






 本文详细介绍了人工智能的三大核心概念——人工智能、机器学习和深度学习,包括它们的定义、原理和应用。同时探讨了学习方法,如基于规则和模型的学习,以及机器学习在生活中的广泛应用和历史发展。文章还涵盖了机器学习的常用术语、建模流程和关键要素——数据、算法和算力。
本文详细介绍了人工智能的三大核心概念——人工智能、机器学习和深度学习,包括它们的定义、原理和应用。同时探讨了学习方法,如基于规则和模型的学习,以及机器学习在生活中的广泛应用和历史发展。文章还涵盖了机器学习的常用术语、建模流程和关键要素——数据、算法和算力。
一.人工智能三大概念
1.人工智能(AI)
研究行为具有智能的计算代理的合成和分析的领域
人工智能(Artificial Intelligenc)即AI。是计算机科学的一个分支,旨在开发和应用能够模拟、延伸和扩展人类智能的理论、方法和技术,包括机器人、语言识别、图像识别、自然语言处理、专家系统等。
人工智能的研究领域十分广泛,它试图了解智能的实质,并生产出一种能以人类智能相似的方式做出反应的智能机器。这些机器和系统被设计为能够执行通常需要人类智能的任务,如学习、推理、理解语言、识别图像等。它们通过学习和优化,逐渐提高自己的性能,以更好地适应各种复杂环境和任务。
2.机器学习(ML)
赋予计算机学习能力而无需显式编程的研究领域
机器学习(Machine Learning)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。它致力于研究计算机如何模拟或实现人类的学习行为,以获取新的知识或技能,并重新组织已有的知识结构以不断改善自身的性能。机器学习被视为人工智能的核心,是使计算机具有智能的根本途径。
机器学习是对研究问题进行模型假设,利用计算机从训练数据中学习得到模型参数,并最终对数据进行预测和分析的一门学科。机器学习算法通过构建一个基于样本数据的数学模型(称为“训练数据”),能够在没有明确编程来执行任务的情况下进行预测或决策。这些算法使得计算机系统能够有效地执行特定任务,依赖的是模式和推理,而不是明确的指令。
机器学习的用途广泛,是一种通用的数据处理技术,包含了大量的学习算法。不同的学习算法在不同的行业及应用中能够表现出不同的性能和优势。因此,机器学习在多个领域都有重要的应用,如自然语言处理、图像识别、语音识别、推荐系统等。
总的来说,机器学习是一个涉及多个学科领域的交叉学科,它通过模拟人类学习行为,使计算机系统能够自动地改进其性能,并应用于各种实际任务中。
3.深度学习(DL)
大脑仿生,设计一层一层的神经元模拟万事万物
深度学习(Deep Learning)也叫深度神经网络,是机器学习(Machine Learning)领域中一个新的研究方向,它的目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字、图像和声音等数据的解释有很大的帮助。
深度学习的原理主要是通过对大量样本的特征自学习来实现输入与输出之间的复杂函数逼近。其核心技术原理包括神经网络、反向传播算法、激活函数以及损失函数等。神经网络是深度学习的核心,它由输入层、隐藏层和输出层组成,每一层之间通过权重和偏置相连。当输入信号进入神经网络时,它会逐层前行,经过迭代修正,直至达到期望的输出值和效果。
深度学习在许多领域都有广泛的应用,如物体检测、人脸识别、自然语言处理、医学和生物信息学、自动驾驶以及金融领域等。在物体检测中,深度学习可以识别图像中的特定物体并标出其位置;在人脸识别中,它可以识别图像或视频中的人脸;在自然语言处理中,深度学习可以实现机器翻译、文本分类和语音识别等功能。
三者的关系可用下图来表示: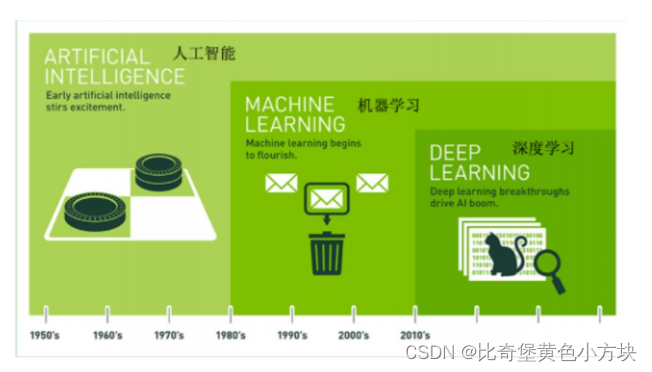
机器学习是实现人工智能的一种途径,深度学习是机器学习的一种方法。
二.如何学习
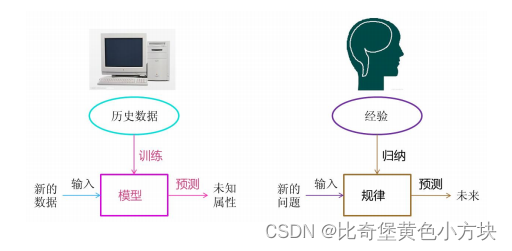
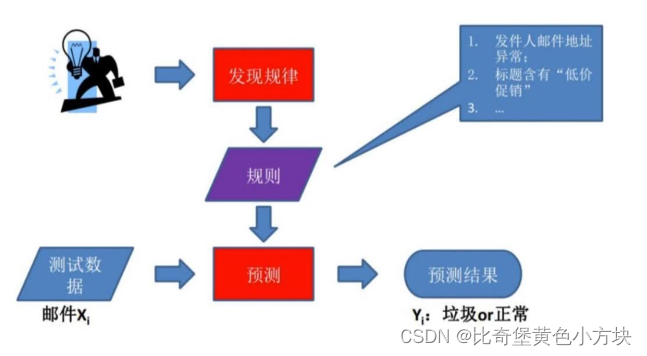
1.基于规则的学习
程序员根据经验利用手工的if-else方式进行预测
基于规则的学习(Rule-based Learning)是一种机器学习方法,其基本原理是通过定义一系列逻辑规则或条件来进行学习和推理。这些规则通常以“如果-那么”的形式表示,即如果某些条件满足,就执行相应的操作或推断。
基于规则的学习的过程包括以下步骤:
- 规则定义:人工定义一系列规则,每条规则由条件和结论组成。条件是关于输入数据或状态的描述,结论是根据条件满足程度进行的输出或行为。
- 规则学习:根据训练数据集或领域知识,学习和优化规则的条件和结论。这可以通过基于数据的方法(例如决策树学习)或专家系统中的知识工程技术来实现。
- 规则推理:将新的输入数据应用于已学习的规则集,根据条件判断和结论推断来产生输出或决策。
基于规则的学习在一些特定领域和任务中很有用,例如专家系统、诊断系统和决策支持系统等。它的优点是易于理解和解释,规则集可以根据需要进行调整和更新。然而,它也面临着规则膨胀、规则矛盾以及对领域知识依赖性强等挑战。
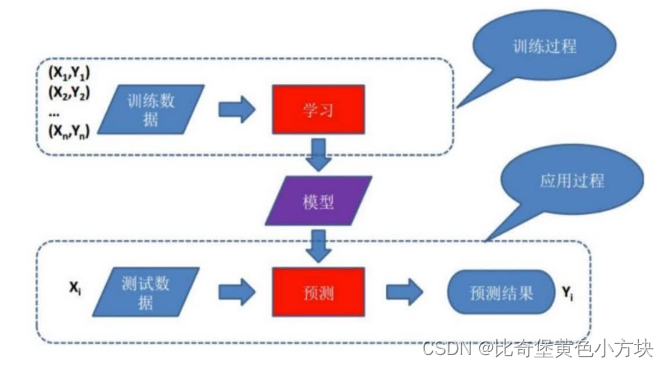
2.基于模型的学习
从数据中自动学出规律
有很多问题无法明确的写下规则,此时我们无法使用规则学习的方式来解决这一类问题,比如:图像和语音识别和自然语言处理 。这时候就要用到基于模型的学习这种学习方法。
基于模型的学习(Model-based Learning)是一种机器学习方法,其中模型被用来表示学习任务的基本结构和关系。在这种方法中,模型可以是数学模型、统计模型或者是其他形式的抽象模型,用来描述输入数据与输出数据之间的关系或者系统的动态行为。
基于模型的学习通常包括以下步骤:
-
模型定义:选择合适的模型来表示学习任务中的数据和变量之间的关系。常见的模型包括线性模型、非线性模型(如神经网络)、贝叶斯网络、隐马尔可夫模型等。
-
模型训练:使用训练数据集来拟合模型,即通过调整模型的参数或者学习模型的结构,使得模型能够最好地描述数据的特征和关系。这通常涉及最小化预测误差或者最大化模型的似然性。
-
模型评估:使用独立的测试数据集评估模型的性能,例如计算模型的预测准确率、均方误差等指标,以了解模型在未见数据上的泛化能力。
-
模型应用:将训练好的模型应用于新的输入数据,进行预测、分类、回归等任务。模型的输出可以用于支持决策、优化系统行为或者生成新的知识。
基于模型的学习适用于各种机器学习任务,包括监督学习、无监督学习和强化学习。它的优点是能够从数据中学习出潜在的模式和结构,具有较好的泛化能力和适应性。然而,模型的选择和训练过程可能需要领域知识和经验,并且对数据质量和模型参数的选择敏感。
二.机器学习的应用领域和发展史
1.应用领域
如今机器学习已经渗透进我们生活的各个方面,在生活中处处可见。
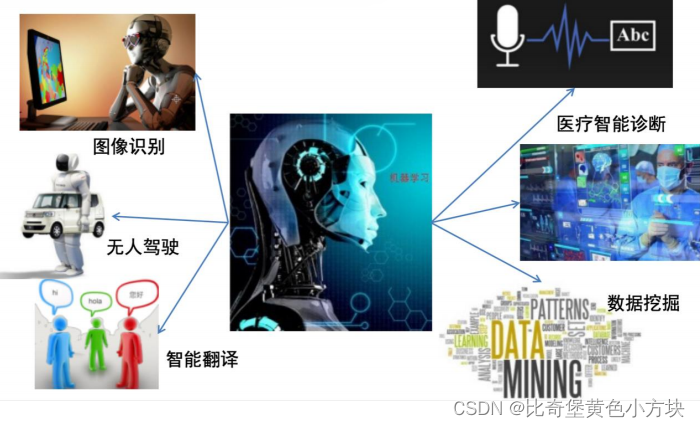
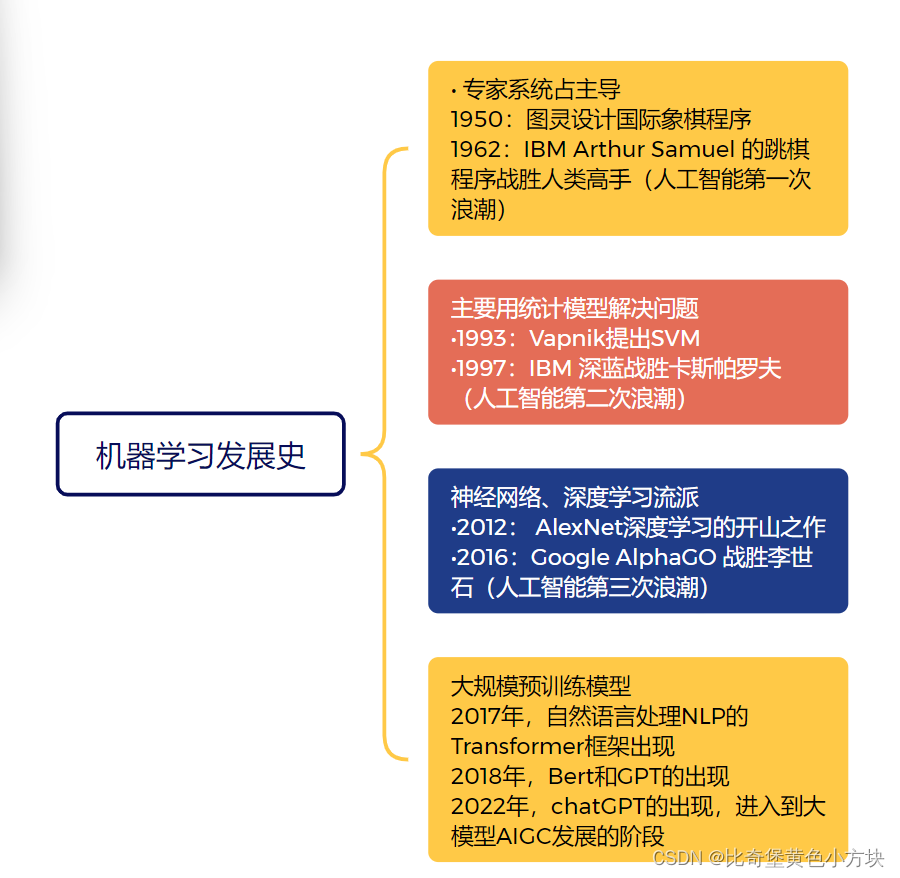
2.机器学习的发展史
3.人工智能发展三要素 :数据,算法,算力
(1)数据:数据是模型训练、评估和优化的基石。数据通常指的是一系列的观察或记录,它们可以包含多种信息,例如数字、文本、图像、声音等。这些数据通常被组织成特定的结构,以便机器学习算法能够有效地从中提取信息并学习出有用的模型。
(2)算法:算法是指一系列用于解决特定问题的计算步骤或方法。机器学习算法旨在从数据中学习并提取有用的信息或规律,以便能够对新的、未见过的数据进行预测或决策。机器学习算法通常可以分为几大类,包括监督学习、无监督学习、半监督学习和强化学习等。
(3)算力:算力是指计算机执行某些操作的能力,它衡量了计算机硬件和软件协同工作的效率,特别是在处理大规模数据集和执行复杂计算任务时的性能。算力通常用于描述计算机系统在单位时间内执行计算任务的能力,这包括执行算术逻辑操作的数量(如浮点运算)或处理指令的数量(如整数操作)。通俗的讲,算力越高,计算机处理数据的速度就越快,能够训练的模型也就越复杂,从而有可能实现更高的预测精度和更好的性能。
三.机器学习的常用术语
1.样本(sample),特征(feature),标签(label/target)
在我个人看来,样本就是在机器学习过程中所处理的单个数据或者是捆绑在一起的多个数据,而特征就是样本所拥有的特征,标签则是我们人为赋予一个类似于“名字”的东西,同样也是机器学习中要预测的部分。
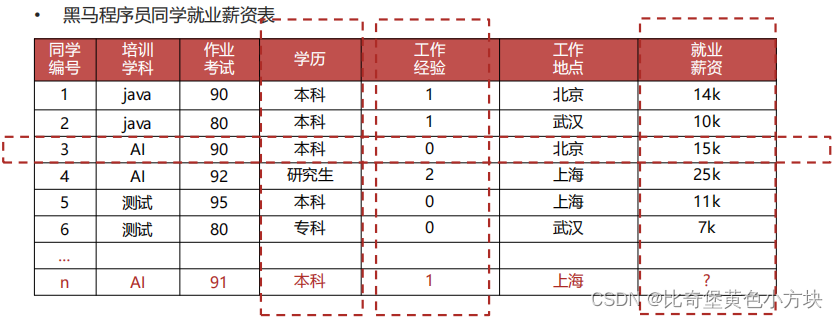
如图为例:
样本:1号同学这一行数据为一个样本,2号,3号等都为单个的样本
特征:培训学科,作业考试,学历,工作经验,工作地点都是样本的特征
标签:就业薪资,同样也是要预测的部分
2.数据集
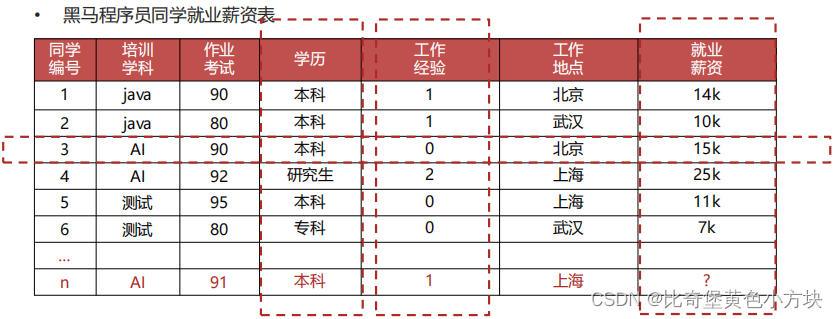
数据集就是样本的集合,通常数据集会被划分为两部分:训练集和测试集占比为8:2或7:3(有的也会划分为训练集,测试集和验证集)。
我习惯用data_train,data_test来表示训练集和测试集中样本的特征用label_train,label_test来表示它们的标签。
四.机器学习的算法
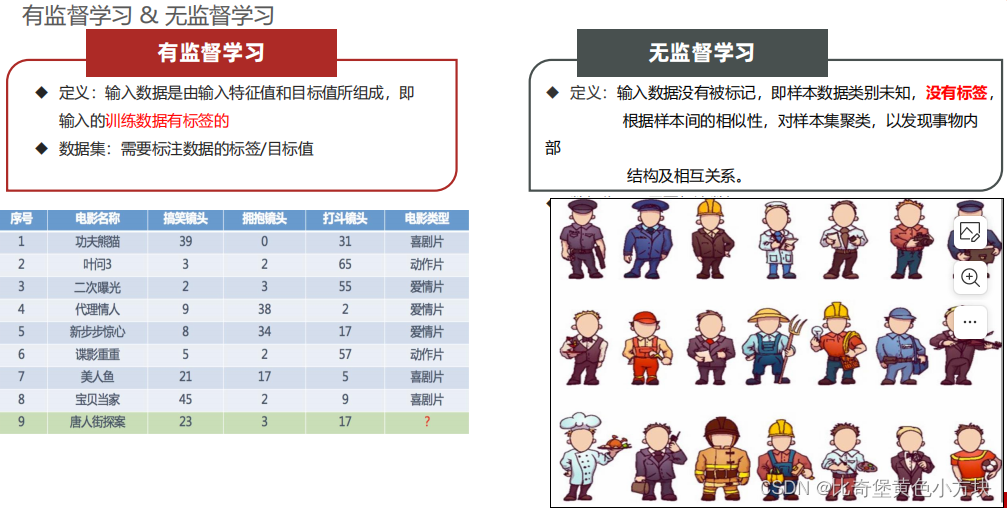
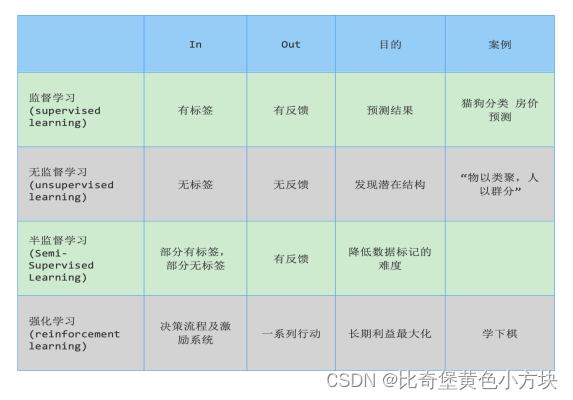
1.有监督学习
有监督学习就是指输入的数据都是带有标签的。
有监督学习的主要步骤包括:
-
数据准备:收集并整理标记好的数据集,其中每个样本都包含特征和对应的标签。
-
特征提取:从原始数据中提取有意义的特征,这些特征将用于训练模型。
-
模型选择:根据问题的性质和数据的特点选择合适的算法来构建模型。常见的有监督学习算法包括线性回归、逻辑回归、支持向量机(SVM)、决策树、随机森林和神经网络等。
-
模型训练:使用标记好的数据集来训练模型。在训练过程中,模型会学习从特征到标签的映射关系,并调整内部参数以最小化预测误差。
-
模型评估:使用验证集来评估模型的性能,检查模型是否过度拟合或欠拟合,并据此调整模型参数或选择其他算法。
-
预测与应用:一旦模型训练完成并通过评估,就可以将其应用于新的、未见过的数据,进行预测或分类。
有监督学习在许多领域都有广泛的应用,如图像识别、语音识别、自然语言处理、金融预测、医疗诊断等。随着技术的不断进步和算法的不断创新,有监督学习将在更多领域发挥重要作用。
2.无监督学习
与有监督学习相反输入的数据都没有标签,这意味着数据本身没有明确的预测目标或结果,模型需要通过学习数据本身的结构和特征来发现数据的内在规律和模式。
无监督学习的关键特点包括:
- 没有人为标签或目标:与有监督学习不同,无监督学习不依赖于任何人工干预的标签或目标。因此,它需要将数据转化为学习对象。
- 数据驱动:无监督学习强调数据驱动,即尽可能多地吸取数据相关信息,发现隐藏在数据内部的知识和规律,从而推导出规则和信息,提高算法和模型的效果。
- 自我学习能力:由于没有外部指导和参数限制,无监督学习具有一定自适应性和自我学习能力,能够根据数据的规律和内在特征进行精准建模。
无监督学习有多种应用场景,包括但不限于:
- 聚类:将数据点分组为具有相似性质的簇。
- 降维:减少数据的维数,使其更易于可视化和处理。
- 异常检测:识别数据集中的异常值或异常数据点。
无监督学习在计算机视觉、语音识别、自然语言处理和数据挖掘等领域有着广泛应用。例如,在图像聚类中,无监督学习算法可以将相似的图像自动分组;在异常检测中,它可以用于识别信用卡交易中的欺诈行为或网络流量中的恶意活动。
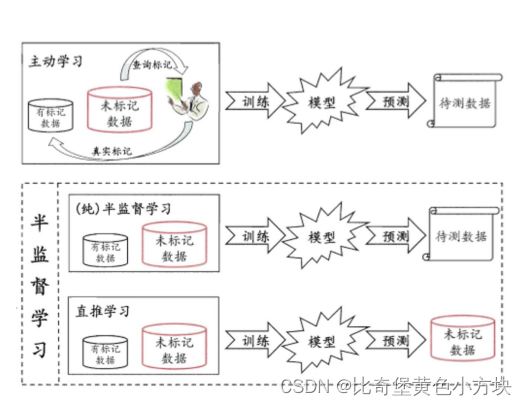
3.半监督学习
半监督学习(Semi-Supervised Learning,SSL)是机器学习领域的一个重要分支,它结合了监督学习与无监督学习的特点。半监督学习利用大量的未标记数据,同时也使用少量的标记数据来进行模式识别工作。
半监督学习的核心思想在于,它能够有效利用无标签数据的信息来提高学习器的泛化性能。在数据标注成本较高的情况下,半监督学习能够充分利用有限的标注信息,从而提高模型的性能。这种学习方法在多个领域都有广泛应用,如欺诈行为检测、医学图像分析、疾病诊断、自然语言处理、文本分类、情感分析、图像处理、图像分割、对象检测以及个性化推荐和信息过滤等。
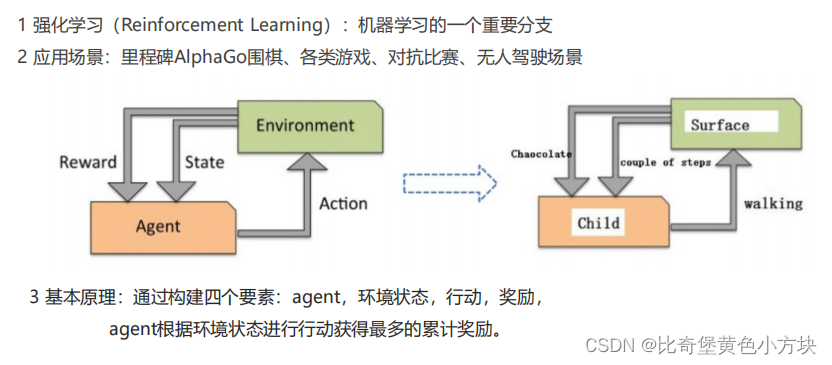
4.强化学习
强化学习(Reinforcement Learning,RL),又称再励学习、评价学习或增强学习,是机器学习的一种范式和方法论。它主要用于描述和解决智能体(agent)在与环境的交互过程中,通过学习策略以达成回报最大化或实现特定目标的问题。强化学习的常见模型是标准的马尔可夫决策过程(Markov Decision Process, MDP)。
强化学习的基本原理是,通过智能体与环境的不断交互,尝试和学习不同的行为,从而找到能够最大化长期回报的最优策略。在这个过程中,环境会对智能体的每一个动作给出反馈,通常是一个奖励或惩罚的信号,智能体则根据这些反馈来更新其策略。
强化学习可以分为多种类型,包括基于模式的强化学习(model-based RL)和无模式强化学习(model-free RL),以及主动强化学习(active RL)和被动强化学习(passive RL)。此外,强化学习还有多种变体,如逆向强化学习、阶层强化学习和部分可观测系统的强化学习等。
用一张图来总结一下
五.机器学习建模流程
机器学习建模的一般步骤:
1.获取数据:搜集与完善相关任务的数据集
2.数据基本处理:对数据集中异常值,缺失值等进行处理
3.特征工程:对数据特征进行提取、转成向量,让模型达到最好的效果
4.模型训练:选择合适的算法对模型进行训练根据不同的任务来选中不同的算法;有监督学 习,无监督学习,半监督学习,强化学习
5.模型评估:评估效果好上线服务,评估效果不好则重复上述步骤
















 1761
1761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









