







 本文提出了一种名为动态卷积神经网络(DCNN)的模型,用于高效表示和理解句子的语义。通过动态k-maxpooling和一维卷积,DCNN能捕捉短程和长程关系,超越传统模型。实验表明,DCNN在情感分析和问题分类任务中表现出色,尤其在远程监督的Twitter情感预测中显著降低错误率。
本文提出了一种名为动态卷积神经网络(DCNN)的模型,用于高效表示和理解句子的语义。通过动态k-maxpooling和一维卷积,DCNN能捕捉短程和长程关系,超越传统模型。实验表明,DCNN在情感分析和问题分类任务中表现出色,尤其在远程监督的Twitter情感预测中显著降低错误率。
本篇论文发表于2014年的ACL
目录
1. Abstract
准确表示句子的能力是语言理解的核心。 我们描述了一种称为动态卷积神经网络(DCNN)的卷积架构,我们采用它来对句子进行语义建模。 该网络使用动态 k-Max Pooling,这是一种针对线性序列的全局池化操作。 该网络处理不同长度的输入句子,并在句子上生成一个特征图,该特征图能够明确捕获短程和长程关系。 该网络不依赖于解析树,并且很容易适用于任何语言。
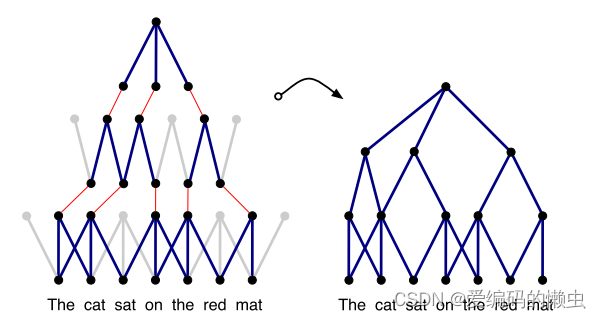
动态卷积神经网络中输入句子诱导的特征图的子图。 完整归纳图具有多个此类子图,并且具有一组不同的边; 子图可以在不同层合并。 左图强调了池节点。 卷积滤波器的宽度分别为3和2。 通过动态池化,较高层宽度较小的过滤器可以将输入句子中相距较远的短语关联起来
我们在四个实验中测试了 DCNN:小规模二元和多类情感预测、六向问题分类和远程监督的 Twitter 情感预测。 与最强基线相比,网络在前三个任务中实现了出色的性能,并且在最后一个任务中错误率降低了 25% 以上。
2. Introduction
句子建模的目的是分析和表示句子的语义内容,以进行分类或生成。 句子建模问题是涉及一定程度自然语言理解的许多任务的核心。 这些任务包括情感分析、释义检测、蕴含识别、摘要、话语分析、机器翻译、基础语言学习和图像检索。 由于单个句子很少被观察到或根本没有被观察到,因此必须根据依赖于句子中经常观察到的单词和短 n 元语法的特征来表示句子。 句子模型的核心涉及到一个特征函数,它定义了从单词或n-gram的特征中提取句子特征的过程。
人们已经提出了各种类型的意义模型。 基于组合的方法已应用于从共现统计中获得的词义的向量表示,以获得较长短语的向量。 在某些情况下,组合是通过词义向量的代数运算来定义的,以产生句子意义向量(Erk 和 Pad´o,2008;Mitchell 和 Lapata,2008;Mitchell 和 Lapata,2010;Turney,2012;Erk,2012;Clarke, 2012)。 在其他情况下,学习组合函数,并且该组合函数要么与特定的句法关系(Guevara,2010;Zanzotto 等人,2010)相关,要么与特定的单词类型(Baroni 和 Zamparelli,2010;Coecke 等人,2010;Grefenstette 和 Sadrzadeh)相关。 ,2011 年;Kartsaklis 和 Sadrzadeh,2013 年;Grefenstette,2013 年)。 另一种方法通过自动提取的逻辑形式来表示句子的含义(Zettlemoyer 和 Collins,2005)。
近年来的一些研究现状
模型的核心类别是基于神经网络的模型。 这些范围从基本的神经词袋或 n-gram 模型到更结构化的递归神经网络以及基于卷积运算的时延神经网络(Collobert 和 Weston,2008 年;Socher 等人,2011 年) ;Kalchbrenner 和 Blunsom,2013b)。 神经句子模型有很多优点。 例如,可以训练它们通过预测单词和短语出现的上下文来获取单词和短语的通用向量。 通过监督训练,神经句子模型可以将这些向量微调为特定于特定任务的信息。 除了包含强大的分类器作为其架构的一部分之外,神经句子模型还可用于调节神经语言模型以逐字生成句子(Schwenk,2012;Mikolov 和 Zweig,2012;Kalchbrenner 和 Blunsom,2013a)。
我们定义了一个卷积神经网络架构并将其应用于句子的语义建模。 网络处理不同长度的输入序列。 网络中的层交错一维卷积层和动态 k-max 池化层。 动态 k-max 池化是最大池化算子的推广。 最大池运算符是一个非线性子采样函数,它返回一组值的最大值(LeCun 等人,1998)。 该运算符在两个方面进行了概括。 首先,对线性值序列进行 kmax 池化返回序列中 k 个最大值的子序列,而不是单个最大值。 其次,可以通过使 k 成为网络或输入的其他方面的函数来动态选择池化参数 k。
卷积层在句子矩阵中的每一行特征上应用一维滤波器。 在句子中的每个位置将相同的过滤器与 n-gram 进行卷积,可以独立于句子中的位置来提取特征。 卷积层后跟动态池化层和非线性层形成特征图。 就像在用于对象识别的卷积网络中一样(LeCun 等人,1998),我们通过对输入句子应用不同的过滤器计算多个特征图来丰富第一层的表示。 后续层还具有通过将滤波器与下面层的所有图进行卷积计算而计算出的多个特征图。 这些层的权重形成一个 4 阶张量。 由此产生的架构被称为动态卷积神经网络。
我们在四种设置中对网络进行实验。 前两个实验涉及预测电影评论的情绪(Socher et al., 2013b)。 该网络在二元和多类实验中都优于其他方法。 第三个实验涉及对 TREC 数据集中六种问题类型的问题进行分类(Li 和 Roth,2002)。 该网络的准确性可与其他基于大量工程特征和手工编码知识资源的最先进方法相媲美。 第四个实验涉及使用远程监督来预测 Twitter 帖子的情绪(Go 等人,2009)。 该网络接受了 160 万条推文的训练,根据推文中出现的表情自动标记。 在手工标记的测试集上,相对于 Go 等人报告的最强一元和二元基线,网络的预测误差降低了 25% 以上(2009)。
上面几段就是我们干了啥以及干的咋样。
3. Background
下面根据这个例子,对各个模型进行详解。
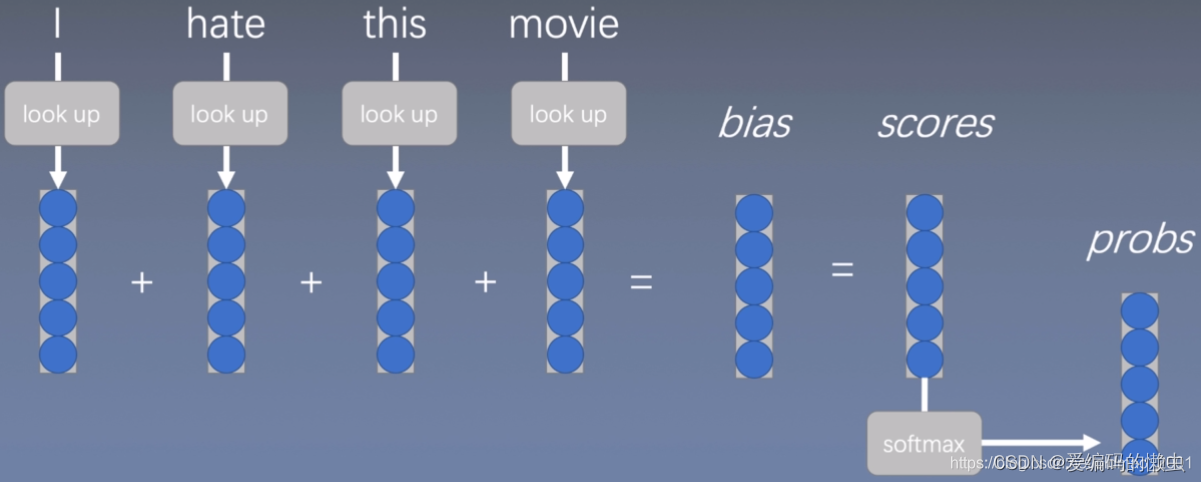
3.1 词袋模型
先用word2vec或者其他方法把词转换成向量表征(通过look up进行查找),然后把这些词表征简单相加起来,再加上偏置bias得到一个得分scores,然后再用softmax函数进行分类。
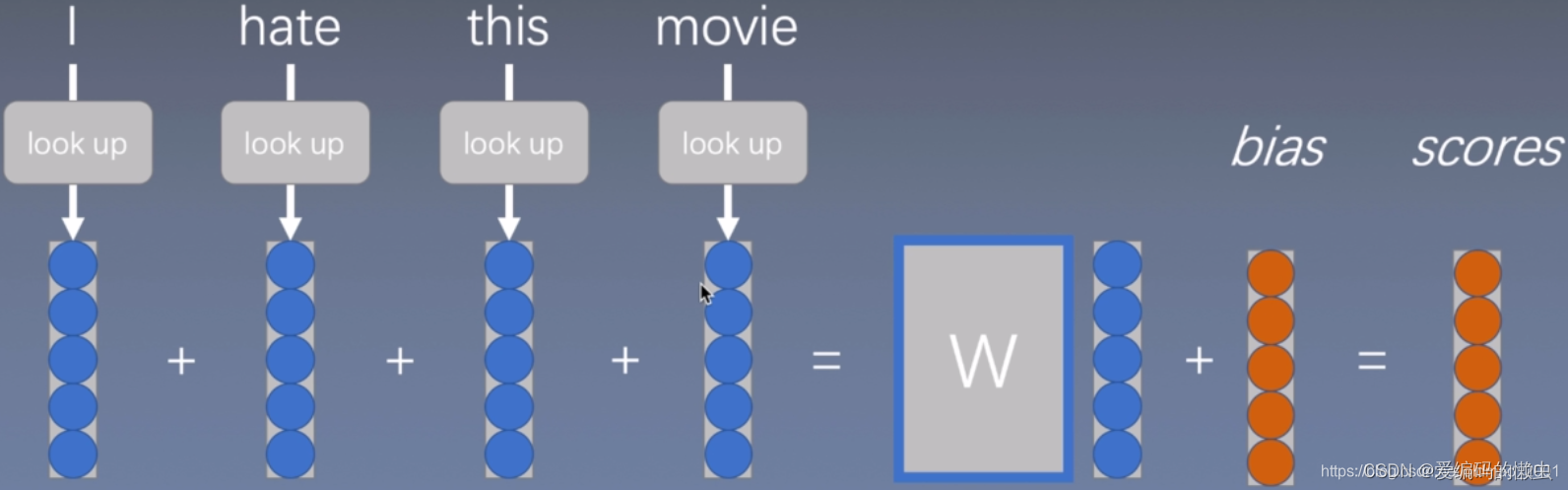
这个模型虽然能够体现出词在句子中的重要性,但是忽略了词与词之间的相互关系。然后对这个模型进行了改进得到:连续词袋模型。
3.2 连续词袋模型
就是在单词向量相加之后,再做一个线性变化,进一步增大模型容量,使得模型更加复杂,更好的拟合这些数据。但是只加上线性变换并不能完全脱离之前词袋模型的缺点。
进一步改进:
3.3 深度的连续词袋模型
把得到的词向量表征输入到tanhh函数中,再输入到tanh函数中,再丢到线性函数中完成拟合。
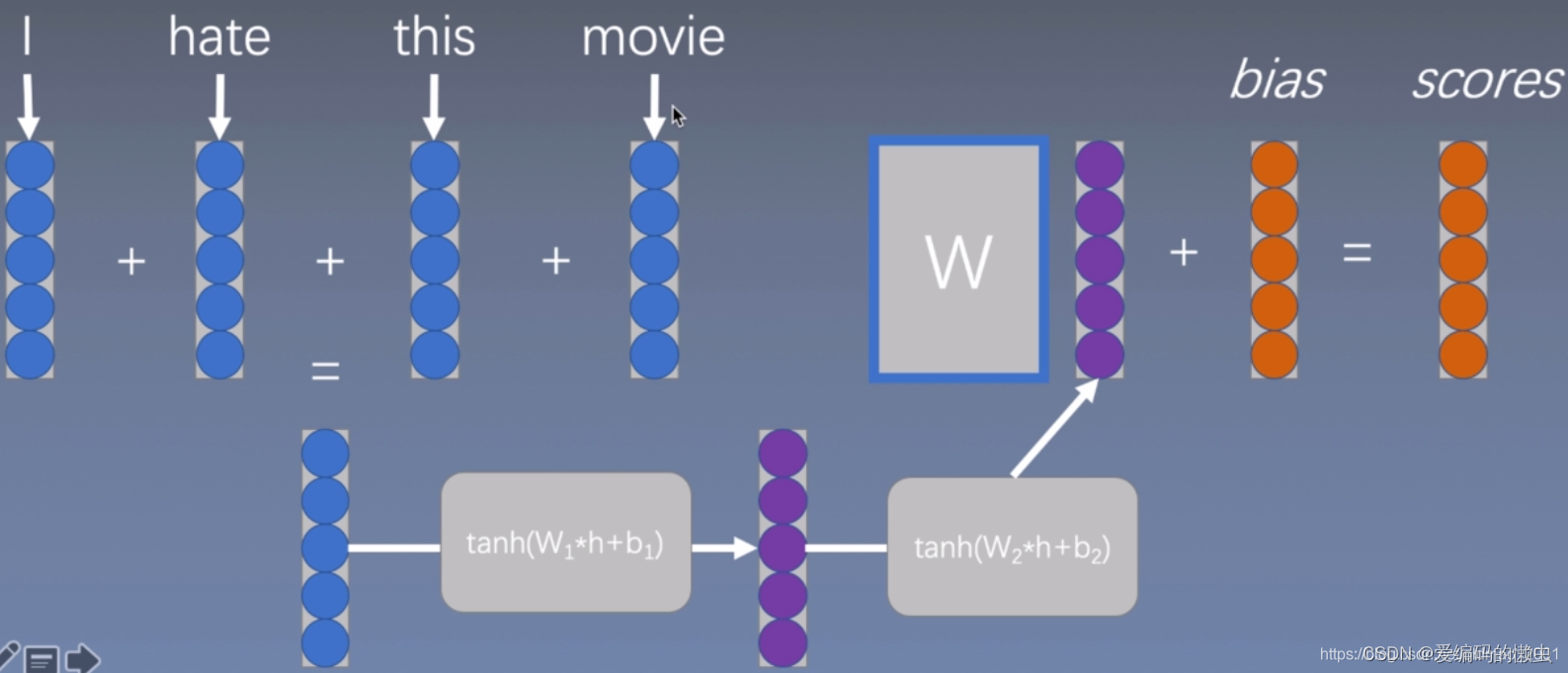
但是仍然没有考虑词组搭配之类的影响。
3.4 n-grams模型
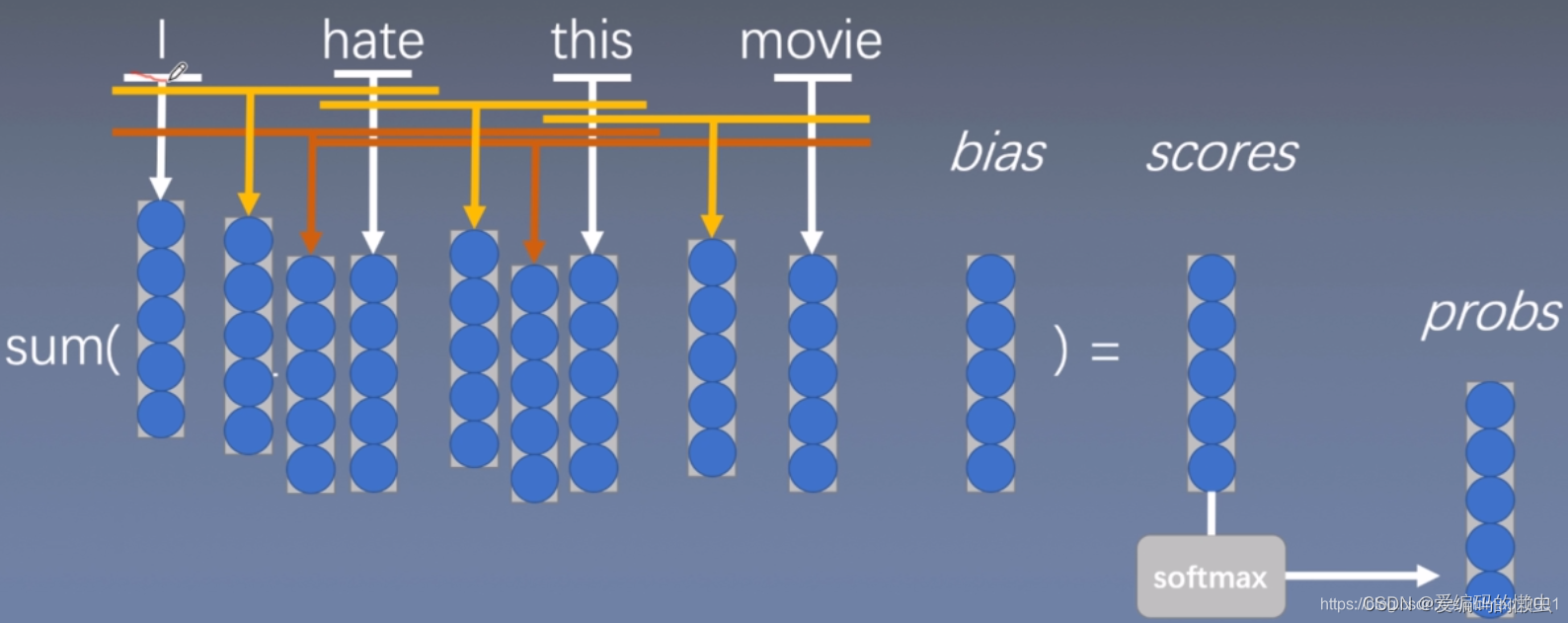
上图中的黄色和深黄色分布显示n=2和n=3的模型。
Why bag of n-grams?
allow us to capture combination features in a simple way “don’t love”,“not the best”
works pretty well
What problems with bag of n-grams?
parameter explosion
No sharing between similar words/n-grams
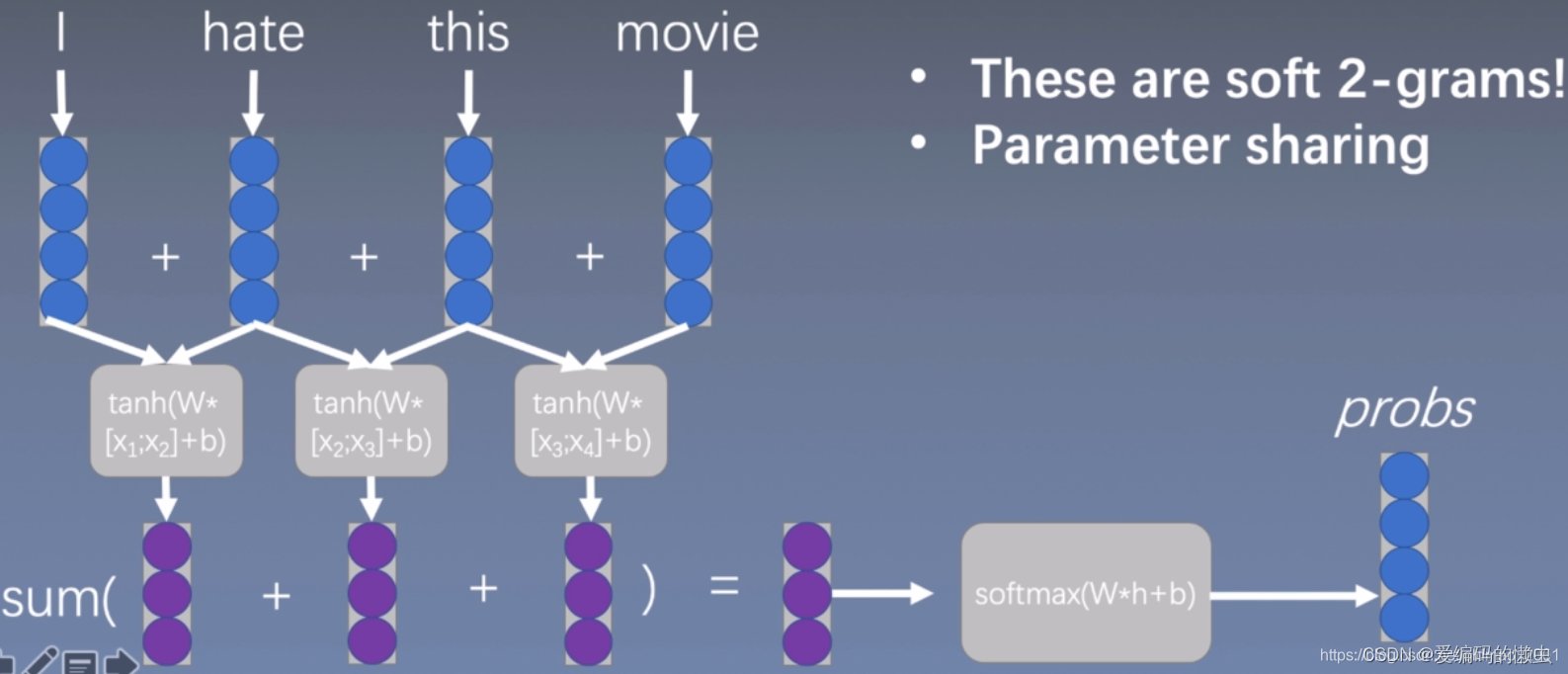
3.5 一维卷积/时间延迟网络
可以看到,使用下面的卷积方式进行扫描,一次2个词向量,和上面的n=2是一样的效果,但是和上面不一样的是,这个是卷积操作,意味着这里是可以共享参数的。
3.6 循环神经网络
3.7 递归神经张量网络
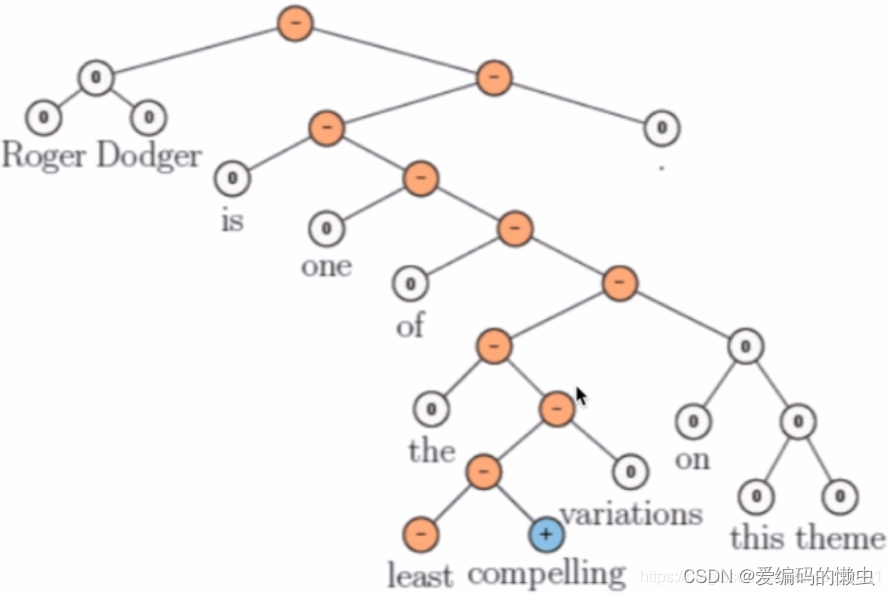
4.Model
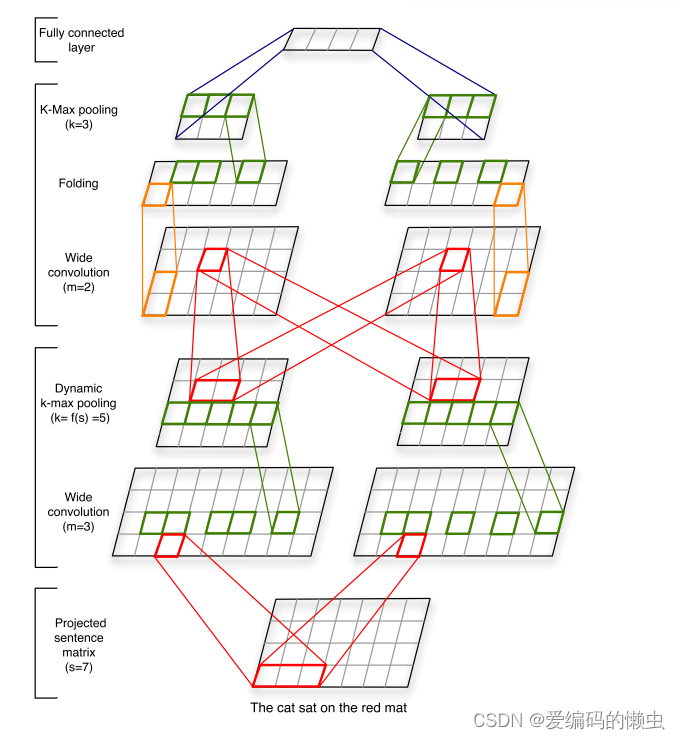
上面的model结构图,我们从下往上看。最下面是一个(7, 4)的词向量矩阵,每一个单词用embedding_dim=4的词向量表示。然后经过卷积核大小m=3的宽卷积操作得到(9, 4)的矩阵,(9, 4)的矩阵再经过k-max pooling操作(k = 5)得到(5, 4)的矩阵,(5, 4)的矩阵再经过卷积核大小m=2的宽卷积操作得到(6, 4)的矩阵,(6, 4)的矩阵再经过folding操作得到(6, 2)的矩阵。(6, 2)的矩阵再经过k-max pooling(k = 3)得到(3, 2)的矩阵,然后做全连接操作。
4.1 宽卷积
宽卷积的操作流程大概如下图所示,如果看不懂没关系去文心一言让它帮你解释一下。
用论文中的公式(3.1节)描述就是一个(d, s)的矩阵,d是词向量维度,此处是d=4,s是句子长度,此处是s = 7。做宽卷积操作会得到一个(d, s + m - 1)的矩阵,m=3的话,也就是model中的第一层宽卷积,即得到一个(4, 9)的矩阵。
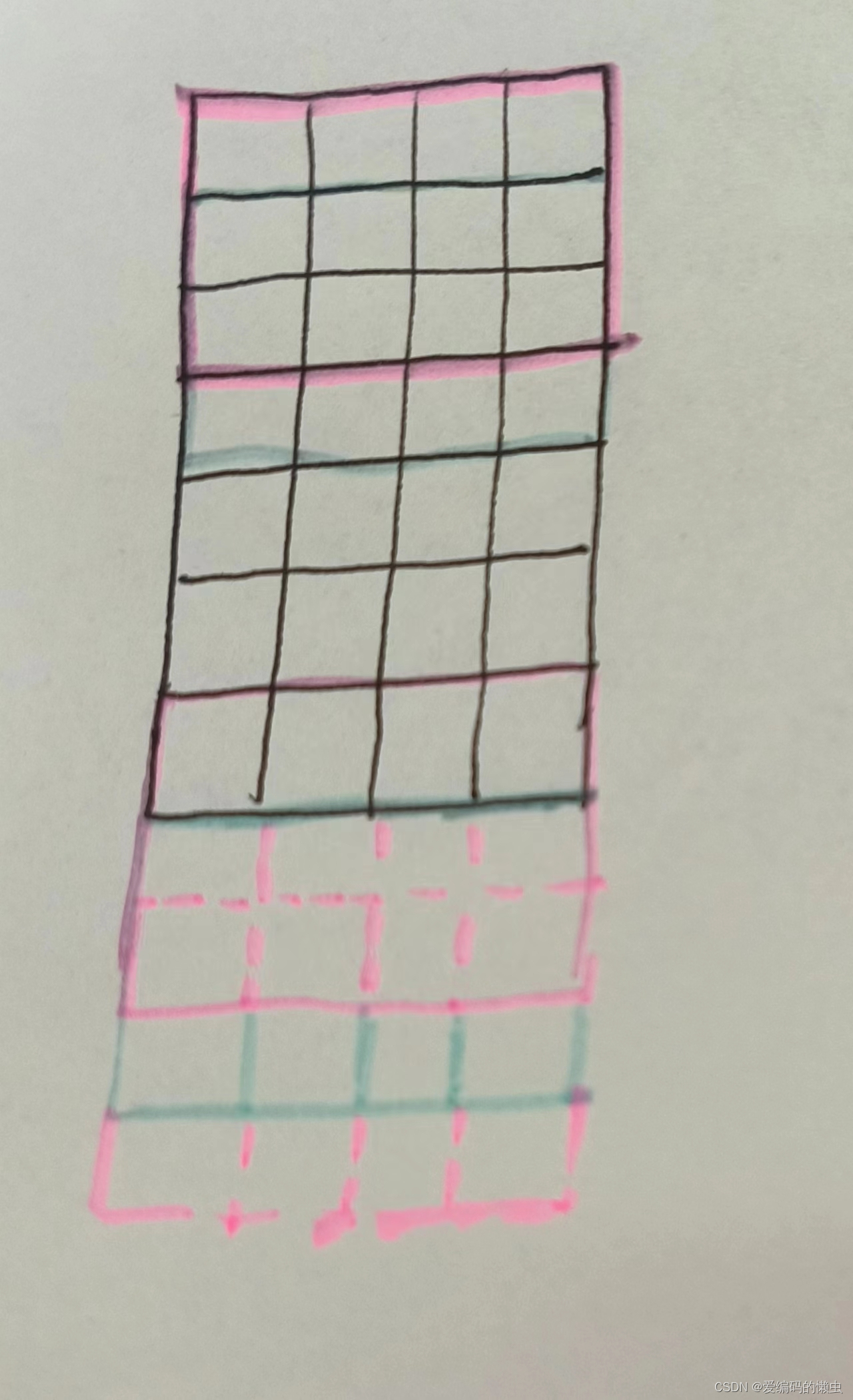
4.2 k-max pooling
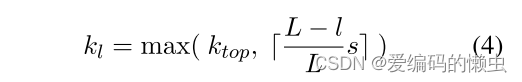
其中l是当前卷积层的层数,L是网络中卷积层的总数; ktop 是最顶层卷积层的固定池化参数(第 3.2 节)。
例如,在一个具有三个卷积层且ktop = 3的网络中,对于长度s = 18的输入句子,
第一层的池化参数为k1 = max(3, 上取整(18 * (3 - 1) / 3))12,
第二层的池化参数为k2 = 6;
第三层具有固定的池化参数 k3 = ktop = 3。
5. 实验结果
5.1 影评中的情感预测
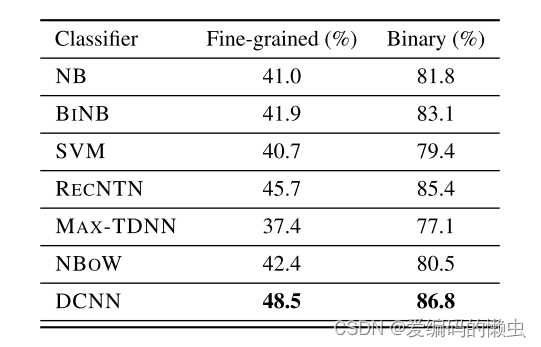
5.2 问题类型的分类
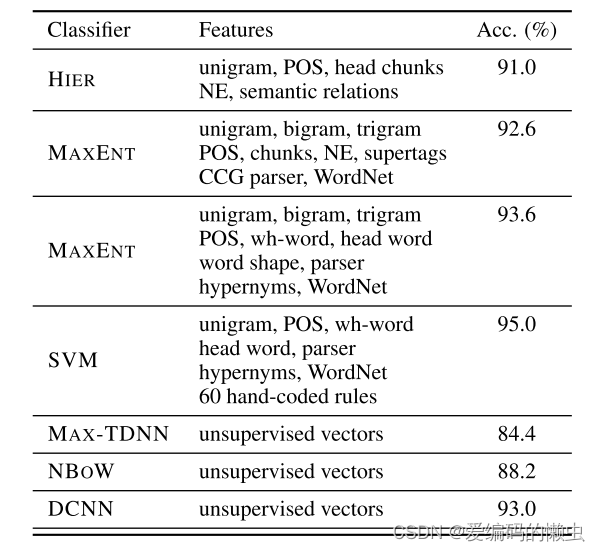
5.3 通过远程监督的Twitter情感预测
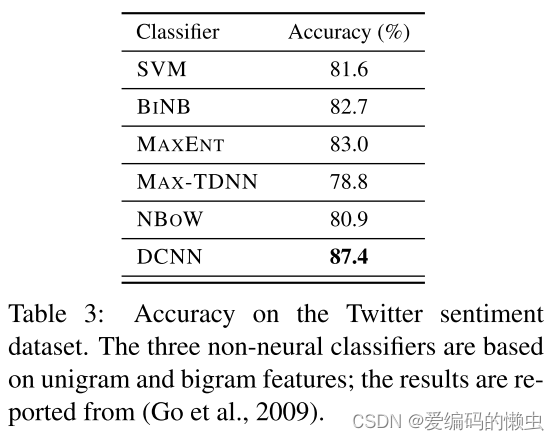
5.4 特征检测器的可视化

6. 讨论和总结
6.1 讨论
1.如何增大特征检测的扫描范围:Wide Convolution
2.如何捕捉到句子更复杂的特征关系:Dynamic k-max pooling
3.如何捕捉到不同维度特征的关系:folding
6.2 总结
1.新的句子模型:动态的卷积神经网络
2.在句子分类和情感分类问题效果很好
3.不需要额外的特征
7. 复现
由于时间紧迫的原因,这篇文章暂时不复现,以后如果有时间复现了再把代码贴上来~















 1515
1515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









