










目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
设计思路
一、课题背景与意义
烟叶成熟度的准确判定和适时采收是提高烟叶质量的关键。传统的鉴别成熟度的方法较为笼统,稳定性低,在田间采收的实际操作中很难准确使用,大多只能停留在理论层次上。因此,生产上迫切需要制定出一系列合理、便捷、客观的量化标准,以便探究一套科学、方便和直观的烟叶成熟度鉴别方法。
二、算法理论原理
2.1 YOLOv5
YOLOv5的网络结构由4大部分组成:输入端、Backbone、Neck、Head。输入端包括Mosaic数据增强、图像尺寸处理和自适应锚框算法。Backbone包含Focus模块,该模块将本模型设定的原始图片大小[3,640,640]进行切片操作,然后通过concat操作连接,通过变换为[12,320,320]的图片进行卷积,将8、16、32倍下采样的特征图作为检测目标的特征层,提升了检测速度。Neck层融合了提取到的语义和位置特征,主干层与检测层特征,丰富了模型的特征信息。Head输出检测对象的类别概率、得分情况和边界框位置信息向量。
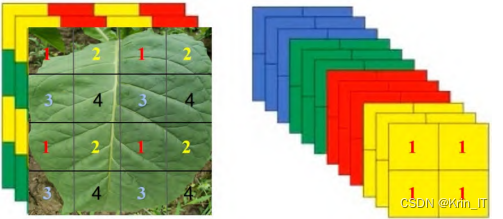
2.2 损失函数
损失函数常被用作机器学习的参数估计。本实验模型包含框损失(lbox)、对象损失(lobj)和分类损失(lcls)。其中,框损失表示算法定位中心对象的程度以及预测的边界框覆盖对象的程度。对象性损失本质上是对象存在于建议的区域中概率的度量,若经计算后得到的概率较高,图像窗口则可能包含一个对象。分类损失是给出算法预测给定对象的正确类别的能力。
目标框位置误差使用 的是GIoU损失函数:
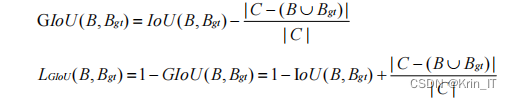
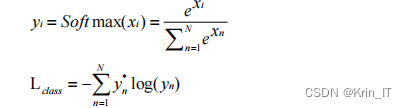
相关代码:
predictions = np.array([[0.2, 0.3, 0.5]])
# 使用Softmax函数进行概率分布转换
probabilities = np.exp(predictions) / np.sum(np.exp(predictions), axis=1, keepdims=True)
# 输出概率分布
print(probabilities)三、检测的实现
3.1 数据集
数据集为学长自己采集,用手机拍摄烟叶的上部叶、中部叶和下部叶为研究对象进行数据采集。采集时间为期30天,包含阴、晴、雨等不同的天气环境背景下的图片数据。拍摄数据在顺光、侧光、逆光等自然条件下进行多角度拍摄,真实还原大田作业下叶片采摘的环境条件。

为排除大田拍摄图像中无效的背景干扰信息,如人员活动、多余叶片等,本研究使用labelimg图像注释软件对数据集进行人工标记,以记录叶片边缘坐标,排除环境信息干扰。随后将预处理过符合要求的图片转成.jpg格式,用.txt文件格式存储相应图片标注信息。在训练开始前对数据进行预处理,使用中值滤波对原始图片进行降噪处理,滤除脉冲噪声的同时保持图像的边缘特性。此外,通过水平翻转、平移缩放旋转,调整原始图像的灰度和亮度等对数据集进行扩充。
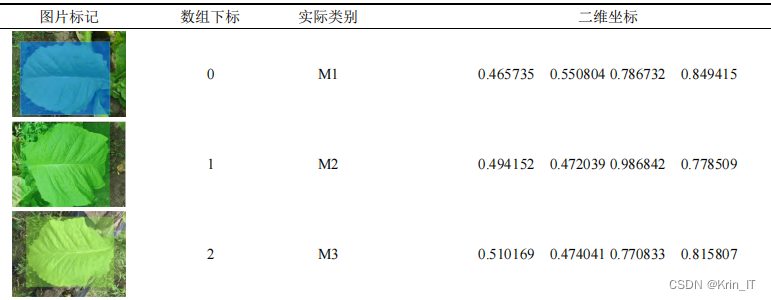
3.2 实验环境搭建
3.3 实验及结果分析
利用YOLOv5模型对CB-1上、中、下3个部位的5档成熟度共3000张训练集数据进行训练,利用450张验证集数据进行训练和验证。对模型训练参数进行优化,图片设置为640×640,batch值为16,初始学习率lr0=0.01,周期学习率lrf=0.2,轮数设置为500轮。在早停机制的作用下,CB-1中部叶模型在449轮自动停止。输出结果由原图和预测框两部分组成。在该参数下,预测框可以准确地覆盖到叶缘部位,并给出较高的预测置信度(1为最高,0为最低)。

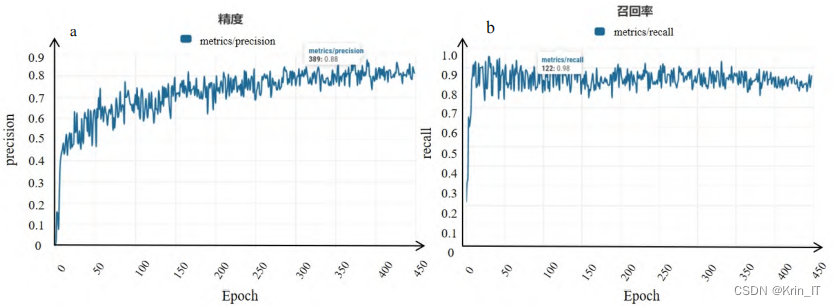
中部叶模型的精度在1~19轮的时候迅速上升,到390轮的时候达到峰值0.88,而召回率则在训练前期就有较好的表现,在123轮的时候达到最高值,为0.98。计算得CB-1上部叶的F1得分为0.89,中部叶的F1得分为0.87,下部叶的F1得分为0.97。
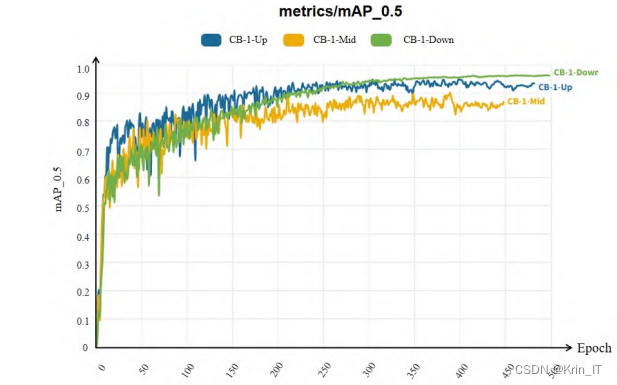
在训练过程中,选取IoU值为0.5的mAP值进行分析。3个部位的mAP值均可达到0.9以上。其中,CB-1中部叶模型mAP在第390轮达到最高值0.90185,上部叶模型的mAP在305轮达到最大值0.94829,下部叶模型mAP在493轮达到最大值0.96309。
相关代码如下:
model = tf.keras.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(5, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 准备数据集并进行预处理
# 这里假设有一个名为"dataset"的数据集,包含成熟度标签和对应的图像数据
# 划分训练集和验证集
train_dataset = dataset[:2500]
valid_dataset = dataset[2500:]
# 定义训练参数
batch_size = 16
epochs = 10
# 进行模型训练
model.fit(train_dataset, epochs=epochs, validation_data=valid_dataset)
# 完成模型训练后,可以使用该模型对新的烟叶图像进行成熟度识别
# 这里假设有一个名为"test_image"的图像需要进行成熟度识别
result = model.predict(test_image)
# 输出识别结果
print(result)创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









