







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于机器学习的婺源天气数据预测
设计思路
一、课题背景与意义
婺源作为中国著名旅游目的地,其独特的自然风光和气候特征吸引了大量游客。了解和预测婺源的天气变化,不仅有助于游客规划行程,也对当地农业、旅游业和生态保护等方面具有重要意义。传统的天气预测方法往往依赖于复杂的气象模型和人工分析,而随着数据科学和可视化技术的发展,利用历史天气数据进行可视化分析和预测,能够帮助我们更直观地理解天气变化趋势,从而做出更为科学的决策。
二、算法理论原理
2.1 机器学习
随机森林是一种强大的集成学习方法,基于决策树的构建和组合,广泛应用于各种回归和分类问题。它通过构建大量的决策树,并根据多数投票或平均值来得到最终的预测结果,从而提高模型的准确性和稳定性。随机森林的核心理念是引入随机性,通过随机抽样和随机特征选择来减少模型的方差,降低过拟合的风险。在构建随机森林时,使用自助法(Bootstrap)进行样本抽样,即从原始数据集中随机选取多个样本,形成多个训练子集。每棵决策树在训练时仅使用其中一个子集,并在每个节点的分裂过程中随机选择一部分特征进行最佳分割。这样做的结果是,多棵树的多样性得以增强,最终通过集成的方式提高模型的泛化能力和鲁棒性。
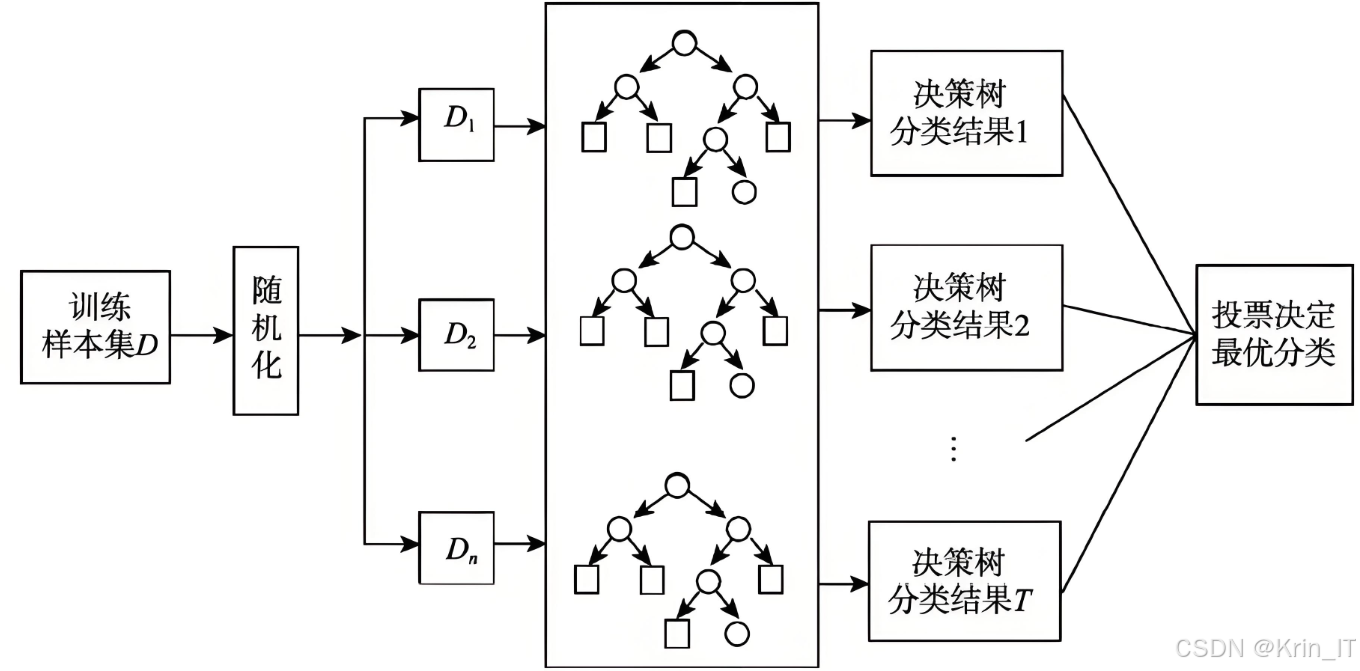
随机森林的优点非常明显。首先,它能够处理高维数据和大量特征而不需要进行特征选择。其次,它对缺失值具有较强的鲁棒性,能够有效地处理数据中存在的缺失情况。此外,随机森林提供了特征重要性评分,可以帮助分析哪些特征对预测结果影响最大,从而为后续的特征工程提供指导。在实际应用中,随机森林被广泛用于天气数据的预测,能够捕捉复杂的非线性关系,尤其适合处理气象数据的多维性和动态变化。
2.2 LSTM
长短期记忆网络(LSTM)是一种特殊类型的递归神经网络(RNN),针对传统RNN在处理长序列数据时的不足而设计,尤其是梯度消失和梯度爆炸的问题。LSTM通过引入记忆单元和门控机制,能够有效地捕捉时间序列中的长期依赖性,这对于天气数据预测尤为重要。LSTM的结构包含三个主要的门控机制:输入门、遗忘门和输出门。输入门控制哪些信息将被存储到记忆单元中,遗忘门决定哪些信息需要被丢弃,而输出门则决定当前记忆单元的输出。通过这些门控机制,LSTM能够选择性地记住和忘记信息,从而在处理复杂的时间序列数据时具备更强的灵活性和适应性。
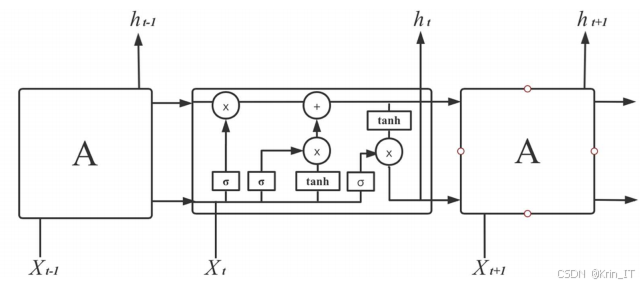
在天气数据预测中,LSTM尤其适合建模气象要素(如温度、湿度、降水量等)随时间变化的动态特性。通过设计多层LSTM网络,可以提取出更高层次的特征,提升模型的预测准确性。LSTM在处理具有周期性和季节性的数据时,能够有效捕捉到这些数据中的长期趋势和短期波动,适应动态变化的气象环境。结合LSTM和随机森林的优势,可以在天气预测中实现更高的精度和更强的鲁棒性。随机森林擅长处理非线性关系和特征交互,而LSTM则能够捕捉时间序列的动态特性。两者的结合使得模型不仅能够针对当前天气条件进行预测,还能利用历史数据中的模式,为未来的天气变化提供更全面的分析和预测。
三、检测的实现
3.1 数据集
数据来源包括气象局发布的历史天气数据、在线天气API或通过爬虫技术获取的天气信息。数据应包含温度、湿度、降水量、风速、气压等气象要素,确保数据的全面性和准确性。数据收集后,进行数据清洗。清洗步骤包括处理缺失值和异常值,确保数据完整。清洗后的数据应符合分析和建模的要求。特征工程是数据集制作的重要环节。提取时间相关特征为模型提供额外的信息。结合历史天气数据,创建滞后特征,例如过去几天的气温和湿度,整合处理后的数据,保存为CSV格式或数据库格式,以便后续模型训练和测试使用。
3.2 实验环境搭建

3.3 实验及结果分析
选择合适的模型是成功预测的关键。针对天气数据预测任务,可以选择随机森林、LSTM等多种模型。这些模型各有优缺点,适用于不同的数据特性和预测需求。在开始训练之前,需要将数据集划分为训练集和测试集,这样能够在训练过程中有效评估模型的性能。训练集用于模型学习,而测试集则用于验证模型的泛化能力,确保模型能够在未见过的数据上表现良好。
from sklearn.preprocessing import MinMaxScaler
import numpy as np
# 数据归一化
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X_train)
# 构建时间序列数据
def create_dataset(data, time_step=1):
X, y = [], []
for i in range(len(data) - time_step):
X.append(data[i:(i + time_step)])
y.append(data[i + time_step, 0]) # 预测目标为第一个特征
return np.array(X), np.array(y)
time_step = 10
X_train_seq, y_train_seq = create_dataset(X_scaled, time_step)
X_train_seq = X_train_seq.reshape(X_train_seq.shape[0], X_train_seq.shape[1], X_train_seq.shape[2])
对于传统的机器学习模型,如随机森林,特征数据通常需要进行标准化或归一化,以提升模型的训练效率。标准化将特征数据转换为均值为0、方差为1的分布,而归一化则将特征缩放到[0, 1]的区间。通过这些处理,可以避免某些特征对模型训练产生过大的影响,从而提高模型的收敛速度和稳定性。对于深度学习模型,如LSTM,数据需要调整为适合输入的形状。LSTM模型要求输入数据具有特定的维度,通常为三维数组,形状为(样本数,时间步长,特征数)。在构建时间序列数据时,需使用滑动窗口方法,创建输入特征与目标输出的对应关系。
from sklearn.ensemble import RandomForestRegressor
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout
# 随机森林模型构建与训练
rf_model = RandomForestRegressor(n_estimators=100, max_depth=10, random_state=42)
rf_model.fit(X_train, y_train)
# LSTM模型构建
lstm_model = Sequential()
lstm_model.add(LSTM(50, return_sequences=True, input_shape=(X_train_seq.shape[1], X_train_seq.shape[2])))
lstm_model.add(Dropout(0.2))
lstm_model.add(LSTM(50, return_sequences=False))
lstm_model.add(Dropout(0.2))
lstm_model.add(Dense(1)) # 输出层
# 编译模型
lstm_model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
lstm_model.fit(X_train_seq, y_train_seq, epochs=100, batch_size=32, validation_split=0.1)在训练阶段,使用训练集对模型进行拟合。监控训练过程中的损失值和相关评估指标,在每个epoch结束时评估模型在验证集上的表现,以防止过拟合。通过早停法,可以在验证集损失不再改善时停止训练,从而节省计算资源。
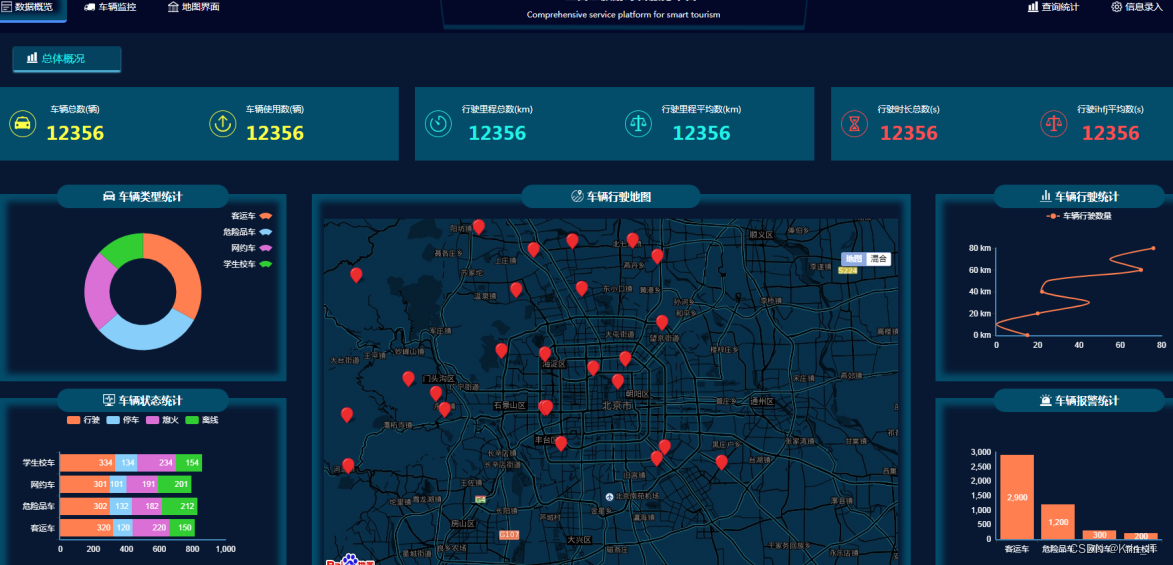
实现效果图样例:



创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









