






一、朴素贝叶斯算法概述
朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理的简单概率分类算法,以其高效、易于实现的特点在文本分类、垃圾邮件过滤等领域广泛应用。
1.1 算法特点
-
"朴素"假设:特征条件独立,即特征之间互不影响
-
训练速度快,适合高维数据
-
对小规模数据表现良好
-
对缺失数据不太敏感
1.2 应用场景
-
文本分类(如垃圾邮件识别)
-
情感分析
-
推荐系统
-
医疗诊断
二、数学原理
2.1 贝叶斯定理
朴素贝叶斯基于贝叶斯公式:
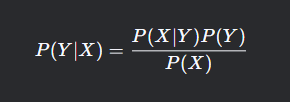
其中:
-
P(Y∣X)P(Y∣X) 是后验概率
-
P(X∣Y)P(X∣Y) 是似然概率
-
P(Y)P(Y) 是先验概率
-
P(X)P(X) 是证据因子
2.2 分类决策
对于输入样本 xx,预测其类别 yy:
y=argmaxyP(y)∏i=1nP(xi∣y)y=argymaxP(y)i=1∏nP(xi∣y)
三、Python实现
3.1 高斯朴素贝叶斯实现
import numpy as np
from collections import defaultdict
class GaussianNB:
def __init__(self):
self.priors = {}
self.means = defaultdict(list)
self.vars = defaultdict(list)
def fit(self, X, y):
self.classes = np.unique(y)
n_samples, n_features = X.shape
for c in self.classes:
X_c = X[y == c]
self.priors[c] = X_c.shape[0] / n_samples
self.means[c] = X_c.mean(axis=0)
self.vars[c] = X_c.var(axis=0)
def predict(self, X):
preds = []
for x in X:
posteriors = []
for c in self.classes:
prior = np.log(self.priors[c])
likelihood = np.sum(np.log(self._pdf(c, x)))
posterior = prior + likelihood
posteriors.append(posterior)
preds.append(self.classes[np.argmax(posteriors)])
return np.array(preds)
def _pdf(self, class_idx, x):
mean = self.means[class_idx]
var = self.vars[class_idx]
numerator = np.exp(-(x - mean)**2 / (2 * var))
denominator = np.sqrt(2 * np.pi * var)
return numerator / denominator
# 测试代码
if __name__ == "__main__":
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
nb = GaussianNB()
nb.fit(X_train, y_train)
predictions = nb.predict(X_test)
accuracy = np.sum(predictions == y_test) / len(y_test)
print(f"准确率: {accuracy:.2%}")3.2 使用scikit-learn实现
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
# 使用sklearn内置的GaussianNB
sk_nb = GaussianNB()
sk_nb.fit(X_train, y_train)
sk_predictions = sk_nb.predict(X_test)
print(f"sklearn准确率: {accuracy_score(y_test, sk_predictions):.2%}")四、不同变体比较
朴素贝叶斯有三种常见变体:
| 类型 | 适用场景 | 特征假设 | sklearn类 |
|---|---|---|---|
| 高斯朴素贝叶斯 | 连续数据 | 特征服从高斯分布 | GaussianNB |
| 多项式朴素贝叶斯 | 文本分类 | 特征服从多项式分布 | MultinomialNB |
| 伯努利朴素贝叶斯 | 二值特征 | 特征服从伯努利分布 | BernoulliNB |
五、文本分类实战
5.1 文本数据预处理
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
# 示例文本数据
texts = ["这是一个好产品", "质量很差", "非常推荐购买", "不会再买了"]
labels = [1, 0, 1, 0] # 1表示正面,0表示负面
# 创建管道:文本向量化 + 朴素贝叶斯
model = make_pipeline(
CountVectorizer(),
MultinomialNB()
)
model.fit(texts, labels)
test_text = ["产品质量不错"]
print(f"预测结果: {model.predict(test_text)[0]}")5.2 特征重要性分析
# 获取特征重要性
feature_names = model.named_steps['countvectorizer'].get_feature_names_out()
coef = model.named_steps['multinomialnb'].coef_[0]
# 打印最重要的10个特征
important_features = sorted(zip(feature_names, coef), key=lambda x: x[1], reverse=True)[:10]
print("最重要的10个特征:")
for feat, score in important_features:
print(f"{feat}: {score:.2f}")5.3 运行截图
六、算法优缺点分析
6.1 优点
-
训练和预测速度快
-
对小规模数据表现良好
-
对缺失数据不敏感
-
适合高维数据
6.2 缺点
-
特征条件独立性假设在实际中往往不成立
-
对输入数据的表达形式敏感
-
需要计算概率乘积,可能导致数值下溢
七、总结
朴素贝叶斯算法虽然简单,但在许多实际应用中表现出色,特别是在文本分类领域。理解其数学原理有助于更好地调参和优化。当特征独立性假设基本满足时,朴素贝叶斯往往能提供令人惊讶的良好表现。

















 1239
1239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









