






前言
经过一段时间的网页学习,设计了一个简单的书籍分析系统,记录一下学习体会,具体成果大致如下:

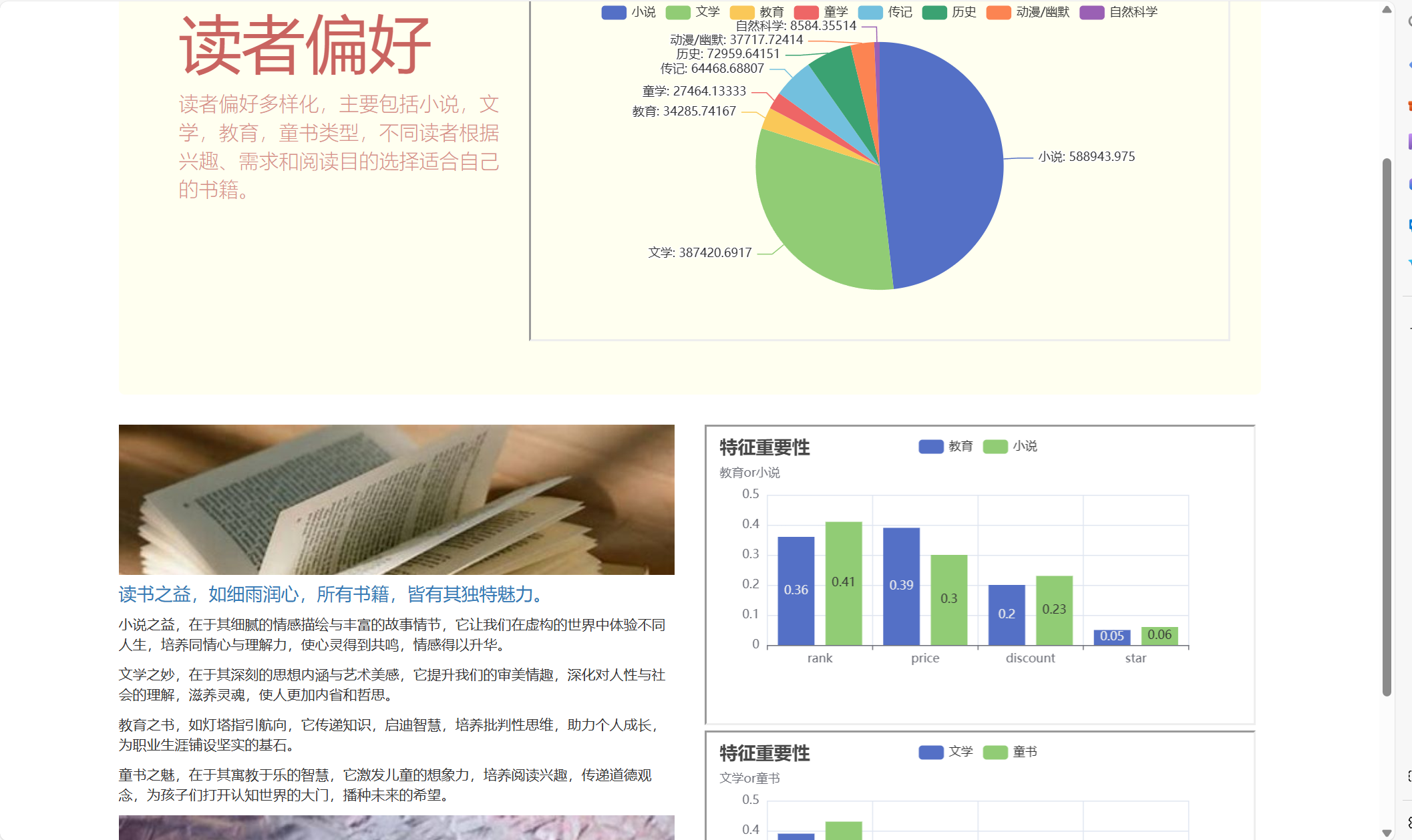
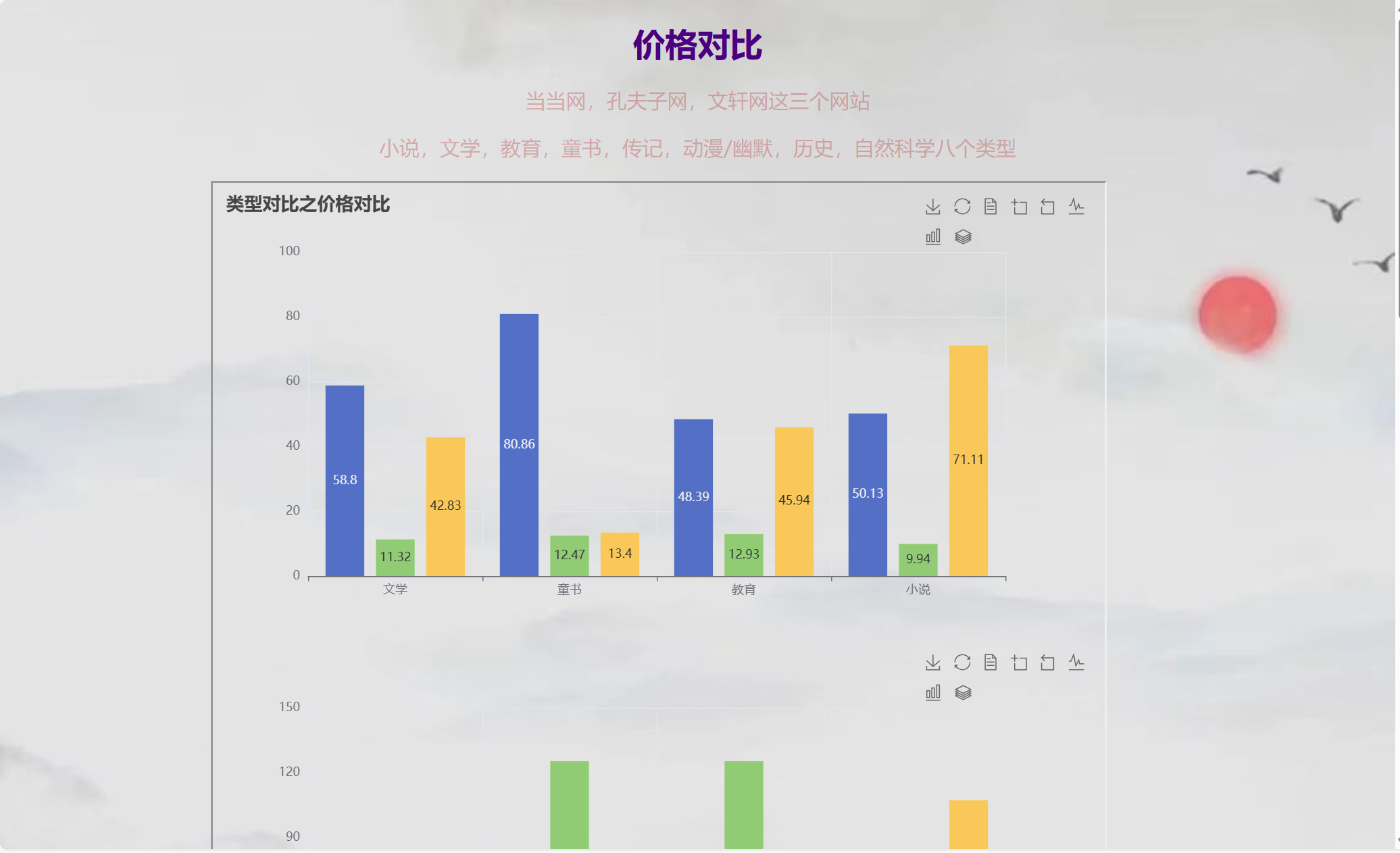
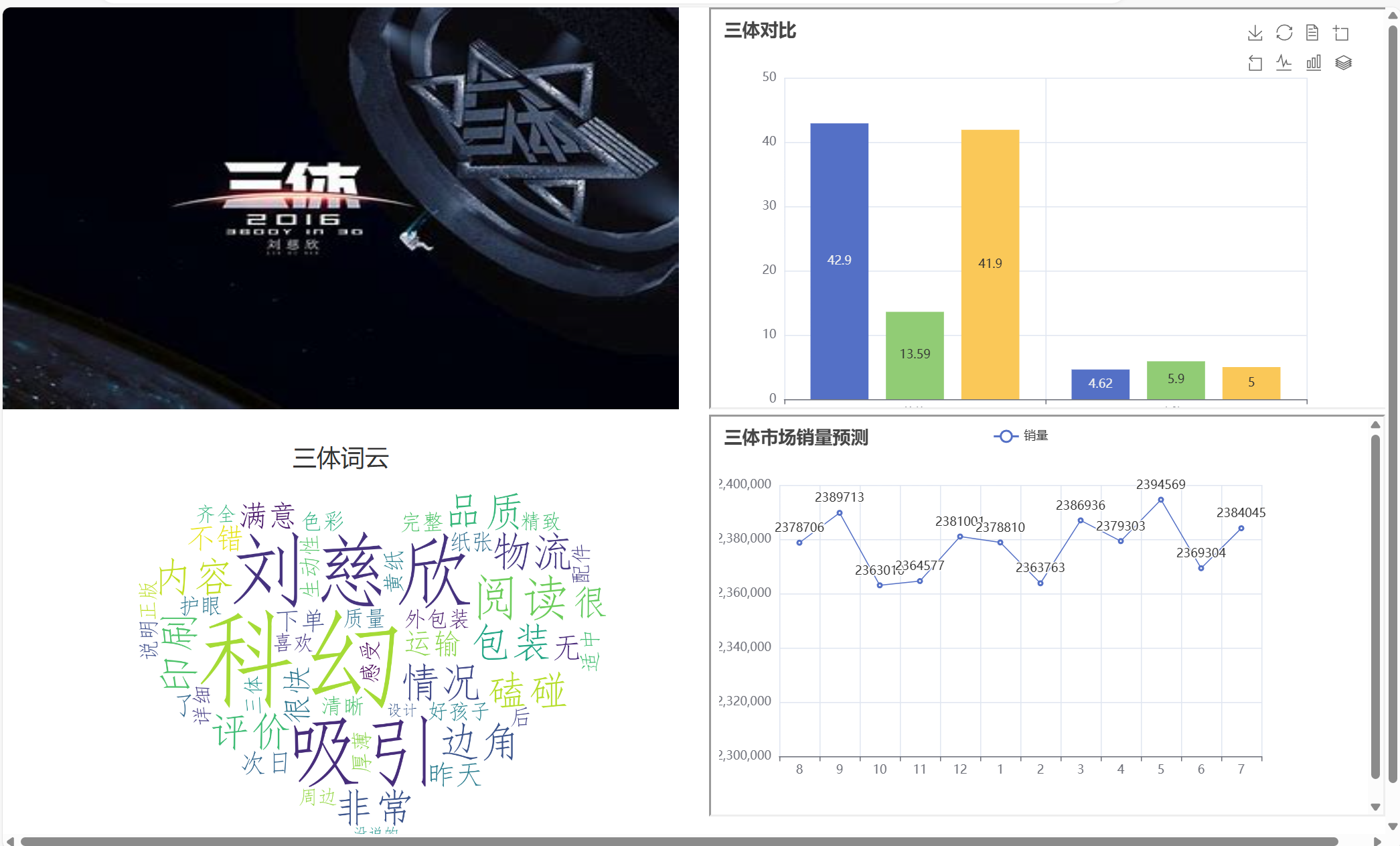
pyecharts
首先来说说网页中的那些图片,属于动态html图片,可以点击,主要是由pyecharts生成的(评价:好用),基本上去pyecharts官网上复制代码然后修改就可以得到html,里面还提供了每个代码的最终效果,修改难度也很低。
pywebio
这个库是我第一版时用的,对于html小白来说,比较友好,里面提供了一些函数,可以直接通过python生成出html,缺点是不能自己控制位置,提供的功能有限,做出来效果肯定比不上用html做。想要学习的话,建议直接看pywebio官网学习就好了,网上零零散散的教程基本上也只是官网上的一部分。
爬虫
关于数据来源这一部分,是最开始最头疼的,但是解决之后也还是比较容易的。python的爬虫代码比较简单,虽然有时候会出现一些奇奇怪怪的情况,这部分我也有一些没学会的地方,例如有些网站需要登录和爬取动态页面的问题。
from lxml import etree
import requests
import pandas as pd
import numpy as np
from concurrent.futures import ProcessPoolExecutor
def get_data(url):
resp = requests.get(
url=url,
headers={
)#填自己电脑的
tree = etree.HTML(resp.text)
datas = tree.xpath('//div[@class="con shoplist"]/div/ul//li')
num = 0
result = np.zeros((61, 9), dtype=object)
for data in datas:
book_name = data.xpath('a/@title')
price = data.xpath('p[@class="price"]/span[1]/text()')
author = data.xpath('p[@class="search_book_author"]/span[1]/a[1]/@title')
publish = data.xpath('p[@class="search_book_author"]/span[3]/a/text()')
discount = data.xpath('p[@class="price"]/span[3]/text()')
star = data.xpath('p[@class="search_star_line"]/span/span/@style')
comment = data.xpath('p[@class="search_star_line"]/a/text()')
num += 1
result[0][0] = 'rank'
result[0][1] = 'name'
result[0][2] = 'price'
result[0][3] = 'author'
result[0][4] = 'publish'
result[0][5] = 'discount'
result[0][6] = 'star'
result[0][7] = 'comment'
result[num][0] = num
for i in book_name:
result[num][1] = i
for j in price:
result[num][2] = j
for a in author:
result[num][3] = a
for p in publish:
result[num][4] = p
for d in discount:
result[num][5] = d
for s in star:
result[num][6] = s
for c in comment:
result[num][7] = c
result = pd.DataFrame(result)
result.to_csv("data/当当销量榜_童书_7_11_5.csv")
print(result)
if __name__ == '__main__':
urls=['https://search.dangdang.com/?key=%CA%E9%BC%AE&category_path=01.41.00.00.00.00&sort_type=sort_sale_amt_desc#J_tab']
max_processes=10
print(urls[0])
with ProcessPoolExecutor(max_processes) as executor:
executor.map(get_data,urls)
print('程序结束')
代码如上,可以看到代码中在用lxm,requests爬取数据的同时,也用了ProcessPoolExecutor线程池去提高爬取速度(新学),以及pandas和numpy进行数据处理将数据存储在csv中。
具体写法介绍
爬虫首先需要urls(你需要爬取的网页地址),以及header(自己的电脑爬虫,也可以是百度爬虫,F12检查网页点击网络然后按刷新,随便点击一个交流,往下翻到最后就可以找到),得到resp之后用etree进行解析得到网页的html文件,后面就是xpath解析了,这部分我研究了一下,实际上很好学,里面有一些规律。当然也可以直接复制,这里我就不多介绍了,感觉言语说不清。最后解析出来的数据放入csv中。
数据清洗
这部分因人而异,不同事情,处理的代码也不同,主要就是那些缺失值的处理啥的,爬虫有时候会出现空的情况,一部分是网页本身没有,一部分是莫名原因(还没研究明白),所以最后要检查一下数据质量。
前端
开始的pywebio做出来的效果并不理想,所以后面还是决定学习html,一个比较好用的前端框架–bootstrap(bootstrap官网),现在更新到v5了,但是由于最开始很小白,只在b站上看见一个非常快速的入门教程,里面教的是v3,所以我用的是v3。最最开始啥也不懂,主打一个堆砌,就拿那些框架堆自己想要的功能,只要修改里面的内容就可以了。
入门
入门的话,看组件这一部分就差不多了,复制粘贴!
进阶
进阶一点,看全局CSS中的一些东西,尤其是上面这部分,控制位置排版的(学习)。这部分需要一点点对html的理解,要不然无脑搬不上去。
好用的html结构
style设置类型,可以写在head里面(就比较多的话),类似这样的,将container写在class里面就可以了。或者在class的后面写style。
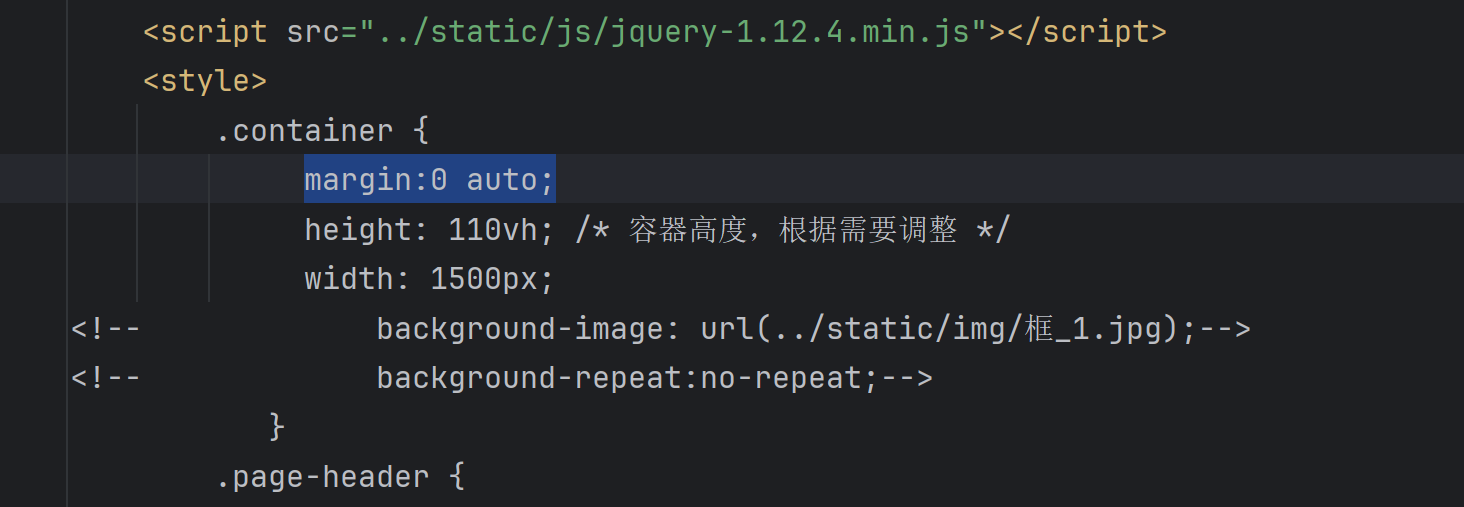
background-image设置背景图片,可以写在class后面,也可以写body后面,那样的话就设置成整个的背景了。
flask后端
简单前端的问题就是经常会重复代码!!不仅自己写的很累,而且看起来html也很多,所以这个时候就需要后端来拯救一下了,只需要将数据放入csv或者数据库中,然后框框读取数据,将数据传给前端显示,就可以节约很多代码量。
后端代码分析
import pandas as pd
from flask import Flask, render_template, redirect, url_for, request
app = Flask(__name__)
@app.route('/')
def redirect_index():
return redirect(url_for('home'))
@app.route('/home')
def home():
return render_template('main.html')
@app.route('/school')
def school():
return render_template('Market compasion.html')
@app.route('/index')
def index():
page = 1
website = 0
types = '总排行'
if request.args.get('page') is not None:
page = int(request.args.get('page'))
print("page:", page)
if request.args.get('website') is not None:
website = int(request.args.get('website'))
print("webiste:", website)
if request.args.get('types') is not None:
types = request.args.get('types')
print("types:", types)
data = pd.read_csv('./data/查询.csv', encoding='ANSI')
headers = data.values[0]
values = data.values[1:].tolist()
# print(values)
web_url = [["当当网", "https://www.dangdang.com/", ],
["文轩网", "https://www.xhsd.com/", ],
["孔夫子网", "https://www.kongfz.com/"]]
list_2 = []
for value in values:
if value[9] == web_url[website][0]:
if value[8] == types:
list_2.append(value[2:])
# print(list)
list_2 = list_2[((page - 1) * 10):(page * 10)]
print(len(list_2))
return render_template('sales_ranking_list.html', web_url=web_url, data=list_2)
if __name__ == '__main__':
app.run(port=8080, debug=True, host='0.0.0.0')
数据通过app路由传输,route是提供一个网址,每个html里面的数据可以通过render_templates传入,注意这里所有的html文件都要写在一个叫templates的文件夹下,如果你需要在这个网页上显示信息,那么就在对应的函数里面写入数据读取和数据处理,将最后处理完的数据用参数传递进去。那么在html前端里面就可以通过{{data}}访问到数据内容,如下:
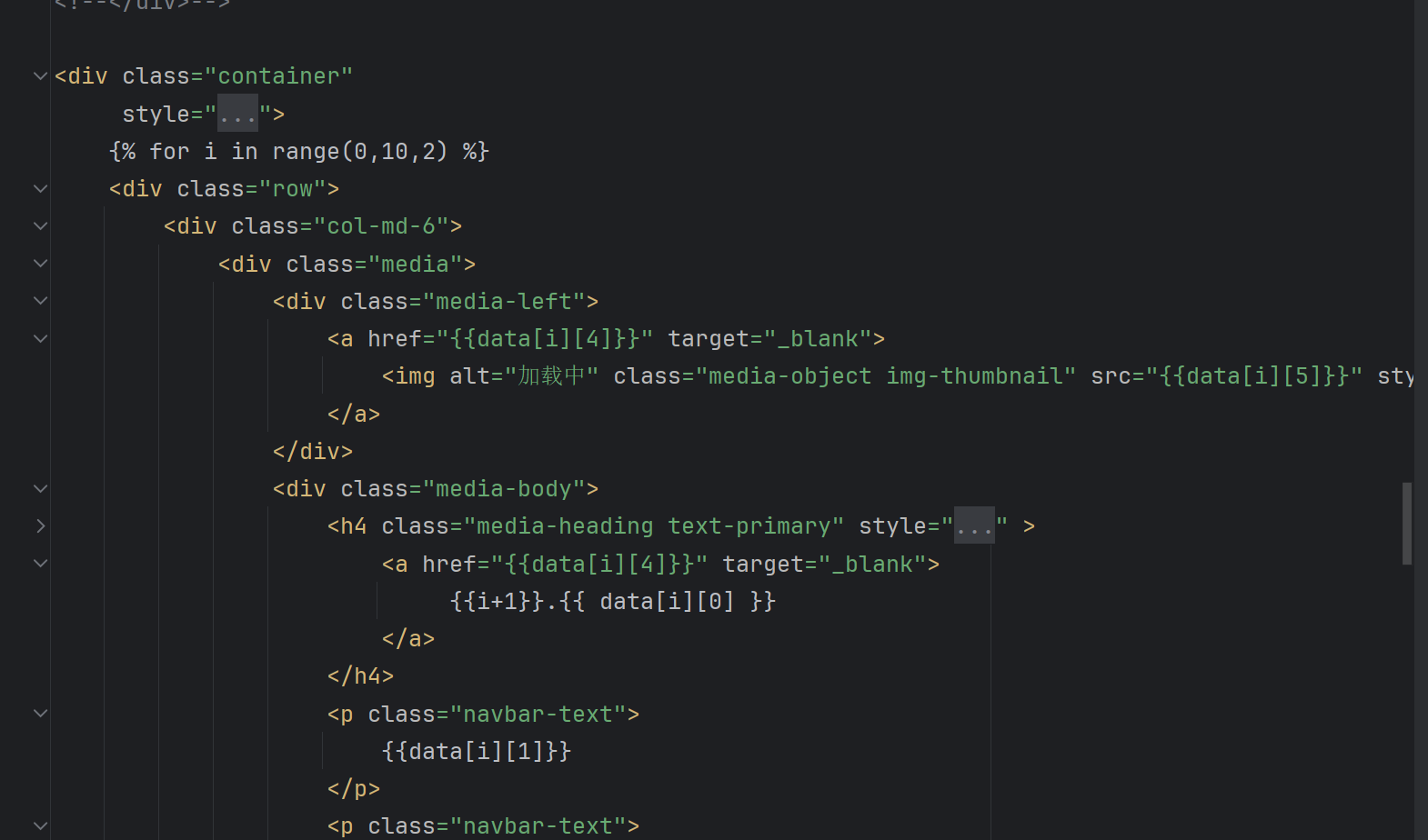
而如果你需要将html前端在用户那里得到的信息传回给后端,那么可以通过url_for,传输对应消息,在后端也要通过request.args.get获取到信息。
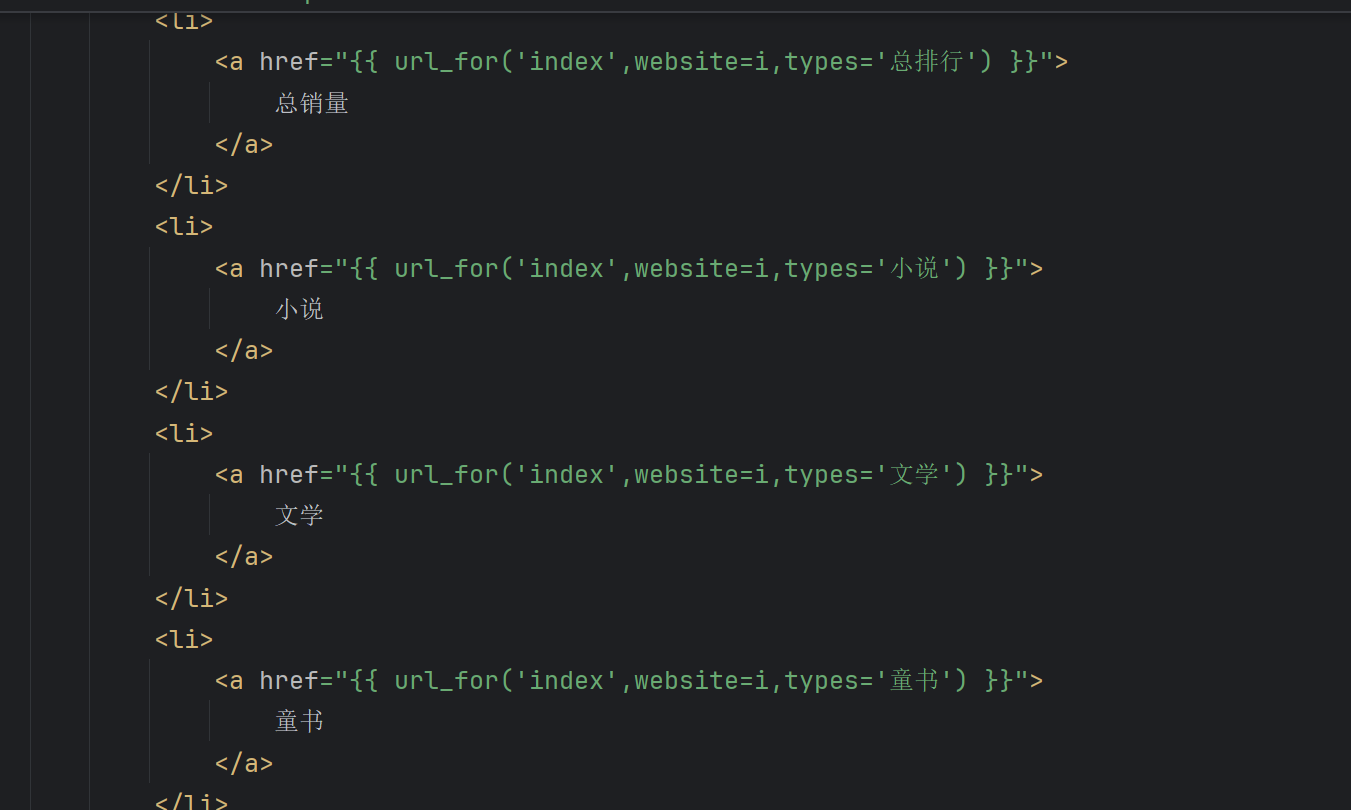
html的for,if
比较让我意外的是,html里面也可以写for,if语句使用方法如下:
{%for i in range(3) %}
{% endfor %}
{% if page<4 %}
<a href="{{url_for('index',page=page+1)}}" aria-label="Next">
<span aria-hidden="true">»</span>
</a>
{% else %}
<a aria-label="Next">
<span aria-hidden="true">»</span>
</a>
{% endif %}
总结
通过这个项目还是学到了很多东西的,其中也遇到了很多帮助我的人,一段快乐的回忆,希望明天的答辩也能快乐吧!!大一的课程要告一段落了。

















 2447
2447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









