






传统的网页爬取方法在许多情况下都非常有效,只需获取页面的URL,并且在需要翻页时,通常可以从URL中找到规律,通过迭代调用每个页面来获取所需的信息。然而,随着网页技术的发展,许多网站采用了异步加载的方式来动态加载内容,特别是在进行翻页时。这就导致了翻页请求的URL中出现了一些无规则的参数,这些参数可能与时间戳、申请指令或其他因素有关,使用者很难推测出其具体规律。
面对这种情况,我们需要另一种更加智能和灵活的方法来解决这个问题。本文以携程网站中“橘子洲头”评论的爬取为例,详细介绍了如何应对动态URL的挑战,同时还展示了如何解析爬取到的JSON格式的信息,并将最终获取的数据保存到一个XLS文件中,以便后续分析和使用。
一、静态页面的爬虫(包含请求、寻找路径的具体操作)
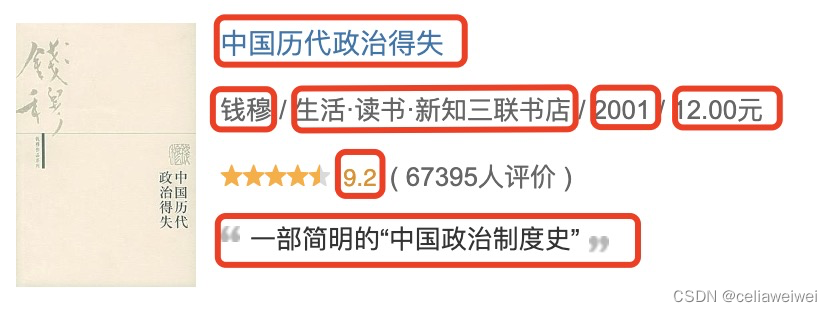
传统爬虫方法通常基于HTTP请求和HTML解析,使用起来相对简单,可以通过编写少量的代码来实现基本的爬取功能。对于大多数静态网页,传统爬虫方法足够了,可以直接获取到所需的内容,如文本、图片,这通常能够快速获取静态网页内容,因为不涉及复杂的页面渲染和动态加载。以爬取豆瓣网图书top的数据为例。
1. 基本准备工作(调库、定义申请头url和deaders)
首先导入爬虫所需的库。
requests库是一个常用的HTTP请求库,用于向网站发送请求并获取响应。可以使用该库设置请求头(Headers),并获取页面内容。
lxml是Python中另一个常用的XML和HTML解析库。它提供了高效且灵活的解析器,用于处理XML和HTML文档。lxml的解析速度非常快,并且支持XPath和CSS选择器,使得数据提取和定位元素变得更加简单和方便。
简而言之,requests库用于得到网页的页面内容,lxml库用于提取我们需要的数据。
from lxml import etree
import requests
import csv
新建一个名称为‘douban250.csv’的文件用于保存我们从网页爬取的数据,由于我们接下来会爬取书籍的名称、图片链接等等,因此将这些标签名保存到文件第一行。
fp = open("douban250.csv",'wt',newline='',
encoding = 'utf-8')
writer = csv.writer(fp)
writer.writerow(('name','url','author','publisher','date','price','rate','comment'))
定义headers请求头和url,用于申请网页内容。
首先右击需要查询的元素, 点击‘检查’,或按下F12(Mac按左下角fn再在触摸键盘上按下F12),即可跳出右边页面,寻找headers和url。
URL是用于标识互联网上资源的地址,headers请求头用于向服务器传递附加的信息或控制请求和响应的行为,以下是寻找过程。
①寻找user-agent申请头的操作如下:
headers = {
'User-Agent': '你的user-agent'
}②寻找url:

第一页的url为‘https://www.qidian.com/all/page0’
第二页的url为‘https://www.qidian.com/all/page25’
第三页的url为‘https://www.qidian.com/all/page50’
由此发现,每翻一页,url后的参数就要加25.
urls = ['https://www.qidian.com/all/page{}/'.format(str(i)) for i in range(1,10)]
2. 根据xpath定位源代码中元素的具体位置
右击网页元素,点击检查,可以直接定位到网页源代码中该元素的位置。
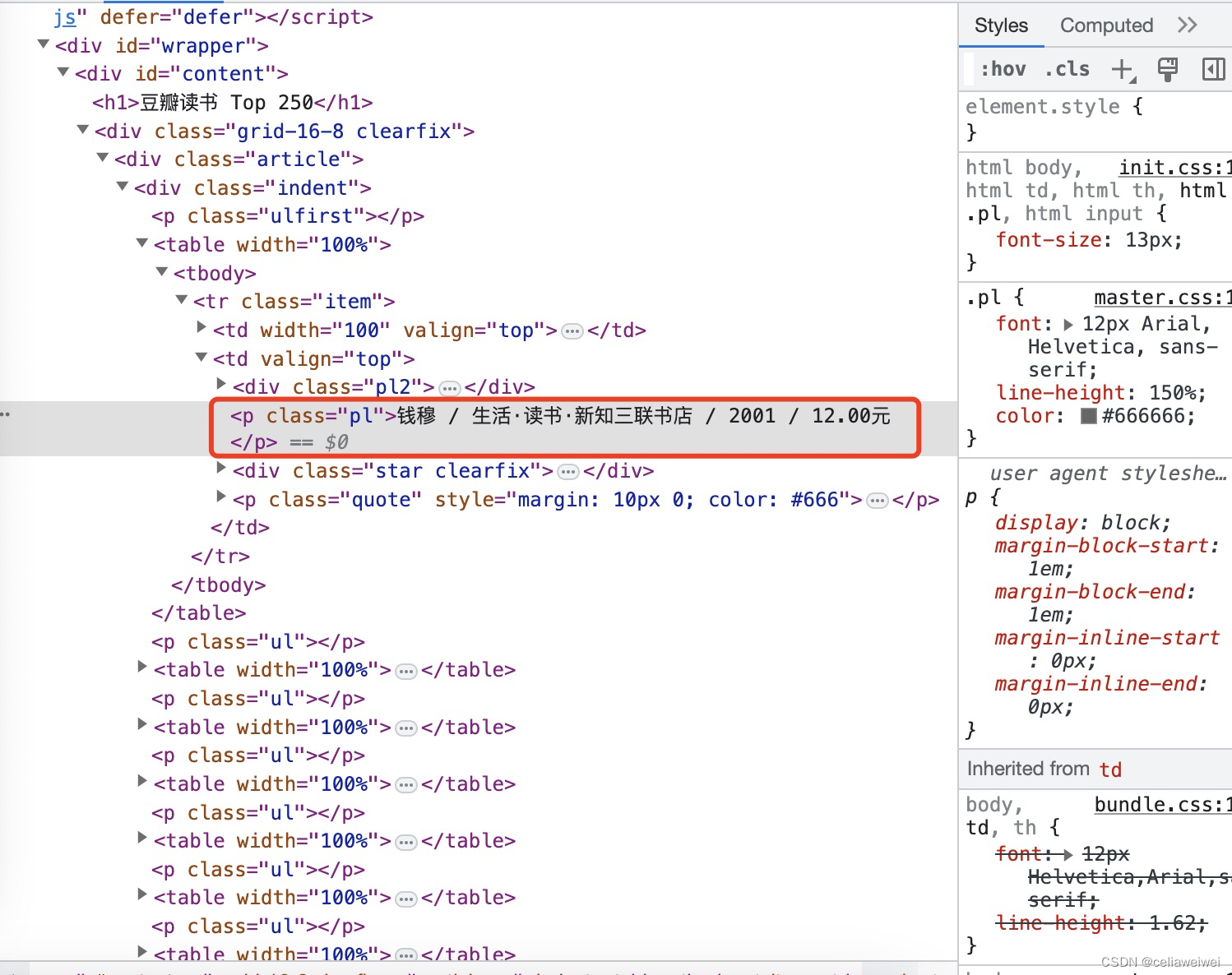
右击这条代码,复制xpath,可得到
//*[@id="content"]/div/div[1]/div/table[1]/tbody/tr/td[2]/p[1] ,
这就是这条信息的在网页源代码中的路径。
for url in urls:
html = requests.get(url,headers=headers)
selector = etree.HTML(html.text)
infos = selector.xpath('//div[@class="book-mid-info"]')
for info in infos:
name = info.xpath('td/div/a/@title')[0]
book_infos = info.xpath('td/p/text()')[0]
author = book_infos.split('/')[0]
publisher = book_infos.split('/')[-3]
date = book_infos.split('/')[-2]
price = book_infos.split('/')[-1]
rate = info.xpath('td/div/span[2]/text()')[0]
comments = info.xpath('td/p/span/text')
comment = comments[0] if len(comments) != 0 else "空"
writer.writerow((name,url,author,publisher,date,price,rate,comment))
fp.close()在这段代码的前一个部分,我们首先使用了请求头(Headers)来模拟浏览器发送请求,以获取目标网页的源代码。通过设置合适的User-Agent等请求头信息,我们可以使得请求看起来更像是由真实浏览器发送的,从而避免被网站的反爬虫机制拦截。这样,我们可以成功获取到网页的原始HTML内容。
接下来,我们利用lxml库来解析这个HTML文档,根据预先定义的XPath路径,定位到具体的元素信息。XPath是一种用于在XML和HTML文档中定位节点的语言。在本例中,我们使用了XPath路径来指定目标元素的位置,从而从整个HTML文档中提取所需的数据。
二、动态页面-异步加载的爬取
许多现代网页使用异步加载技术,通过JavaScript动态加载内容,传统爬虫方法往往无法直接捕获这些内容,导致无法完整获取页面数据。
1. 异步加载的表现
异步加载(Asynchronous Loading)是一种在网页上加载内容的方式,通俗来说就是不需要等待当前内容加载完毕才能继续加载其他内容。这种加载方式使得网页在用户浏览时更加快速和流畅。
当一个页面中的某块内容采用逆向加载时,意味着页面在初始加载时,并没有将该块内容一起加载,而是在用户滚动页面或执行某些操作时,动态地向服务器请求新的内容,然后将其展示在页面上。
想象一下,你正在访问一个包含很多图片和文字的网页。在传统的同步加载方式下,浏览器会按照页面上内容出现的顺序逐一加载,也就是说,如果一个图片加载很慢,整个页面其他部分也会被阻塞,直到图片加载完成才能显示。这会导致页面加载速度很慢。
而异步加载则是改进的解决方案。网页利用异步加载技术,当需要加载某些内容时,会单独发起一个请求,然后继续加载其他内容,而不需要等待该请求完成。这样,其他部分的内容可以先加载显示,而不会因为某个资源的加载时间过长而被阻塞。
以携程网页为例:‘https://you.ctrip.com/sight/changsha148/9010.html#ctm_ref=www_hp_his_lst’
在翻页过程中,网页url不变,不同页面的元素xpath也不变。
2. 异步加载的实现途径
在实际中,异步加载经常通过 JavaScript 来实现。网页中的 JavaScript 代码会负责在需要的时候发起异步请求,获取资源或数据,并在加载完成后将其展示在网页上。
总的来说,异步加载就是一种优化网页加载的技术,通过在必要时才加载特定内容,让用户能够更快地访问网页并且更流畅地浏览网页上的内容。
因此,需要从JavaScript代码入手,才能完整地了解网页的加载过程和不同阶段产生的数据。
JavaScript代码在浏览器中执行,可以动态地修改DOM(文档对象模型)结构,实现页面的动态效果和数据加载。这些动态生成的内容可能包括评论、推荐信息、用户交互数据等。因此,若仅从原始HTML源代码入手,很可能无法获取完整的页面数据。
为了全面抓取现代Web应用中的数据,我们需要通过模拟浏览器行为来执行JavaScript代码,使得页面完整渲染,并在其之后提取所需数据。
3.异步加载的页面解析
进行翻页操作后,会生成一系列文件,从这群新生成的文件中找到申请翻页的文件,它的request url为
‘https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList?_fxpcqlniredt=09031098111600950761&x-traceID=09031098111600950761-1690373857939-9219508’
这个URL可能包含了一些参数,用于标识请求的具体信息。让我们来解析这个URL的一些重要部分:
‘https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList**:这部分是服务器端的地址,指明了我们要访问的具体资源或服务。’
_fxpcqlniredt和x-traceID:这两个参数是请求中的某些标识或验证信息。在这里不用深究,继续往下做。
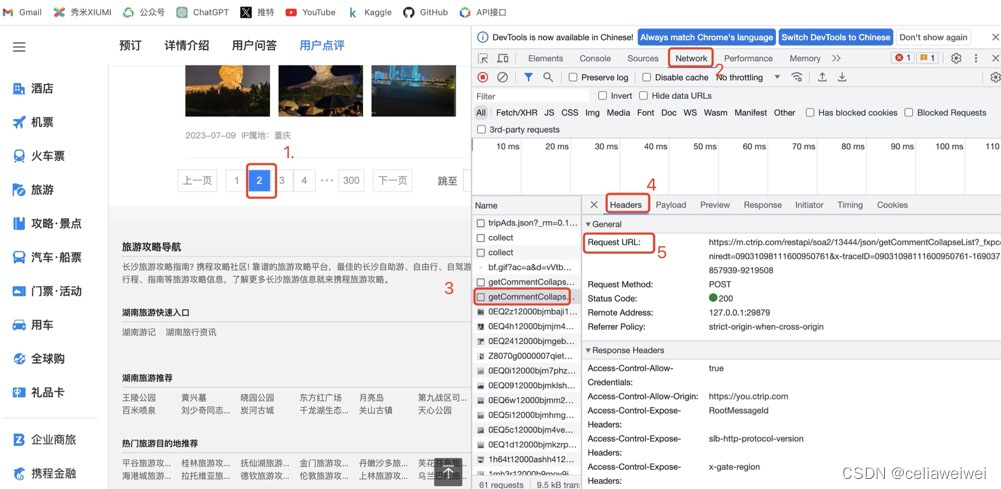
既然无法通过URL直接获取翻页请求,我们可以考虑通过观察payload中页面的申请信息来获取动态的URL。在现代Web应用中,很多网页在进行翻页或异步加载时,会使用JavaScript动态生成请求的参数,而这些参数可能是动态生成的时间戳、请求标识等。如果我们能够从页面的payload中提取这些信息,就可以构造出完整的翻页请求URL。
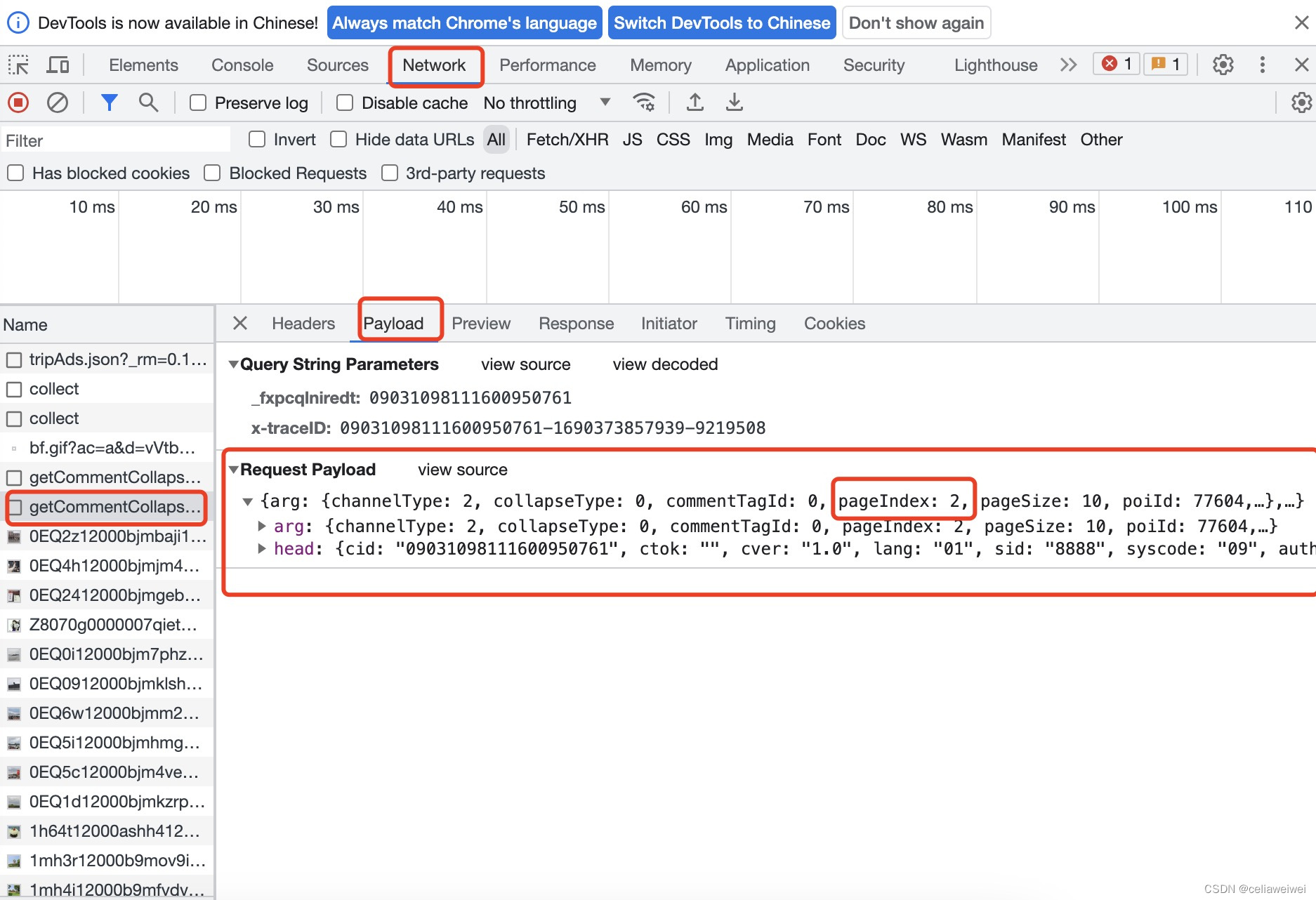
headers = {
'User-Agent': '你的user-agent',
#'Cookie': 'your_cookie_value_here',
#可以根据需要设置其他请求头
}
#base_url此处定义一个基础的url,是服务器端的地址,指明了我们要访问的具体资源或服务,和上面申请文件的url前部一样
base_url = 'https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList'
payload = {
"arg": {
"channelType": 2,
"collapseType": 0,
"commentTagId": 0,
"pageIndex": 2,
"pageSize": 10,
"poiId": 77604,
"sourceType": 1,
"sortType": 3,
"starType": 0
},
"head": {
"cid": "09031098111600950761",
"ctok": "",
"cver": "1.0",
"lang": "01",
"sid": "8888",
"syscode": "09",
"auth": "",
"xsid": "",
"extension": []
}
}
base_url是一个基础的url,不包含参数,是服务器端的地址,指明了我们要访问的具体资源或服务,和上面申请文件的url前部一样。
4. 异步加载页面的爬取方法
response = requests.post(base_url, data=json.dumps(payload), headers=headers)
soup = BeautifulSoup(response.text,'html.parser')
soup.text我们可以使用 Python 的内置 JSON 模块来解析这个 JSON 数据,并获取其中的 "comment" 字段内容。代码得到的是js文档,即下图的呈现,只需要在信息中找到我们需要的部分,就可以通过字典方法进行调用。
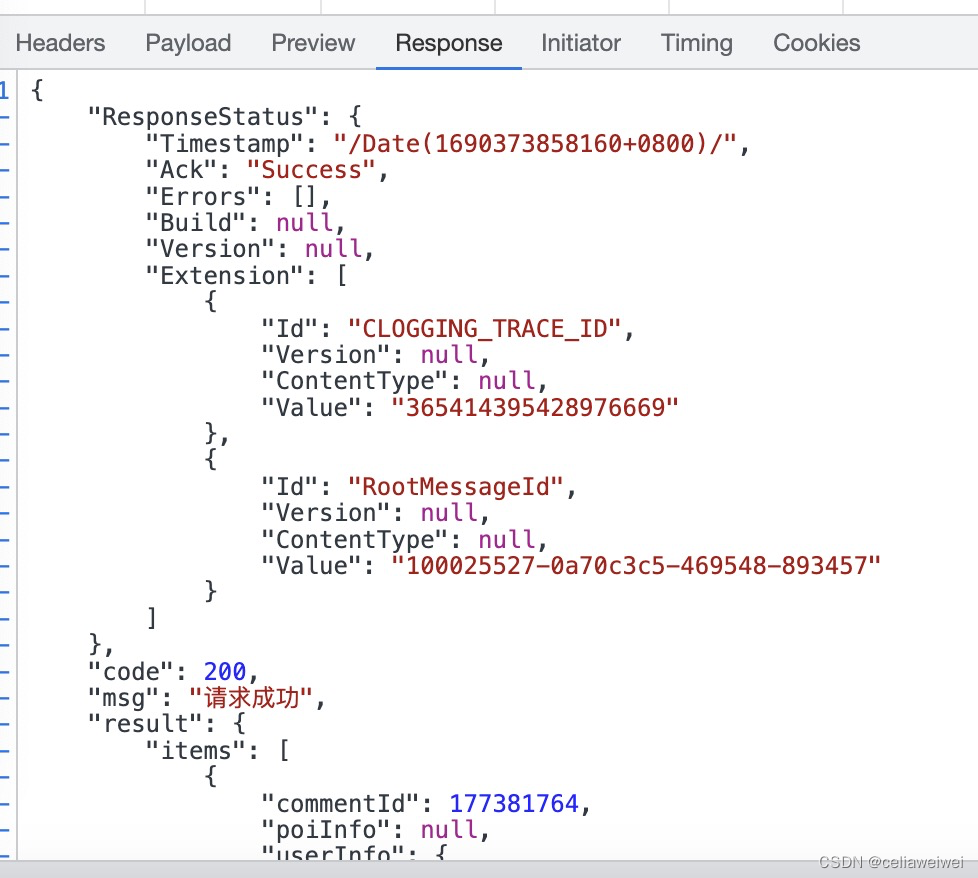
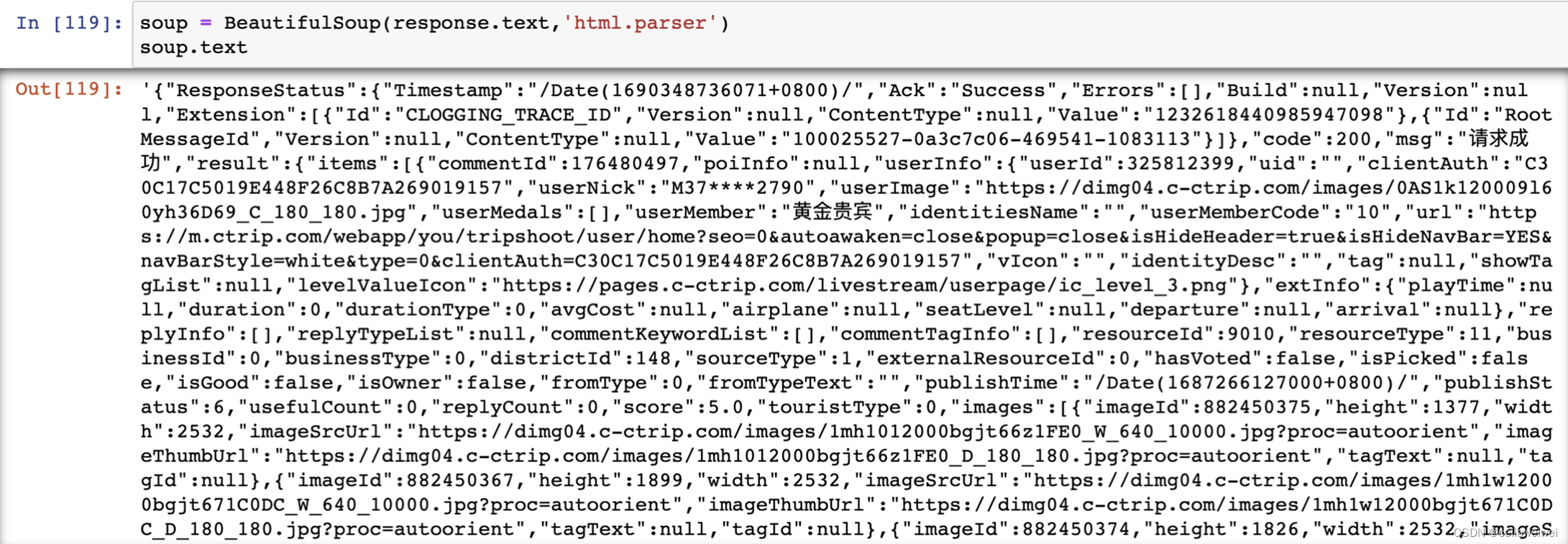
如图所示,爬取的内容呈现混乱且难以直接提取所需数据,因此我们可以借助JSON库进行解析。JSON库是Python中用于处理JSON(JavaScript Object Notation)数据的标准库之一,它能够帮助我们有效地解析信息,从中获取我们需要爬取的数据。
通过使用JSON库,我们可以轻松地将JSON数据转换为Python的字典或列表,从而更方便地提取和处理其中的内容。
import xlwt
import json
comment = xlwt.Workbook(encoding='utf-8')
sheet = comment.add_sheet('sheet1')
# 解析 JSON 数据
data = json.loads(soup.text)接下来定位到我们需要爬取的信息,在“content”标签中:
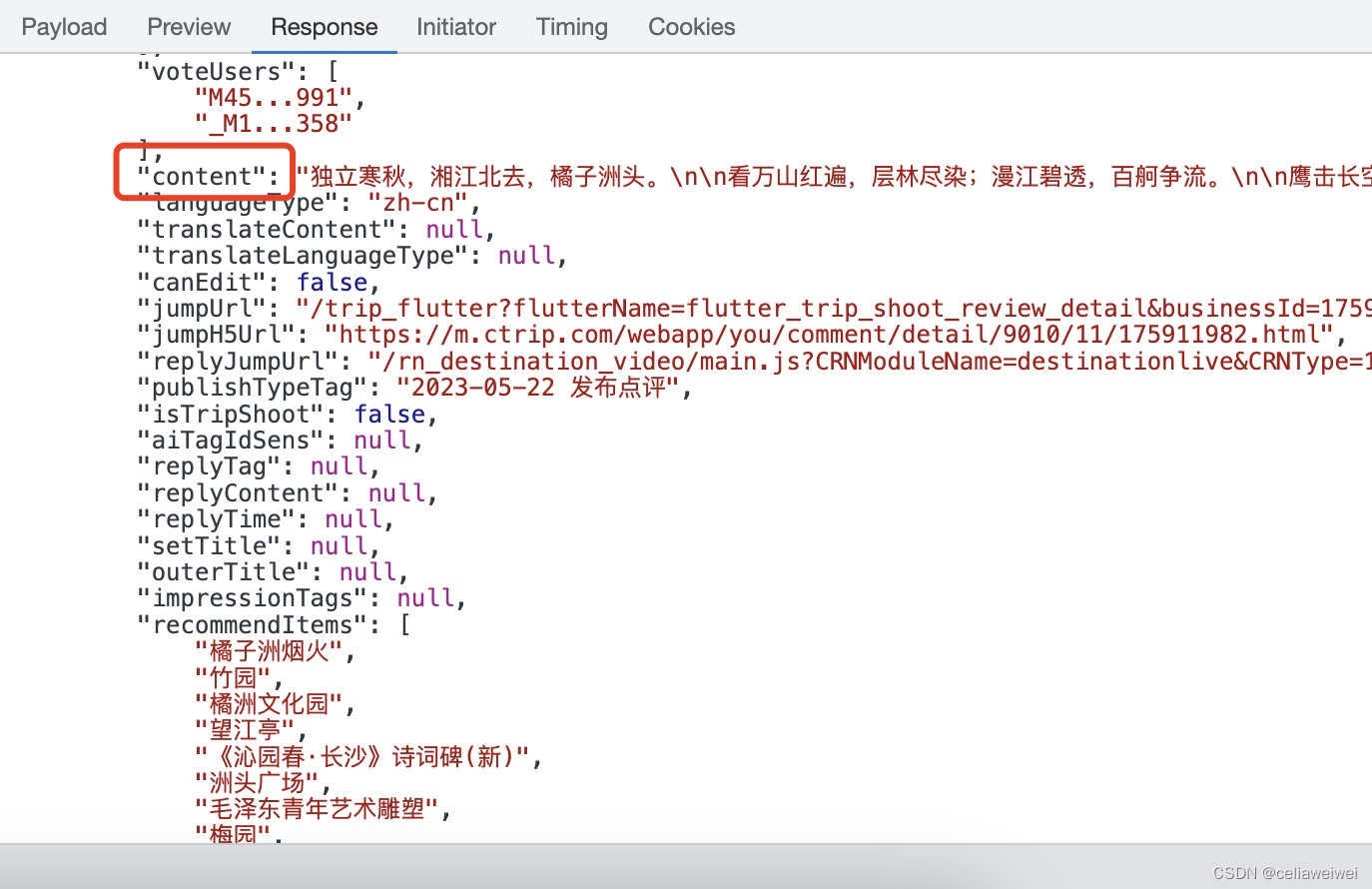
content在result的items中:
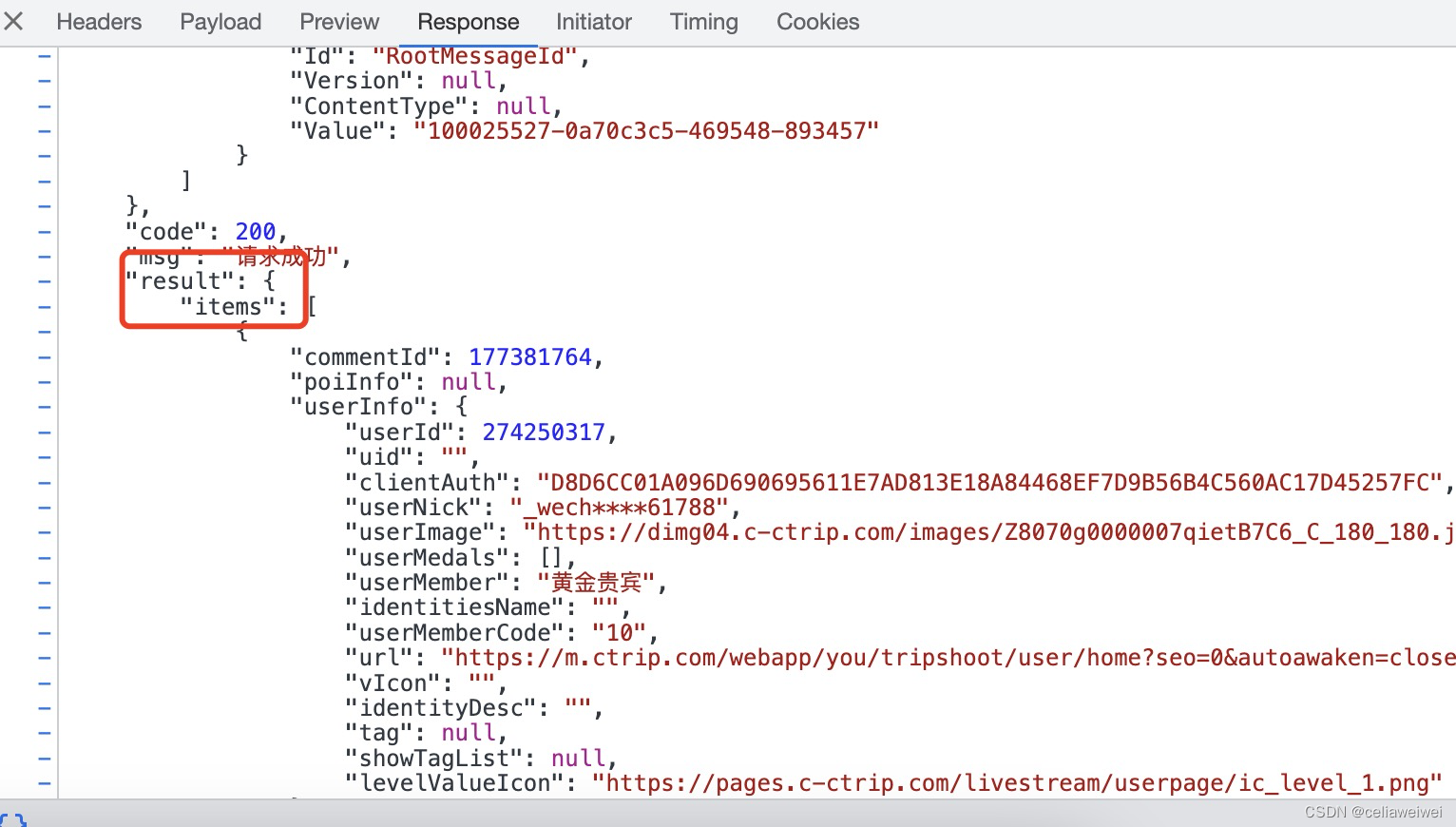
result上面没有其他标签,我们通过data.get("result", [ ])获取result,得到的是列表,保存在comments中。
再通过comments['items']获取item,获取了每个评论对象中 "content" 字段的值。
# 获取 "comment" 字段的内容
comments = data.get("result", [])
items = comments['items']
a_list=[]
i=0
for item in items:
k = item['content']
j=0
sheet.write(i,j,k)
i = i+1
comment.save('评论.xls')集合以上代码,若需要爬取不同页面的数据,只需要修改payload中的page_index即可:
#加上得分情况
book = xlwt.Workbook(encoding='utf-8')
sheet = book.add_sheet('sheet1')
header = ['评论','用户']
for h in range(len(header)):
sheet.write(0,h,header[h])
for index in range(1,30):
base_url = 'https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList'
payload = {
"arg": {
"channelType": 2,
"collapseType": 0,
"commentTagId": 0,
"pageIndex": index,
"pageSize": 10,
"poiId": 77604,
"sourceType": 1,
"sortType": 3,
"starType": 0
},
"head": {
"cid": "09031098111600950761",
"ctok": "",
"cver": "1.0",
"lang": "01",
"sid": "8888",
"syscode": "09",
"auth": "",
"xsid": "",
"extension": []
}
}
response = requests.post(base_url, data=json.dumps(payload), headers=headers)
soup = BeautifulSoup(response.text,'html.parser')
# 解析 JSON 数据
data = json.loads(soup.text)
# 获取 "content" 字段的内容
comments = data.get("result", [])
items = comments['items']
i=(index-1)*10+1
for item in items:
comments = item['content']
name = item['userInfo']['userNick']
j=0
sheet.write(i,j,comments)
sheet.write(i,j+1,name)
i = i+1
book.save('评论.xls')

















 1508
1508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









