







本篇论文发布于2017年的ACL。DPCNN论文链接
文章目录
1. Abstract
本文提出了一种用于文本分类的低复杂度词级深度卷积神经网络(CNN)架构,可以有效地表示文本中的长程关联。 在文献中,假设有相对大量的训练数据,已经提出了几种深度且复杂的神经网络来完成此任务。 然而,随着网络的加深,相关的计算复杂度也会增加,这在实际应用中提出了严峻的挑战。 此外,最近的研究表明,即使在大量训练数据的情况下,浅层字级 CNN 也比最先进的超深网络(例如字符级 CNN)更准确、更快。 受这些发现的启发,我们仔细研究了词级 CNN 的深化以捕获文本的全局表示,并找到了一种简单的网络架构,通过增加网络深度可以在不增加太多计算成本的情况下获得最佳精度。 我们称之为深度金字塔 CNN。 所提出的具有 15 个权重层的模型在情感分类和主题分类的六个基准数据集上优于之前的最佳模型。
2. Introduction
文本分类是一项重要的任务,其应用包括垃圾邮件检测、情感分类和主题分类。 近年来,可以利用词序的神经网络已被证明对于文本分类是有效的。虽然简单和浅层的卷积神经网络(CNN)(Kim,2014;John son 和Zhang,2015a)较早地被提出来用于这项任务,但最近,深层和更复杂的神经网络也得到了研究,假设有相对大量的可用 训练数据(例如一百万个文档)。 例如深度字符级 CNN(Zhang 等人,2015;Conneau 等人,2016)、CNN 和循环神经网络(RNN)的复杂组合(Tang 等人,2015)以及单词句子层次结构中的 RNN (杨等人,2016)。
CNN 是一种前馈网络,其中卷积层与池化层交错。 本质上,卷积层将每个位置(例如,每个单词周围的 3 个单词窗口)的每小块数据(原始数据,如文本或图像或前一层的输出)转换为向量,这可以是 并行处理。 相比之下,RNN 具有形成循环的连接。 在文本的典型应用中,循环单元逐个获取单词以及前一个单词的自己的输出,这是并行处理不友好的。 虽然 CNN 和 RNN 都可以利用词序,但 CNN 的简单性质和并行处理友好性使它们具有吸引力,特别是当大量训练数据导致计算挑战时。
CNN利用词序,是本文作者发表的另一篇论文《Effective use of word order for text categorization with convolutional neural networks》。
词的向量表示即以词为单位来做embedding层,虽然词的个数特别多,但是训练时使用的30K个常用词就占数据集总词量的98%
最近有几项关于 CNN 在大型训练数据设置中进行文本分类的研究。 例如,在 (Conneau et al., 2016) 中,非常深的 32 层字符级 CNN 的性能优于 (Zhang et al., 2015) 的深 9 层字符级 CNN。 然而,在(Johnson 和Zhang,2016)中,非常浅的 1 层单词级 CNN 比(Conneau 等人,2016)的非常深的字符级 CNN 更准确且更快。 尽管字符级方法的优点在于不必处理数百万个不同的单词,但即使仅使用可管理数量(30K)的最常用单词,浅层单词级 CNN 也表现出优越性。 这证明了一个基本事实——单词知识可以产生强有力的表征。 这些结果激励我们追求一种有效且高效的深度词级 CNN 设计来进行文本分类。 但请注意,这并不像仅仅在字符级 CNN 中用单词替换字符那么简单; 这样做会降低准确性(Zhang et al., 2015)。
这段文字说明加深网络是有意义的,而且单词级的CNN比字符级更有优越性(单词知识可以产生强有力的表征)。所以作者将两者结合起来:一种有效且高效的深度词级CNN设计来进行文本分类。
我们仔细研究了大数据环境下词级CNN的深化,发现了一种深度但复杂度低的网络架构,通过增加深度而不是增加计算时间的顺序可以获得最佳精度——总计算时间为 由常数限制。 我们将其称为深度金字塔 CNN(DPCNN),因为每层的计算时间以“金字塔形状”呈指数减少。 将离散文本转换为连续表示后,DPCNN 架构只需一遍又一遍地交替使用卷积块和下采样层,从而形成一个内部数据大小(以及每层计算)以金字塔形状缩小的深度网络。 网络深度可以被视为元参数。 该网络的计算复杂度不会超过一个卷积块的计算复杂度的两倍。 同时,正如后面所述,随着网络的加深,“金字塔”能够有效地发现文本中的远程关联(以及更多的全局信息)。 这就是为什么DPCNN能够比上面提到的只能使用短程关联的浅层CNN(以下简称ShallowCNN)获得更好的精度。 此外,DPCNN 可以被视为 ShallowCNN 的深度扩展,我们在(Johnson 和Zhang,2015b)中提出了它,后来在(Johnson 和Zhang,2016)中用大数据集进行了测试。
论文使用步长为2的池化层,这样每经过一次池化层,数据就会缩减一半。
大小为3、步长为2的池化层,是常用的设置,这里论文中说成“金字塔”形状,可见发顶刊顶会的论文还得需要要有想想象力。
这一段告诉我们作者干了啥。
我们表明,具有 15 个权重层的 DPCNN 在情感分类和主题分类的六个基准数据集上优于之前的最佳模型。
干的咋样
:
3. DPCNN原理
3.1 model结构
DPCNN 如下图(a)所示。 第一层执行文本区域嵌入,将常用的单词嵌入概括为覆盖一个或多个单词的文本区域的嵌入。 接下来是堆叠卷积块(两个卷积层和一个残差连接),并与步长为 2 的池化层交错进行下采样。 最后的池化层将每个文档的内部数据聚合到一个向量中。 我们对所有池层使用最大池化。
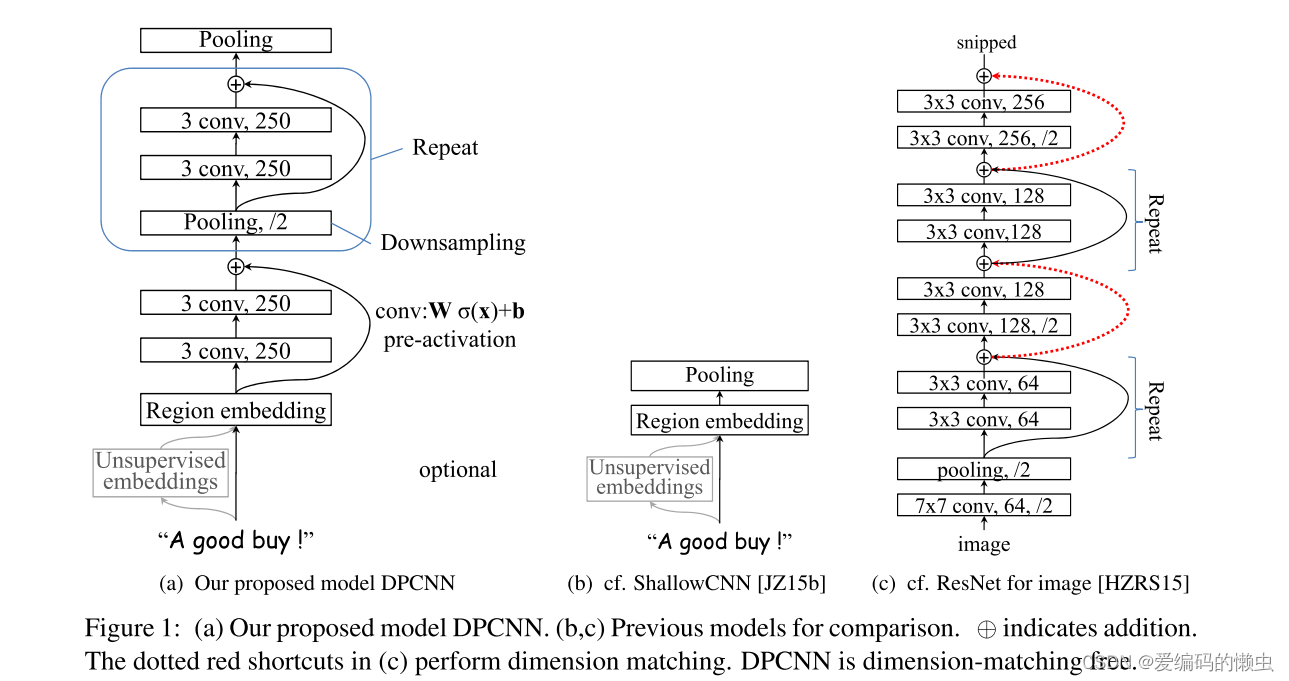
step1:模型输入
从下往上看,首先是输入的一句话“A good buy!”,毫无疑问,我们需要将这句话转化为向量。如果我来写这个代码会怎么做呢?先根据语料库生成一个word_to_index字典,然后根据字典将输入的字符串转换为索引表示;
接着我们可以使用通过word2vec预先训练好的词向量或者自己随机初始化:
self.embedding = nn.Embedding(vocab_size, embedding_dim),
然后再通过查表操作即x = embedding(x)会得到该句子的词向量表示矩阵。
step2:Region embedding
作者将TextCNN的包含多尺寸卷积滤波器的卷积层的卷积结果称之为Region embedding。意思是对一个文本区域(比如3-grams)进行一组卷积操作后生成的embedding。
对一个3gram进行卷积操作时可以有两种选择,一种是保留词序,也就是设置一组size=3*D的二维卷积核对3gram进行卷积(其中D是word embedding维度);还有一种是不保留词序(即使用词袋模型),即首先对3gram中的3个词的embedding取均值得到一个size=D的向量,然后设置一组size=D的一维卷积核对该3gram进行卷积。显然TextCNN里使用的是保留词序的做法,而DPCNN使用的是词袋模型的做法,DPCNN作者argue前者做法更容易造成过拟合,后者的性能却跟前者差不多。
step3:等长卷积
之后在模型主干上,经过两次等长卷积操作、激活,然后使用shortcut connections把原先的x与f(x)相加,作为下一层的输入。
此处,论文说的是shortcut connections with pre-activation,即预先激活的shortcut连接。就是说在模型主干的两个卷积层上先做激活,然后直接加上x,即ReLU(conv(x)) + x,而不是在模型主干的两个卷积层上走完加上x后激活,即ReLU(conv(x) + x)。
等长卷积:步长s = 1,两端补零p = (m - 1) / 2,m是卷积核的尺寸大小。等长卷积,顾名思义,卷积后的输出长度不变。DPCNN模型中采用两层,每层均为250个尺寸为3的卷积核。
那么,等长卷积的意义是什么呢?既然输入输出序列的位置数一样多,我们将输入输出序列的第n个embedding称为第n个词位,那么这时size为n的卷积核产生的等长卷积的意义就很明显了,那就是将输入序列的每个词位及其左右((n-1)/2)个词的上下文信息压缩为该词位的embedding,也就是说,产生了每个词位的被上下文信息修饰过的更高level更加准确的语义。
step4:Repeat
然后会进入一个循环的“池化—卷积块”。这里论文提到,feature map(可以认为是fliter)的数量是固定的,这有利于做“池化—卷积块”内部的shortcut connections,也有利于模型加深而不提高复杂度。
假设一次训练,数据走到Repeat部分前,batch=128, len=32, filter=250
第一次循环:经过Pooling(size为3、步长为2,导致数据缩减一半),那么len = len / 2 = 16,得到x[128, 16, 250]。主干部分经过2个等长卷积变成px[128, 16, 250],但是它的形状没有变。最后x = px +x为[128, 16, 50],直接相加形状也没变。
第二次循环:同理,变为[128, 8, 250]。
第三次循环:同理,变为[128, 4, 250]。
第四次循环:同理,变为[128, 2, 250]。
第五次循环:同理,变为[128, 1, 250]。此时不再循环,接个fc就可以分类输出了。
4.DPCNN模型的使用
为什么在这块就上代码呢?帮助你更好的理解DPCNN的model结构
4.1 二分类问题
首先从文件中读取相应训练集和测试集的语料,利用jieba对文本进行分词,然后利用nltk去停用词。
def tokenizer(text):
sentence = jieba.lcut(text, cut_all=False)
stopwords = stopwords.words('chinese')
sentence = [_ for _ in sentence if _ not in stopwords]
return sentence
利用torchtext包处理预处理好的语料,将所提供的语料集转化为相应的词向量模型。由于每一个词均为一个向量,作为模型的输入。
train_set, validation_set = data.TabularDataset.splits(
path='corpus_data/',
skip_header=True,
train='corpus_train.csv',
validation='corpus_validation.csv',
format='csv',
fields=[('label', label), ('text', text)],
)
text.build_vocab(train_set, validation_set)
将处理好的词向量输入到DPCNN模型中进行处理。
self.conv_region = nn.Conv2d(1, args.filter_num, (3, embedding_dim), stride=1)
self.conv = nn.Conv2d(args.filter_num, args.filter_num, (3, 1), stride=1)
self.max_pool = nn.MaxPool2d(kernel_size=(3, 1), stride=2)
self.padding1 = nn.ZeroPad2d((0, 0, 1, 1)) # top bottom
self.padding2 = nn.ZeroPad2d((0, 0, 0, 1)) # bottom
self.relu = nn.ReLU()
self.fc = nn.Linear(args.filter_num, label_num)
def forward(self, x):
# region embedding 层
# 输入x的维度为(batch_size, max_len)
x = self.embedding(x) # [batch_size, seq_length, embedding_dim]
x = x.view(x.size(0), 1, x.size(1), self.args.embedding_dim) # [(]batch_size, 1, seq_length, embedding_dim]
x = self.conv_region(x) # x = [batch_size, num_filters, seq_len-3+1, 1]
# 等长卷积层
x = self.padding1(x) # [batch_size, num_filters, seq_len, 1]
x = self.relu(x)
x = self.conv(x) # [batch_size, num_filters, seq_len-3+1, 1]
x = self.padding1(x) # [batch_size, num_filters, seq_len, 1]
x = self.relu(x)
x = self.conv(x) # [batch_size, num_filters, seq_len-3+1, 1]
# block结构
while x.size()[2] >= 2:
x = self._block(x) # [batch_size, num_filters,1,1]
x = x.squeeze() # [batch_size, num_filters]
# 全连接+输出
loggits = self.fc(x) # [batch_size, 1]
return loggits
def _block(self, x):
x = self.padding2(x)
px = self.max_pool(x)
x = self.padding1(px)
x = F.relu(x)
x = self.conv(x)
x = self.padding1(x)
x = F.relu(x)
x = self.conv(x)
x = x + px # Short Cut
return x
5.实验结果
5.1 Large data results
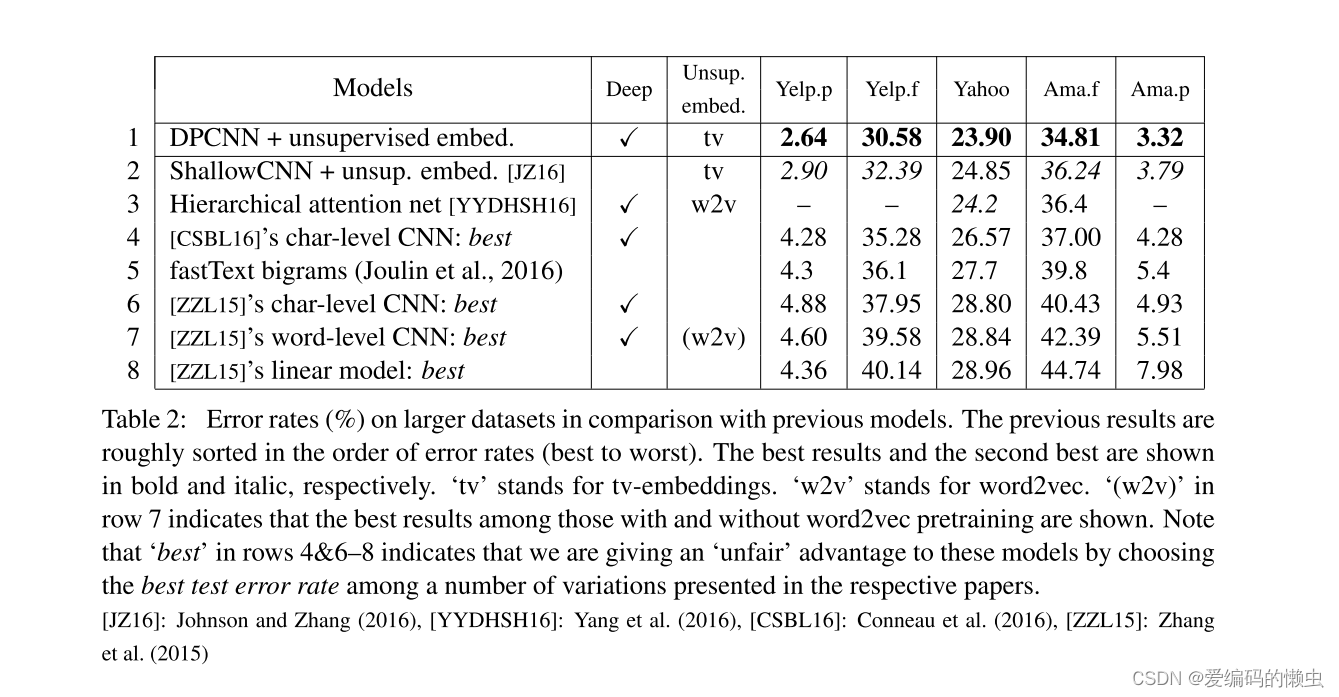
我们首先报告我们的完整模型(具有 15 个权重层的 DPCNN 加上无监督嵌入)在较大的 5 个数据集上的错误率(表 2)。 前面的结果大致按照错误率从最好到最差的顺序排序。 在所有五个数据集上,DPCNN 都优于之前的所有结果,这验证了我们方法的有效性。
5.2 Computation time

在图 2 中,我们绘制了错误率与计算时间的关系——计算时间是使用我们在 GPU 上实现对 10K 文档进行分类所花费的时间。 右图是左图 x ∈ [0, 20] 的特写。 从左图中可以看出(Conneau et al., 2016)的字符级 CNN 比 DPCNN 慢得多。 部分原因是它通过下采样增加了特征图的数量(即无金字塔),同时它更深(32 个权重层),部分原因是它处理字符——每个文档中的字符比单词多。DPCNN 比 ShallowCNN 更准确,但由于深度而需要更多的计算时间(15 层与 1 层)。 尽管如此,它们的计算时间是相当的——两者的点都在同一范围内 [0, 20]。 DPCNN 的效率是由于在特征图数量固定的情况下进行下采样,导致每层计算量呈指数下降。
5.3 与非金字塔变体的比较

第一个模型在每隔一次下采样时将特征图的数量加倍,以便每层计算保持大致恒定4。 第二个模型不执行下采样。 除此之外,这两个模型与 DPCNN 相同。 我们在图 3 中显示了这两种变体(分别标记为“增加特征图”和“无下采样”)与 DPCNN 的错误率。 x 轴是计算时间,以对 10K 文档进行分类所花费的秒数来衡量。 对于所有类型,显示深度为 11 和 15 的模型。 显然,DPCNN 比其他模型更准确且计算速度更快。 图 3 位于 Yelp.f 上,我们在其他四个大型数据集上观察到相同的性能趋势。
5.4 Small data results
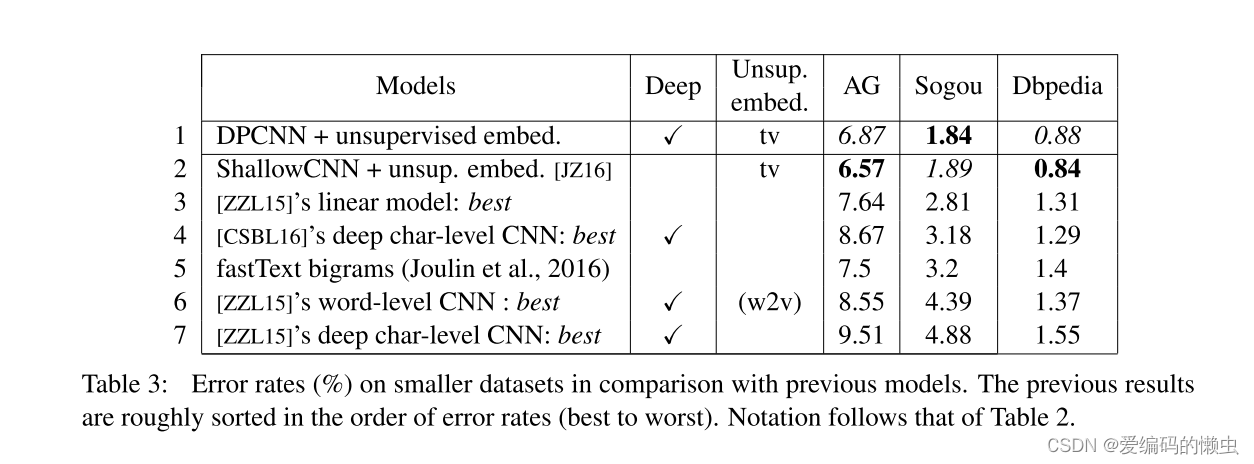
表 3 中三个较小数据集的结果。同样,之前的模型从最好到最差进行了粗略排序。 对于这些小数据集,显示了具有 100 维无监督嵌入的 DPCNN 性能,结果与具有 300 维无监督嵌入的 DPCNN 性能一样好。 与大型数据集结果的一个区别是浅层模型的优势非常突出。 ShallowCNN(第 2 行)与 DPCNN(第 1 行)竞争,Zhang 等人的最佳线性模型(第 3 行)从表现最差上升到第三。 结果符合这样一个普遍事实:更复杂的模型需要更多的训练数据,并且在训练数据较少的情况下,更简单的模型可以胜过更复杂的模型。
6. 总结
DPCNN模型的设计思想:设计一个词级别的深度CNN
- 词序信息在文本分类中很重要,RNN和CNN都能获得词序信息,但由于CNN更简单并且容易并行,所以DPCNN中使用CNN
- CNN研究中,浅层级别的CNN效果好于深度字级别的CNN,DPCNN中使用词级别作为输入
- CNN的词序信息有限,通过加深网络可以获得更大感受野,但是被证明加深网络词级别CNN性能反而下降。
DPCNN模型的创新点:
- 预训练的Region Embedding
- pre-activation shortcut connections
- 下采样不增加feature maps















 1045
1045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









