






This is a very beginner-friendly article ^o^
目录
QAT(Quantization Aware Training)量化感知训练:
值得一看的文件(有详细的参数讲解,包括nvida的cuda配置方法):
EIQ 工具包用户指南 - NXP (readkong.com)第21页起
第十七届智能车竞赛智能视觉组eIQ教程--逐飞科技 (qq.com)
成功安装后文件夹自带文件:eIQ_Toolkit——>docs——>eIQ_Toolkit_UG.pdf
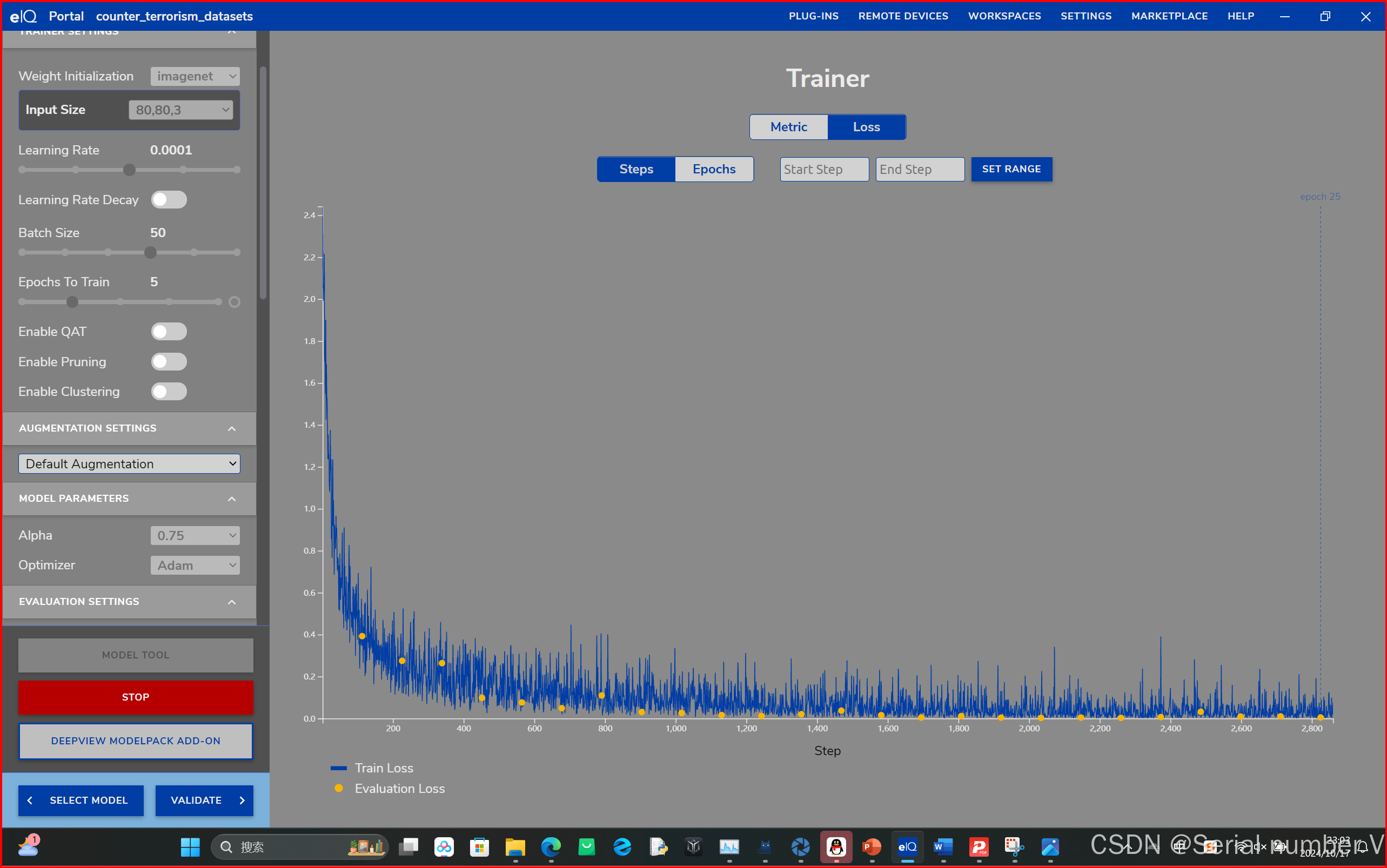
🍂一、训练器设置
input size:
指输入到模型的尺寸,以(高度,宽度,通道数)的形式表示,模型在训练时所有图像要调整到一致的大小
选择的Input Size要与数据集的图片大小相近
learning rate:
指在每次迭代更新模型参数时,调整权重的步长大小。高学习率:参数更新步长较大,收敛速度快,可能导致错过最优解或训练过程不稳定;低学习率:参数更新步长较小,更可能找到全局最优解,但训练过程慢,可能会陷入局部最优解
learning rate decay:
学习率衰减目的是在训练初期保持较高的学习率,以加快收敛速度,在后期降低学习率,从而使模型能逼近全局最优解
Epochs:
设置调整学习率的轮数
Decay Rate:
决定学习率衰减速度的快慢,Decay Rate越大学习率下降越快,在指数衰减时:新学习率=初学习率 * e^( - decay rate * epoch )
Linear Decay:
学习率按线性规律减少
Batch Size:
设置处理样本的数量。对于有许多非常相似的图像的数据集来说,较大的批次更有可能更快地达到较高的准确率。对于较小的数据集和图像不相似的数据集,较小的批次规模可能会更快达到较高的准确率。
Epochs to Train:
整个数据集被处理的次数(可理解为模型对整个数据集进行一次全面学习),如果数据集大小为10000个样本,批次大小batch size为100,那么一次epoch包含100次Iteration(每处理一批数据的次数)。多个Epochs:单次遍历数据集不足以让模型充分学习到数据的特征,通过多个Epochs模型能不断调整参数,逼近最佳权重值;过多Epochs可能导致过拟合:过拟合指模型在训练数据上表现很好,但在新数据(测试集)上表现较差
通过增加该值(整个训练数据集中的训练次数),模型权重有更多机会学习到需要提取的重要特征。如果使用过多的epochs,训练可能会导致模型过度拟合训练数据集
QAT(Quantization Aware Training)量化感知训练:
指将模型参数和计算从浮点(32-bit)降低精度到整型(8-bit),使模型简化,计算速度快,但精度下降
Pruning剪枝:
移除模型中不重要的权重、神经元或整个过滤器,以减少模型大小和计算量
Clustering聚类:
将相似的权重值聚集在一起共享权重,从而减少模型参数

🍂二、关于图像增强的设置
见开头链接,官方说明更加详细
垂直翻转谨慎选择(若不会出现就不选择)
🍂三、模型参数
Alpha权重更新比率:
Alpha 是一个乘数,会影响模型各层滤波器的数量
Optimizer优化器:
优化器是一种数学公式,应用于权重时,可以在尽可能少的调整中找到最佳权重。可使用以下优化器(Adam、Nadam 和 Adamax常用):
-
随机梯度下降(Stochastic Gradient Descent, SGD):
- SGD是一种优化算法,通过在每次迭代中只使用一个样本或一小批样本来更新模型的权重,从而快速训练模型。当模型远离理想状态时,SGD能够迅速调整权重。
-
Adagrad:
- Adagrad在计算权重调整方向时与SGD类似,但它在调整权重时考虑了之前所有更新的累积大小,这意味着它会自动调整学习率,对于频繁更新的权重,其学习率会减小。
-
Adadelta:
- Adadelta是Adagrad的扩展,它只保留过去一定数量的更新历史,而不是全部。这使得算法更加高效,并且能够适应不断变化的优化景观。
-
均方根传播(Root Mean Square Propagation, RMSprop):
- RMSprop在计算权重调整方向时与SGD类似,但它对每个权重参数分别进行调整,有助于减少在单一轴上的振荡。在几乎所有情况下,RMSprop的表现都优于Adagrad和SGD。
-
自适应移动估计(Adaptive Movement Estimation, Adam):
- Adam结合了Adagrad和RMSprop的优点,通过累积过去调整的平均值来评估下一次调整。在几乎所有情况下,Adam的表现都优于SGD和Adagrad,而在大多数情况下优于RMSprop。它结合了Adagrad的快速梯度下降和RMSprop的振荡抑制学习率。
-
Adamax:
- Adamax是Adam优化器的泛化版本,使用无穷范数。模型越简单(参数越少),这个优化器越精确。在小模型中,Adamax的表现可能优于Adam,而在大型模型中,Adamax和Adam的表现相似,因此可以作为可选的替代方案。
-
Nesterov-加速自适应移动估计(Nesterov-accelerated Adaptive Movement Estimation, Nadam):
- Nadam结合了Adam优化器和Nesterov加速梯度技术,这使得下一次调整的计算似乎是在当前调整趋势再继续一步的情况下进行的。
经验之谈:如果发现使用Adam收敛速度过快,担心陷入局部最优解,不妨试试SGD吧 !!!
🍂四、推荐的设置(简单的模型)
• Imagenet weight initialization
• Input size of 128, 128, 3
• Learning rate of 0.0001
• Batch size of 50
• Alpha of 0.75
• Adam Optimizer
如果(经过一段时间的训练后)这些设置的精确度太低,可以逐步增加input size和Alpha,以获得理想的结果。如果(经过一段时间的训练后)推理时间过长,可以逐步减少input size和 Alpha。
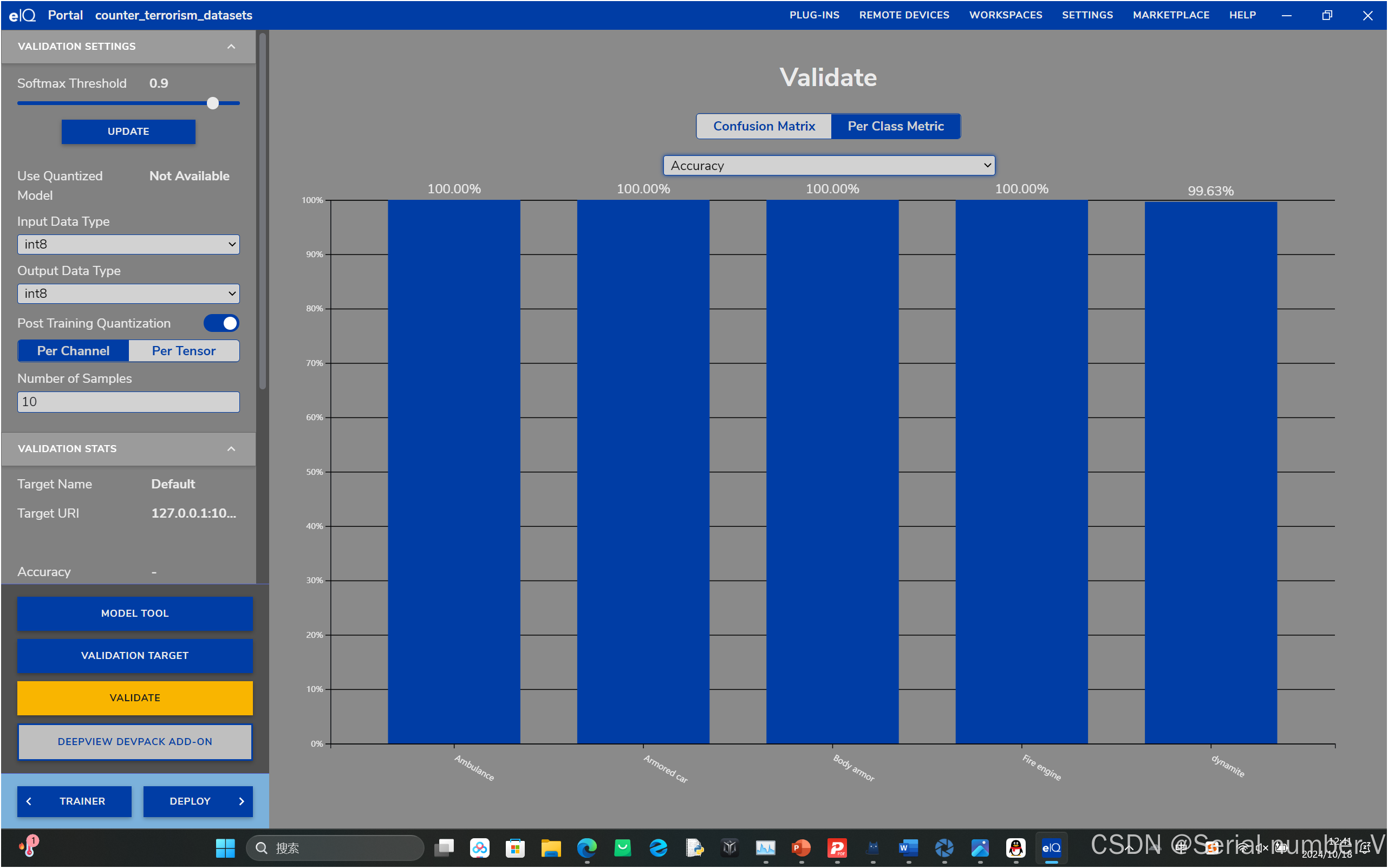
eIQ的小bug
注意:eIQ有的时候在验证时会一直卡在加载提示,解决办法:点击验证(VALIDATE)后,要等待一段时间5~10秒左右,待UI所有的东西都加载好再点击即可,不然训练半天的模型可就废了
🍂五、分析Loss曲线
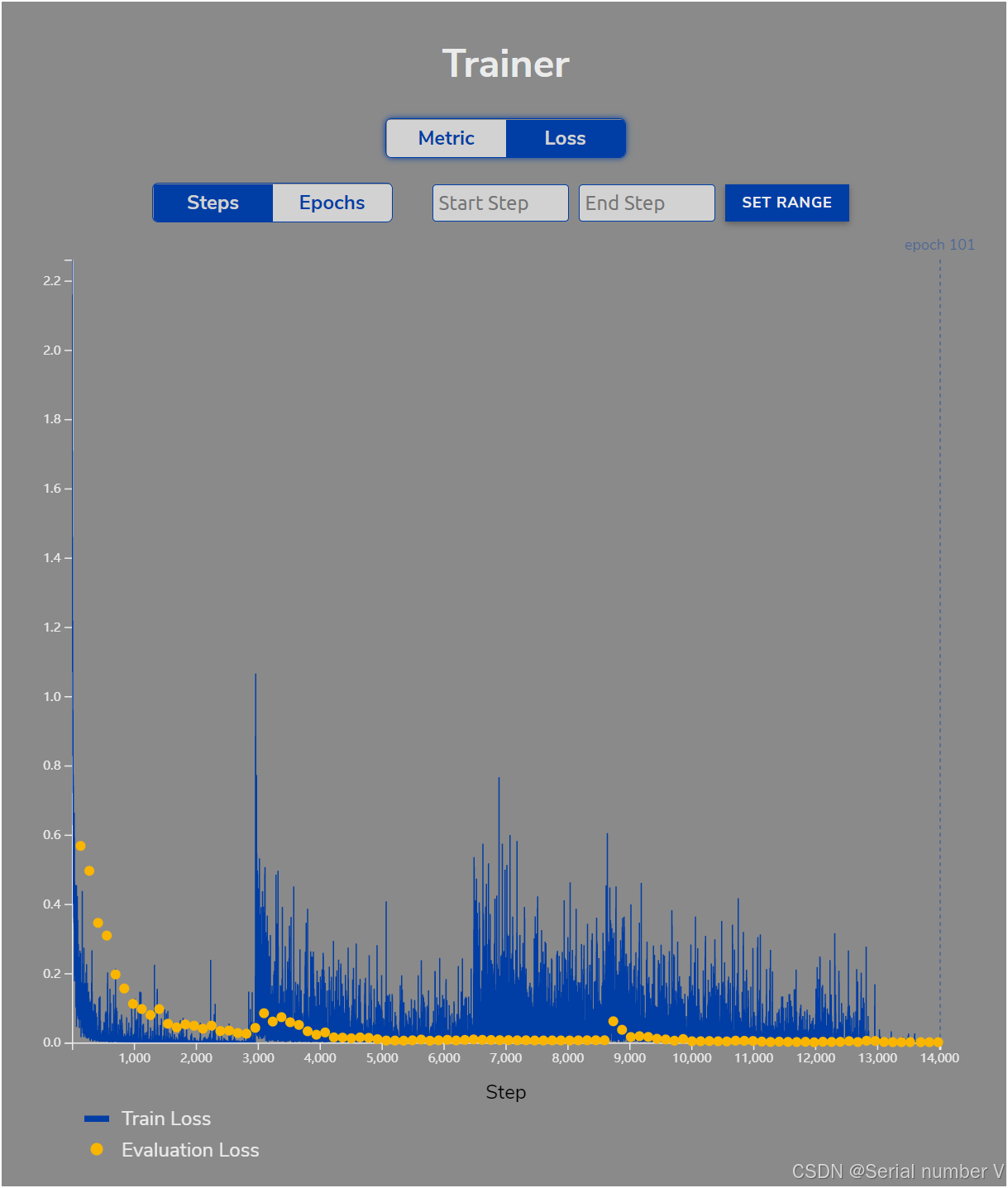
①概念
训练集Loss曲线
想象一下,你正在教一个小朋友学习数学。训练集Loss曲线就像是你给小朋友出的一系列数学题,每做一道题,你都会检查他的答案是否正确,并记录下来他的错误数量。这个错误数量,就是我们说的Loss(损失)。随着你不断出题,小朋友的错误数量会逐渐减少,因为你在不断地教他,他也在不断地学习。
- 下降趋势:如果这个错误数量一直在减少,说明小朋友在进步,你的教学方法是有效的。
- 停滞不前:如果错误数量突然不再减少,可能说明小朋友遇到了难题,需要你换一种教学方法或者更详细地解释。
- 波动很大:如果错误数量忽高忽低,可能说明小朋友对某些类型的题目掌握得不好,或者他可能有些分心。
测试集Loss曲线
现在,我们换个场景,想象一下小朋友已经学了一段时间的数学,你想测试一下他的真实水平。于是你给他一套全新的题目,这套题目他之前没有做过,这就是测试集。测试集Loss曲线记录的就是小朋友在这些新题目上的错误数量。
- 与训练集Loss比较:如果测试集上的错误数量比训练集上的要高很多,那就像小朋友在家里做得很好,但在学校考试时却考得不好。这可能是因为他只是机械地记住了你出的题目,而没有真正理解数学概念(过拟合)。
- 稳定下降:如果测试集的错误数量也在逐渐减少,并且和训练集的错误数量差不多,那说明小朋友真的掌握了数学知识,能够解决新的问题(良好的泛化能力)。
- 突然上升:如果测试集的错误数量突然增加,可能是因为小朋友在某些他没有遇到过的题目类型上遇到了困难,或者他可能在测试时感到紧张。
总的来说,训练集Loss曲线告诉我们模型在已知数据上的表现,而测试集Loss曲线则告诉我们模型在新数据上的表现。两者结合起来,就能帮助我们判断模型是否真正学会了我们想要它学习的东西,以及它在面对新情况时的表现如何。
②分析
如何通过分析训练集和测试集的Loss曲线来判断学习率,decay rate,Batch size,epochs to train, Alpha(权重更新比率)这些参数的设置是否合理?
1. 学习率(Learning Rate)
• 学习率过高:Loss曲线剧烈波动,无法收敛(训练和测试Loss都不稳定),表明模型每次更新步长过大,难以找到最佳解。
• 学习率过低:两条loss 曲线会平稳下降,但下降非常缓慢,收敛速度较低,最终可能在一个较高的 loss 值处停止, loss 曲线也可能过早停滞,表明模型学习效率低,未充分训练,也难以找到最佳解。
• 合理的学习率:训练集的 loss 曲线平稳下降,并在一定 epochs 后逐渐趋于稳定。测试集的 loss 曲线在训练过程中同步下降,最终保持平稳。
分析方法:
• 如果训练和测试集 loss 曲线波动过大,考虑降低学习率。
• 如果训练和测试集 loss 曲线下降缓慢,考虑增加学习率。
2. Epochs to Train(训练轮次)
• Epochs 过少:训练集的 loss 曲线会在明显下降阶段突然停止,表明模型尚未完成学习。测试集的 loss 曲线可能没有完全下降,模型没有充分训练。
• Epochs 过多:训练集的 loss 可能继续下降,甚至达到非常低的值,而测试集的 loss 曲线开始上升,表明模型开始过拟合,即在训练数据上表现很好,但在测试数据上泛化能力不足。
分析方法:
• 如果测试集的 loss 随训练轮次增加而上升,说明模型可能过拟合,应该减少 epochs 或使用早停法(在测试集Loss不再降低时停止训练)。
• 如果训练和测试集的 loss 曲线均未达到稳定,应考虑增加 epochs。
3. Decay Rate(学习率衰减率)
• Decay Rate 过高:学习率下降得太快,训练集 loss 曲线的下降速率会逐渐变慢,可能提前停止收敛。测试集的 loss 曲线也可能在一定程度下降后停滞,表明模型未能充分学习。
• Decay Rate 过低:学习率下降得太慢,训练集的 loss 曲线可能呈现急剧下降的趋势,但后期表现出抖动或者不稳定。测试集的 loss 曲线也可能在后期呈现不规则的波动。
分析方法:
• 如果训练和测试集的 loss 曲线在前期下降明显,但后期停滞,考虑减缓衰减速率。
• 如果曲线在后期不再稳定,且学习较慢,考虑加快衰减。
4. Batch Size(批次大小)
• Batch Size 过小:训练集的 loss 曲线会有较大的波动,因为小批次带来的噪声影响较大。测试集的 loss 曲线也可能波动较大,训练过程不稳定。
• Batch Size 过大:训练集的 loss 曲线会非常平滑,但训练速度可能较慢,并且模型容易陷入局部最优解。测试集的 loss 曲线也可能较早达到平稳状态,可能没有很好地学习到数据中的变异性。
如果batch size较小,可适当增大学习率以弥补。
分析方法:
• 如果曲线波动大且不稳定,可以增大批次大小。
• 如果曲线下降缓慢且训练时间长,考虑减小批次大小。
5. Alpha(权重更新比率)
• Alpha 过大:更新步长过大,导致训练损失震荡,甚至发散。
• Alpha 过小:更新速度太慢,损失下降缓慢,需要更多 epoch。
6. 训练集和测试集 Loss 曲线的分析原则
• 训练集 loss 持续下降,测试集 loss 稳定:这表示模型在训练过程中表现良好,参数设置较为合理。
• 训练集 loss 下降,测试集 loss 上升:这表明模型可能过拟合,需要调整正则化、减少训练轮次、或者增加数据。
• 训练集和测试集 loss 曲线都下降很慢:表明学习率太低,或模型容量不足,可以增加学习率或使用更复杂的模型。
7.验证集 Loss 出现波动或过拟合时
- 增加更激进的增强,如旋转、剪切、噪声等。
- 如果增强后的验证集 Loss 持续上升,说明增强过度,此时应适当减少。
总结:
• 学习率影响曲线的整体下降速度和波动。
• Epochs 决定训练何时结束,过少可能训练不足,过多可能导致过拟合。
• Decay Rate 控制学习率的衰减速度,影响后期收敛情况。
• Batch Size影响曲线的平滑度和噪声。
• Alpha 控制模型的复杂度,避免过拟合。
| 观察到的现象 | 可能原因 | 调整策略 |
| 训练和测试Loss都不稳定、波动较大、无法收敛 | 更新步长过大、小批次训练的噪声影响较大、Decay Rate 过低 | 降低学习率、增大Batch Size、增大Decay Rate、降低Alpha |
| 两条loss 曲线非常缓慢平稳下降,收敛速度低,最终在一个较高的 loss 值处停止 | 模型未完全学习、Decay Rate 过高 | 加大学习率、降低Decay Rate |
| 训练 Loss 和验证 Loss 均快速下降,但停滞(较早达到平稳状态) | 学习率过大,跳过了最优解、陷入局部最优解、Decay Rate 过高 | 减小学习率(使用学习率衰减策略)、降低Batch Size、降低Decay Rate |
| 训练集的 loss 下降,甚至达到非常低的值,而测试集的 loss 曲线开始上升 | 过拟合 | 停止训练、增加更激进的增强,如旋转、剪切、噪声等 |
③放弃模型
当你观察到训练集和测试集的Loss曲线出现以下状态时,通常意味着你应该放弃当前模型并重新训练:
-
过拟合:训练集Loss持续降低,但测试集Loss在达到某个点后开始上升。这表明模型在训练集上学习得太好了,以至于开始记住噪声和不相关的细节,而没有从数据中学习到泛化的模式。这时,模型在新数据上的表现会很差。
-
欠拟合:如果训练集和测试集的Loss都很高,并且训练集Loss下降缓慢,这通常意味着模型太简单,无法捕捉数据的基本结构,即模型欠拟合了。解决欠拟合的方法可能包括增加模型复杂度、增加训练数据、特征工程或调整模型参数。
-
Loss曲线震荡:如果Loss曲线出现剧烈震荡,可能是因为学习率设置不当、模型结构问题、数据预处理不当或数据中存在噪声。可以尝试调整学习率、改进模型结构、清洗数据或使用更复杂的优化算法。
-
Loss曲线平坦:如果Loss曲线在很短的时间内变得平坦,可能是因为模型学习能力太强而数据集太简单,或者batch size过大导致模型过早收敛。
-
Loss曲线上升:如果训练集和测试集的Loss都持续上升,可能是因为模型结构设计不当、数据预处理问题或学习率过高。
在这些情况下,你可能需要重新考虑模型的选择、结构、超参数设置,或者可能需要更多的数据来训练模型。此外,使用早停(Early Stopping)策略可以帮助避免过拟合,通过在验证集Loss不再改善时停止训练来保存模型的最佳状态。早停法是一种有效的正则化方法,可以防止模型在训练过程中对数据过度拟合
🍂六、eIQ的其他常用UI介绍
若对某个epoch之后的loss曲线不满意,其实不需要重新开始训练
step1:点击SELECT MODEL
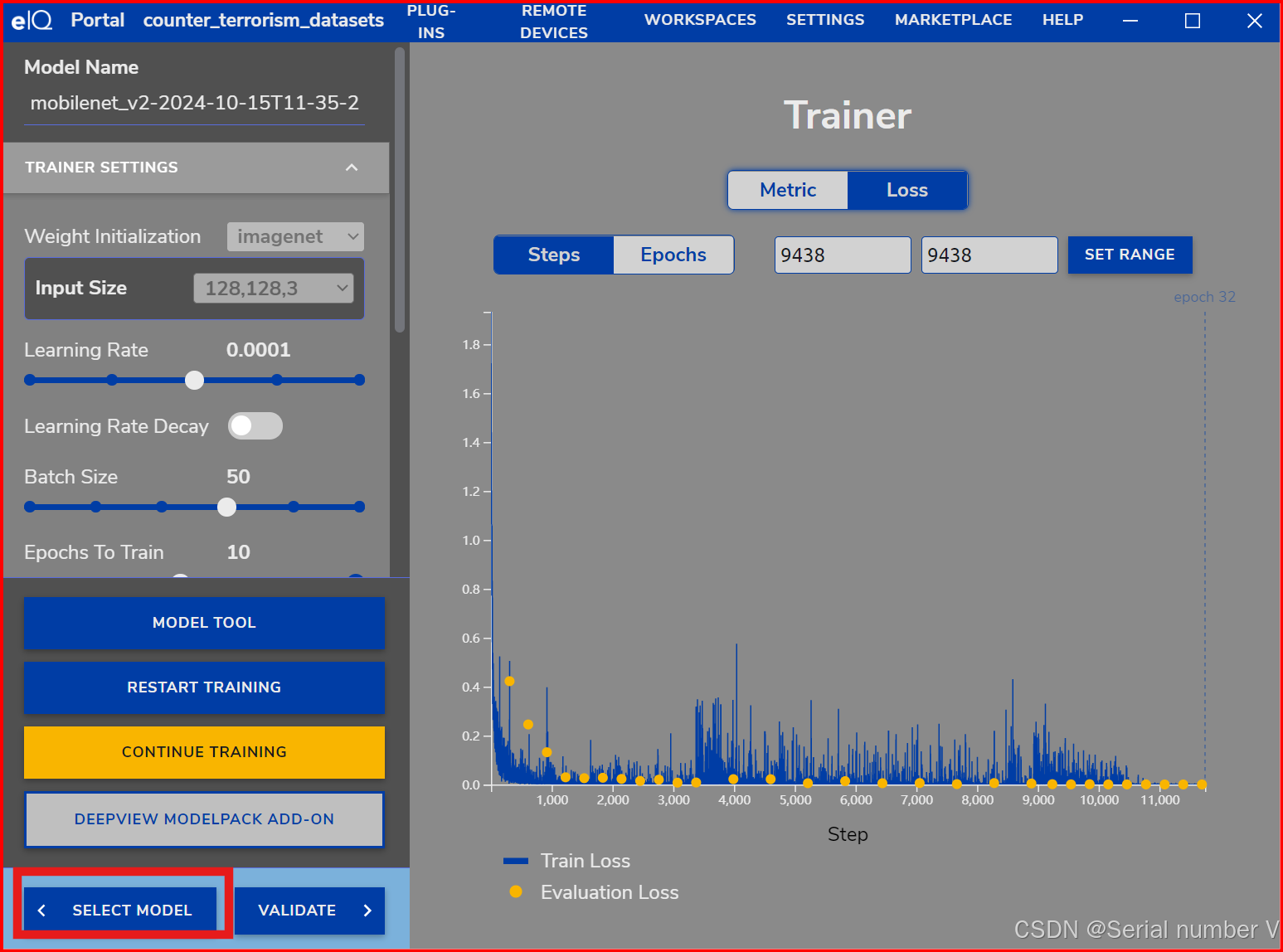
step2:点击RESTORE MODEL 
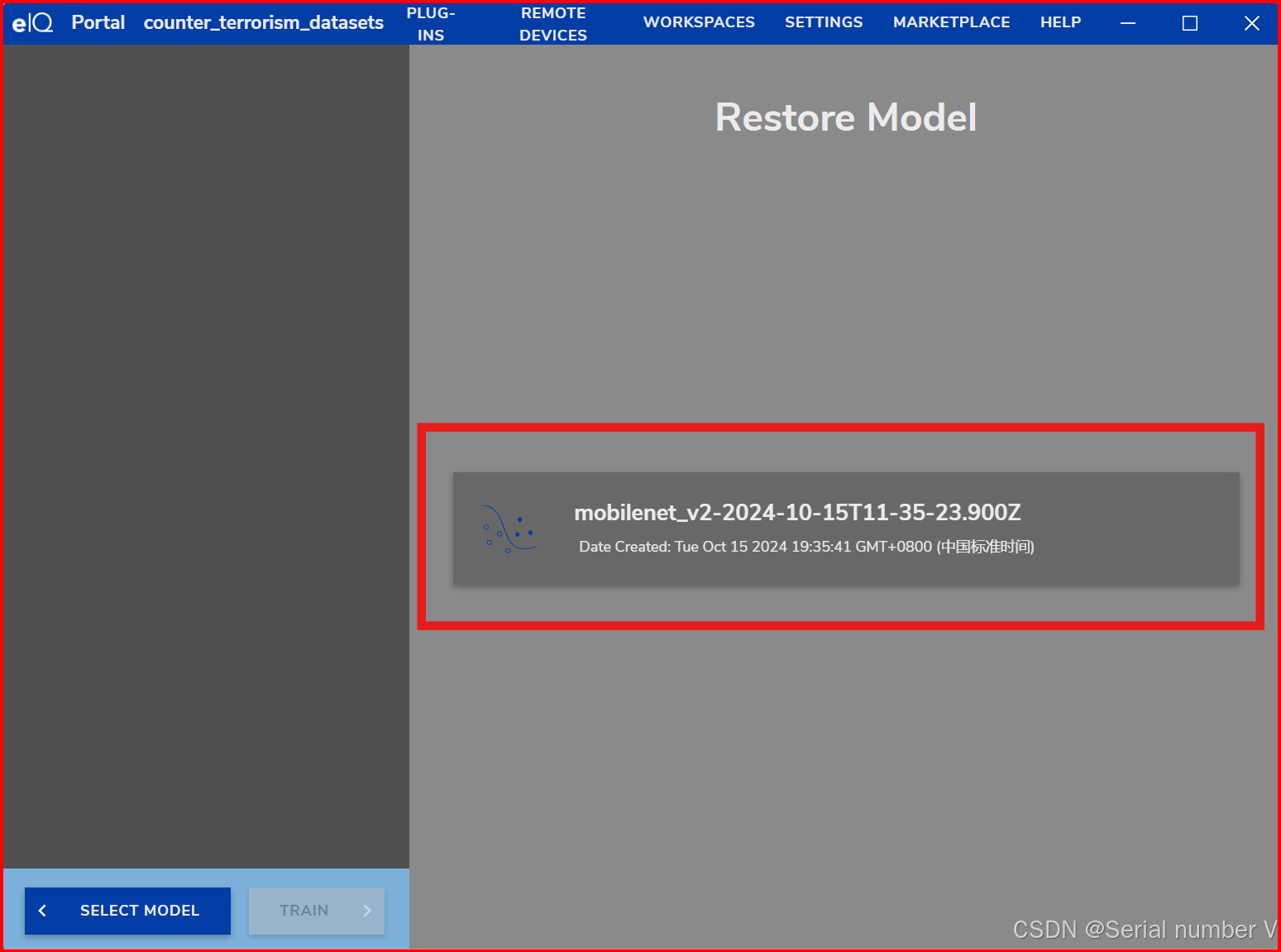
step3:选择刚才训练的模型
step4:选择要返回的epoch
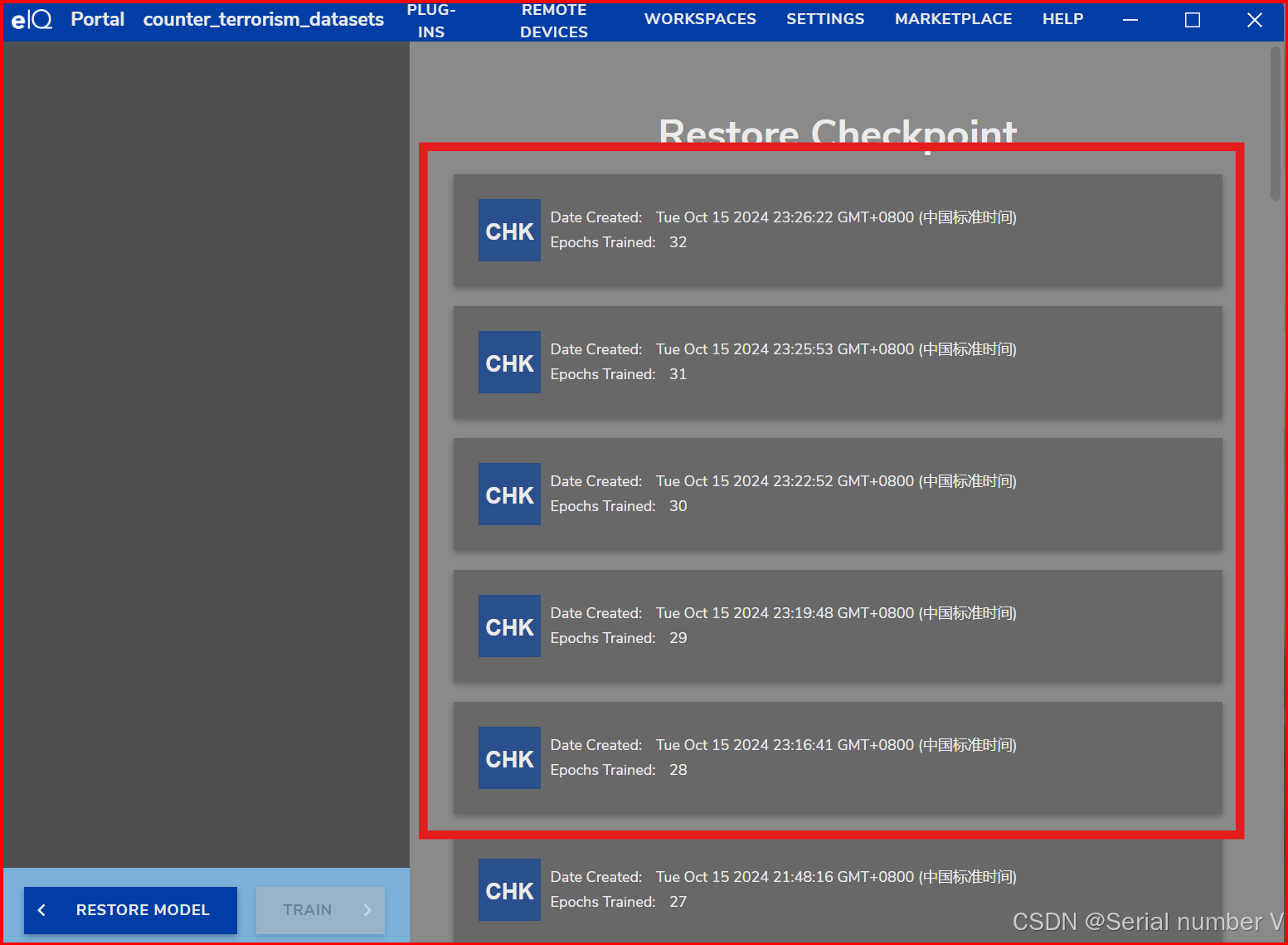
可以看到模型从第32个epoch回到了第31个epoch
🍂七、OpenART的部署例程
1、常用的方法
像素设置
sensor.set_framesize(sensor.QVGA) #正常配置
sensor.set_framesize(sensor.VGA) #献祭帧率换清晰度
sensor.set_framesize(sensor.QQVGA) #献祭清晰度换帧率模型加载
net = tf.load(net_path, load_to_fb=True) # 加载模型True:模型将被加载到帧缓冲区,这在处理图像时特别有用,因为可以更快地获取图像数据并减少内存使用。
畸变校正
img = sensor.snapshot().lens_corr(1.5)
lens_corr(1.5):对这张图像进行镜头畸变校正。1.5 是畸变校正的系数。
- 畸变校正的强度,范围通常在 1.0 到 2.0 之间。
- 数值越高,校正越强,但过高可能会导致图像失真或不自然。
模型应用
for obj in tf.classify(net, img, min_scale=1.0, scale_mul=0.5, x_overlap=0.0, y_overlap=0.0):
print(obj.rect, obj.label, obj.confidence)完整参数:
tf.classify(model, img, roi=(x, y, w, h), min_scale=1.0, scale_mul=0.5, x_overlap=0.0, y_overlap=0.0)
tf.classify 函数是 TensorFlow 的一个函数,用于在图像上运行目标检测模型,并返回检测到的对象列表。这个函数通常用于图像识别任务,比如识别图像中的物体并给出它们的类别。
参数的意义如下:
net:这是加载的 TensorFlow 模型,用于对输入图像进行推理。img:这是待检测的输入图像。min_scale:这是检测的最小尺度,值在 0 到 1 之间,1 表示 100% 的图像尺寸。较小的值会检测更小的物体,但可能会增加误检率。
通俗来说,想象你有一个放大镜,min_scale 就像你用放大镜看图像时的最小放大倍数。如果min_scale设为1.0,就意味着你会用最大倍数的放大镜去看图像,这样可以更容易看到图像中的小细节。但如果设得更小,比如0.5,就意味着你会用一个缩小的放大镜去看图像,这样你一次能看到更大的范围,但细节就没那么清楚了。
scale_mul:这是每次图像尺度变化的乘数。例如,如果scale_mul=0.8,则每次尺度变化都会缩小 20%。
通俗来说,通过调整scale_mul,你可以决定模型在检测时应该更关注细节(小视野),还是更关注整体(大视野)。调小scale_mul:模型会在更多的小尺度上进行检测,有助于捕捉小物体,但可能增加计算量;调大scale_mul:模型会在较少的大尺度上进行检测,有助于快速检测大物体,但可能错过小物体,并且计算量可能减少。
x_overlap和y_overlap:这两个参数控制滑动窗口检测时的重叠比例。值为 0 表示没有重叠,值接近 1 表示高度重叠。这有助于在图像的不同位置进行多次检测。
通俗来说,假设你要把一张大照片切成几个小方块来看,x_overlap 就是指这些小方块在水平方向(x轴)上的重叠部分。如果x_overlap设为0,就意味着这些小方块完全不重叠;如果设得更高,比如0.5,就意味着每个小方块有一半是重叠的。重叠的好处是可以更细致地检查重叠区域的物体,减少漏检 。 y_overlap同理
返回值的意义: tf.classify 函数返回一个迭代器,迭代器中的每个项目都是一个检测到的对象。每个对象通常包含以下信息:
label:对象的类别标签。confidence:模型对检测到的对象属于其类别的置信度。
加载标签
sorted_list = sorted(zip(labels, obj.output()), key = lambda x: x[1], reverse = True)上述代码涉及到lambda匿名函数、内置函数zip等高级用法,此处不进行详细解释
总而言之,这行代码的作用是:将标签和对应的输出值配对,然后根据输出值进行降序排序,最后返回一个包含这些配对且排序后的列表。这在机器学习中常用于获取模型预测的最可能的类别及其置信度。
2、多目标检测中存在的问题
在多目标检测时,我遇到了单个识别率很高但同时有多个物品出现在镜头时就会混乱的情况
现象为:A和B同时出现在镜头,但是输出几乎都为AA,很少出现AB,BB,BA的情况,我尝试用img1、img2、img3……等来接收img的copy值,发现并没有用,然后又采样了状态机的方法在识别后重装模型,进行下一次识别,也没有用……
参考以下文章后,知道了问题出现的原因,采纳建议后问题有所改善:
openMV使用---多目标检测_openmv多目标识别-CSDN博客
问题在于:使用copy方法无法根据roi切割出目标的图片



上图为伪代码,左下图为img,右下图为用copy()方法得出的img1
所以,出现上述现象的原因是img1里包含了A和B两个对象,和一开始设想的img1里只包含A或B不一样,而A的置信度大多时候都高于B,所以模型大多时候只对A进行识别
解决办法:
而我的解决办法是每进行一次检测之前调用一次img = sensor.snapshot(),在检测其中一个对象时,将其他对象用于背景颜色接近的方块遮住,来模拟多目标识别
🍂八、尝试使用云端进行在线训练
由于eIQ Portal对于电脑配置要求较高,且难以调用GPU训练,以及存在诸多bug等问题,我尝试寻找其他简单友好的方法来训练模型
网站链接(需要科学上网):
灵感来源于:
通过云端自动生成openmv的神经网络模型,进行目标检测_openmv可以上传至云端吗-CSDN博客
Openmv通过IMPULSE训练模型实现目标检测_openmv模型训练网站-CSDN博客
可以参考以下教程学习:
Wio Terminal 中文教程 | 深度学习-part4 EdgeImpulse训练神经网络_哔哩哔哩_bilibili
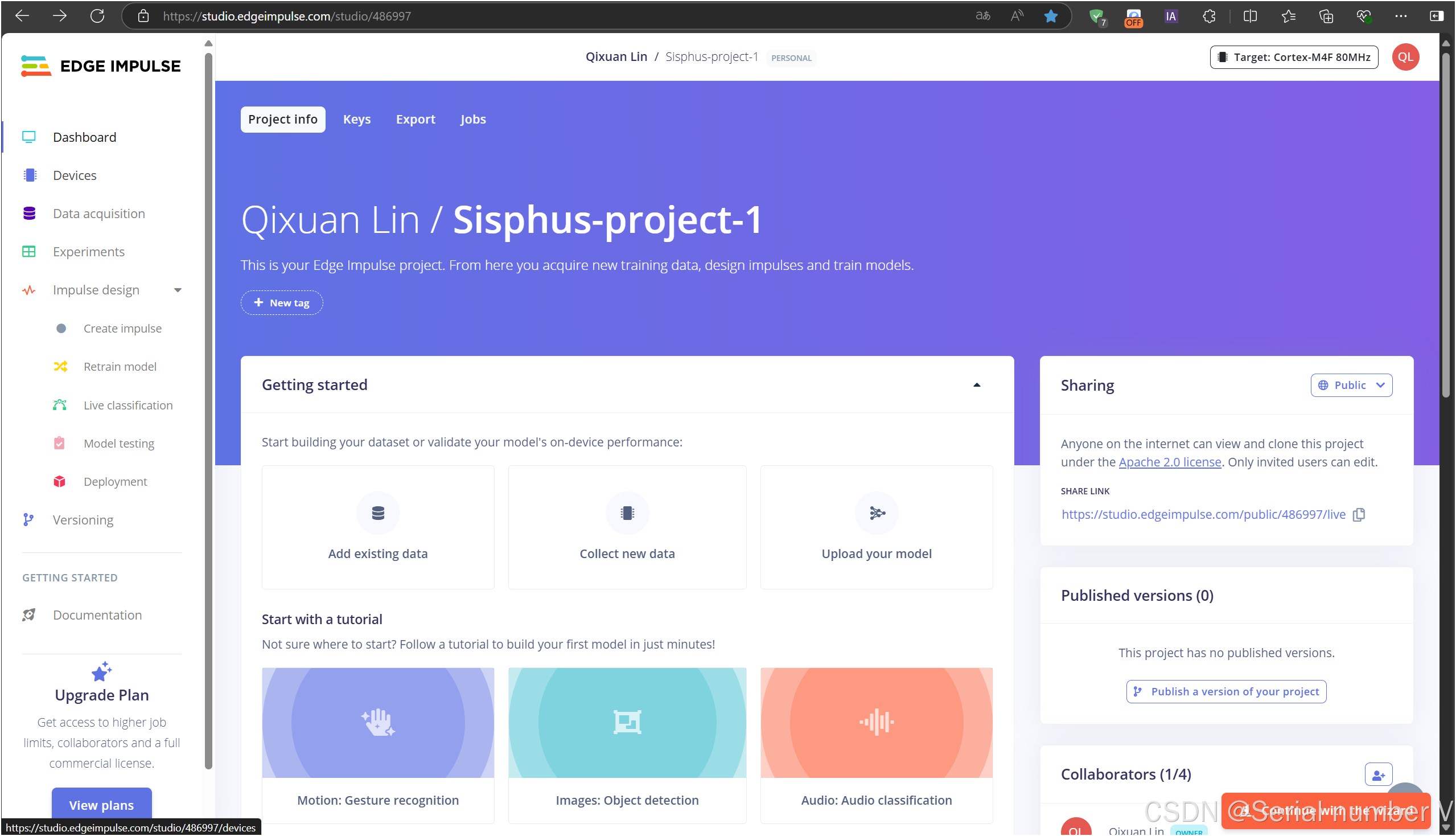
使用edge impulse平台,也能导出tflite类型的文件以及标签,所以我打算在线训练模型,并尝试部署在OpenART上
令人惊喜的是edge impluse支持的边缘计算平台十分广大(包括OpenMV,树莓派,Jetson,英飞凌、Arduino等)
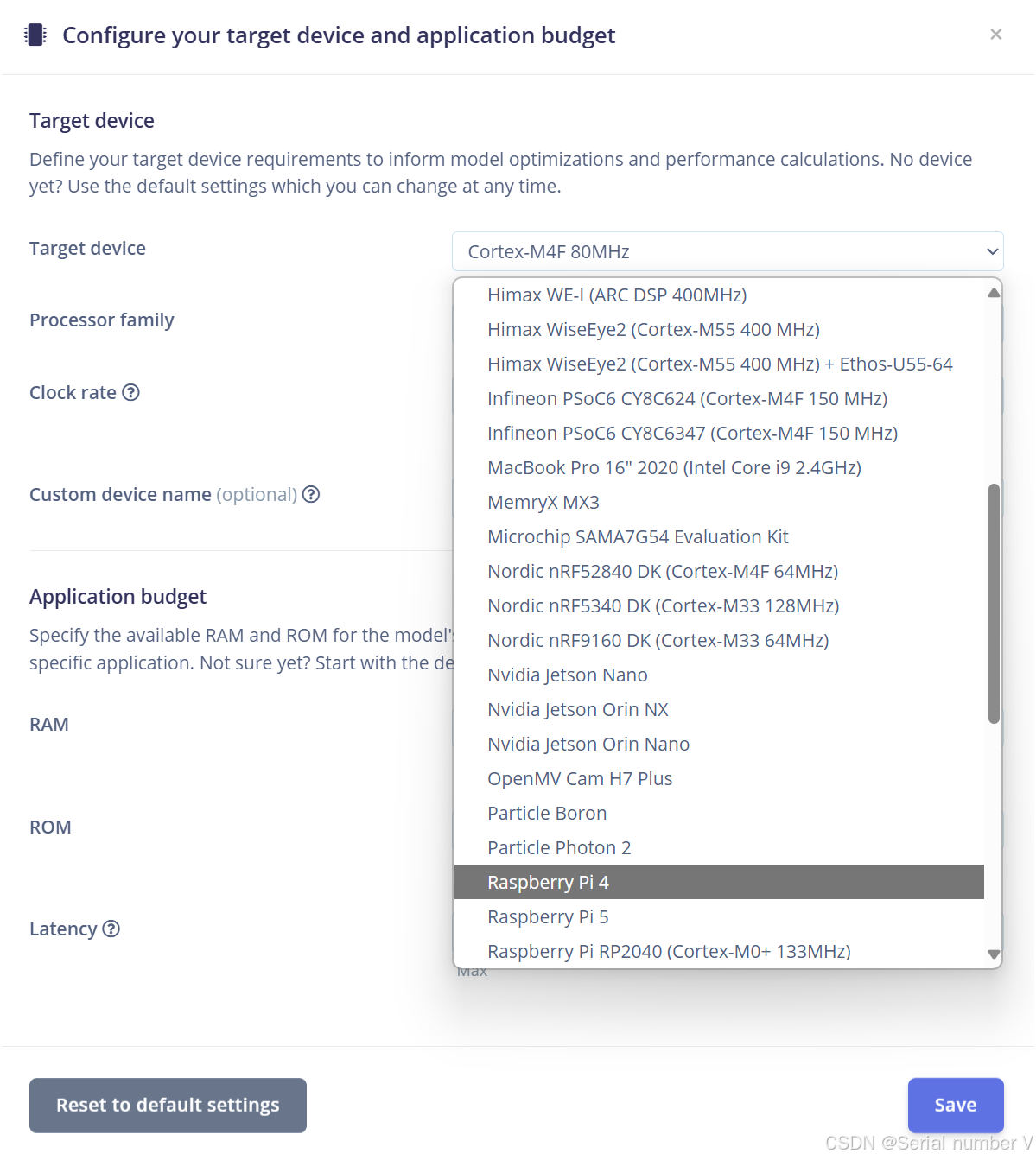
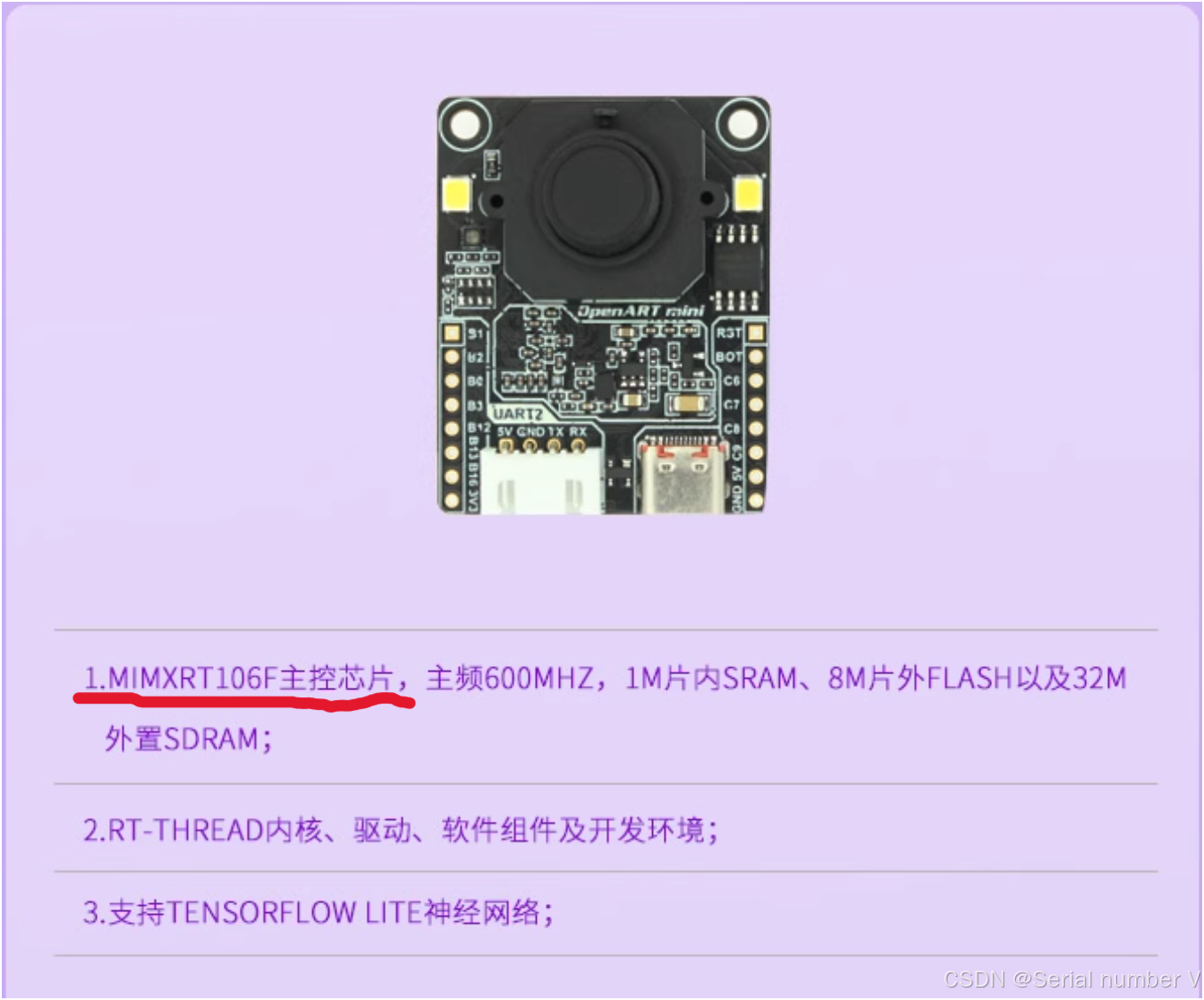
但是我没能找到openart上的主控芯片,所以我打算选择OpenMV Cam H7 Plus代替
图片上传方便
🔚九、结语
博文到此结束,写得模糊或者有误之处,欢迎小伙伴留言讨论与批评



















 287
287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











