







闲言
写这篇博客的原因是最近在做的项目由于给视频标注太过费时,所以选择了用模型进行预标注再去人工调整的方法。在这个过程中遇到了一点点小小的困难,首先是标注软件的选择,非常多的选择,最后是选择了网页版的via,主要是因为不需要下载。其次是模型训练好的数据标签怎么导入via中,在网上查找只有一篇rcnn_fast和via的结合,重点也不是导入代码,gpt写的代码就看着好像一样,但是用不了,最终无奈,只能自己研究了一下。
csv文件
代码
先不讲过程,先上代码,但是还是需要自己根据需要进行一定修改。(我只写了关键点的csv文件代码,如果想导入其他标签的,可以参考一下我后面写代码的思路和过程,自己去写)
# 打开 CSV 文件进行写入
csv_filename = os.path.join(output_path, f"{video_id}.csv")
# 创建csv
csvFile = open(csv_filename, "w+", encoding="gbk")
# 创建写的对象
CSVwriter = csv.writer(csvFile)
# 先写入columns_name
# 写入列的名称
CSVwriter.writerow(
["filename", "file_size", "file_attributes", "region_count", "region_id", "region_shape_attributes",
"region_attributes"])
这部分需要修改output_path,写成你要导出了路径, f"{video_id}.csv"写成你要导出的csv文件名。
ImgSize = os.path.getsize(frame_filename)
num=0
# 将坐标转成 CSV 中的格式
region_shape_attributes = {
"name":"point",
"cx":all_points_x,
"cy":all_points_y
}
# 写入 CSV 文件,遵循给定的格式
csv_writer.writerow([
f"{video_id}_{frame_count:04d}.png", # filename
ImgSize, # file_size
"{}", # file_attributes
58, # region_count
num, # region_id
str(region_shape_attributes).replace("'", '"'), # region_shape_attributes (JSON 格式)
"{}" # region_attributes
])
num+=1
这部分的需要提供all_points_x和all_points_y(从模型拿到的),f"{video_id}_{frame_count:04d}.png"改成文件名,ImgSize是图片字节大小(frame_filename是图片路径),58改成总关键点数量,num是你这一个关键点是第几个。
via导入
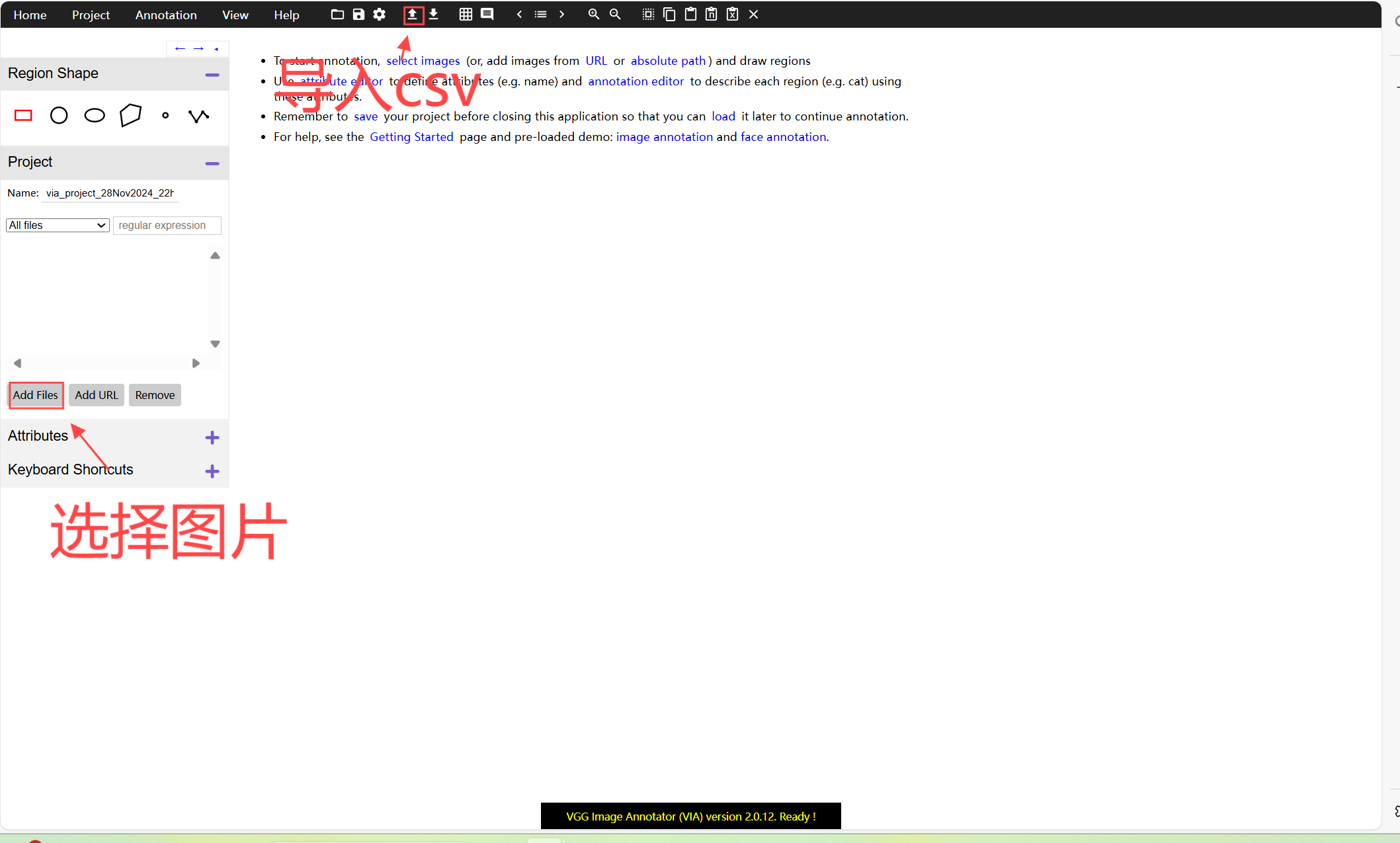
via修改
在导入csv之后,会在图片上显示模型标注的关键点,可以通过拖拽改变点的位置。
via导出
导入的旁边是导出,在修改完成之后直接点击,下载新生成的csv文件就可以。
过程
写这个代码的最大的一个问题是via兼容的csv文件到底长什么样??所以第一步,我去via上随便上传一张图然后进行画点,导出了csv文件。
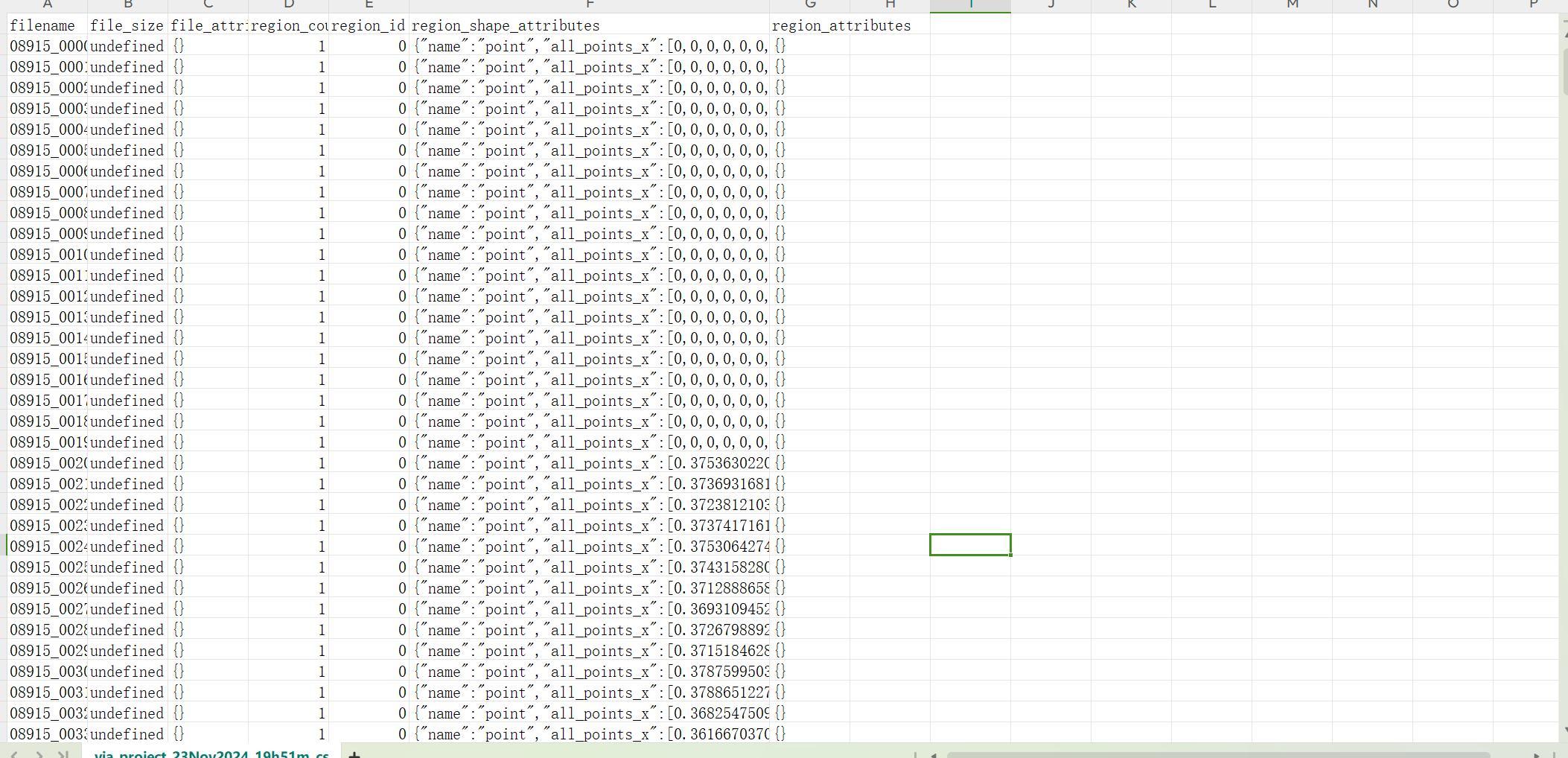
看到这张图,痛苦面具,奇怪的矩形,不是很理解,这里困了我好久,然后我就往下翻。
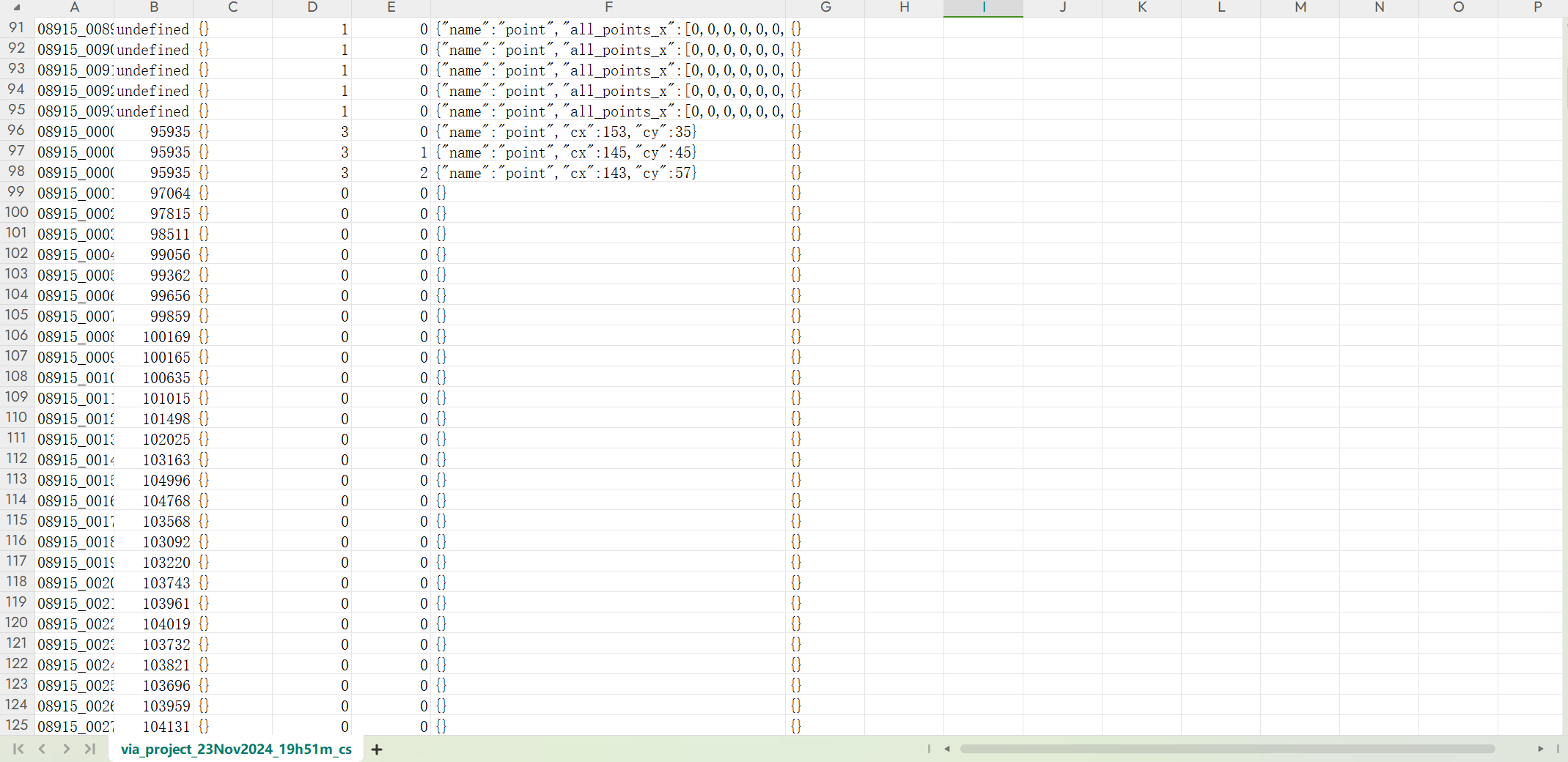
猛然发现后面出现了cx,cy,xy坐标!再看一眼三行,我记得我刚刚打了三个点!文件名也正确,那么上面的行是什么呢?有没有用呢?所以我就尝试把上面行全部删除之后再导入via中,结果是没有影响的。
可以得出结论,上面的是没用的。那么就再来看看这三行,第一列图片名,第二列有点奇怪gpt一下,第三列都是{}照搬,第四列3?3行!关键点总数,第五列0,1,2,每次加一,第几个标签,第六个name是point照搬,就只有cx,cy记录位置,第七个还是{}照搬。这样csv生成代码就出现了。
总结
我提供的代码大抵是不能直接复制粘贴直接使用的,我还是个入门1年的人,做不到大佬的封装(我也没有时间封装),而且这个东西也需要根据自己的需求改变。希望能对你有帮助,有误可以指出。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









