






[(PaddleOCR)](https://github.com/PaddlePaddle/PaddleOCR)
复现上述代码踩了很多坑,现在来记录一波。
复现过程主要参考
PaddleOCR训练属于自己的模型详细教程(从打标,制作数据集,训练到应用,以行驶证识别为例)-CSDN博客(https://blog.csdn.net/qq_52852432/article/details/131817619)
和[模块概述 - PaddleOCR 文档](https://paddlepaddle.github.io/PaddleOCR/main/version3.x/module_usage/module_overview.html)
前者已经记录了部分坑。
1. 打标签
此版本的PaddleOCR不像PaddleOCR-release-2.6内含PPOCRLabel,故要去下述链接下载。
[GitHub - PFCCLab/PPOCRLabel](https://github.com/PFCCLab/PPOCRLabel)
但是其配置过程会报错,我也没有解决。
建议直接使用[Releases · PFCCLab/PPOCRLabel](https://github.com/PFCCLab/PPOCRLabel/releases)种的exe文件,可以轻松很多
2. 训练自己的文字检测和识别模型
用PPOCRLabel打出的标签如下:

训练文字检测模型利用上面的标签格式是可以的,但是训练文字识别模型需要如下格式:
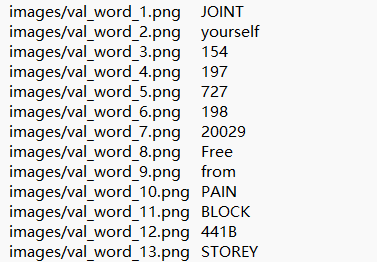
并且图片是要经过裁剪的,如下
![]()
故写了一个代码,可以根据PPOCRLabel打出的标签裁剪原始图片并保存到新的文件夹,且导出符合训练要求的txt文件
其中,label_path是你PPOCRLabel打出的标签文件,output_path是处理后的标签文件保存的地方,out_path是裁剪的图片保存的地方,path实际上就是output_path的前面一部分。(感觉这个path我处理的不好,后续有时间我再优化一下代码)
import json
from PIL import Image
import os
label_path = r'F:\OCR\PaddleOCR-main\train_data\image\det_test_label.txt' # 文字检测时的标签文件
output_path = r'F:\OCR\PaddleOCR-main\train_data\rec_image\extracted_transcriptions_test.txt' # 处理后的标签文件
out_path = './train_data/rec_image' # 裁剪的图片保存out_path
path = r'F:\OCR\PaddleOCR-main\train_data'
os.makedirs(out_path, exist_ok=True)
with open(label_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
with open(output_path, 'w', encoding='utf-8') as out_file:
for line in lines:
line = line.strip()
if '\t' not in line:
print(f"Skipping line without tab character: {line}")
continue
image_path, data = line.split('\t', 1)
try:
json_data = json.loads(data)
except json.JSONDecodeError as e:
print(f"Failed to parse JSON in line: {line}. Error: {e}")
continue
for item in json_data:
transcription_value = item.get("transcription")
points = item.get('points')
if transcription_value and points:
# 截取图片区域
try:
image_path = os.path.join(path, image_path)
image_path=image_path.replace('\\','/')
# print(image_path)
img = Image.open(image_path)
# 转换为PIL支持的坐标格式
points = [(int(x), int(y)) for x, y in points]
min_x = min(point[0] for point in points)
min_y = min(point[1] for point in points)
max_x = max(point[0] for point in points)
max_y = max(point[1] for point in points)
# 创建裁剪区域
cropped_img = img.crop((min_x, min_y, max_x, max_y))
# 文件名处理,避免重复
name = os.path.basename(image_path)
base_name, ext = os.path.splitext(name)
# print(name)
save_path = os.path.join(out_path, name)
counter = 1
while os.path.exists(save_path):
save_path = os.path.join(out_path, f"{base_name}_{counter}{ext}")
name = f"{base_name}_{counter}{ext}"
print(name)
counter += 1
# 保存裁剪后的图片
cropped_img.save(save_path)
# print(f"Saved cropped image to {save_path}")
# 写入
out_file.write(f"rec_image/{name}\t{transcription_value}\n")
except Exception as e:
print(f"Failed to crop image {image_path}. Error: {e}")
3. 模型测试
python tools/infer_det.py -c configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml -o Global.pretrained_model=output/ch_db_driving/best_accuracy.pdparams Global.infer_img="C:\Users\User\Desktop\PaddleOCR-release-2.6\train_data\det\test\0201_1 (3).jpg"只能测试一张图片,为了测试文件夹下的多张图片,写了超级简单的代码
文字检测测试指定文件夹中的所有图片文件 :
import os
import subprocess
def test_images(image_folder, config_path, pretrained_model_path):
"""
测试指定文件夹中的所有图片文件
Args:
image_folder (str): 图片文件夹路径
config_path (str): 配置文件路径
pretrained_model_path (str): 模型路径
"""
# 获取图片文件夹中的所有图片文件
image_files = [os.path.join(image_folder, file) for file in os.listdir(image_folder) if file.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.gif'))]
# 遍历图片文件
for image_file in image_files:
print(f"正在测试图片:{image_file}")
# 构造命令行参数
command = f"python tools/infer_det.py -c {config_path} -o Global.pretrained_model={pretrained_model_path} Global.infer_img={image_file}"
# 执行命令行
subprocess.run(command, shell=True)
if __name__ == "__main__":
# 配置参数
config_path = r"F:\OCR\PaddleOCR-main\configs\det\PP-OCRv5\PP-OCRv5_server_det.yml"
pretrained_model_path = r"F:\OCR\PaddleOCR-main\output\PP-OCRv5_server_det\best_model\model.pdparams"
image_folder = r"F:\OCR\test_images"
# 调用函数
test_images(image_folder, config_path, pretrained_model_path)文字识别测试指定文件夹中的所有图片文件
和上面是一样的,只是要把
command = f"python tools/infer_det.py -c {config_path} -o Global.pretrained_model={pretrained_model_path} Global.infer_img={image_file}" 改为
command = f"python tools/infer_rec.py -c {config_path} -o Global.pretrained_model={pretrained_model_path} Global.infer_img={image_file}"配置参数也改成对应的文字识别模型和config
4. 模型导出
训练出的模型要转换成推理模型,才能实现检测出文字并识别出该文字是什么
运行:
python3 tools/export_model.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml -o \
Global.pretrained_model=output/PP-OCRv5_server_det/best_accuracy.pdparams \
Global.save_inference_dir="./PP-OCRv5_server_det_infer/"出现了
ValueError: PP-OCRv5_server_det is not supported. Please check if the model is supported by the PaddleOCR wheel.
这块有点淡忘了是什么原因造成的,好像是版本问题。解决办法参考[导出inference模型只有两个文件,无法使用 · PaddlePaddle/PaddleOCR · Discussion #14279 · GitHub](https://github.com/PaddlePaddle/PaddleOCR/discussions/14279)
实际上代码这里给出了答案:
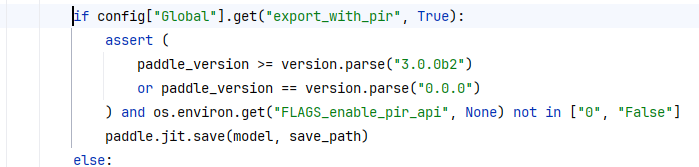
利用下述代码更新版本
python -m pip install paddlepaddle-gpu==3.0.0b2 -i https://www.paddlepaddle.org.cn/packages/stable/cu123/5. 测试图片
我在加载模型部分(加载模型代码如下)
model = PaddleOCR(
text_detection_model_dir=r'F:\OCR\PaddleOCR-main\inference_model\det',
text_recognition_model_dir=r"F:\OCR\PaddleOCR-main\inference_model\rec",
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False,
) 就出现了报错
AssertionError: Model name mismatch,please input the correct model dir.
打印出:
Creating model: ('PP-OCRv5_mobile_det', 'F:\OCR\PaddleOCR-main\inference_model\det')
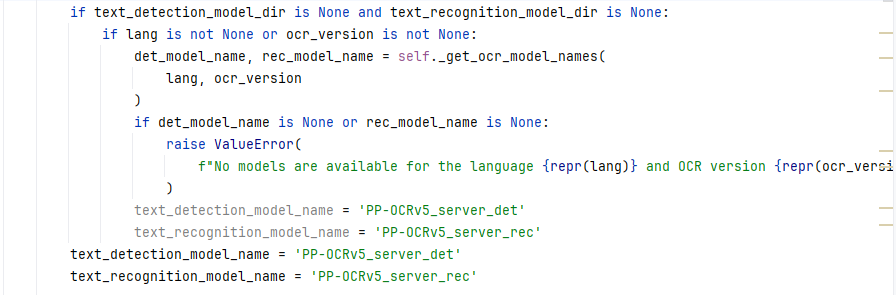
总而言之,我的解决办法就是:
将 https://github.com/PaddlePaddle/PaddleOCR/tree/main/paddleocr/_pipelines/ocr.py代码的if text_detection_model_dir is None and text_recognition_model_dir is None:
if lang is not None or ocr_version is not None:
det_model_name, rec_model_name = self._get_ocr_model_names(
lang, ocr_version
)
if det_model_name is None or rec_model_name is None:
raise ValueError(
f"No models are available for the language {repr(lang)} and OCR version {repr(ocr_version)}."
)
text_detection_model_name = det_model_name
text_recognition_model_name = rec_model_name
改成这样

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









