






目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的异常网络流量检测系统
设计思路
一、课题背景与意义
随着互联网的快速发展,网络安全问题日益突出。异常网络流量是网络攻击和入侵的重要指标之一,因此,开展基于深度学习的异常网络流量检测系统的研究具有重要的意义和应用价值。该系统可以通过学习网络流量的模式和行为规律,自动检测并识别潜在的异常流量,为网络安全管理人员提供及时的预警和响应措施,从而保护网络的安全性和稳定性。
二、算法理论原理
2.1 生成对抗网络
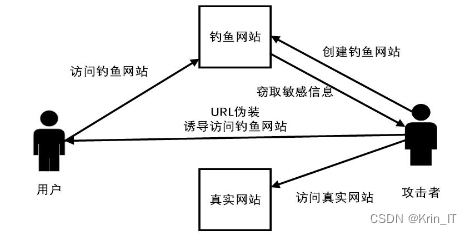
网络异常流量攻击是针对网络的安全和稳定性的一种威胁,常见的攻击类型包括分布式拒绝服务、畸形报文攻击、网络钓鱼和SQL注入攻击。这些攻击通过大量流量淹没网络、诱使用户透露敏感信息或利用数据库漏洞获取未经授权的访问或窃取数据。随着攻击趋势的复杂化,组织需要采取强大的安全措施,并利用人工智能和机器学习技术进行异常流量检测,以提高准确性和实时处理能力。
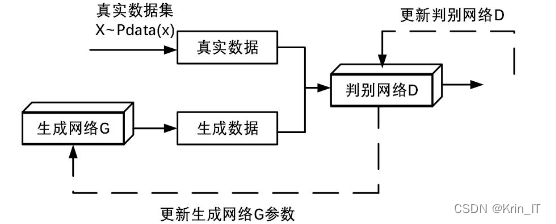
生成对抗模型(GAN)是一种深度学习模型,由生成器和判别器两个部分组成,通过互相对抗的训练方式来生成高质量的输出。生成器通过生成伪造样本来欺骗判别器,而判别器则努力识别真实样本和伪造样本的差异。通过不断的迭代训练,生成器和判别器逐渐提升自己的能力,最终达到生成逼真样本的目标。生成对抗模型可以用于生成各种类型的数据,如图像、文本和音频等。
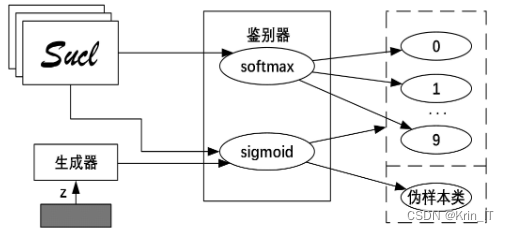
监督生成式对抗网络(SGAN)是一种结合了生成式对抗网络(GAN)和半监督学习的深度学习模型。它包括一个生成器和一个鉴别器,通过对真实和虚假数据进行区分来训练模型。在半监督设置下,鉴别器还被训练来对标记数据进行分类,并将真实数据分为N+1个类别,其中N是数据集中的类别数,而生成器生成的伪样本属于其中一个类别。SGAN使用对抗性损失和分类损失的组合进行训练,对抗性损失鼓励生成器生成与真实数据无法区分的样本,而分类损失用于训练鉴别器对标记数据进行正确分类。SGAN的目标是最大程度地利用标记数据和生成数据,并最小化未标记数据的可能性。由于它可以从有标签和无标签的数据中学习,因此在标记数据稀缺或昂贵的情况下特别有用。在训练过程中,SGAN的生成器旨在成为一个准确率接近全监督分类器的半监督分类器。与传统的GAN相比,SGAN的区别在于鉴别器需要处理多个类别的任务,从而增加了模型架构、训练过程和训练目标的复杂性。训练完毕后,生成器被丢弃,而训练有素的鉴别器被用作分类器。
2.2 自注意力机制
自注意力机制在半监督学习和图结构学习中具有重要应用。在半监督学习中,自注意力机制可以利用无标签数据的相似性为其生成标签,扩展训练数据并提高模型性能。在图结构学习中,自注意力机制可以对节点之间的关系进行建模,并生成更准确的图表示。它能够自适应地计算节点之间的相似度,适应不同图结构的数据,提高模型的适应性和泛化能力。自注意力机制在自然语言处理任务中也起到关键作用,使模型能够根据输入特征与输出的相关性学习权重,从而更有效地捕捉输入特征之间的长程依赖和关系,提高性能。
2.3 异常流量监测
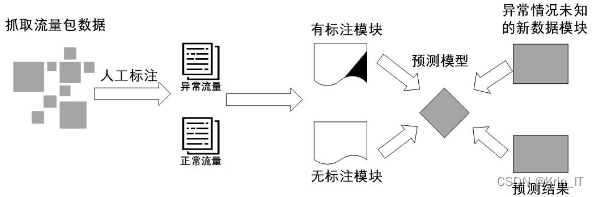
异常流量检测是网络安全中的重要组成部分,旨在识别和防止未授权访问和恶意活动。它可以通过基于签名、基于异常和基于行为的方法来实现。基于签名的检测使用已知攻击签名的数据库来识别潜在的威胁,但受到数据库更新限制。基于异常的检测通过识别与正常网络行为的偏差来标记潜在的安全威胁,但可能会产生假阳性警报。基于行为的检测侧重于用户和设备的行为,提供更全面的网络活动视图,但需要更多的数据量和资源。
联邦学习是一种在不共享隐私数据的情况下进行协同训练的方法,最初由Bernd等人提出。与传统的集中式模型训练不同,联邦学习通过传递加密的梯度相关数据,让多个数据源协同训练同一个模型。在异常流量检测领域,联邦学习的方法受到广泛关注,因为它能够很好地解决不同数据源的隐私保护问题。基于联邦学习框架的网络异常流量检测模型是DFC-NID,它结合了自动编码器技术和深度神经网络。该模型对初始数据进行预处理和归一化处理,利用自动编码器技术实现特征降维,得到一个通用模型模块。多个参与方使用这个通用模型进行联邦学习训练,并将训练完成后的参数上传至中心服务器进行迭代更新。最终,通过Softmax分类器得到最终的分类预测结果。
基于双向循环生成对抗网络的异常流量检测引入对抗学习异常检测(ALAD),通过潜在空间来表示原始特征,提高对原始特征的可理解性。然后,采用双向循环对抗的结构确保真实空间和潜在空间之间的一致性,提高生成对抗网络(GAN)的训练稳定性和异常检测性能。该方法还引入了Wasserstein距离和谱归一化优化方法来改进GAN的目标函数,以解决模式崩溃和生成器缺乏多样性的问题。最后,通过引入带有Dropout操作的全连接层网络对异常检测结果进行优化,以应对异常流量攻击数据统计属性的变化。
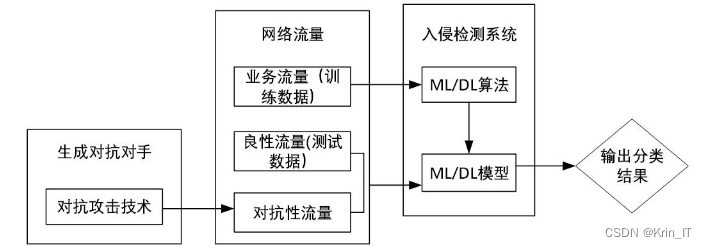
三、检测的实现
3.1 数据集
由于网络上没有现有的合适的异常网络流量数据集,我通过互联网爬取收集两种方式进行数据集的收集。通过互联网收集了大量的网络流量样本,包括来自真实网络环境和模拟网络攻击的数据。在数据扩充过程中,我使用了网络流量数据的混合、噪声添加和特征变换等方法。这些技术能够生成具有不同特征和变化模式的网络流量样本,增加了模型对各种异常流量的识别能力。数据扩充为基于深度学习的异常网络流量检测系统的研究提供了更加全面和可靠的数据基础,提高了系统的准确性和鲁棒性。
augmenter = iaa.Sequential([
iaa.MixAugment(),
iaa.AdditiveGaussianNoise(),
iaa.Affine()
])
# 设置扩充后的样本数量
num_augmented_samples = 10000
# 扩充数据
augmented_data = []
for _ in range(num_augmented_samples):
augmented_sample = augmenter.augment_image(original_data)
augmented_data.append(augmented_sample)
# 将原始数据和扩充后的数据合并
combined_data = np.concatenate((original_data, np.array(augmented_data)), axis=0)
3.2 实验环境搭建
实验环境使用Windows操作系统,并利用Python作为主要的编程语言进行算法和模型的实现。这样的实验环境提供了一个方便和高效的平台,用于开发和测试算法系统。针对所有的数据集,使用了窗口大小为60和步幅大小为10的设置。采用学习速率为0.002的Adam优化器来更新所有参数。时间表示方面,使用了一层LSTM来提取特征。图形结构方面,采用了一个学习率为0.2的自注意层来学习图形结构。归一化流框架作为数据预处理的方法。
3.3 实验及结果分析
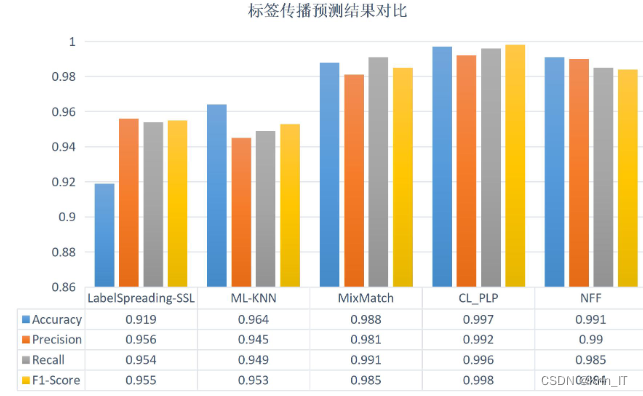
在分类任务中,常见的评价指标有准确率(ACC)、精确率(P)、召回率(TPR)、假正例率(FPR)、F1值和AUC。准确率衡量分类器预测正确的样本数占总样本数的比例,精确率表示分类器预测为某类别的样本中实际属于该类别的比例,召回率表示实际属于某类别的样本中分类器成功预测为该类别的比例,假正例率表示实际属于其他类别的样本中分类器错误地预测为该类别的比例,F1值综合了精确率和召回率,AUC衡量分类器在不同分类阈值下的综合性能。这些指标可以根据任务需求选择使用,综合考虑可以更全面地评估分类器的性能。
相关代码示例:
import numpy as np
from sklearn.svm import OneClassSVM
# 加载有标签样本和无标签样本
labeled_samples = np.load('labeled_samples.npy')
unlabeled_samples = np.load('unlabeled_samples.npy')
# 训练有标签样本的分类器
labeled_labels = labeled_samples[:, -1] # 假设标签列在最后一列
labeled_features = labeled_samples[:, :-1] # 假设特征列在前面
classifier = OneClassSVM()
classifier.fit(labeled_features)
# 利用有标签样本训练的分类器进行异常检测
predicted_labels = classifier.predict(unlabeled_samples[:, :-1])
# 设置阈值来确定异常样本
threshold = 0 # 需根据实际情况调整
anomalies = unlabeled_samples[predicted_labels < threshold]
# 输出异常样本
for anomaly in anomalies:
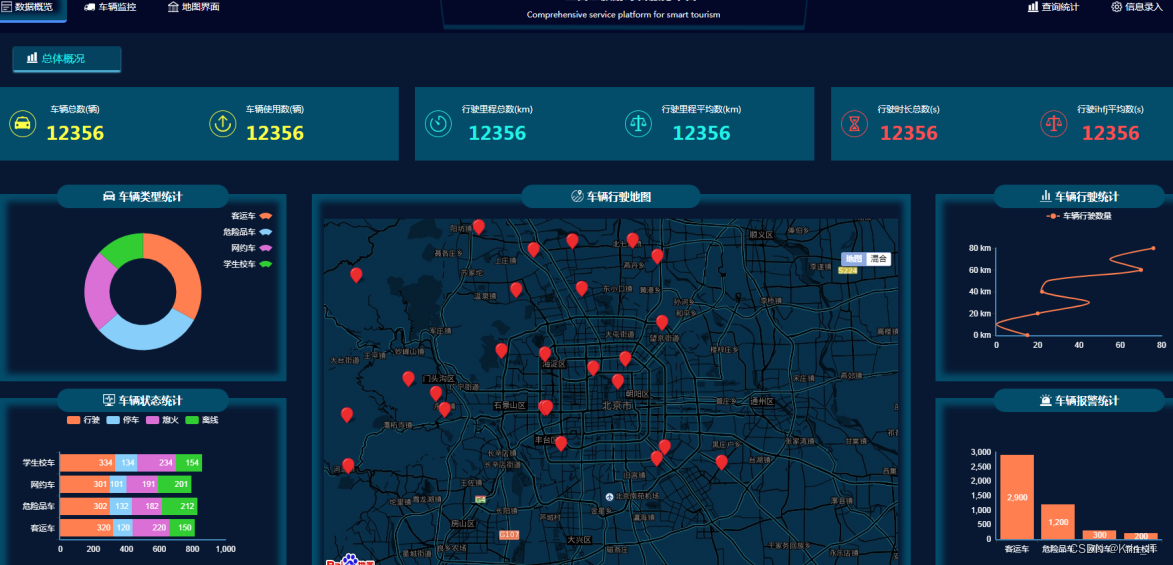
print(anomaly)实现效果图样例:



创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!















 1322
1322











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









