






 本文介绍了机器学习中的线性回归模型,包括其简单性、可解释性和预测能力的优点,以及线性假设、对异常值敏感和多重共线性的局限性。同时提供了使用PythonSklearn库实现线性回归模型的代码示例,展示了如何处理这些问题并评估模型性能。
本文介绍了机器学习中的线性回归模型,包括其简单性、可解释性和预测能力的优点,以及线性假设、对异常值敏感和多重共线性的局限性。同时提供了使用PythonSklearn库实现线性回归模型的代码示例,展示了如何处理这些问题并评估模型性能。
机器学习中的线性回归模型是一种统计学上的预测分析,用于估计两个或多个变量之间的关系。在线性回归中,目标是拟合一个最佳的直线(或在多维空间中的超平面)来描述自变量(特征)和因变量(目标)之间的关系。这种关系通过一个线性方程来表示,该方程描述了自变量与因变量之间的依赖关系。
线性回归模型的主要优点:
- 简单性:模型易于理解和实现,计算成本相对较低。
- 可解释性:回归系数提供了自变量对因变量影响的直接度量,有助于理解变量之间的关系。
- 预测能力:在许多情况下,线性回归模型能够提供良好的预测性能。
线性回归模型的局限性:
- 线性假设:模型假设自变量和因变量之间存在线性关系,这可能不适用于某些复杂的数据集。
- 对异常值敏感:最小二乘法对异常值(离群点)非常敏感,这可能导致回归系数的估计不准确。
- 多重共线性:当自变量之间存在高度相关性时,模型的稳定性可能会受到影响,导致回归系数的估计不准确。
为了克服这些局限性,可以使用改进的线性回归模型,如岭回归(Ridge Regression)、套索回归(Lasso Regression)和弹性网络(Elastic Net)等。这些模型通过引入正则化项来处理多重共线性和过拟合问题,从而提高模型的稳定性和预测性能。
代码参考
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 读取数据
data = pd.read_csv('data.csv')
# 删除空值数据
data = data.dropna(subset=['b_p', 'gender','等等'])
# 提取特征变量和目标变量
# 提取特征和目标变量
X = data[['b_p', 'gender','等等']] # 特征变量
y = data['要预测的列'] # 目标变量
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建并训练模型
model = LinearRegression()
model.fit(X_train, y_train)
# 使用模型进行预测
y_pred = model.predict(X_test)
# 计算预测的准确性
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# 打印评估结果
print(f'平均绝对误差 (MAE): {mae:.3f}')
print(f"R-squared: {r2:.3f}")
print(f"均方误差 (MSE): {mse:.3f}")
max_error = np.max(np.abs(y_test - y_pred))
print(f"最大误差: {max_error:.3f}")
min_error = np.min(np.abs(y_test - y_pred))
print(f"最小误差: {min_error:.3f}")
rmse = np.sqrt(mse)
print(f"均方根误差 (RMSE): {rmse:.3f}")
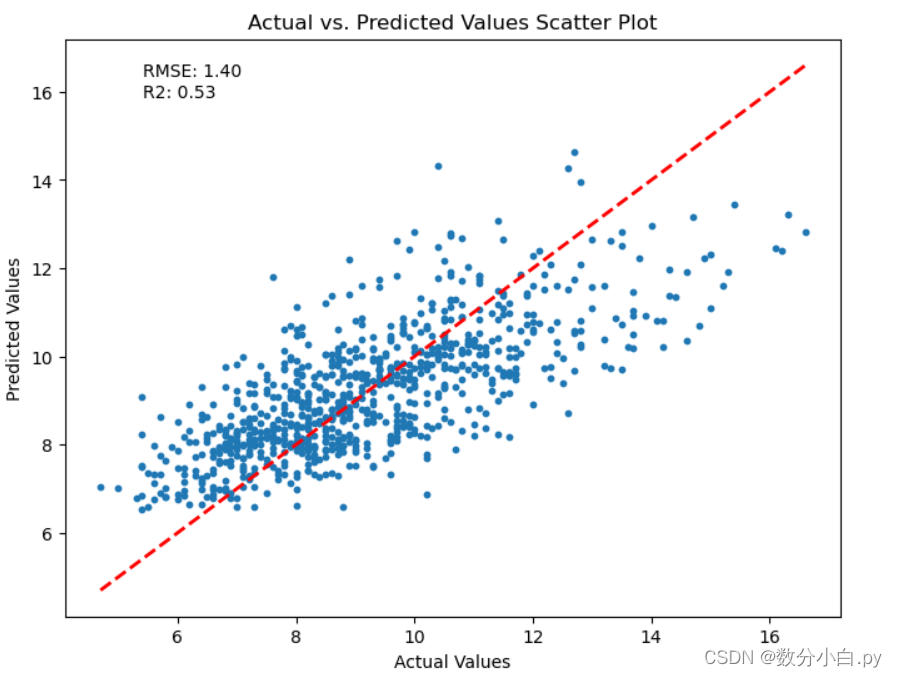
# 绘制预测值和实际值的散点图
reference_line_color = 'red' # 或者你想要的其他颜色
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, s=10) # 使用统一的颜色plot_color
plt.xlabel('Actual Values')
plt.ylabel('Predicted Values')
plt.title('Actual vs. Predicted Values Scatter Plot')
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], color=reference_line_color, linestyle='--', linewidth=2) # 使用统一的颜色reference_line_color
plt.text(0.1, 0.9, f'RMSE: {rmse:.2f}\nR2: {r2:.2f}', transform=plt.gca().transAxes, color='black') # 修改这里,将颜色设置为黑色
# 设置保存图形的路径和文件名
save_path = r"C:\要保存的路径\LR散点图.png"
# 保存图形到文件
plt.savefig(save_path, bbox_inches='tight', dpi=300)
# 显示图形(如果还需要在屏幕上显示的话)
plt.show()
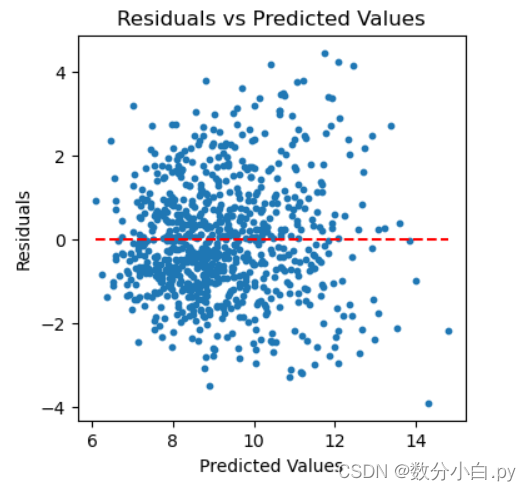
# 绘制残差图
residuals = y_test - y_pred
plt.figure(figsize=(4, 4))
plt.scatter(y_pred, residuals, s=10) # 使用统一的颜色plot_color
plt.hlines(y=0, xmin=y_pred.min(), xmax=y_pred.max(), colors=reference_line_color, linestyles='--') # 使用统一的颜色reference_line_color
plt.xlabel('Predicted Values')
plt.ylabel('Residuals')
plt.title('Residuals vs Predicted Values')
# 设置保存图形的路径和文件名
save_path = r"C:\要保存的路径\LR残差图 .png"
# 保存图形到文件
plt.savefig(save_path, bbox_inches='tight', dpi=300)
# 显示图形(如果还需要在屏幕上显示的话)
plt.show()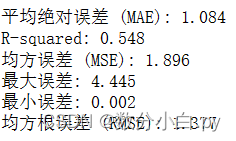



















 915
915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









