






 文章讲述了如何预处理非数值型数据,将特征转换为数值并处理缺失值,然后使用随机森林模型进行心脏病相关肥胖风险预测。通过GridSearchCV进行超参数优化,并展示了其他机器学习模型如逻辑回归、梯度提升树、K近邻和SVM的性能对比。
文章讲述了如何预处理非数值型数据,将特征转换为数值并处理缺失值,然后使用随机森林模型进行心脏病相关肥胖风险预测。通过GridSearchCV进行超参数优化,并展示了其他机器学习模型如逻辑回归、梯度提升树、K近邻和SVM的性能对比。
 本次比赛的目标是利用各种因素来预测与心血管疾病相关的个体肥胖风险。
本次比赛的目标是利用各种因素来预测与心血管疾病相关的个体肥胖风险。
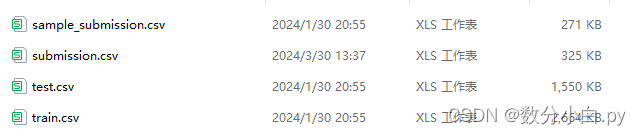
给了三个csv文件,train.csv用来训练模型,test用来测试结果,sample_submission.csv是给的提交的示例。submission.csv是自己创建的,用来保存模型测试结果产生并要提交的结果。
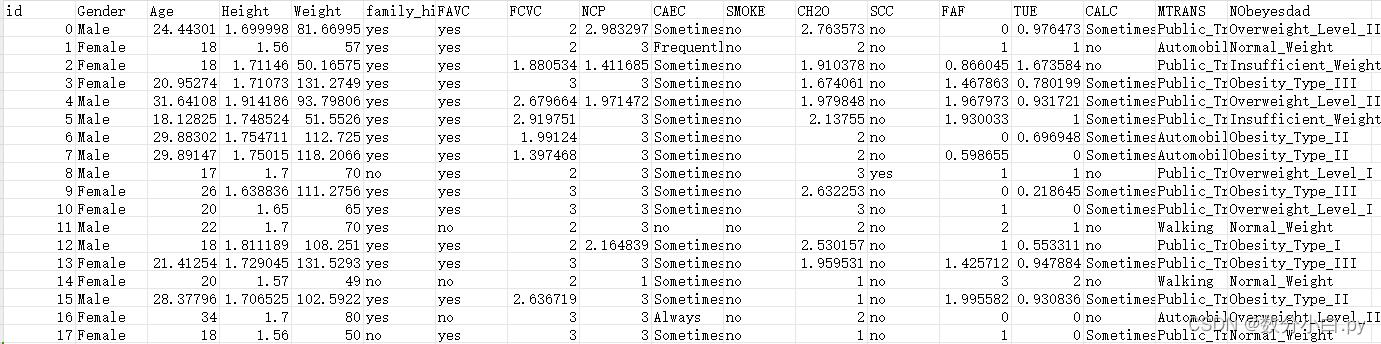
这个是train.csv里的各个特征,大概看了一下很多列不是数值型的所以第一步就是要把这些非数值类型的数据转换为数值类型的。
data['Gender'] = data['Gender'].map({'Male': 1, 'Female': 0})
data['family_history_with_overweight'] = data['family_history_with_overweight'].map({'yes': 1, 'no': 0})
data['FAVC'] = data['FAVC'].map({'yes': 1, 'no': 0})
data['CAEC'] = data['CAEC'].map({'Always': 0.8, 'no': 0, 'Frequently': 0.6, 'Sometimes': 0.3})
data['SMOKE'] = data['SMOKE'].map({'yes': 1, 'no': 0})
data['SCC'] = data['SCC'].map({'yes': 1, 'no': 0})
data['CALC'] = data['CALC'].map({'Always': 0.8, 'no': 0, 'Frequently': 0.6, 'Sometimes': 0.3})
data['MTRANS'] = data['MTRANS'].map({'Public_Transportation':0.6, 'no': 0, 'Automobile': 0.3, 'Walking': 0.8}) 利用map处理非数值列,这里有几列含有Always Frequently Sometimes 处理的时候我根据英语里的语气程度分别赋值了 0.8 0.6 0.3.
随后就是处理空值了,最简单的把所有空值行删掉
# 确保没有空值
columns_to_check = [
'Gender', 'Age', 'Height', 'Weight', 'family_history_with_overweight',
'SCC', 'FCVC', 'NCP', 'CAEC', 'SMOKE', 'CH2O', 'FAF', 'TUE', 'CALC', 'NObeyesdad'
]
# 删除包含空值的行
data = data.dropna(subset=columns_to_check) 接下来就是套模型了,这里我用了随机森林模型,使用 GridSearchCV 进行超参数优化。
模型训练代码
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc
import numpy as np
from sklearn.metrics import classification_report
from sklearn.model_selection import GridSearchCV
# 加载数据(假设数据保存在CSV文件中)
data = pd.read_csv(r"C:\Users\11794\Desktop\新建文件夹 (2)\train.csv", encoding='utf-8', encoding_errors='replace')
data['Gender'] = data['Gender'].map({'Male': 1, 'Female': 0})
data['family_history_with_overweight'] = data['family_history_with_overweight'].map({'yes': 1, 'no': 0})
data['FAVC'] = data['FAVC'].map({'yes': 1, 'no': 0})
data['CAEC'] = data['CAEC'].map({'Always': 0.8, 'no': 0, 'Frequently': 0.6, 'Sometimes': 0.3})
data['SMOKE'] = data['SMOKE'].map({'yes': 1, 'no': 0})
data['SCC'] = data['SCC'].map({'yes': 1, 'no': 0})
data['CALC'] = data['CALC'].map({'Always': 0.8, 'no': 0, 'Frequently': 0.6, 'Sometimes': 0.3})
data['MTRANS'] = data['MTRANS'].map({'Public_Transportation':0.6, 'no': 0, 'Automobile': 0.3, 'Walking': 0.8})
# 并确保没有空值
columns_to_check = [
'Gender', 'Age', 'Height', 'Weight', 'family_history_with_overweight',
'SCC', 'FCVC', 'NCP', 'CAEC', 'SMOKE', 'CH2O', 'FAF', 'TUE', 'CALC', 'NObeyesdad'
]
# 删除包含空值的行
data = data.dropna(subset=columns_to_check)
# 选择特征和目标变量
X = data[['Gender', 'Age', 'Height', 'Weight', 'family_history_with_overweight',
'SCC', 'FCVC', 'NCP', 'CAEC', 'SMOKE',
'CH2O', 'FAF', 'TUE', 'CALC']]
y = data['NObeyesdad'] # 目标变量是'NObeyesdad'列
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.01, random_state=42)
# 定义要搜索的参数网格
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20, 30],
}
# 创建随机森林分类器实例
rf = RandomForestClassifier(random_state=42)
# 创建网格搜索实例并设置verbose参数以查看进度
grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=5, scoring='accuracy', verbose=2)
# 打印消息以确认开始网格搜索
print("Starting grid search...")
# 在训练数据上执行网格搜索
grid_search.fit(X_train, y_train)
# 打印消息以确认网格搜索完成
print("Grid search completed.")
# 打印最佳参数
print("Best parameters: ", grid_search.best_params_)
# 使用最佳参数的模型进行预测和评估
best_model = grid_search.best_estimator_
y_pred = best_model.predict(X_test)
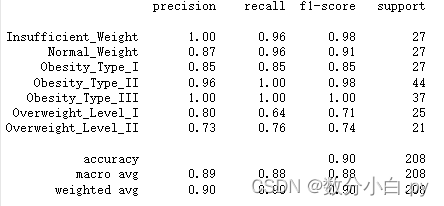
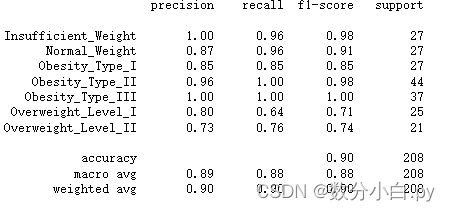
print(classification_report(y_test, y_pred))
这是在训练集上的效果,分辨肥胖的准确率达到了0.90
测试其他机器学习模型效果的代码
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc
import numpy as np
from sklearn.metrics import classification_report
# 加载数据(假设数据保存在CSV文件中)
data = pd.read_csv(r"C:\Users\11794\Desktop\新建文件夹 (2)\train.csv", encoding='utf-8', encoding_errors='replace')
data['Gender'] = data['Gender'].map({'Male': 1, 'Female': 0})
data['family_history_with_overweight'] = data['family_history_with_overweight'].map({'yes': 1, 'no': 0})
data['FAVC'] = data['FAVC'].map({'yes': 1, 'no': 0})
data['CAEC'] = data['CAEC'].map({'Always': 0.8, 'no': 0, 'Frequently': 0.6, 'Sometimes': 0.3})
data['SMOKE'] = data['SMOKE'].map({'yes': 1, 'no': 0})
data['SCC'] = data['SCC'].map({'yes': 1, 'no': 0})
data['CALC'] = data['CALC'].map({'Always': 0.8, 'no': 0, 'Frequently': 0.6, 'Sometimes': 0.3})
data['MTRANS'] = data['MTRANS'].map({'Public_Transportation':0.6, 'no': 0, 'Automobile': 0.3, 'Walking': 0.8})
# 并确保没有空值
columns_to_check = [
'Gender', 'Age', 'Height', 'Weight', 'family_history_with_overweight',
'SCC', 'FCVC', 'NCP', 'CAEC', 'SMOKE', 'CH2O', 'FAF', 'TUE', 'CALC'
]
# 删除包含空值的行(对于test_data)
test_data = test_data.dropna(subset=columns_to_check)
# 选择特征和目标变量
X = data[['Gender', 'Age', 'Height', 'Weight', 'family_history_with_overweight',
'SCC', 'FCVC', 'NCP', 'CAEC', 'SMOKE',
'CH2O', 'FAF', 'TUE', 'CALC']]
y = data['NObeyesdad'] # 目标变量是'NObeyesdad'列
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.01, random_state=42)
# 创建并训练模型
model = RandomForestClassifier(n_estimators=200,max_depth=30, random_state=42)
model.fit(X_train, y_train)
# 预测测试集并评估模型
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred)) # 打印分类报告(只需要一次)
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
# Logistic Regression
log_reg = LogisticRegression(max_iter=1000, random_state=42)
log_reg.fit(X_train, y_train)
y_pred_log_reg = log_reg.predict(X_test)
print("Logistic Regression:")
print(classification_report(y_test, y_pred_log_reg))
# Gradient Boosting Trees
gb_clf = GradientBoostingClassifier(n_estimators=200, random_state=42)
gb_clf.fit(X_train, y_train)
y_pred_gb = gb_clf.predict(X_test)
print("Gradient Boosting Trees:")
print(classification_report(y_test, y_pred_gb))
# K-Nearest Neighbors
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
y_pred_knn = knn.predict(X_test)
print("K-Nearest Neighbors:")
print(classification_report(y_test, y_pred_knn))
# Support Vector Machines
svm = SVC(random_state=42)
svm.fit(X_train, y_train)
y_pred_svm = svm.predict(X_test)
print("Support Vector Machines:")
print(classification_report(y_test, y_pred_svm))各模型的效果
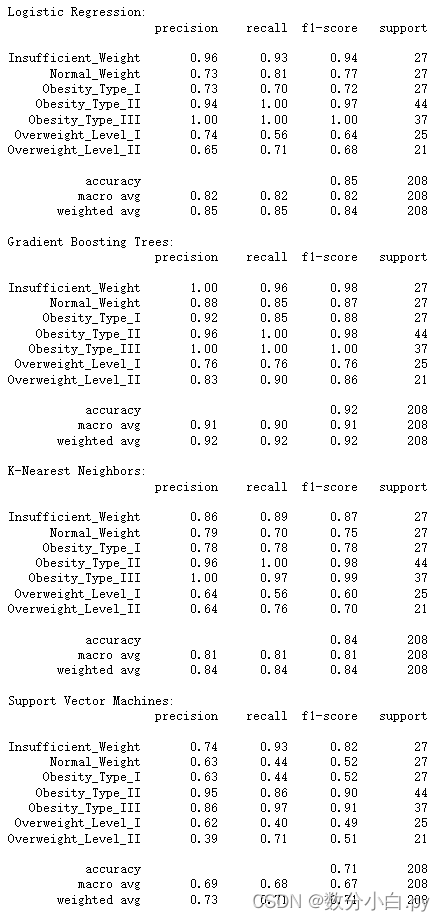
可以私信讨论


















 5058
5058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









