










目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
设计思路
一、课题背景与意义
近年来随着"河长制"管理制度的实施,工厂向河流中集中排污现象已基本消失,水体环境得到明显改善,但仍存在居民乱丢乱弃的现象,水面中漂浮着些许生活垃圾。传统人工巡检、记录污染物分布位置、上报的河道监管方式效率低下、成本高且不具备信息透明性。
二、算法理论原理
2.1 目卷积神经网络
深度学习作为人工智能的一个重要组成部分,在图片识别及分类、目标检测、无人驾驶、机器翻译、语音识别等多个领域推动了发展。根据核心算法的区别,深度学习包括卷积神经网络(CNN)、循环神经网络(RNN)、置信网络(BN)等。在图像识别、目标检测、图像分割等领域,卷积神经网络具有许多优势。
由于图像在计算机中通常以多维数组表示,利用卷积核对多维数组进行卷积可以共享参数,从而大大减少参数数量。典型的卷积神经网络由卷积层(CONV)、非线性激活函数、池化层和全连接层(FC)构成。
卷积层负责将上层输入的原始图像或特征图与本层的卷积核进行卷积,以提取特征。为了提高网络的泛化能力,卷积层采用局部连接方式,即卷积核只连接局部相邻区域的特征图。
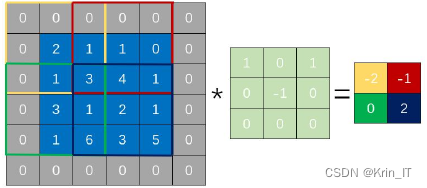
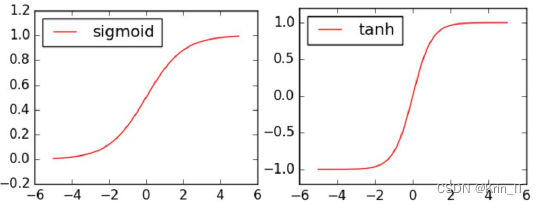
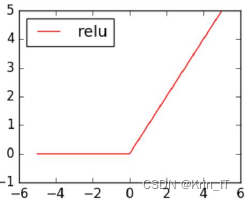
非线性激活函数是指将上层节点提取到的特征值进行一个非线性的函数映射,其作用是让网络具备非线性变化的能力。如果不使用非线性激活函数,即使网络层数再多,输入和输出之间也都是一个线性关系,和单层网络结构的效果是相当的,网络的预测能力也就差强人意了。非线性激活函数对上层节点提取的特征值进行非线性映射,使网络具备非线性变化的能力。常用的非线性激活函数有Sigmoid函数、Tanh函数、ReLU函数和Softmax函数。
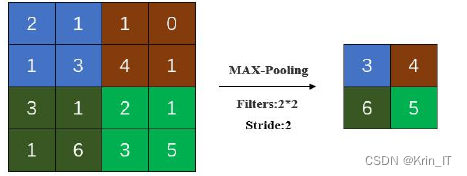
池化层又被称之为下采样层,其目的在于减少网络需要学习的参数量,来提高模型的运算效率,另外还具备扩大感受野和提高网络泛化的能力。目前最为常见的池化方式主要有:最大值池化和均值池化。最大值池化是指选取一个邻域内最大的特征值来代替整个邻域的特征值,由于这种映射属于非线性变化,因此可以提高模型的非线性逼近能力;
均值池化是指让一个邻域内特征值的平均值来代替整个邻域的特征值,这种映射属于线性变化,可以使提取到的特征变得更加平滑。池化层共有三个参数:池化核尺寸、步长、边界扩充。
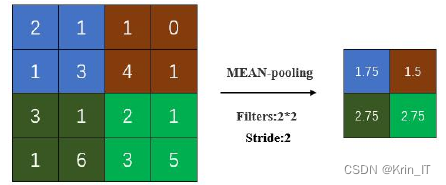
全连接层对经过卷积和池化层提取的特征进行分类,类似于传统机器学习中的分类算法。在卷积神经网络中,全连接层将经过多层卷积和池化后得到的三维特征矩阵展平为一维列向量,然后通过加权和加偏置的操作,并经过激活函数如sigmoid或softmax函数,得到分类结果。全连接层的参数与特征值之间采用全连接方式,因此占据了整个卷积神经网络大约80%的参数。将卷积、激活函数、
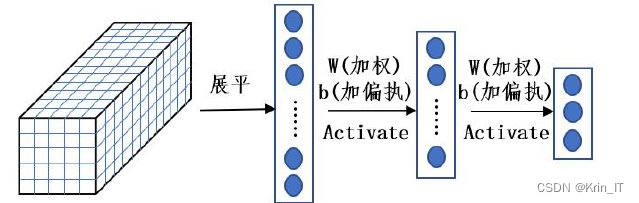
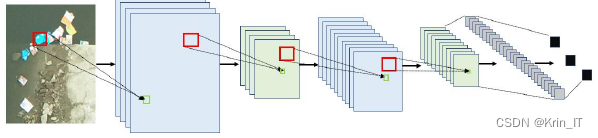
池化和全连接等模块有目的地组合起来,就构成了一个卷积神经网络。标准的卷积神经网络示意图如下所示:
2.1 改进的YOLOv5算法
YOLOv5s训练和检测阶段的大致流程为:
- 将输入的河道影像通过Mosaic增强后自适应缩放至640×640大小,然后按设定的批次(minibatch)作为卷积神经网络的输入。
- 通过前向传播得到垃圾预测框的位置、大小以及所包含垃圾的类别。前向传播包括特征提取(Backbone)、特征融合(Neck)与检测头(Prediction)三部分。
- 利用损失函数计算预测框与标注文件中的真实框之间的差别。
- 通过梯度下降迭代更新前向传播中的权重矩阵和偏置,来减小预测框与真实框之间的损失。
- 求取规定迭代次数下损失函数取最小值时的权重矩阵和偏置。
- 将权重矩阵和偏置作为检测阶段前向传播的参数来求取待检测河道影像中垃圾的预测信息。


YOLOv5s结构如图所示。首先将经过自适应缩放至640×640大小的图像通过特征提取网络(Backbone)得到20×20、40×40、80×80三个不同尺寸的特征图。然后将20×20的特征图经过两次上采样(采样率为2)、40×40的特征图经过一次上采样(采样率为2)与80×80的特征图进行特征融合(Neck),得到用来检测小垃圾的特征图。同样的方式可以得到用来检测中等垃圾和大垃圾的特征图。这样的做法是为了让网络既可以学习到垃圾的深层特征,也可兼顾浅层特征。最后利用检测头(Prediction)来预测三种不同大小的垃圾。
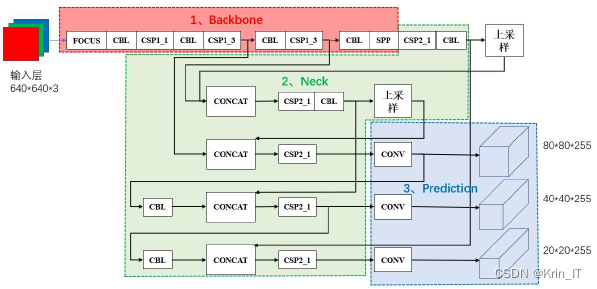
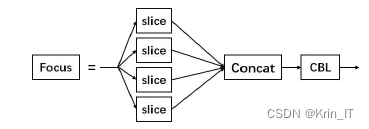
Focus模块相当于将输入的图像先复制四份,然后每一份图像都隔像素取值,最后将四份图像进行通道融合(Concat),这样就得到了没有丢失信息的二倍下采样图。
CBL模块是指图像的卷积(Convolution, Conv)、批量归一化(Batch Normalization, BN)和Leaky_ReLU函数激活。
![]()
CSP1模块是将输入的图像分成两支,其中一支流向残差结构后卷积再与另一支的卷积图像进行通道融合。

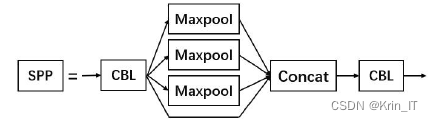
SPP(空间金字塔池化)模块是将输入图像分别进行滤波器为55、99、13*13的最大值池化,然后将原图像与池化后的三幅图像进行通道融合。

CSP2模块是将输入图像分为两支,其中一支流向两个CBL模块后卷积再与另一支的卷积图像进行通道融合。

上采样模块采用的是两倍最近邻插值的方式。
输入的河道影像经过特征提取和特征融合网络后会生成三个下采样(8倍、16倍和32倍)的特征图(例如,对于640×640的输入河道影像,将会得到20×20、40×40和80×80的三个特征图)。每个特征图的每个方格都包含3×(1+4+C)个通道,用于预测三种不同尺寸的目标。其中,3代表锚框的数量,1代表锚框的置信度,4代表锚框坐标相对于先验锚框的偏移量(tx, ty, tw, th),C代表目标类别的总数。 如果目标的中心点位于方格内,该方格负责预测目标的锚框位置和尺寸,以及锚框的类别置信度。
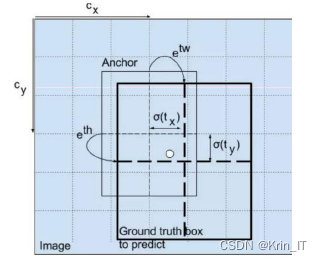
Class-Specific Confidence Score表示锚框的类别置信度,Pr(classi∣ object)表示目标属于第i类的概率。这个乘积同时预测了锚框的类别和准确度。
三、漂浮垃圾检测的实现
3.1 数据集
目前常用的公开数据集上还没有发现可用于训练的样本。专门制作了适用于河道漂浮垃圾检测的数据集。影像数据来源于无人机在WGS84坐标系下对数十条河流的倾斜摄影。数据集标注使用Windows 10操作系统和Labelme标注软件,标注文件格式转换采用Python脚本语言。
数据预处理使用OpenCV 4.5.1库。通过无人机在不同时间段、不同飞行高度下,以及相机以不同角度对河流进行倾斜摄影,增加影像的时间和空间多样性,以确保算法训练结果的全面性和准确性。无人机倾斜摄影作业平均分布在早晨7点到下午6点,飞行高度包括20m、30m、40m、50m和70m,机载相机与水平方向夹角包括90度、60度和45度。

在垃圾较为密集的区域,通过无人机控制手柄进行不同角度和高度的手动飞行拍摄,以增加垃圾影像的数量。图3-2展示了河道漂浮垃圾数据集中的原始影像。

目标检测模型在对数据集中的数据进行训练学习的过程中需要对影像中的目标进行标记,本文使用Labelme标注工具对影像进行了标注。图3-3展示了数据集中的标注影像。

3.2 实验及结果分析
区段范围的确定
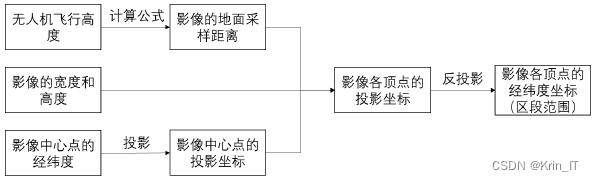
确定各正射影像所覆盖的河道区段范围具体流程为:
a. 根据无人机拍摄影像时的飞行高度,求解影像的地面采样距离;
b. 对影像中心点进行投影,得到中心点的投影坐标;
c. 利用影像的地面采样距离、宽度和高度以及中心点的投影坐标,求得影像各顶点的投影坐标;
d. 对影像顶点进行反投影,得到各顶点的经纬度(区段范围)。如图5-8所示。
步骤a中,想要利用无人机飞行高度精确解算影像的地面采样距离,首先需要通过相机标定法来求取机载相机的焦距,然后再利用小孔成像原理实现,具体计算公式如下:
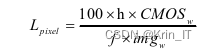
因河流流速、人为等因素,河道漂浮垃圾并不会固定在一个位置,利用相机标定法解算机载相机焦距进而求取影像的精确地面采样距离并无意义,故本文采用大疆无人机官网给定的地面采样距离公式如下:
![]()
影像左上顶点投影坐标是依据下列公式得到的,同理可求得各顶点投影坐标。式中,LTx、LTy分别为影像左上顶点在UTM投影中的x、y坐标,Cx、Cy分别为影像中心点在UTM投影中的x、y坐标,imgh为影像高度。
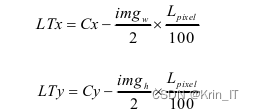
不同种类的垃圾给河流造成的污染程度不同,因此想要依据各种类垃圾的数量来量化区段的污染程度,需要先确定各类垃圾的权重值。主观赋权法是专家根据决策问题并结合自身经验来确定权重值的,该方法的研究较为成熟,不会出现权重与实际重要程度不符的情况。层次分析法(Analytic Hierarchy Process, AHP)是一种常用的主观赋权法,该方法结合专家经验在利用较少数据信息的前提下就可得到较好的结果。

部分代码如下:
# 加载并预处理图像
def preprocess_image(image_path):
image = Image.open(image_path)
image = image.convert('RGB')
image = torch.from_numpy(np.array(image)).float()
image /= 255.0
image = image.permute(2, 0, 1)
return image.unsqueeze(0).to(device)
# 进行水上漂浮垃圾检测
def detect_water_garbage(image_path):
image = preprocess_image(image_path)
# 使用YOLOv5进行目标检测
results = model(image)
# 获取检测结果
detections = results.pandas().xyxy[0]
# 过滤出水上漂浮垃圾的检测框
water_garbage_detections = detections[detections['class'] == 'water_garbage']
# 可根据需要对检测结果进行进一步处理或输出
return water_garbage_detections
# 指定输入图像路径进行水上漂浮垃圾检测
image_path = 'input_image.jpg'
detections = detect_water_garbage(image_path)
# 可根据需要对检测结果进行处理或输出
print(detections)创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!















 2672
2672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









