







这个我感觉真的不用解释了吧。就是把爬取到的数据做一个保存,数据的存储形式多种多样,但主要分为两类,一类是简单的保存为文本文件,例如txt、json、csv等,另一类是保存到数据库,例如MySQL、MongoDB、Redis等。接下来就来学习这些方法吧~
学习数据存储前我们需要先爬取数据,这里我就不再编写这部分代码了,直接用前面爬取豆瓣的代码演示,不明白的回去看我前面的博客哦
文件打开方式
tip: 这里列举一下文件保存的一个参数
| 参数 | 含义 |
| — | — |
| r | 只读方式打开(默认这种方式) |
| rb | 以二进制只读打开(用于音频、图片、视频) |
| r+ | 以读写方式打开文件 |
| rb+ | 以二进制读写打开 |
| w | 以写入方式打开文件(文件存在则覆盖,不存在就新建) |
| wb | 以二进制写入方式写入(文件存在则覆盖,不存在就新建) |
| w+ | 以读写方式打开文件 (文件存在则覆盖,不存在就新建) |
| wb+ | 以二进制读写方式打开文件 (文件存在则覆盖,不存在就新建) |
| a | 以追加方式打开文件 |
| ab | 以二进制追加方式打开文件 |
| a+ | 以读写方式打开文件 |
| ab+ | 以二进制追加打开文件 |
保存为txt文本
这应该是爬虫数据保存最简单的一种方式了,直接看代码,这里为了方便我将所有的数据保存都定义为函数,调用对应的函数实现保存即可。
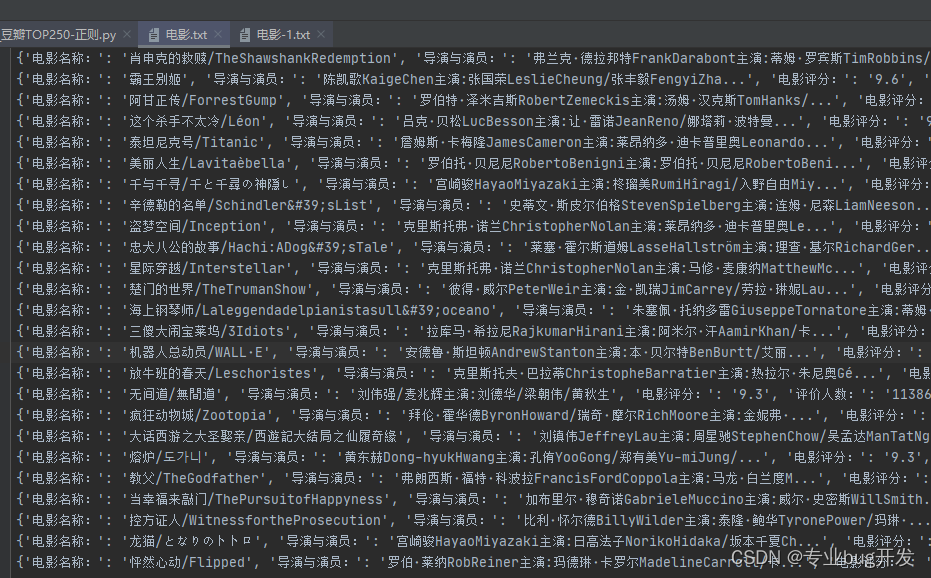
第一种写法:
这种方式需要定义file等于
def save_txt_2(mystr):
file = open(‘…/Include/电影-1.txt’, ‘a’, encoding=‘utf-8’)
file.write(mystr+‘\n’)
file.close()
第二种写法:
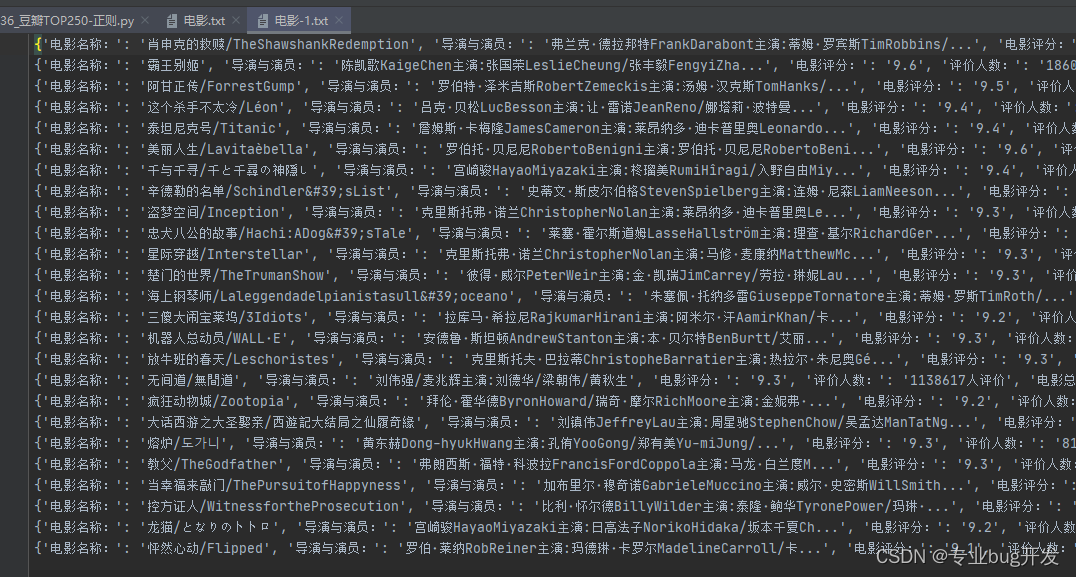
这种方法对一种方法进行了简化,一般都会使用这种方式
保存数据为txt(简写的方式)
def save_txt_1(mystr):
with open(‘…/Include/电影.txt’, ‘a’, encoding=‘utf-8’) as file:
file.write(f’{mystr}\n’)
保存为JSON
json作为一种很常见的数据存储格式,通常以一个大括号包裹着键值对的形式,例如下面的这个数据
{‘name’:‘张三’, ‘age’:18, ‘sex’:‘男’}
数据存储为json
def save_json(data):
with open(‘…/Include/电影.json’, ‘a’, encoding=‘utf-8’) as file:
file.write(f’{data}\n’)

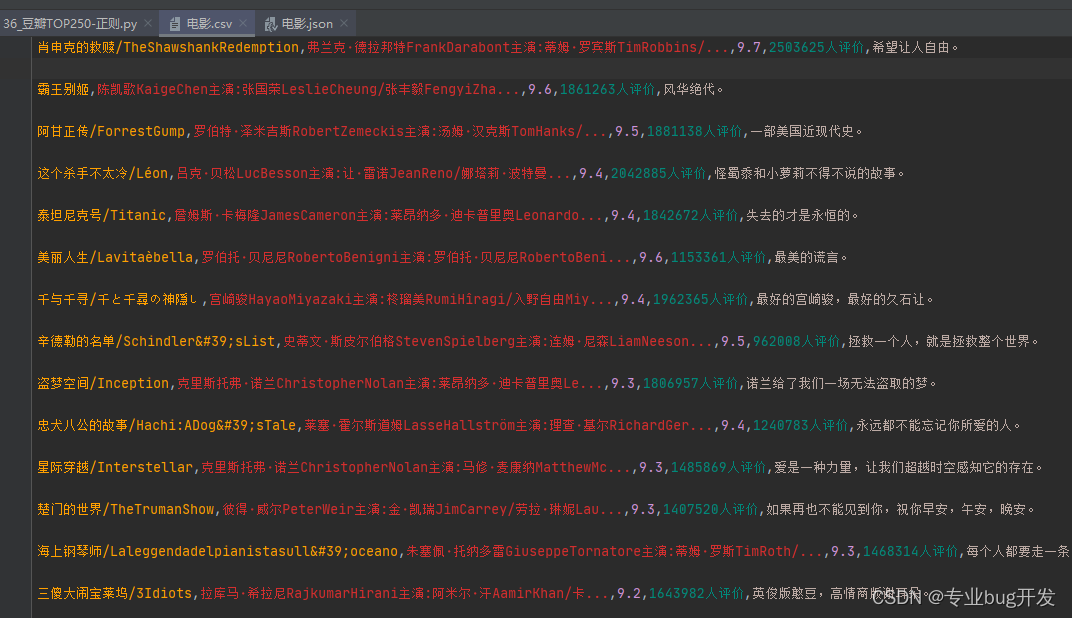
保存为CSV
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。
因为爬虫里面我们通常会以字典的形式保存数据,所以这里我就演示如何将字典数据存储为csv文件。
数据存储为csv
def save_csv(data):
with open(‘…/Include/电影.csv’, ‘a’, encoding=‘utf-8’) as file:
注意这里的fieldnames里的字段必须和你要存储的字典里的键对应,否则会报错
fieldnames = [‘电影名称:’, ‘导演与演员:’, ‘电影评分:’, ‘评价人数:’, ‘电影总结:’]
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writerow(data)
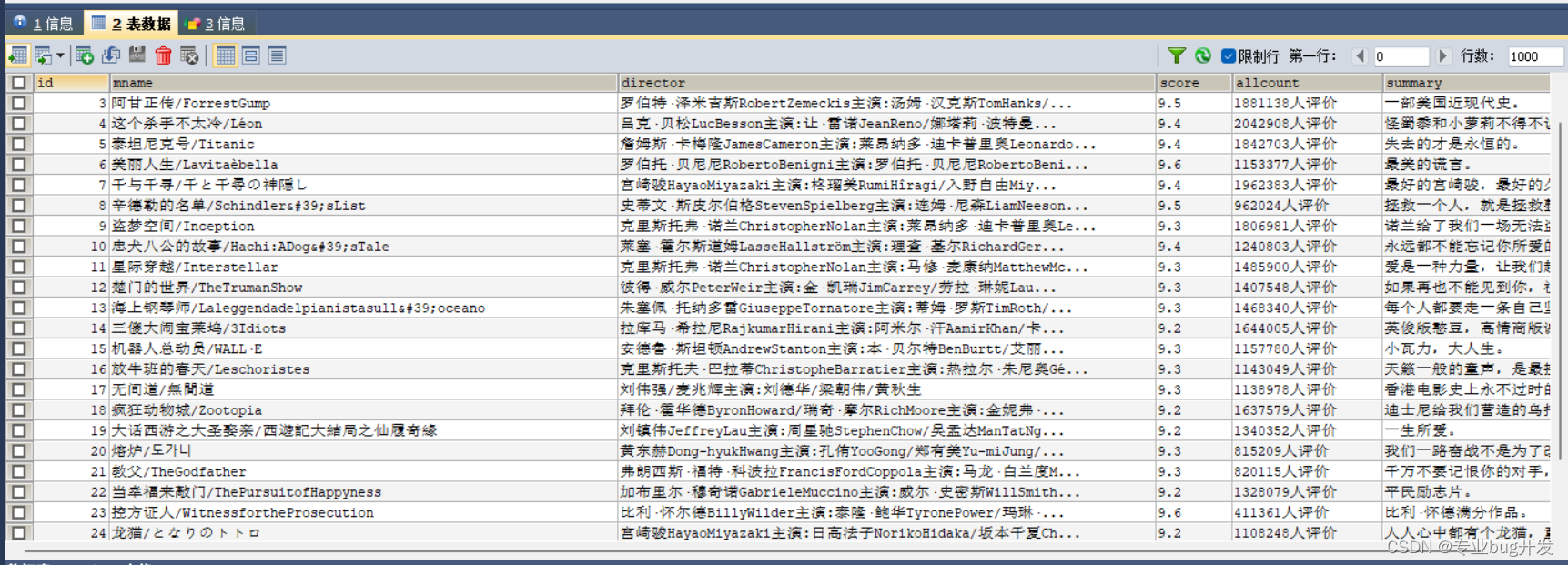
保存到MySQL
MySQL作为一种开源关系型数据深受开发者的喜欢,在爬虫数据存储的过程中我们也经常使用。
与前面存储为文本形式不同,存储到数据库时我们通常需要先连接数据库,然后才能执行存储操作,这里我事先在mysql里面见一个名为movies的数据库和一张名为movie的数据表。
数据存储到MySQL
def save_mysql(data):
建立连接
db = pymysql.connect(host=‘127.0.0.1’, user=‘root’, password=‘123456’, port=3306, db=‘movies’)
建立游标
cursor = db.cursor()
sql语句
sql = "insert into movice(mname,director,score,allcount,summary) values (%s,%s,%s,%s,%s) "
操作
data = (data[‘电影名称:’], data[‘导演与演员:’], data[‘电影评分:’], data[‘评价人数:’], data[‘电影总结:’])
try:
cursor.execute(sql,data)
db.commit()
except Exception as e:
print(‘插入数据失败’, e)
db.rollback() # 回滚
关闭游标
cursor.close()
关闭连接
db.close()
保存到MongoDB
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)
png)
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)
















 173
173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









