






目录
说明:
1.网上 Pytorch 自然语言处理中的相关代码普遍具有较高的相似程度和较难的理解程度,而本文针对自然语言处理中文本多分类的问题,提供了相对简洁易懂的 csv 代码版本,供大家进行学习和参考。
2.代码运行环境:google colab(GPU模式)
3.数据集:本项目使用的数据集是经过处理的以 csv 文件形式储存的的恶意评论多分类数据集。因此,以下代码均是以 csv 文件为基础进行处理的。
一、数据集 csv 文件导入
import numpy as np
import pandas as pd
from google.colab import drive
drive.mount('/content/drive')
csv_path = '/content/drive/MyDrive/train_test.csv'
df = pd.read_csv(csv_path)
df
二、将原始数据集划分为训练集和测试集
import pandas as pd
from sklearn.model_selection import train_test_split
def data_split(path, test_size=0.25, random_state=None):
# 取原始数据集第 1 列数据作为 x
x = df.iloc[:, 0]
# 取原始数据集第 2 列数据作为 y
y = df.iloc[:, 1]
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=test_size, random_state=random_state)
# 将 x 和 y 的训练集数据沿着列的方向拼接在一起
train_data = pd.concat([x_train, y_train], axis=1)
# 将 x 和 y 的测试集数据沿着列的方向拼接在一起
test_data = pd.concat([x_test, y_test], axis=1)
return train_data, test_data
train_data, test_data = data_split(csv_path, test_size=0.25, random_state=1234)
三、训练集和测试集评论预处理
import re
def tokenized(text):
# 1. 去除网址
clean_text = re.sub(r'http\S+|www\.\S+', ' ', text)
# 2. 去除@及其后面的内容
clean_text = re.sub('@\S+', ' ', clean_text)
# 3. 去除特定符号
clean_text = re.sub('[:=<>]', ' ', clean_text) # 根据需要添加其他符号
# 4. 提取文本内容中的所有中文字符;并将文本中所有非中文字符全部替换为空格
clean_text = re.sub('[^\u4e00-\u9fa5\n]', ' ', clean_text)
# 5. 替换行内多余的空格
clean_text = re.sub(r'\s+', ' ', clean_text)
# 6. 删除行首尾的空格
clean_text = re.sub(r'^\s+|\s+$', '', clean_text, flags=re.MULTILINE)
return clean_text
train_data['text'] = train_data['text'].apply(tokenized)
# 重新设置 train_data 的索引
train_data_reset_index = train_data.reset_index(drop=True)
test_data['text'] = test_data['text'].apply(tokenized)
# 重新设置 test_data 的索引
test_data_reset_index = test_data.reset_index(drop=True)
四、删除预处理后过短和过长的评论
from collections import Counter
# 定义返回符合删除条件的评论所在行索引的函数
def delete(data_reset_index):
# 查看数据集中每个评论里单词的数量,并存放到一个列表里
sentence_length = [len(sentence.split()) for sentence in data_reset_index['text']]
# 查找长度在 5 以下的评论的索引
below5_index = [i for i, length in enumerate(sentence_length) if length < 5]
# 查找长度在 1000 以上的评论的索引
above1000_index = [i for i, length in enumerate(sentence_length) if length > 1000]
# 将要删除的索引列表相加,形成一个新列表
return below5_index + above1000_index
# 删除指定索引的行,并更新训练数据集的标签数据
index_to_drop1 = delete(train_data_reset_index)
train_data_updated = train_data_reset_index.drop(index_to_drop1)
train_label_int_updated = np.array(train_data_updated['label'])
# 删除指定索引的行,并更新测试数据集的标签数据
index_to_drop2 = delete(test_data_reset_index)
test_data_updated = test_data_reset_index.drop(index_to_drop2)
test_label_int_updated = np.array(test_data_updated['label'])
五、创建词汇表与字典
5.1 将所有评论存放到一个列表里
# 定义评论转换列表函数
def text_to_list(data_updated):
train_data_reset_text = data_updated['text']
text_list = train_data_reset_text.tolist()
return text_list
train_text_list = text_to_list(train_data_updated)
print(len(train_text_list))
test_text_list = text_to_list(test_data_updated)
print(len(test_text_list))
# 运行结果,可以看到训练集与测试集的数据量
102773
34322
5.2 创建词汇表
import jieba
def vocab_build(train_text_list):
# 定义一个集合,来存储不同的单词
unique_words = set()
for text in train_text_list:
# 使用 jieba 进行中文分词 (注意:英文分词则代码要写成 words = text.split())
words = jieba.lcut(text)
# update 方法用于将新的单词添加到 unique_words 集合中
unique_words.update(words)
return unique_words
# 将训练集与测试集中的文本合并成一个列表
new_list = train_text_list + test_text_list
vocab = vocab_build(new_list)
vocab = list(vocab)
len(vocab)
# 运行结果,可以看到创建的词汇表中不同的单词个数
85886
5.3 创建字典:单词 → 索引
# 创建字典格式:(整数: 单词)
int_word_dict = dict(enumerate(vocab, 1))
# 转换字典格式:(单词: 整数)
word_int_dict = {w:int(i) for i,w in int_word_dict.items()}
六、将删除更新后的的评论转化为数字
# 定义评论映射函数
def text_to_int(textlist):
text_int_list = []
# 读取 textlist 列表中的每条评论
for sentence in textlist:
sample = list()
# 根据空格切分 sentence,这样就能读取到每一个单词
for word in sentence.split():
int_value = word_int_dict[word]
sample.append(int_value)
text_int_list.append(sample)
return text_int_list
# 将函数应用到训练集和测试集的数据中
train_text_int = text_to_int(train_text_list)
test_text_int = text_to_int(test_text_list)
七、将所有的评论长度固定到统一的大小
# 设定每条评论的固定长度是 500 个单词,单词数量不足的评论用 0 填充,超过的直接截断
# 定义评论长度固定函数
def reset_text(text, seq_len=500):
# 初始化一个全为 0 的矩阵,形状为 (评论数量 * 评论长度)
text_dataset = np.zeros((len(text), seq_len))
# 读取每一条评论的索引和内容
for index, sentence in enumerate(text):
# 如果评论长度小于 500,用 0 进行填充
if len(sentence) < seq_len:
text_dataset[index, :len(sentence)] = sentence
else:
# 如果评论长度大于 500,截断
text_dataset[index, :] = sentence[:seq_len]
return text_dataset
train_text_dataset = reset_text(train_text_int, seq_len=500)
test_text_dataset = reset_text(test_text_int, seq_len=500)
# 输出 train_text_dataset 和 test_text_dataset 的形状
print(train_text_dataset.shape)
print(test_text_dataset.shape)
# 运行结果
(102773, 500)
(34322, 500)
print(type(train_text_dataset))
print(train_label_int_updated.shape)
print(type(test_text_dataset))
print(test_label_int_updated.shape)
# 运行结果
# 可以看到 train_text_dataset 和 test_text_dataset 的类型
# 也可以看到 train_label_int_updated 和 test_label_int_updated 的形状
<class 'numpy.ndarray'>
(102773,)
<class 'numpy.ndarray'>
(34322,)
八、Pytorch 构建 Dataloader 加载并按批处理数据
import torch
from torch.utils.data import TensorDataset, DataLoader
from torchtext.data.functional import to_map_style_dataset
# 创建训练集和测试集中各自的评论张量和标签张量
# torch.Size([102773, 500])
train_text_tensor = torch.from_numpy(train_text_dataset)
# torch.Size([102773])
train_label_tensor = torch.from_numpy(train_label_int_updated)
# torch.Size([34322, 500])
test_text_tensor = torch.from_numpy(test_text_dataset)
# torch.Size([34322])
test_label_tensor = torch.from_numpy(test_label_int_updated)
# 对数据进行封装 (评论,标签)
train_dataset = TensorDataset(train_text_tensor, train_label_tensor)
test_dataset = TensorDataset(test_text_tensor, test_label_tensor)
batch_size = 64
# Dataloader在每一轮迭代结束后,重新生成索引并将其传入到 to_map_style_dataset 中,就能返回一个个样本
# shuffle=True 表示打乱样本顺序
# collate_fn 可以对 Dataloader 生成的 mini-batch 进行后处理
# pin_memory=True 表示使用 GPU
# drop_last=True 表示若最后数据量不足 64 个,则将其全部舍弃
train_loader = DataLoader(to_map_style_dataset(train_dataset), batch_size=batch_size, shuffle=True, drop_last=True)
test_loader = DataLoader(to_map_style_dataset(test_dataset), batch_size=batch_size, shuffle=True, drop_last=True)
# 打印第一个批次来查看结构
for batch in test_loader:
print(batch)
break
# 运行结果
[tensor([[ 3835., 23991., 43223., ..., 0., 0., 0.],
[27526., 64017., 32570., ..., 0., 0., 0.],
[61437., 41159., 83364., ..., 0., 0., 0.],
...,
[84234., 26553., 70366., ..., 0., 0., 0.],
[17595., 64017., 22429., ..., 0., 0., 0.],
[48351., 61453., 41750., ..., 0., 0., 0.]],
dtype=torch.float64),
tensor([0, 0, 4, 4, 2, 0, 4, 2, 0, 0, 1, 1, 0, 2, 1, 0, 4, 1, 0, 0, 0, 1, 4, 2,
3, 2, 4, 2, 3, 1, 0, 0, 4, 0, 3, 5, 4, 0, 4, 4, 4, 4, 0, 2, 4, 4, 4, 0,
0, 2, 5, 0, 4, 0, 4, 4, 0, 0, 4, 3, 2, 0, 0, 1])]
九、LSTM 模型定义
batch_size = 64
# 每个评论列表的大小
seqLen = 500
# 词汇表的大小加上 1
input_size = len(vocab) + 1
# 总共有6个类别
output_size = 6
embedding_size = 300
hidden_size = 128
# LSTM 层数
num_layers = 2
# 循环次数
num_epoch = 20
class Sentiment(torch.nn.Module):
def __init__(self, input_size, embedding_size, hidden_size, output_size, num_layers, dropout=0.5):
super(Sentiment, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers
# 将输入的文本进行词嵌入表示的操作
self.embedding = torch.nn.Embedding(input_size, embedding_size)
# LSTM 的输入维度就是 embedding_size,即 300。batch_first=True 表示将 batch_size 设置成第一个维度。bidirectional=True 表示设置 LSTM 模型为双向的
self.lstm = torch.nn.LSTM(embedding_size, hidden_size, num_layers, batch_first=True, bidirectional=True)
self.dropout = torch.nn.Dropout(dropout)
# 全连接层,其中 output_size 就是类别数量,即 6
self.linear = torch.nn.Linear(hidden_size * 2, output_size)
def forward(self, x):
'''
x original shape: (seqLen, batch_size, input_size)
x transform shape (batch_first=True) : (batch_size, seqLen, input_size)
batch_size:一组数据有多少个,即 64
seqLen:每个影评列表的大小,即 500
input_size:每个评论中每个数字的输入特征的维度
'''
batch_size = x.size(0)
# 将输入的影评转换为长整型,形状为 (batch_size, seqLen, input_size)
x = x.long()
# 1. 初始化隐藏层中的隐藏状态 h0 (用于传递序列中前一个时间点的信息到下一个时间点),同时将其转移到与输入影评相同的设备上 (即GPU)
# 2. h0 的形状为 (num_layers * 2, batch_size, hidden_size)
h0 = torch.zeros(self.num_layers * 2, batch_size, self.hidden_size).to(x.device)
# 1. 初始化隐藏层中的单元状态 c0 (用于在网络中长期传递信息),同时将其转移到与输入影评相同的设备上 (即GPU)
# 2. c0 的形状为 (num_layers * 2, batch_size, hidden_size)
c0 = torch.zeros(self.num_layers * 2, batch_size, self.hidden_size).to(x.device)
# 输出 x 的形状为 (batch_size, seqLen, embedding_size)
x = self.embedding(x)
# 1. 输出 output 的形状为 (batch_size, seqLen, hidden_size)
# 2. 输出 hn 的形状为 (num_layers * 2, batch_size, hidden_size)
# 3. 输出 cn 的形状为 (num_layers * 2, batch_size, hidden_size)
output, (hn, cn) = self.lstm(x, (h0, c0))
# 1. 选择最后一个时间步的输出
# 2. 输入 output 的形状变为 (batch_size, hidden_size)
# 3. 输出 output 的形状变为 (batch_size, output_size)
output = output[:, -1]
# 输出 output 的形状为 (batch_size, output_size),表示每个序列属于目标类别的概率
output = self.linear(output)
return output
# 创建模型
model = Sentiment(input_size, embedding_size, hidden_size, output_size, num_layers, dropout=0.5)
model.to(device)
output[:, -1] 代码解释:
假设我们有一个小批量的输出 output,其形状为(2, 3, 4),这表示我们有2个序列,每个序列有3个时间步,每个时间步的输出是一个4维的向量,如下图所示:

当执行 output[:, -1] 时,我们选择每个序列的最后一个时间步的输出,即每个序列的第3个时间步。这样,我们得到的结果如下图所示:
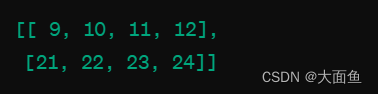
在我们这个例子中,output 的形状是 (64, 500, 128),这表示对于 64 个恶意评论,每个恶意评论有500个时间步(也即每个恶意评论列表中统一的单词数),每个时间步的输出是一个 128 维的向量。这个输出代表了 LSTM 网络在每个时间步对每个恶意评论的处理结果。
当执行 output[:, -1] 这个操作时,我们是在选择每个恶意评论的最后一个时间步的输出。这意味着从每个恶意评论中,我们只取出该序列经过 LSTM 处理后的最终状态,忽略之前所有时间步的输出。因此,对于 64 个恶意评论,每个恶意评论最终只对应一个 128 维的向量,这个向量概括了整个恶意评论的信息。
import torch.optim as optim
# 定义交叉熵损失函数
criterion = torch.nn.CrossEntropyLoss()
# 定义 Adam 优化器
optimizer = optim.Adam(model.parameters(), lr=0.01, weight_decay=1e-5)
十、测试与训练函数定义
def test(model, data_loader, device, criterion):
model.eval()
test_loss = 0
test_correct = 0
total = 0
# 测试函数无需梯度计算
with torch.no_grad():
for data, target in data_loader:
# 将 batch 中的每一对样本数据都传到 GPU 设备上
data, target = data.to(device), target.to(device)
# 获得输出结果
output = model(data)
# 计算损失
loss = criterion(output, target)
# 损失累加
test_loss += loss.item()
#在每一行找到最大概率的索引,这个索引即为模型的预测类别
pred = output.argmax(dim=1)
# 1. 将 pred 与 target 作比较
# 2. 例如,pred=[3, 2, 5, 0],target=[3, 2, 4, 0]
# 3. 则 (pred == target) = [True, True, False, True]
# 4. 那么就意味着有 3 个样本预测正确了,并累加预测正确的样本数量,即 3
test_correct += (pred == target).sum().item()
total += target.size(0)
# 计算评价损失和平均准确率
average_loss = test_loss / len(data_loader)
average_accuracy = test_correct / total * 100
return average_loss, average_accuracy
def train(model, device, train_loader, test_loader, criterion, optimizer, num_epoch):
for epoch in range(num_epoch):
model.train()
train_loss = 0
train_correct = 0
total = 0
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_loss += loss.item()
pred = output.argmax(dim=1)
train_correct += (pred == target).sum().item()
total += target.size(0)
train_accuracy = train_correct / total * 100
# 在每个 epoch 中后调用测试模型返回的结果,以计算测试损失和测试准确率
test_loss, test_accuracy = test(model, test_loader, device, criterion)
print(f'Epoch: {epoch+1}/{num_epoch} | '
f'Train Loss: {train_loss / len(train_loader):.5f} | '
f'Train Accuracy: {train_accuracy:.2f}% | '
f'Test Loss: {test_loss:.5f} | '
f'Test Accuracy: {test_accuracy:.2f}%')
train(model, device, train_loader, test_loader, criterion, optimizer, num_epoch)
# 运行结果
Epoch: 1/20 | Train Loss: 1.13465 | Train Accuracy: 56.78% | Test Loss: 0.52180 | Test Accuracy: 81.61%
Epoch: 2/20 | Train Loss: 0.47561 | Train Accuracy: 82.42% | Test Loss: 0.45031 | Test Accuracy: 83.07%
Epoch: 3/20 | Train Loss: 0.42417 | Train Accuracy: 83.48% | Test Loss: 0.42681 | Test Accuracy: 83.54%
Epoch: 4/20 | Train Loss: 0.39456 | Train Accuracy: 84.11% | Test Loss: 0.40082 | Test Accuracy: 84.31%
Epoch: 5/20 | Train Loss: 0.37064 | Train Accuracy: 84.60% | Test Loss: 0.40056 | Test Accuracy: 84.12%
Epoch: 6/20 | Train Loss: 0.34796 | Train Accuracy: 85.05% | Test Loss: 0.37667 | Test Accuracy: 85.01%
Epoch: 7/20 | Train Loss: 0.33346 | Train Accuracy: 85.38% | Test Loss: 0.38841 | Test Accuracy: 84.42%
Epoch: 8/20 | Train Loss: 0.32330 | Train Accuracy: 85.55% | Test Loss: 0.36889 | Test Accuracy: 85.17%
Epoch: 9/20 | Train Loss: 0.31073 | Train Accuracy: 85.78% | Test Loss: 0.36134 | Test Accuracy: 85.26%
Epoch: 10/20 | Train Loss: 0.31008 | Train Accuracy: 85.81% | Test Loss: 0.37652 | Test Accuracy: 84.54%
Epoch: 11/20 | Train Loss: 0.30182 | Train Accuracy: 85.96% | Test Loss: 0.36001 | Test Accuracy: 85.19%
Epoch: 12/20 | Train Loss: 0.30273 | Train Accuracy: 85.90% | Test Loss: 0.35754 | Test Accuracy: 85.28%
Epoch: 13/20 | Train Loss: 0.29926 | Train Accuracy: 86.02% | Test Loss: 0.35608 | Test Accuracy: 85.21%
Epoch: 14/20 | Train Loss: 0.29657 | Train Accuracy: 85.97% | Test Loss: 0.37081 | Test Accuracy: 84.76%
Epoch: 15/20 | Train Loss: 0.30007 | Train Accuracy: 85.95% | Test Loss: 0.35090 | Test Accuracy: 85.29%
Epoch: 16/20 | Train Loss: 0.29613 | Train Accuracy: 86.04% | Test Loss: 0.35479 | Test Accuracy: 85.30%
Epoch: 17/20 | Train Loss: 0.29722 | Train Accuracy: 86.06% | Test Loss: 0.35326 | Test Accuracy: 85.16%
Epoch: 18/20 | Train Loss: 0.29108 | Train Accuracy: 86.17% | Test Loss: 0.35978 | Test Accuracy: 85.34%
Epoch: 19/20 | Train Loss: 0.29494 | Train Accuracy: 86.05% | Test Loss: 0.35597 | Test Accuracy: 85.01%
Epoch: 20/20 | Train Loss: 0.29320 | Train Accuracy: 86.10% | Test Loss: 0.35220 | Test Accuracy: 85.35%

















 308
308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









