






深度学习是人工智能领域的一个重要分支,它通过模拟人脑神经网络的工作原理,实现对复杂数据的高效处理。本文将为大家介绍深度学习领域的十大经典算法,帮助大家更好地理解和应用深度学习技术。
1. 卷积神经网络(CNN)
卷积神经网络(Convolutional Neural Networks,简称CNN)是一种专门用于处理具有类似网格结构的数据(如图像)的神经网络。CNN通过卷积层、池化层和全连接层等组件,实现了对图像的有效识别和分类。
首先我们来看看CNN的基本结构。一个常见的CNN例子如下图:
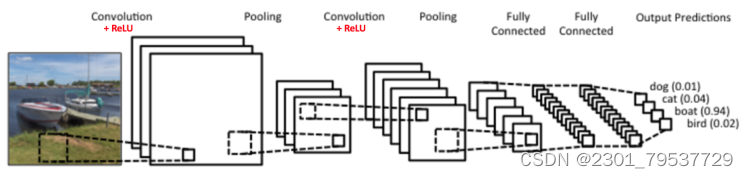
图中是一个图形识别的CNN模型。可以看出最左边的船的图像就是我们的输入层,计算机理解为输入若干个矩阵,这点和DNN基本相同。接着是卷积层(Convolution Layer),这个是CNN特有的,我们后面专门来讲。卷积层的激活函数使用的是ReLU。我们在DNN中介绍过ReLU的激活函数,它其实很简单,就是ReLU(x)=max(0,x)ReLU(x)=max(0,x)。在卷积层后面是池化层(Pooling layer),这个也是CNN特有的,需要注意的是,池化层没有激活函数。
卷积层+池化层的组合可以在隐藏层出现很多次,上图中出现两次。而实际上这个次数是根据模型的需要而来的。当然我们也可以灵活使用使用卷积层+卷积层,或者卷积层+卷积层+池化层的组合,这些在构建模型的时候没有限制。但是最常见的CNN都是若干卷积层+池化层的组合,如上图中的CNN结构。
在若干卷积层+池化层后面是全连接层(Fully Connected Layer, 简称FC),全连接层其实就是我们前面讲的DNN结构,只是输出层使用了Softmax激活函数来做图像识别的分类。
从上面CNN的模型描述可以看出,CNN相对于DNN,比较特殊的是卷积层和池化层,如果我们熟悉DNN,只要把卷积层和池化层的原理搞清楚了,那么搞清楚CNN就容易很多了。
2. 循环神经网络(RNN)
循环神经网络(Recurrent Neural Networks,简称RNN)是一种能够处理序列数据的神经网络。RNN具有记忆功能,可以捕捉序列中的长期依赖关系。常见的RNN变体有长短时记忆网络(LSTM)和门控循环单元(GRU)。
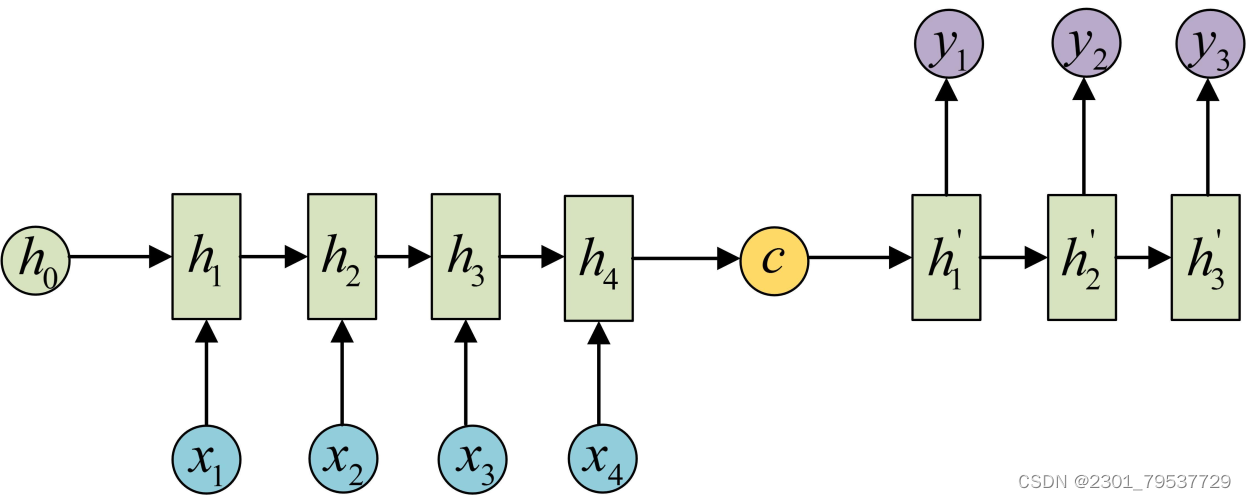
2.1RNN原理
2.1.1 基本思想
RNN的基本思想是引入“记忆”机制,使神经网络可以处理序列数据并保持对过去信息的记忆。每个时间步的隐藏状态会根据输入和前一个时间步的隐藏状态进行更新,从而实现信息的传递和保存。这使得RNN可以捕捉到上下文关系,并对时序数据进行建模。
2.1.2 循环结构
RNN的循环结构是其与其他神经网络模型最明显的区别。隐藏状态会在每个时间步上被更新,并在下一个时间步作为输入的一部分被传递。这种反馈机制允许网络保持对过去信息的记忆,并在不同时间步上共享权重,避免参数数量的爆炸性增长。
2.1.3 长期依赖问题
尽管RNN在处理序列数据时具有优势,但在处理长序列时却存在长期依赖问题。由于信息的传递和变换通过每个时间步的隐藏状态完成,当序列较长时,梯度会随着时间步的增加而指数级衰减或爆炸。为了解决这个问题,出现了一些改进的RNN结构,如LSTM和GRU。
2.2 RNN结构
2.2.1输入和输出
RNN的输入可以是任意长度的序列数据,如文本、语音等。每个时间步的输入会与隐藏状态进行计算,并得到输出结果。输出可以是每个时间步的预测结果,也可以是最后一个时间步的隐藏状态。
2.2.2 隐藏状态更新
RNN的隐藏状态更新是RNN的核心操作。隐藏状态会根据当前时间步的输入和前一个时间步的隐藏状态进行计算,并被传递给下一个时间步。隐藏状态的更新可以使用简单的线性变换和激活函数,也可以使用更复杂的门控机制。
2.2.3 参数共享
RNN中的参数共享是其特点之一。在每个时间步上,RNN使用相同的权重和偏置进行计算。这种参数共享使得RNN可以处理任意长度的序列数据,并减少了模型的参数数量,提高了训练效率。
RNN通过引入时间序列上的隐藏状态,具备处理序列数据和捕捉上下文信息的能力。RNN具有循环结构和参数共享的特点,可以处理任意长度的序列数据。在自然语言处理、语音识别和时间序列预测等领域,RNN都具有广泛的应用。
3. 自编码器(Autoencoder)
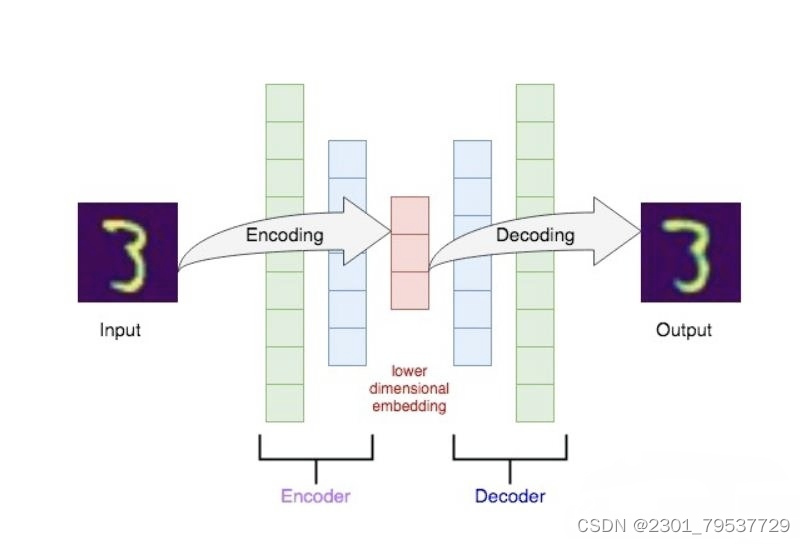
AutoEncoder是一种非监督学习的神经网络,它通过encoder网络将输入压缩为低维表达,然后通过decoder网络将低维表达再重构为原始输入,实现自动学习输入的特征表示。
AutoEncoder主要由两个部分组成:
1. Encoder: 将高维输入压缩为低维表达,实现对输入的降维与特征抽取。Encoder通常由全连接层或CNN组成。
2. Decoder: 将低维表达解码为高维输入空间,实现自动学习对输入的特征表示。解码器与编码器结构相反,也由全连接层或CNN组成。
AutoEncoder的训练目标是最小化重构误差,使得输出尽可能接近输入。在训练过程中,AutoEncoder会自动学习到输入的特征表达,这些特征表达就编码在encoder的隐层上。我们可以利用这些特征表达进行降维、聚类、预测与生成等任务。
相比于PCA等传统降维方法,AutoEncoder具有以下优点:
1. 非线性映射:AutoEncoder可以学习输入到隐空间的任意非线性映射,而PCA只能学习线性映射。
2. 更强大的特征学习能力:深层AutoEncoder可以学习输入的分层特征表达,表达能力更强。
3. 无需声明目标维数:AutoEncoder可以自动学习到最佳的编码维度,无需人工指定。
4. 可用于其他任务:AutoEncoder学习到的特征表达可用于分类、聚类、预测与生成等其他机器学习任务。
但AutoEncoder也面临一定局限,主要体现在:
1. 可能学习到 INPUT的一致性特征而非真正有用的特征。
2. deeper AutoEncoder 训练较慢且较难收敛。
3. 编码后的特征表达没有明确的统计解释(如PCA)。
AutoEncoder为无监督特征学习提供了一种有效方法,已广泛应用于数据压缩、特征抽取与其他机器学习任务。但要学习到最真实与有用的特征表达,还需对模型和训练技巧进行改进。让我们共同努力,开拓AutoEncoder这一有潜力的话题。
4. 生成对抗网络(GAN)
生成对抗网络(Generative Adversarial Networks,简称GAN)是一种生成模型,由生成器和判别器两个部分组成。生成器负责生成数据,判别器负责判断生成数据的真实性。两者相互博弈,最终使生成器能够生成逼真的数据。
GANs基本思想
4.1 基本概念
在概率统计理论里,生成模型泛指在给定一些隐含参数的条件下随机生成观测数据的模型,主要分为两类模型,第一类旨在建立数据确切的分布函数;而第二类则是在无需完全明确数据分布函数的情况下直接生成新样本,对抗生成网络就是其一个典型。
如图1所示,GANs通过对抗的方式,训练生成器(Generator)和判别器(Discriminator)两部分,其中,生成器用于生成尽量逼真的“假”样本,判别器用于尽可能准确地区分输入是真实样本还是生成的“假”样本。
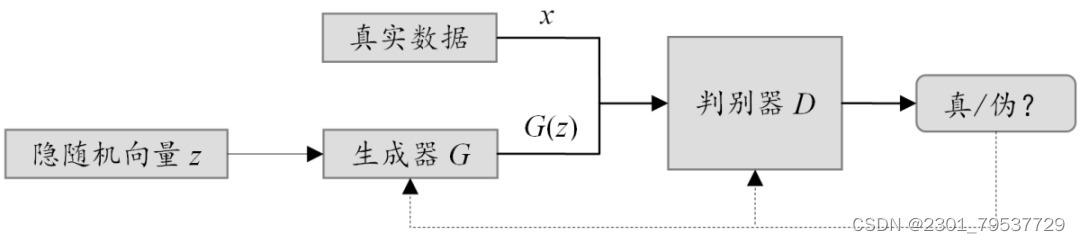
图1
具体训练过程中,生成器与判别器交替训练:首先,固定生成器,使用生成器基于隐随机向量z模拟出G(z)作为负样本,并从真实数据中采样得到正样本x,然后将正负样本输入给判别器,进行二分类预测,最后利用其二分类交叉熵损失更新判别器参数;之后固定判别器优化生成器,对于生成器,为了尽可能欺骗判别器,即尽量让判别器将生成的“假”样本判为正样本,一般考虑以最大化生成样本的判别概率为目标来优化。
4.2目标函数
对于判别器,输入样本一半来自真实数据,一半来自生成器,则其二分类交叉熵损失可表示为:
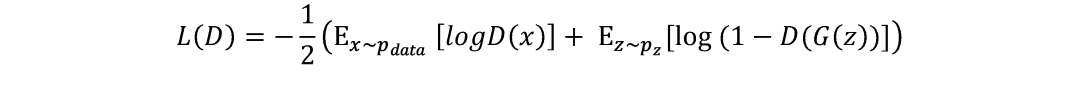
分别对应真实数据和生成数据的交叉熵损失之和,以此得到优化目标函数为:
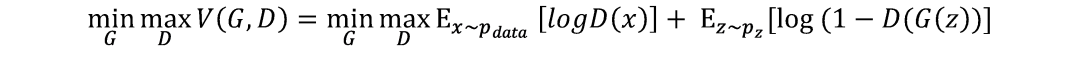
然后在训练优化阶段,一方面让判别器最大化目标函数,使得其尽量对真实数据采样样本x的预测概率D(x)趋近于1,对生成样本G(z)的预测概率D(G(z))趋近于0;另一方面,要让生成器最小化目标函数,而且logD(x)一项与生成器无关,因此此时主要是最小化后一项,使得生成器生成样本让判别器预测概率D(G(z))趋近于1即可
5. 强化学习(RL)
强化学习(Reinforcement Learning,简称RL)是一种通过与环境交互来学习最优策略的方法。强化学习的核心是智能体(Agent),它根据当前状态选择合适的动作,以获得最大的累积奖励。
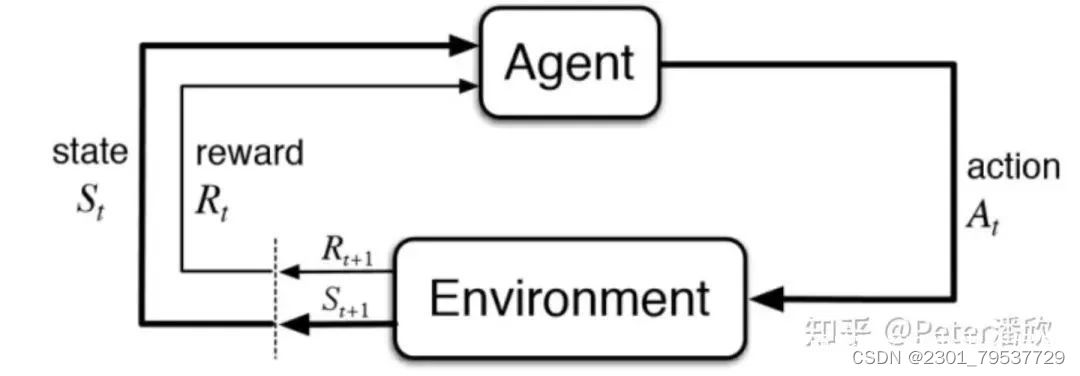
强化学习是机器学习中的⼀个领域,强调如何基于环境⽽⾏动,以取得最⼤化的预期利益。其灵感来源于⼼理学中的⾏为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产⽣能获得最⼤利益的习惯性⾏为。
它主要包含四个元素,环境状态,⾏动,策略,奖励, 强化学习的⽬标就是获得最多的累计奖励。RL考虑的是智能体(Agent)与环境(Environment)的交互问题,其中的agent可以理解为学习的主体,它⼀般是咱们设计的强化学习模型或者智能体,这个智能体在开始的状态试图采取某些⾏动去操纵环境,它的⾏动从⼀个状态到另⼀个状态完成⼀次初始的试探,环境会给予⼀定的奖励,这个模型根据奖励的反馈作出下⼀次⾏动(这个⾏动就是当前这个模型根据反馈学来的,或者说这就是⼀种策略),经过不断的⾏动、反馈、再⾏动,进⽽学到环境状态的特征规律。⼀句话概括:RL的⽬标是找到⼀个最优策略,使智能体获得尽可能多的来⾃环境的奖励。
6. 深度信念网络(DBN)
深度信念网络(Deep Belief Networks,简称DBN)是一种生成式概率图模型,由多个受限玻尔兹曼机(RBM)堆叠而成。DBN可以用于无监督预训练和有监督微调,提高神经网络的性能。
将若干个RBM“串联”起来则构成了一个DBN,其中,上一个RBM的隐层即为下一个RBM的显层,上一个RBM的输出即为下一个RBM的输入。训练过程中,需要充分训练上一层的RBM后才能训练当前层的RBM,直至最后一层。
若想将DBM改为监督学习,方式有很多,比如在每个RBM中加上表示类别的神经元,在最后一层加上softmax分类器。也可以将DBM训出的W看作是NN的pre-train,即在此基础上通过BP算法进行fine-tune。实际上,前向的算法即为原始的DBN算法,后项的更新算法则为BP算法,这里,BP算法可以是最原始的BP算法,也可以是自己设计的BP算法。例如下图使用DBN作为判别模型:
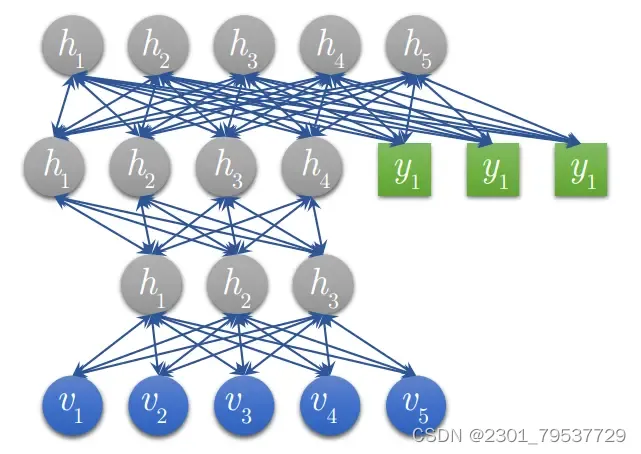
在最后的一层RBM的显层加入表示类别的神经元,一起参与训练。
DBN调优的过程是一个生成模型的过程:
1.除了顶层 RBM,其他层 RBM 的权重被分成向上的认知权重和向下的生成权重;
2.Wake 阶段:认知过程,通过外界的特征和向上的权重 (认知权重) 产生每一层的抽象表示 (结点状态) ,并且使用梯度下降修改层间的下行权重 (生成权重) 。
3. Sleep 阶段:生成过程,通过顶层表示 (醒时学得的概念) 和向下权重,生成底层的状态,同时修改层间向上的权重。
使用随机隐性神经元状态值,在顶层 RBM 中进行足够多次的吉布斯抽样; 向下传播,得到每层的状态。
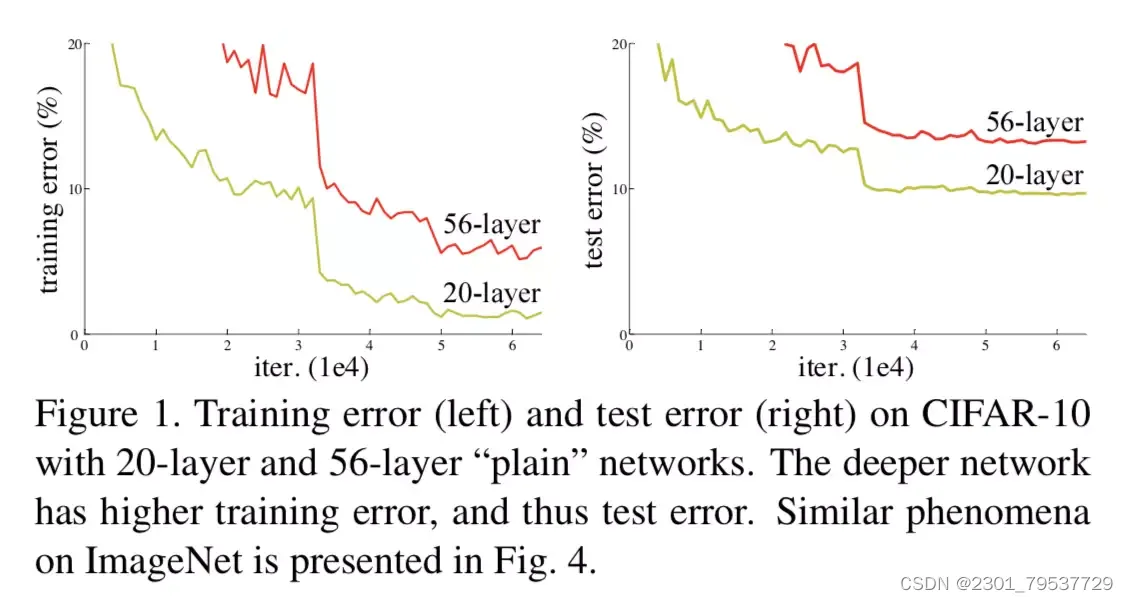
7. 深度残差网络(ResNet)
深度残差网络(Deep Residual Networks,简称ResNet)是一种解决深度神经网络训练困难的算法。ResNet通过引入残差连接,使得网络可以学习到恒等映射,从而提高网络的性能。
7.1残差
假设我们想要找一个 x,使得 f(x)=b,给定一个 x 的估计值 x0
残差(residual):b−f(x0)
误差: x−x0
7.2残差网络(Residual Networks,ResNets)
越深(deeper)的网络不会比浅层的网络效果差。由于退化问题,网络的优化变难,效果反而不如较浅(shallower)网络。
7.3残差块(residual block)
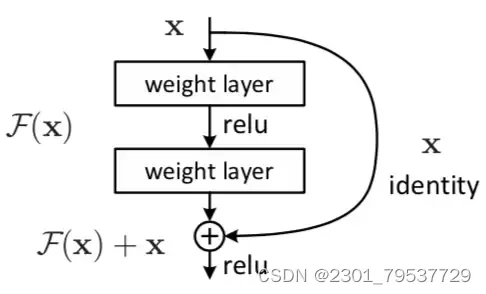
图2
如图 2 所示,x 表示输入,F(x) 表示残差块在第二层激活函数之前的输出,即 F(x)=W2σ(W1x),其中 W1 和 W2 表示第一层和第二层的权重,σ 表示 ReLU 激活函数。(这里省略了 bias。)最后残差块的输出是 σ(F(x)+x)。
原因:
如果在该 2层网络中,最优的输出就是输入 x,那么对于没有 shortcut connection 的网络,就需要将其优化成 H(x)=x;对于有 shortcut connection 的网络,即残差块,最优输出是 x,则只需要将 F(x)=H(x)−x 优化为 0 即可。后者的优化会比前者简单。
我们给一个网络不论在中间还是末尾加上一个残差块,并给残差块中的 weights 加上 L2 regularization(weight decay),这样图 1 中 F(x)=0 是很容易的。这种情况下加上一个残差块和不加之前的效果会是一样,所以加上残差块不会使得效果变得差。如果残差块中的隐藏单元学到了一些有用信息,那么它可能比 identity mapping(即 F(x)=0)表现的更好。
举例: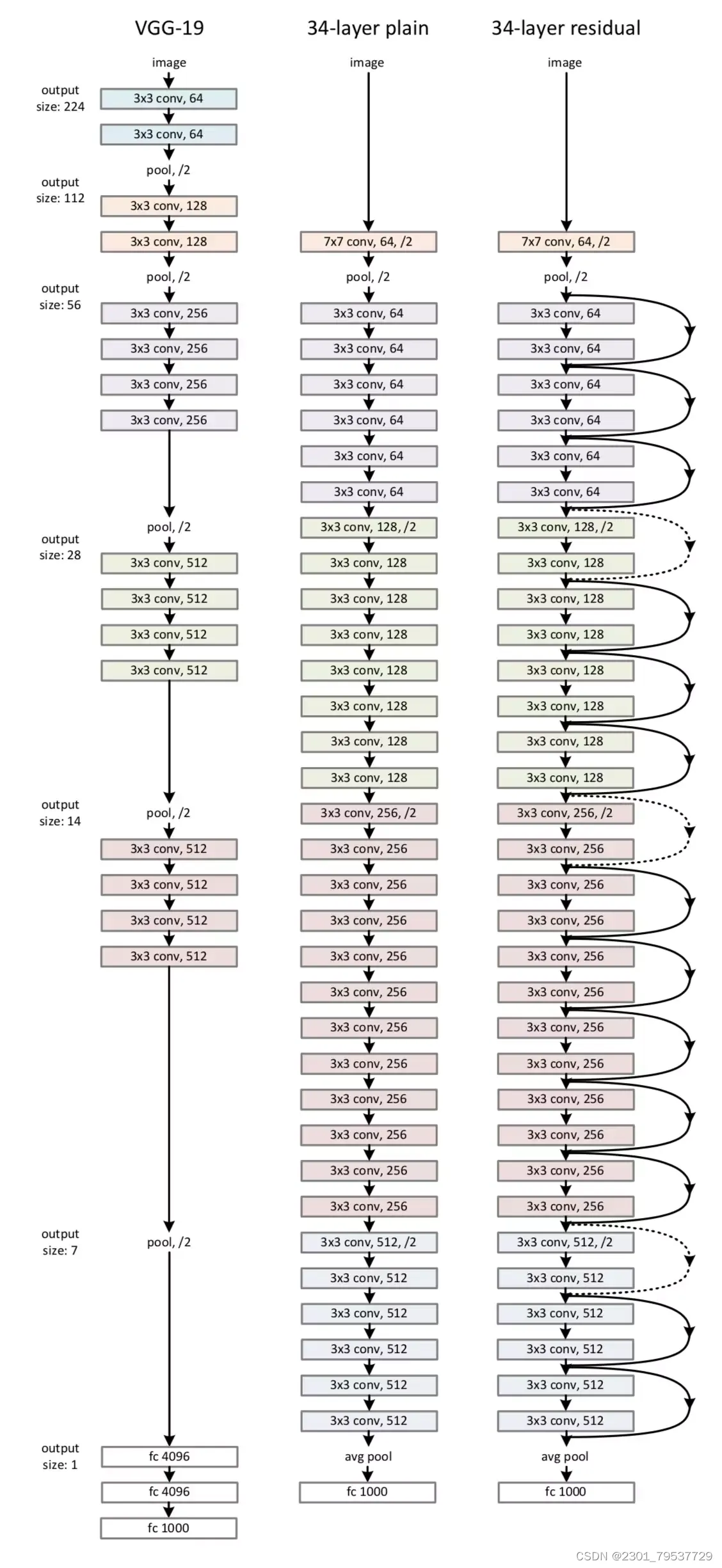
feature map 减半时,filter 的个数翻倍,这样保证了每一层的计算复杂度一致。
ResNet 因为使用 identity mapping,在 shortcut connections 上没有参数,所以 plain network 和 residual network的计算复杂度都是一样的,都是 3.6 billion FLOPs.
8. 胶囊网络(CapsNet)
胶囊网络(Capsule Networks,简称CapsNet)是一种针对卷积神经网络的改进算法。CapsNet通过引入胶囊(Capsule)的概念,提高了网络对物体姿态和变形的识别能力。
8.1胶囊网络的基本原理
胶囊网络是一种由胶囊(Capsule)组成的神经网络结构。胶囊是一组神经元的集合,它们通过向量的形式来表示特定的特征或概念。胶囊内部的神经元之间具有动态路由的机制,可以根据数据的特点动态地调整各个胶囊之间的连接权重。
胶囊网络与传统的CNN不同之处在于,它在低层次的特征检测上引入了胶囊的概念。传统CNN中,通过卷积操作来提取特征,并通过池化操作进行特征降维。而胶囊网络则在这一过程中引入了胶囊层,使得网络能够更加有效地学习特征的空间关系和层级结构。
8.2胶囊网络的特点
8.2.1动态路由:胶囊网络通过动态路由机制来调整各个胶囊之间的连接权重。这使得网络能够自适应地学习不同特征之间的空间关系,从而提高了特征的稳定性和鲁棒性。
8.2.2层级结构:胶囊网络具有层级结构,每一层胶囊代表了不同层次的特征。这使得网络能够更好地捕捉图像和数据的多层次特征,并实现更高层次的抽象和表示。
8.2.3姿态估计:胶囊网络可以进行姿态估计,即判断图像中不同物体之间的相对关系和位置。这使得网络在处理图像中存在变形或遮挡的情况下更加鲁棒和准确。
8.2.4解决池化问题:胶囊网络可以避免传统CNN中的池化操作,从而减少了特征降维过程中的信息损失,有利于提高图像识别和分类的准确性。
8.3胶囊网络的应用领域
胶囊网络在计算机视觉和自然语言处理等领域有着广泛的应用。
8.3.1图像识别与分类:胶囊网络在图像识别和分类任务中表现出色。它可以更好地捕捉图像中的多层次特征,实现更准确的识别和分类。
8.3.2目标检测与跟踪:胶囊网络的姿态估计功能使其在目标检测和跟踪任务中具有优势。它可以更准确地判断图像中不同物体的相对位置,从而实现更精确的目标检测和跟踪。
8.3.3自然语言处理:胶囊网络可以应用于自然语言处理任务中,例如情感分析和文本分类。它可以更好地理解文本中的层级结构和语义关系,从而实现更准确的文本分类和情感分析。
9. 深度Q网络(DQN)
9.1 DQN简介
9.1.1 强化学习与神经网络
该强化学习方法是这么一种融合了神经网络和Q-Learning的方法,名字叫做Deep Q Network。
Q-Learning使用表格来存储每一个状态state,和在这个state每个行为action所拥有的Q值。而当今问题实在是太复杂,状态可以多到比天上的星星还多(比如下围棋)。如果全用表格来存储它们,恐怕我们的计算机有再大的内存都不够,而且每次在这么大的表格中搜索对应的状态也是一件很耗时的事。不过在机器学习中,有一种方法对这种事情很在行,那就是神经网络。我们可以将状态和动作当成神经网络的输入,然后经过神经网络的分析得到动作的Q值,这样我们就没有必要在表格中记录Q值,而是直接使用神经网络分析后得到动作的Q值,这样我们就没必要在表格中记录Q值,而是直接使用神经网络生成Q值。还有一种形式是这样,我们也只能输入状态值,输出所有的动作值,然后按照Q-Learning的原则,直接选择拥有最大值的动作当做下一步要做的动作。我们可以想象,神经网络接收外部的信息,相当于眼睛比子耳朵收集信息,然后经过大脑加工输出每种动作的值,最后通过强化学习的方式选择动作。
9.1.2 更新神经网络
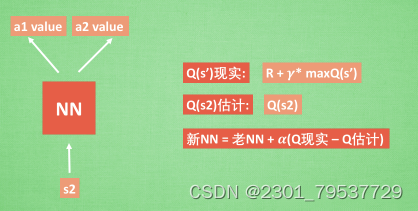
接下来我们基于第二种神经网络来分析,我们知道,神经网络是要被训练才能预测出准确的值。那在强化学习中,神经网络是如何被训练的呢?首先,我们需要a1,a2正确的Q值,这个Q值我们就用之前在Q-Learning中的Q现实来代替。同样我们还需要一个Q估计来实现神经网络的更新。所以神经网络的参数就是老的NN参数加学习率α乘以Q现实和Q估计的差距。我们整理一下
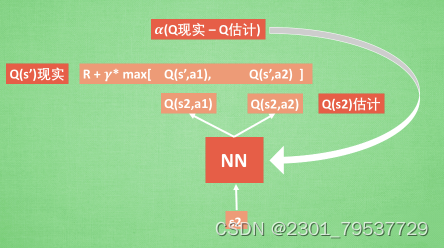
通过NN预测出Q(s2, a1)和Q(s2,a2)的值,这就是Q估计。然后我们选取Q估计中最大值的动作来换取环境中的奖励reward。而Q现实中也包含从神经网络分析出来的两个Q估计值,不过这个Q估计是针对于下一步在s’的估计。最后再通过刚刚所说的算法更新神经网络中的参数。但是这并不是DQN会玩电脑的根本原因。还有两大因素支撑着DQN使得它变得无比强大。这两大因素就是Experience replay和Fixed Q-targets。
9.1.3 DQN两大利器
简单来说,DQN有一个记忆库用于学习之前的经历。Q-Learning是一种off-policy离线学习法,它能学习当前经历着的,也能学习过去经历过的,甚至是学习别人的经历。所以每次DQN更新的时候,我们都可以随机抽取一些之前的经历进行学习。随机抽取这种做法打乱了经历之间的相关性,也使得神经网络更新更有效率。Fixed Q-targets也是一种打乱相关性的机理,如果使用fixed Q-targets也是一种打乱相关性的机理,如果使用fixed Q-targets,我们就会在DQN中使用到两个结构相同但参数不用的神经网络,预测Q估计的神经网络具备最新的参数,而预测Q现实的神经网络使用的参数则是很久以前的。有了这两种提升手段,DQN才能在一些游戏中超越人类。
10. Transformer
Transformer是一种基于自注意力机制(Self-Attention Mechanism)的神经网络结构。Transformer在自然语言处理领域取得了显著的成果,如机器翻译、文本摘要等任务。
10.1Transformer模型结构
Transformer的主体结构图:
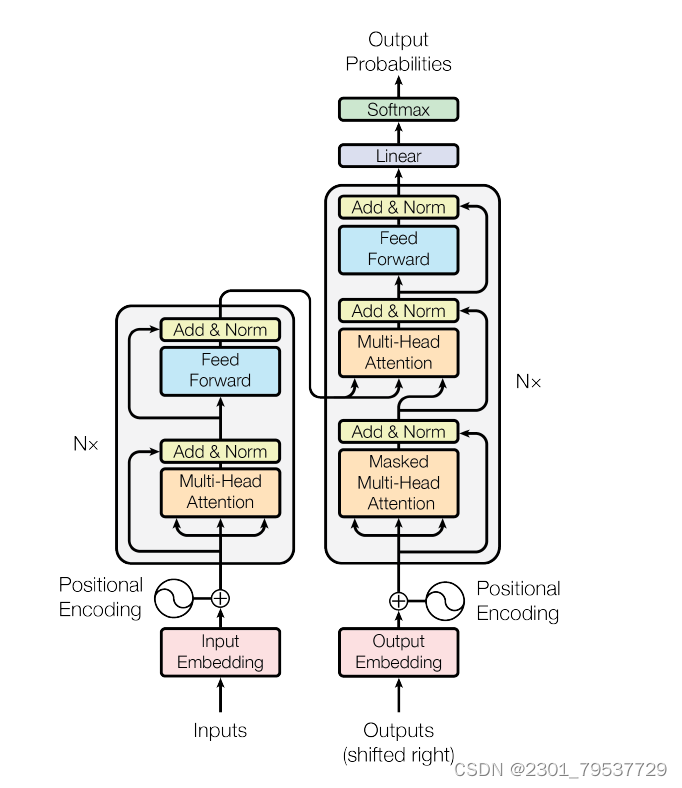
10.2Transformer的编码器解码器
模型分为编码器和解码器两个部分。
*编码器由6个相同的层堆叠在一起,每一层又有两个支层。第一个支层是一个多头的自注意机制,第二个支层是一个简单的全连接前馈网络。在两个支层外面都添加了一个residual的连接,然后进行了layer nomalization的操作。模型所有的支层以及embedding层的输出维度都是dmodel。
*解码器也是堆叠了六个相同的层。不过每层除了编码器中那两个支层,解码器还加入了第三个支层,如图中所示同样也用了residual以及layer normalization。具体的细节后面再讲。
10.3输入层
编码器和解码器的输入就是利用学习好的embeddings将tokens(一般应该是词或者字符)转化为d维向量。对解码器来说,利用线性变换以及softmax函数将解码的输出转化为一个预测下一个token的概率。
10.4位置向量
以上就是深度学习领域的十大经典算法。希望本文能帮助大家更好地理解和应用深度学习技术,共同探索AI的奥秘。
10.5 Attention模型
10.5.1 Scaled attention
论文中用的attention是基本的点乘的方式,就是多了一个所谓的scale。输入包括维度为dk的queries以及keys,还有维度为dv的values。计算query和所有keys的点乘,然后每个都除以dk(这个操作就是所谓的Scaled)。之后利用一个softmax函数来获取values的权重。实际操作中,attention函数是在一些列queries上同时进行的,将这些queries并在一起形成一个矩阵Q同时keys以及values也并在一起形成了矩阵K以及V。则attention的输出矩阵可以按照下述公式计算:
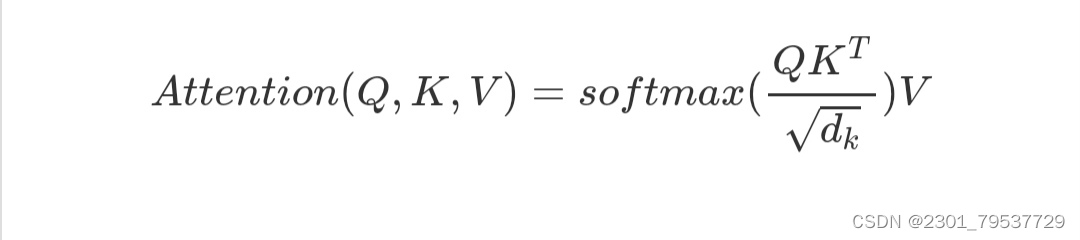
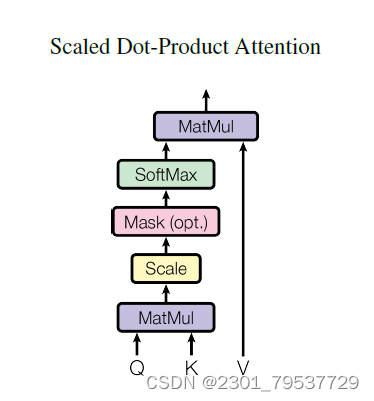
10.5.2 Multi-Head Attention
本文结构中的Attention并不是简简单单将一个点乘的attention应用进去。作者发现先对queries,keys以及values进行h次不同的线性映射效果特别好。学习到的线性映射分别映射到dk,dk以及dv维。分别对每一个映射之后的得到的queries,keys以及values进行attention函数的并行操作,生成dv维的output值。具体结构和公式如下。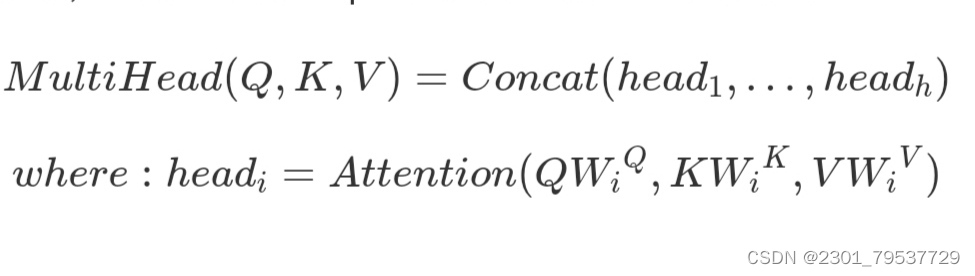
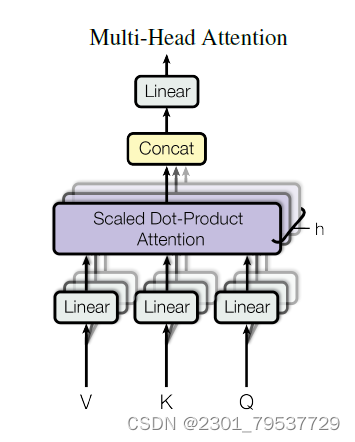
10.5.3 模型中的attention
Transformer以三种不同的方式使用了多头attention。
在encoder-decoder的attention层,queries来自于之前的decoder层,而keys和values都来自于encoder的输出。这个类似于很多已经提出的seq2seq模型所使用的attention机制。
在encoder含有self-attention层。在一个self-attention层中,所有的keys,values以及queries都来自于同一个地方,本例中即encoder之前一层的的输出。
类似的,decoder中的self-attention层也是一样。不同的是在scaled点乘attention操作中加了一个mask的操作,这个操作是保证softmax操作之后不会将非法的values连到attention中。
10.5.4 Feed Foreword
每层由两个支层,attention层就是其中一个,而attention之后的另一个支层就是一个前馈的网络。公式描述如下。
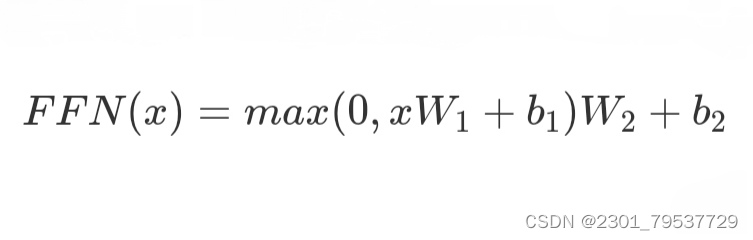
模型的整体框架基本介绍完了,其最重要的创新应该就是Self-Attention和Multi-Head Attention的架构。在摒弃传统CNN和RNN的情况下,还能提高表现,降低训练时间。Transformer用于机器翻译任务,表现极好,可并行化,并且大大减少训练时间。并且也给我们开拓了一个思路,在处理问题时可以增加一种结构的选择。
以上就是深度学习的十大算法。















 7352
7352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









