







 本文详细描述了在Spark3.4.2环境中使用YARN进行部署时遇到的问题,包括错误提示和如何配置SparkHistoryServer以查看详细的日志记录。通过配置`spark-env.sh`和`spark-defaults.conf`文件,以及启动HistoryServer,解决了运行SparkPi示例时的错误并确保了日志管理。
本文详细描述了在Spark3.4.2环境中使用YARN进行部署时遇到的问题,包括错误提示和如何配置SparkHistoryServer以查看详细的日志记录。通过配置`spark-env.sh`和`spark-defaults.conf`文件,以及启动HistoryServer,解决了运行SparkPi示例时的错误并确保了日志管理。
概述
spark 版本 3.4.2, hadoop 版本 3.3.6

实践
SparkPi
官方案例实践,直接执行报错。
[root@hadoop01 spark-3.4.2]# ./bin/spark-submit --class org.apache.spark.examples.SparkPi \
> --master yarn \
> --deploy-mode cluster \
> --driver-memory 4g \
> --executor-memory 2g \
> --executor-cores 1 \
> --queue thequeue \
> examples/jars/spark-examples*.jar \
> 10
24/02/22 15:56:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
24/02/22 15:56:50 INFO DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at hadoop01/10.32.36.142:8032
24/02/22 15:56:51 INFO Configuration: resource-types.xml not found
24/02/22 15:56:51 INFO ResourceUtils: Unable to find 'resource-types.xml'.
24/02/22 15:56:51 INFO Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8096 MB per container)
24/02/22 15:56:51 INFO Client: Will allocate AM container, with 4505 MB memory including 409 MB overhead
24/02/22 15:56:51 INFO Client: Setting up container launch context for our AM
24/02/22 15:56:51 INFO Client: Setting up the launch environment for our AM container
24/02/22 15:56:51 INFO Client: Preparing resources for our AM container
24/02/22 15:56:51 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
24/02/22 15:56:53 INFO Client: Uploading resource file:/tmp/spark-8fe81d98-3b2f-4a03-aa5f-4665a3959e70/__spark_libs__2923631333742251680.zip -> hdfs://hadoop01:9000/user/root/.sparkStaging/application_1708505130791_0001/__spark_libs__2923631333742251680.zip
24/02/22 15:56:54 INFO Client: Uploading resource file:/data/hadoop/soft/spark-3.4.2/examples/jars/spark-examples_2.12-3.4.2.jar -> hdfs://hadoop01:9000/user/root/.sparkStaging/application_1708505130791_0001/spark-examples_2.12-3.4.2.jar
24/02/22 15:56:54 INFO Client: Uploading resource file:/tmp/spark-8fe81d98-3b2f-4a03-aa5f-4665a3959e70/__spark_conf__3172536214166465796.zip -> hdfs://hadoop01:9000/user/root/.sparkStaging/application_1708505130791_0001/__spark_conf__.zip
24/02/22 15:56:54 INFO SecurityManager: Changing view acls to: root
24/02/22 15:56:54 INFO SecurityManager: Changing modify acls to: root
24/02/22 15:56:54 INFO SecurityManager: Changing view acls groups to:
24/02/22 15:56:54 INFO SecurityManager: Changing modify acls groups to:
24/02/22 15:56:54 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: root; groups with view permissions: EMPTY; users with modify permissions: root; groups with modify permissions: EMPTY
24/02/22 15:56:54 INFO Client: Submitting application application_1708505130791_0001 to ResourceManager
24/02/22 15:56:55 INFO Client: Deleted staging directory hdfs://hadoop01:9000/user/root/.sparkStaging/application_1708505130791_0001
Exception in thread "main" org.apache.hadoop.yarn.exceptions.YarnException: Failed to submit application_1708505130791_0001 to YARN : Application application_1708505130791_0001 submitted by user root to unknown queue: thequeue
at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.submitApplication(YarnClientImpl.java:336)
at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:225)
at org.apache.spark.deploy.yarn.Client.run(Client.scala:1310)
at org.apache.spark.deploy.yarn.YarnClusterApplication.start(Client.scala:1758)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:1020)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:192)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:215)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:91)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1111)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1120)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
24/02/22 15:56:55 INFO ShutdownHookManager: Shutdown hook called
24/02/22 15:56:55 INFO ShutdownHookManager: Deleting directory /tmp/spark-8fe81d98-3b2f-4a03-aa5f-4665a3959e70
24/02/22 15:56:55 INFO ShutdownHookManager: Deleting directory /tmp/spark-33c5a540-ae1c-4f37-933c-fde2893c89a0
[root@hadoop01 spark-3.4.2]#
没有建这个队列,采取默认队列
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 4g \
--executor-memory 2g \
--executor-cores 1 \
examples/jars/spark-examples*.jar \
10
[root@hadoop01 spark-3.4.2]# ./bin/spark-submit --class org.apache.spark.examples.SparkPi \
> --master yarn \
> --deploy-mode cluster \
> --driver-memory 4g \
> --executor-memory 2g \
> --executor-cores 1 \
> examples/jars/spark-examples*.jar \
> 10
24/02/22 16:00:00 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
24/02/22 16:00:00 INFO DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at hadoop01/10.32.36.142:8032
24/02/22 16:00:01 INFO Configuration: resource-types.xml not found
24/02/22 16:00:01 INFO ResourceUtils: Unable to find 'resource-types.xml'.
24/02/22 16:00:01 INFO Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8096 MB per container)
24/02/22 16:00:01 INFO Client: Will allocate AM container, with 4505 MB memory including 409 MB overhead
24/02/22 16:00:01 INFO Client: Setting up container launch context for our AM
24/02/22 16:00:01 INFO Client: Setting up the launch environment for our AM container
24/02/22 16:00:01 INFO Client: Preparing resources for our AM container
24/02/22 16:00:01 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
24/02/22 16:00:03 INFO Client: Uploading resource file:/tmp/spark-337dc919-faec-4ce4-8500-2a353afe9d01/__spark_libs__3444560846958053802.zip -> hdfs://hadoop01:9000/user/root/.sparkStaging/application_1708505130791_0002/__spark_libs__3444560846958053802.zip
24/02/22 16:00:04 INFO Client: Uploading resource file:/data/hadoop/soft/spark-3.4.2/examples/jars/spark-examples_2.12-3.4.2.jar -> hdfs://hadoop01:9000/user/root/.sparkStaging/application_1708505130791_0002/spark-examples_2.12-3.4.2.jar
24/02/22 16:00:04 INFO Client: Uploading resource file:/tmp/spark-337dc919-faec-4ce4-8500-2a353afe9d01/__spark_conf__9205864261457490190.zip -> hdfs://hadoop01:9000/user/root/.sparkStaging/application_1708505130791_0002/__spark_conf__.zip
24/02/22 16:00:04 INFO SecurityManager: Changing view acls to: root
24/02/22 16:00:04 INFO SecurityManager: Changing modify acls to: root
24/02/22 16:00:04 INFO SecurityManager: Changing view acls groups to:
24/02/22 16:00:04 INFO SecurityManager: Changing modify acls groups to:
24/02/22 16:00:04 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: root; groups with view permissions: EMPTY; users with modify permissions: root; groups with modify permissions: EMPTY
24/02/22 16:00:04 INFO Client: Submitting application application_1708505130791_0002 to ResourceManager
24/02/22 16:00:04 INFO YarnClientImpl: Submitted application application_1708505130791_0002
24/02/22 16:00:05 INFO Client: Application report for application_1708505130791_0002 (state: ACCEPTED)
24/02/22 16:00:05 INFO Client:
client token: N/A
diagnostics: [Thu Feb 22 16:00:05 +0800 2024] Scheduler has assigned a container for AM, waiting for AM container to be launched
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1708588804348
final status: UNDEFINED
tracking URL: http://hadoop01:8088/proxy/application_1708505130791_0002/
user: root
24/02/22 16:00:06 INFO Client: Application report for application_1708505130791_0002 (state: ACCEPTED)
24/02/22 16:00:07 INFO Client: Application report for application_1708505130791_0002 (state: ACCEPTED)
24/02/22 16:00:08 INFO Client: Application report for application_1708505130791_0002 (state: ACCEPTED)
24/02/22 16:00:09 INFO Client: Application report for application_1708505130791_0002 (state: ACCEPTED)
24/02/22 16:00:10 INFO Client: Application report for application_1708505130791_0002 (state: ACCEPTED)
24/02/22 16:00:11 INFO Client: Application report for application_1708505130791_0002 (state: ACCEPTED)
24/02/22 16:00:12 INFO Client: Application report for application_1708505130791_0002 (state: RUNNING)
24/02/22 16:00:12 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: hadoop02
ApplicationMaster RPC port: 41047
queue: default
start time: 1708588804348
final status: UNDEFINED
tracking URL: http://hadoop01:8088/proxy/application_1708505130791_0002/
user: root
24/02/22 16:00:13 INFO Client: Application report for application_1708505130791_0002 (state: RUNNING)
24/02/22 16:00:14 INFO Client: Application report for application_1708505130791_0002 (state: RUNNING)
24/02/22 16:00:15 INFO Client: Application report for application_1708505130791_0002 (state: RUNNING)
24/02/22 16:00:16 INFO Client: Application report for application_1708505130791_0002 (state: RUNNING)
24/02/22 16:00:17 INFO Client: Application report for application_1708505130791_0002 (state: RUNNING)
24/02/22 16:00:18 INFO Client: Application report for application_1708505130791_0002 (state: RUNNING)
24/02/22 16:00:19 INFO Client: Application report for application_1708505130791_0002 (state: FINISHED)
24/02/22 16:00:19 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: hadoop02
ApplicationMaster RPC port: 41047
queue: default
start time: 1708588804348
final status: SUCCEEDED
tracking URL: http://hadoop01:8088/proxy/application_1708505130791_0002/
user: root
24/02/22 16:00:19 INFO ShutdownHookManager: Shutdown hook called
24/02/22 16:00:19 INFO ShutdownHookManager: Deleting directory /tmp/spark-337dc919-faec-4ce4-8500-2a353afe9d01
24/02/22 16:00:19 INFO ShutdownHookManager: Deleting directory /tmp/spark-e095d81e-dd03-4ad7-bbb6-d84a6bd8ca62
[root@hadoop01 spark-3.4.2]#
执行如下图

添加日志记录
如下图,当想看详细日志时,没有

配置如下:
hadoop 中 yarn-site.xml 参考 hadoop一主三从安装 中的 hadoop historyserver 配置
[root@hadoop01 spark-3.4.2]# cd conf/
[root@hadoop01 conf]# ls
fairscheduler.xml.template log4j2.properties.template metrics.properties.template spark-defaults.conf.template spark-env.sh.template workers.template
[root@hadoop01 conf]# pwd
/data/hadoop/soft/spark-3.4.2/conf
# 第一步配置 spark-env.sh
[root@hadoop01 conf]# mv spark-env.sh.template spark-env.sh
[root@hadoop01 conf]# vi spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=200 -Dspark.history.fs.logDirectory=hdfs://hadoop01:9000/spark-eventlog"
fairscheduler.xml.template log4j2.properties.template metrics.properties.template spark-defaults.conf.template spark-env.sh workers.template
# 第二步配置 spark-defaults.conf
[root@hadoop01 conf]# mv spark-defaults.conf.template spark-defaults.conf
[root@hadoop01 conf]# vi spark-defaults.conf
spark.master=yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop01:9000/spark-eventlog
spark.eventLog.compress true
# 注意:在哪个节点上启动spark的historyserver进程,spark.yarn.historyServer.address的值里面就指定哪个节点的主机名信息
spark.yarn.historyServer.address hadoop01:18080
spark.history.ui.port 18080
spark.ui.retainedJobs 50
spark.ui.retainedStages 300
# 序列化
spark.serializer org.apache.spark.serializer.KryoSerializer
# 注意先建 /spark-eventlog 目录,否则执行会报错
[root@hadoop01 spark-3.4.2]# hdfs dfs -mkdir /spark-eventlog
2024-02-22 16:27:15,442 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[root@hadoop01 spark-3.4.2]#
# 第三步
[root@hadoop01 spark-3.4.2]# sbin/start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /data/hadoop/soft/spark-3.4.2/logs/spark-root-org.apache.spark.deploy.history.HistoryServer-1-hadoop01.out
[root@hadoop01 spark-3.4.2]#
最终执行,如下
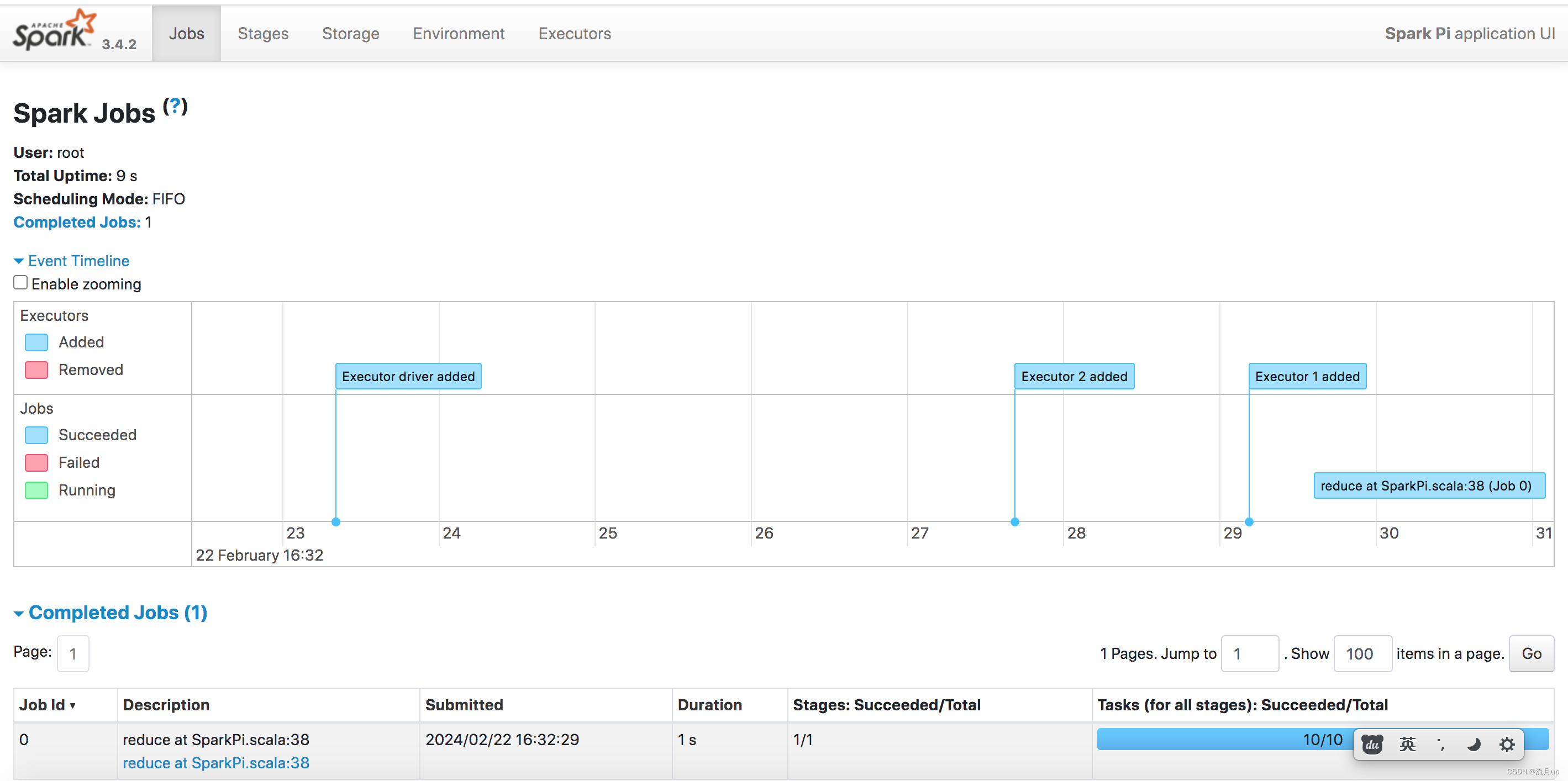
结束
spark on yarn 实践至此结束,如有疑问,欢迎评论区留言。

















 1591
1591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











