1}. {step}" for i, step in enumerate(plan))
task = plan[0]
task_formatted = f"""对于以下计划:
{plan_str}\n\n你的任务是执行第{1}步,{task}。"""
agent_response = await agent_executor.ainvoke(
{"messages": [("user", task_formatted)]}
)
return {
"past_steps": state["past_steps"] + [(task, agent_response["messages"][-1].content)],
}
# 定义一个异步函数,用于重新计划步骤
async def replan_step(state: PlanExecute):
output = await replanner.ainvoke(state)
if isinstance(output.action, Response):
return {"response": output.action.response}
else:
return {"plan": output.action.steps}
# 定义一个函数,用于判断是否结束
def should_end(state: PlanExecute) -> Literal["agent", "__end__"]:
if "response" in state and state["response"]:
return "__end__"
else:
return "agent"
from langgraph.graph import StateGraph, START
# 创建一个状态图,初始化PlanExecute
workflow = StateGraph(PlanExecute)
# 添加计划节点
workflow.add_node("planner", plan_step)
# 添加执行步骤节点
workflow.add_node("agent", execute_step)
# 添加重新计划节点
workflow.add_node("replan", replan_step)
# 设置从开始到计划节点的边
workflow.add_edge(START, "planner")
# 设置从计划到代理节点的边
workflow.add_edge("planner", "agent")
# 设置从代理到重新计划节点的边
workflow.add_edge("agent", "replan")
# 添加条件边,用于判断下一步操作
workflow.add_conditional_edges(
"replan",
# 传入判断函数,确定下一个节点
should_end,
)
# 编译状态图,生成LangChain可运行对象
app = workflow.compile()
# 将生成的图片保存到文件
graph_png = app.get_graph().draw_mermaid_png()
with open("plan_execute.png", "wb") as f:
f.write(graph_png)
# 设置配置,递归限制为50
config = {"recursion_limit": 50}
# 输入数据
inputs = {"input": "2024年巴黎奥运会100米自由泳决赛冠军的家乡是哪里?请用中文答复"}
# 异步执行状态图,输出结果
async for event in app.astream(inputs, config=config):
for k, v in event.items():
if k != "__end__":
print(v)
# 运行异步函数
asyncio.run(main())
工具代码:
#示例:plan_execute.py
from langchain_community.tools.tavily_search import TavilySearchResults
# 创建TavilySearchResults⼯具,设置最⼤结果数为1
tools = [TavilySearchResults(max_results=1)]
定义我们的执行代理
现在我们将创建要⽤于执⾏任务的执⾏代理。 请注意,对于此示例,我们将对每个任务使⽤相同
的执⾏代理,但这并⾮必须如此。
from langchain import hub
from langchain_openai import ChatOpenAI
import asyncio
from langgraph.prebuilt import create_react_agent
# 从LangChain的Hub中获取prompt模板,可以进⾏修改
prompt = hub.pull("wfh/react-agent-executor")
prompt.pretty_print()
# 选择驱动代理的LLM,使⽤OpenAI的ChatGPT-4o模型
llm = ChatOpenAI(model="gpt-4o")
# 创建⼀个REACT代理执⾏器,使⽤指定的LLM和⼯具,并应⽤从Hub中获取的prompt
agent_executor = create_react_agent(llm, tools, messages_modifier=prompt)# 调⽤代理执⾏器,询问“谁是美国公开赛的冠军”
agent_executor.invoke({"messages": [("user", "谁是美国公开赛的获胜者")]})
定义状态
现在让我们从定义要跟踪此代理的状态开始。 ⾸先,我们需要跟踪当前计划。 让我们将其表示为字符串列表。 接下来,我们应该跟踪先前执⾏的步骤。 让我们将其表示为元组列表(这些元组将包含步骤及其 结果) 最后,我们需要⼀些状态来表示最终响应以及原始输⼊。
import operator
from typing import Annotated, List, Tuple, TypedDict
# 定义⼀个TypedDict类PlanExecute,⽤于存储输⼊、计划、过去的步骤和响应
class PlanExecute(TypedDict):
input: str
plan: List[str]
past_steps: Annotated[List[Tuple], operator.add]
response: str
规划步骤
现在让我们考虑创建规划步骤。 这将使⽤函数调⽤来创建计划。
from langchain_core.pydantic_v1 import BaseModel, Field
# 定义⼀个Plan模型类,⽤于描述未来要执⾏的计划
class Plan(BaseModel):
"""未来要执⾏的计划"""
steps: List[str] = Field(
description="需要执⾏的不同步骤,应该按顺序排列"
)
from langchain_core.prompts import ChatPromptTemplate
# 创建⼀个计划⽣成的提示模板
planner_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""对于给定的⽬标,提出⼀个简单的逐步计划。这个计划应该包含独⽴的任务,如
果正确执⾏将得出正确的答案。不要添加任何多余的步骤。最后⼀步的结果应该是最终答案。确保每
⼀步都有所有必要的信息 - 不要跳过步骤。""",
),
("placeholder", "{messages}"),
]
)
# 使⽤指定的提示模板创建⼀个计划⽣成器,使⽤OpenAI的ChatGPT-4o模型
planner = planner_prompt | ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(Plan)
# 调⽤计划⽣成器,询问“当前澳⼤利亚公开赛冠军的家乡是哪⾥?”
planner.invoke(
{
"messages": [
("user", "现任澳⽹冠军的家乡是哪⾥?")
]
}
)
{'plan': ['查找2024年澳⼤利亚⽹球公开赛的冠军是谁', '查找该冠军的家乡是哪⾥', '⽤中⽂
回答该冠军的家乡']}
重新制定计划的步骤。
现在,让我们创建⼀个根据上⼀步结果重新制定计划的步骤。
from typing import Union
# 定义⼀个响应模型类,⽤于描述⽤户的响应
class Response(BaseModel):
"""⽤户响应"""
response: str
# 定义⼀个⾏为模型类,⽤于描述要执⾏的⾏为
class Act(BaseModel):
"""要执⾏的⾏为"""
action: Union[Response, Plan] = Field(
description="要执⾏的⾏为。如果要回应⽤户,使⽤Response。如果需要进⼀步使⽤
⼯具获取答案,使⽤Plan。"
)
# 创建⼀个重新计划的提示模板
replanner_prompt = ChatPromptTemplate.from_template(
"""对于给定的⽬标,提出⼀个简单的逐步计划。这个计划应该包含独⽴的任务,如果正确执⾏
将得出正确的答案。不要添加任何多余的步骤。最后⼀步的结果应该是最终答案。确保每⼀步都有所
有必要的信息 - 不要跳过步骤。
你的⽬标是:
{input}
你的原计划是:
{plan}
你⽬前已完成的步骤是:
{past_steps}
相应地更新你的计划。如果不需要更多步骤并且可以返回给⽤户,那么就这样回应。如果需要,填写
计划。只添加仍然需要完成的步骤。不要返回已完成的步骤作为计划的⼀部分。"""
)
# 使⽤指定的提示模板创建⼀个重新计划⽣成器,使⽤OpenAI的ChatGPT-4o模型
replanner = replanner_prompt | ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(Act)
创建图
现在我们可以创建图了!
from typing import Literal
# 定义⼀个异步主函数
async def main():
# 定义⼀个异步函数,⽤于执⾏步骤
async def execute_step(state: PlanExecute):
plan = state["plan"]
plan_str = "\n".join(f"{i + 1}. {step}" for i, step in enumerate(p
lan))
task = plan[0]
task_formatted = f"""对于以下计划:
{plan_str}\n\n你的任务是执⾏第{1}步,{task}。"""
agent_response = await agent_executor.ainvoke(
{"messages": [("user", task_formatted)]}
)
return {
"past_steps": state["past_steps"] + [(task, agent_response["me
ssages"][-1].content)],
}
# 定义⼀个异步函数,⽤于⽣成计划步骤
async def plan_step(state: PlanExecute):
plan = await planner.ainvoke({"messages": [("user", state["inpu
t"])]})
return {"plan": plan.steps}
# 定义⼀个异步函数,⽤于重新计划步骤
async def replan_step(state: PlanExecute):
output = await replanner.ainvoke(state)
if isinstance(output.action, Response):
return {"response": output.action.response}
else:
return {"plan": output.action.steps}
# 定义⼀个函数,⽤于判断是否结束
def should_end(state: PlanExecute) -> Literal["agent", "__end__"]:
if "response" in state and state["response"]:
return "__end__"
else:
return "agent"
from langgraph.graph import StateGraph, START
# 创建⼀个状态图,初始化PlanExecute
workflow = StateGraph(PlanExecute)
# 添加计划节点
workflow.add_node("planner", plan_step)
# 添加执⾏步骤节点
workflow.add_node("agent", execute_step)
# 添加重新计划节点
workflow.add_node("replan", replan_step)
# 设置从开始到计划节点的边
workflow.add_edge(START, "planner")
# 设置从计划到代理节点的边
workflow.add_edge("planner", "agent")
# 设置从代理到重新计划节点的边
workflow.add_edge("agent", "replan")
# 添加条件边,⽤于判断下⼀步操作
workflow.add_conditional_edges(
"replan",
# 传⼊判断函数,确定下⼀个节点
should_end,
)
# 编译状态图,⽣成LangChain可运⾏对象
app = workflow.compile()
# 将⽣成的图⽚保存到⽂件
graph_png = app.get_graph().draw_mermaid_png()
with open("plan_execute.png", "wb") as f:
f.write(graph_png)
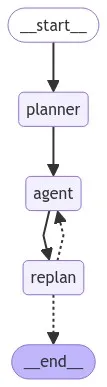
# 设置配置,递归限制为50
config = {"recursion_limit": 50}
# 输⼊数据
inputs = {"input": "2024年巴黎奥运会100⽶⾃由泳决赛冠军的家乡是哪⾥?请⽤中⽂答复"}
# 异步执⾏状态图,输出结果
async for event in app.astream(inputs, config=config):
for k, v in event.items():
if k != "__end__":
print(v)
{'plan': ['查找2024年巴黎奥运会100⽶⾃由泳决赛冠军的名字', '查找该冠军的家乡']}
{'past_steps': [('查找2024年巴黎奥运会100⽶⾃由泳决赛冠军的名字', '2024年巴黎奥运会
男⼦100⽶⾃由泳决赛的冠军是中国选⼿潘展乐(Zhanle Pan)。')]}
{'plan': ['查找潘展乐的家乡']}
{'past_steps': [('查找2024年巴黎奥运会100⽶⾃由泳决赛冠军的名字', '2024年巴黎奥运会
男⼦100⽶⾃由泳决赛的冠军是中国选⼿潘展乐(Zhanle Pan)。'), ('查找潘展乐的家乡', '潘
展乐的家乡是浙江温州。')]}
{'response': '2024年巴黎奥运会100⽶⾃由泳决赛冠军潘展乐的家乡是浙江温州。'}
结束!

















 758
758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









