






目录
第一题
如果一个数 p 是个质数,同时又是整数 a 的约数,则 p 称为 a 的一个质因数。
请问, 2024 的最大的质因数是多少?
答案:23
质数的判断
首先,介绍质数的判断:
方法1
首先就是最常见的判断质数的方法,从2开始遍历,直到n为止
bool zhishu1(int n){
if(n == 1) return false;
for(int i = 2 ; i <= n ; i++){
if(n % i == 0) return false
}
return true;
}方法2
为了加快查询速度,查询效率,发现查到n/2就可以了。
bool zhishu2(int n){
if(n == 1) return false;
for(int i = 2 ; i <= n / 2 ; i++){
if(n % i == 0) return false
}
return true;
}方法3
通过数学知识了解,找24,找到4就可以了,后面的组合重复了,同理,找51,找到7即可,所以,发现规律:如果要判断n是否为质数,即判断到就可以了。
bool zhishu3(int n){
if(n == 1) return false;
for(int i = 2 ; i * i <= n ; i++){
if(n % i == 0) return false
}
return true;
}方法4
再一次对数字的思考,一个数可以写成的形式。
n=0,2,3,4的时候,肯定能被2或3整除。
即n=1,5的时候有时是有争议的,即判断和
即可
bool zhishu4(int n){
//n较小的情况需要单独处理
if(n == 2 || n == 3 || n == 5) return true;
if(n == 1 || n % 2 == 0 || n % 3 == 0 ||n % 5 == 0) return false;
int i = 7;
while(i * i <= n){
if(n % i == 0) return false;
i += 4; //成了6k+5
if(n % i == 0) return false;
i += 2; //成了6k+1
}
return true;
}约数
这里的不是找最大公约数,即判断 n % i == 0成不成立即可。
完整代码
#include <iostream>
#include <algorithm>
using namespace std;
bool zhishu4(int n) //质数判断
{
//n较小的情况需要单独处理
if(n == 2 || n == 3 || n == 5) return true;
if(n == 1 || n % 2 == 0 || n % 3 == 0 || n % 5 == 0) return false;
int i = 7;
while(i * i <= n)
{
if(n % i == 0) return false;
i += 4; //成了6k+5
if(n % i == 0) return false;
i += 2; //成了6k+1
}
return true;
}
int main(int argc, char const *argv[])
{
int maxi = 2;
for (int i = 2; i < 2025; ++i)
{
if(zhishu4(i) && 2024 % i == 0) //满足质数和约数条件
maxi = i; //最大值肯定是后面查找的
}
cout << maxi;
return 0;
}第二题
对于两个整数 a, b,既是 a 的整数倍又是 b 的整数倍的数称为 a 和 b 的公倍数。公倍数中最小的正整数称为 a 和 b 的最小公倍数。
请问, 2024 和 1024 的最小公倍数是多少?
答案:259072
最大公约数
一般最大公约数使用辗转相除法。
不断用较大数除以较小数取余数,然后将除数和余数作为新的两个数继续进行这个过程,直到余数为 0,此时的除数就是最大公约数。
举个例子:
如果我们有a,b a = 24 b = 18 ,我们先让 24 % 18 = 6 ,
接下来我们让 18 % 6 = 0 ;刚好符合我们流程图中蓝色框框的条件,这样就能确定 6 就是最大公倍数。
int gcd(int a,int b)
{
return b?gcd(b,a%b):a;
}在C++函数里algorithm头文件里就整理好了一个求最大公约数的函数__gcd(x,y)。即求x和y的最大公约数。
最小公倍数
依据数学知识,最小公倍数 = 两数相乘 / 两数的最大公约数。
即LCM(x,y) = (x*y)/__gcd(x,y)。
完整代码
#include <iostream>
#include<algorithm>
using namespace std;
int main(int argc, char const *argv[])
{
cout << (2024 * 1014) / __gcd(2024, 1024);
return 0;
}第三题
两个数按位异或是指将这两个数转换成二进制后,最低位与最低位异或作为结果的最低位,次低位与次低位异或作为结果的次低位,以此类推。
例如,3 与 5 按位异或值为 6 。
请问,有多少个不超过 2024 的正整数,与 2024 异或后结果小于 2024 。
答案:2001
异或运算
异或运算符(^)
- 对应二进制位进行异或运算
- 对应二进制位上,相同结果为0,不同结果为1
异或运算的性质
- 满足交换律 A ^ B = B ^ A
- 满足结合律(A ^ B)^ C = A ^ (B ^ C)
看不懂的看专门写异或讲解的文章去—>异或运算
完整代码
#include <iostream>
using namespace std;
int main()
{
int num = 0;
for (int i = 1; i <= 2024; i++)
{
if ((i ^ 2024) < 2024) //与2024异或并且异或值<2024
num++;
}
cout << num;
return 0;
}第四题
小蓝有一个整数,初始值为 1 ,他可以花费一些代价对这个整数进行变换。
小蓝可以花费 1 的代价将整数增加 1 。
小蓝可以花费 3 的代价将整数增加一个值,这个值是整数的数位中最大的那个(1 到 9)。
小蓝可以花费 10 的代价将整数变为原来的 2 倍。
例如,如果整数为 16,花费 3 将整数变为 22 。
又如,如果整数为 22,花费 1 将整数变为 23 。
又如,如果整数为 23,花费 10 将整数变为 46 。
请问,如果要将整数从初始值 1 变为 2024,请问最少需要多少代价?
答案:79
01背包
一看动态规划,头大,随手甩一篇文章—>背包
二维:
在01背包问题中,每个问题只能放一次进背包。
f[i][j]表示只考虑前i件物品,当背包容量为i时的最大价值。
f[0][0~ m] ; 考虑0件物品,总体积不超过0~m 的最大价值
由于此时一件物品都没有所以最大价值都0
由于之前在前面已经在全局变量中初始化过,所以此处不用再初始化
状态转移方程:
对于每个物品i,我们有两种选择:不放入背包,或者放入背包。如果不放入背包,那么f[i][j]=f[i-1][j];如果放入背包,前提是背包的容量 大于等于物品i的体积v[i],那么f[i][j] a (f[i-1][j], f[i-1][j-v[i]] w[i])。选择这两种情况的最大值作为f[i][j]的值。
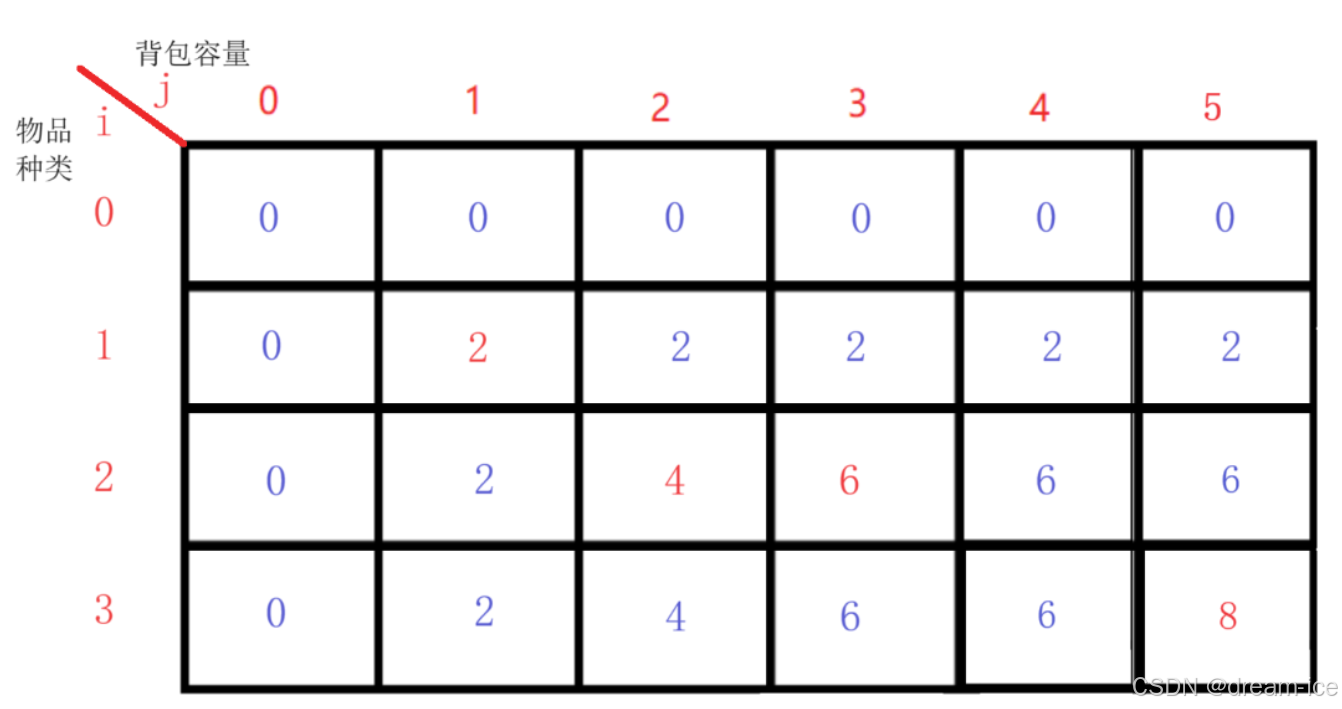
循环遍历:
当前背包容量为 i 时所得最大价值,必不小于背包容量为 i - 1 时的最大价值,故先令此时背包容 量的最大价值为 f[i - 1][j],再判断是否能放的下每个不同的物品,如果能放下,则比较后取较大的值。
for (int i = 1; i <= n; i++)
for (int j = 0; j <= m; ++j)
{
f[i][j] = f[i - 1][j];
if (j >= v[i])f[i][j] = max(f[i][j], f[i - 1][j - v[i]] + w[i]);
}一维:
f[j]表示背包容量为j时,能装入的最大价值。
状态转移方程:
对于每个物品i,考虑是否放入背包中。若不放入,则总价值不变;
若放入,则总价值为f[j-v[i]] + w[i](在当前容量下,放入物品i后的总价值)。
因此,状态转移方程为f[j] = max(f[j], f[j-v[i]] + w[i])。
循环遍历:
在01背包问题中,每个物品只能放一次进背包。
如果我们从最小的背包容量开始考虑放物品(即正序遍历),那么在更新较大的背包容量 j 时,较小的背包容量 j-v[i] 可能已经考虑过了物品 i。这会导致物品 i 被错误地计算两次,即它在更新 f[j-v[i]] 时被考虑过一次,在更新 f[j] 时又被考虑。因为逆序是从大到小考虑,所以,并不会发生上述重复考虑的情况
for (int i = 1; i <= n; ++i)
{
for (int j = m; j >= v[i]; j--)
{
f[j] = max(f[j], f[j - v[i]] + w[i]);
}
}完整代码
#include <iostream>
#include <vector>
using namespace std;
using ll = long long;
// 用于记录每个数字的数位中最大的那个数字,提前计算好,避免重复求数位最大值的操作
vector<int> v(3000, 0);
int main() {
ios::sync_with_stdio(0);
int n = 2024;
vector<int> dp(n + 1, 1e9);
dp[1] = 0;
// 提前计算每个数字数位中的最大值,存到v数组中
for (int i = 1; i <= n; ++i) {
int num = i;
while (num) {
v[i] = max(v[i], num % 10);
num /= 10;
}
}
for (int i = 1; i < n; ++i) {
// 花费1的代价将整数增加1
if (i + 1 <= n)
dp[i + 1] = min(dp[i + 1], dp[i] + 1);
// 花费10的代价将整数变为原来的2倍
if (i * 2 <= n)
dp[i * 2] = min(dp[i * 2], dp[i] + 10);
// 花费3的代价将整数增加一个值,这个值是整数的数位中最大的那个(1到9)
if (i + v[i] <= n)
dp[i + v[i]] = min(dp[i + v[i]], dp[i] + 3);
}
cout << dp[2024];
return 0;
}第五题
小蓝有以下 100 个整数:
534, 386, 319, 692, 169, 338, 521, 713, 640, 692, 969, 362, 311, 349, 308, 357, 515, 140, 591, 216,57, 252, 575, 630, 95, 274, 328, 614, 18, 605, 17, 980, 166, 112, 997, 37, 584, 64, 442, 495,821, 459, 453, 597, 187, 734, 827, 950, 679, 78, 769, 661, 452, 983, 356, 217, 394, 342, 697, 878,475, 250, 468, 33, 966, 742, 436, 343, 255, 944, 588, 734, 540, 508, 779, 881, 153, 928, 764, 703,459, 840, 949, 500, 648, 163, 547, 780, 749, 132, 546, 199, 701, 448, 265, 263, 87, 45, 828, 634.
小蓝想从中选出一部分数求和,使得和是 24 的倍数,请问这个和最大是多少
答案:49176
方法一:深度优先搜索
开始甩文章—>dfs
再甩一个简单的dfs题目
构建dfs深度优先搜索的函数
dfs(index,sum),sum表示目前加到的总数之和,index表示目前加到了第几位;
void dfs(index,sum)
{
搜索结束判断条件
dfs(index + 1 ,sum); //表示下一位不加
dfs(index + 1 ,sum + n); //表示下一位可以加
}
为了减小搜索的时间复杂度,可以采用一些简单的剪枝
即如果当前和加上剩余所有数字的和都小于等于已有的最大和,就不用继续探索该分支了
完整代码
#include <iostream>
#include <vector>
#include <cmath>
using namespace std;
int maxSum = 0; // 记录满足条件的最大和
int a[101] = {
0, 534, 386, 319, 692, 169, 338, 521, 713, 640, 692, 969, 362, 311, 349, 308, 357, 515, 140, 591, 216, 57, 252, 575,
630, 95, 274, 328, 614, 18, 605, 17, 980, 166, 112, 997, 37, 584, 64, 442, 495, 821, 459, 453, 597, 187, 734, 827,
950, 679, 78, 769, 661, 452, 983, 356, 217, 394, 342, 697, 878, 475, 250, 468, 33, 966, 742, 436, 343, 255, 944,
588, 734, 540, 508, 779, 881, 153, 928, 764, 703, 459, 840, 949, 500, 648, 163, 547, 780, 749, 132, 546, 199, 701,
448, 265, 263, 87, 45, 828, 634
};
// 计算剩余数字的总和,用于剪枝判断
int jzhi(int startIndex) {
int sum = 0;
for (int i = startIndex; i < 101; ++i) {
sum += a[i];
}
return sum;
}
void dfs(int index, int sum) {
if (index == 101) {
if (sum % 24 == 0) {
maxSum = max(maxSum, sum);
}
return;
}
// 剪枝判断,如果当前和加上剩余所有数字的和都小于等于已有的最大和,就不用继续探索该分支了
if (sum + jzhi(index) <= maxSum) {
return;
}
// 不选当前数字,继续搜索下一个数字
dfs(index + 1, sum);
// 选当前数字,继续搜索下一个数字
dfs(index + 1, sum + a[index]);
}
int main(int argc, char const *argv[]) {
dfs(0, 0);
cout << maxSum << endl;
return 0;
}
方法二:背包
背包觉得有点难处理,就用暴力深搜吧
#include <iostream>
#include <climits> // 引入用于表示整数极限值的头文件,这里主要用于初始化dp数组时设置极小值
using namespace std;
int a[101] =
{
0, 534, 386, 319, 692, 169, 338, 521, 713, 640, 692, 969, 362, 311, 349, 308, 357, 515, 140, 591, 216, 57, 252, 575,
630, 95, 274, 328, 614, 18, 605, 17, 980, 166, 112, 997, 37, 584, 64, 442, 495, 821, 459, 453, 597, 187, 734, 827,
950, 679, 78, 769, 661, 452, 983, 356, 217, 394, 342, 697, 878, 475, 250, 468, 33, 966, 742, 436, 343, 255, 944,
588, 734, 540, 508, 779, 881, 153, 928, 764, 703, 459, 840, 949, 500, 648, 163, 547, 780, 749, 132, 546, 199, 701,
448, 265, 263, 87, 45, 828, 634
};
// dp数组用于记录不同余数对应的最大和,大小为24,因为和除以24的余数范围是0到23,每个余数对应一种状态下的最大和
int dp[24];
int main(int argc, char const *argv[])
{
// 初始化dp数组,除dp[0]设为0外,其余设为极小值表示无效状态
// dp[0]设为0是因为初始和为0时,其除以24的余数就是0,这是一种合法的初始情况
for (int i = 0; i < 24; ++i)
{
dp[i] = INT_MIN;
}
dp[0] = 0;
// 从索引1开始遍历数组a,因为a[0]是占位0,实际的数据从a[1]开始
for (int i = 1; i < 101; ++i)
{
int cur = a[i]; // 获取当前要处理的数组元素值
// 创建curDp数组,用于复制当前dp数组的状态
// 这么做是为了在更新dp数组时,基于旧的状态进行更新,避免因为同时修改同一个数组导致状态更新错误
int curDp[24];
for (int k = 0; k < 24; ++k)
{
curDp[k] = dp[k];
}
// 遍历dp数组代表的所有余数情况(范围是0到23)
for (int j = 0; j < 24; ++j)
{
// 只有当当前余数对应的最大和不是无效状态(即不是INT_MIN)时,才进行后续操作
// 因为无效状态表示还未找到有效的组合达到该余数对应的最大和情况,不能基于此进行更新
if (curDp[j]!= INT_MIN)
{
// 计算加入当前数cur后,新的和除以24得到的余数newRemainder
int newRemainder = (j + cur % 24) % 24;
// 更新dp数组中newRemainder对应的最大和
// 取原来newRemainder对应的最大和与加入当前数cur后的新和两者中的较大值
dp[newRemainder] = max(dp[newRemainder], curDp[j] + cur);
}
}
}
// 输出余数为0对应的最大和,即和为24倍数的最大和
// 因为在整个动态规划过程中,dp[0]记录的就是满足和是24倍数时的最大和情况
cout << dp[0] << endl;
return 0;
}第六题
小蓝准备请自己的朋友吃饭。小蓝朋友很多,最终吃饭的人总数达 2024 人(包括他自己)。
请问如果每桌最多坐 n 人,最少要多少桌才能保证每个人都能吃饭。
【输入格式】
输入一行包含一个整数 n 。
【输出格式】
输出一行包含一个整数,表示最少的桌数。
【样例输入】
10
【样例输出】
203
【样例输入】
8
【样例输出】
253
【评测用例规模与约定】
对于所有评测用例,1 <= n <= 2024。
解
这题主要就是判断2024是否整除n,不能整除,就2024/n+1,反则,2024/n.
完整代码
#include <iostream>
using namespace std;
int main(int argc, char const *argv[])
{
ios::sync_with_stdio(0);
int n, ans;
cin >> n;
ans = 2024 / n;
if (2024 % n != 0) //如果不能整除
{
ans++; //答案+1
}
cout << ans;
return 0;
}第七题
小蓝有一个数组 a[1], a[2], ..., a[n] ,请求出数组中值最小的偶数,输出这个值。
【输入格式】
输入的第一行包含一个整数 n 。
第二行包含 n 个整数,相邻数之间使用一个空格分隔,依次表示 a[1], a[2], ..., a[n] 。
【输出格式】
输出一行,包含一个整数,表示答案。数据保证数组中至少有一个偶数。
【样例输入】
9
9 9 8 2 4 4 3 5 3
【样例输出】
2
【样例输入】
5
4321 2143 1324 1243 4312
【样例输出】
1324
【评测用例规模与约定】
对于 30% 的评测用例,1 <= n <= 100,0 <= a[i] <= 1000。
对于 60% 的评测用例,1 <= n <= 1000,0 <= a[i] <= 1000。
对于所有评测用例,1 <= n <= 10000,0 <= a[i] <= 1000000。
解:
就是一普通的找找偶数,比比大小,没玩出什么花样
完整代码
#include <iostream>
using namespace std;
const int N = 1e4 + 10;
int n, arr[N], minN = 1e9;
int main(int argc, char const *argv[])
{
cin >> n;
for (int i = 0; i < n; ++i)
{
cin >> arr[i];
if (arr[i] % 2 == 0)
{
minN = min(minN, arr[i]);
}
}
cout << minN;
return 0;
}第八题
一个字符串包含LANQIAO是指在字符串中能取出几个字符,将他们按照在原串中的位置顺序摆成一排后字符串为 LANQIAO 。即字符串包含 LANQIAO 是指 LANQIAO 是这个串的子序列。
例如:LLLLLANHAHAHAQLANIIIIALANO 中包含 LANQIAO 。
又如:OAIQNAL 中不包含 LANQIAO 。
给点一个字符串,判断字符串中是否包含 LANQIAO 。
【输入格式】
输入一行包含一个字符串。
【输出格式】
如果包含 LANQIAO ,输出一个英文单词 YES ,否则输出一个英文单词 NO 。
【样例输入】
LLLLLANHAHAHAQLANIIIIALANO
【样例输出】
YES
【样例输入】
OAIQNAL
【样例输出】
NO
【评测用例规模与约定】
对于所有评测用例,输入的字符串非空串,由大写字母组成,长度不超过 1000 。
解:
一个简答的对字符串的应用,好像没什么难度。
完整代码
#include <iostream>
using namespace std;
using ll = long long;
string ans = "LANQIAO";
string s;
int res;
int main()
{
ios::sync_with_stdio(0);
cin >> s;
for(int i = 0; i < s.size(); i++)
{
if(s[i] == ans[res])
res++;
if (res == 7)
{
cout << "YES";
return 0;
}
}
cout << "NO";
return 0;
}第九题
小蓝有一个 n 行 m 列的矩阵 a[i][j] ,他想在矩阵中找出一个“口”字形状的区域,使得区域上的值的和最大。
具体讲,一个“口”字形状的区域可以由两个坐标 (x1, y1) 和 (x2, y2) 确定,满足:
1 <= x1 < x2 <= n ;
1 <= y1 < y2 <= m ;
x2 - x1 = y2 - y1 。
对应的区域由满足以下条件之一的点 (x, y) 构成:
x1 <= x <= x2,且 y = y1 ,对应“口”的左边一竖;
y1 <= y <= y2,且 x = x1 ,对应“口”的上面一横;
x1 <= x <= x2,且 y = y2 ,对应“口”的右边一竖;
y1 <= y <= y2,且 x = x2 ,对应“口”的下面一横。
请注意有些点满足以上条件的多个,例如左上角的点 (x1, y1) ,在计算时算为一个点。
区域上的值是指对应区域的所有点的值,即“口”字的框上的值,不含框内和框外的值。
【输入格式】
输入的第一行包含两个整数 n, m ,分别表示行数和列数。
接下来 n 行,每行包含 m 个整数,相邻数之间使用一个空格分隔,依次表示矩阵的每行每列的值,本部分的第 i 行第 j 列表示 a[i][j] 。
【输出格式】
输出一行包含一个整数,表示最大的和。
【样例输入】
5 6
1 -1 2 -2 3 -3
-1 2 -2 3 -3 4
2 -2 3 -3 4 -4
-2 3 -3 4 -4 5
3 -3 4 -4 5 -5
【样例输出】
4
【样例说明】
取 (x1, y1) = (1, 1) , (x2, y2) = (5, 5) 可得到最大值。
【评测用例规模与约定】
对于 30% 的评测用例,1 <= n, m <= 30 ,-1000 <= a[i][j] <= 1000 。
对于 60% 的评测用例,1 <= n, m <= 100 ,-1000 <= a[i][j] <= 1000 。
对于所有评测用例,1 <= n, m <= 300 ,-1000 <= a[i][j] <= 1000 。
前缀和
这是一个二维的前缀和。前缀和给你们推一篇文章吧,人家有图我没图,懒癌犯了
完整代码
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
// 定义一个较大的常量N,用于表示二维数组的最大维度,这里假设最大为310,可根据评测用例规模调整
const int N = 310;
// 表示矩阵的行数
int n;
// 表示矩阵的列数
int m;
// a[N][N]用于存储输入的矩阵元素值
int a[N][N];
// s[N][N]用于存储矩阵的前缀和,方便后续快速计算子矩阵的元素和
int s[N][N];
// ans用于记录找到的“口”字形状区域值的最大值,初始化为一个很小的值(-1e9)
int ans = -1e9;
// 函数功能:计算包含内部点的矩阵区域(左上角坐标为(x1, y1),右下角坐标为(x2, y2))的元素值之和
// 通过利用前缀和数组s,按照容斥原理来快速计算子矩阵的和
// 例如:s[x2][y2]包含了从(0, 0)到(x2, y2)整个大矩形的和,s[x2][y1 - 1]是包含了从(0, 0)到(x2, y1 - 1)的和(多减去了一部分)
// s[x1 - 1][y2]是包含了从(0, 0)到(x1 - 1, y2)的和(也多减去了一部分),所以需要再加上s[x1 - 1][y1 - 1](被多减了两次的部分)
int juzhen(int x1, int y1, int x2, int y2)
{
return s[x2][y2] - s[x2][y1 - 1] - s[x1 - 1][y2] + s[x1 - 1][y1 - 1];
}
// 函数功能:计算“口”字形状区域(由左上角坐标(x1, y1)和右下角坐标(x2, y2)确定)的元素值之和
// 这里根据“口”字形状区域的特点,如果是特殊情况(内部只有一个点,即x1 + 1 == x2 - 1 && y1 + 1 == y2 - 1)
// 则用包含整个区域的矩阵和减去中间那个单独的点的值(a[x1 + 1][y1 + 1])来得到“口”字形状区域的和
// 否则(一般情况),用包含整个区域的矩阵和减去内部小矩形区域(左上角坐标为(x1 + 1, y1 + 1),右下角坐标为(x2 - 1, y2 - 1))的和
// 以此来得到“口”字形状区域的和,也就是框上元素值的总和
int kou(int x1, int y1, int x2, int y2)
{
if (x1 + 1 == x2 - 1 && y1 + 1 == y2 - 1) return juzhen(x1, y1, x2, y2) - a[x1 + 1][y1 + 1];
return juzhen(x1, y1, x2, y2) - juzhen(x1 + 1, y1 + 1, x2 - 1, y2 - 1);
}
int main()
{
// 从标准输入读取矩阵的行数n和列数m
cin >> n >> m;
// 预处理前缀和数组s
// 按照动态规划的思想,通过递推公式计算出每个位置的前缀和
// s[i][j]表示从矩阵左上角(0, 0)到当前位置(i, j)这个子矩阵的元素值之和
// 递推公式:s[i][j] = s[i - 1][j] + s[i][j - 1] - s[i - 1][j - 1] + a[i][j]
// 其中s[i - 1][j]是左边相邻子矩阵的和,s[i][j - 1]是上边相邻子矩阵的和,s[i - 1][j - 1]是左上角重复计算的部分,所以要减去,最后加上当前位置元素a[i][j]
for (int i = 1; i <= n; i++)
for (int j = 1; j <= m; j++)
{
cin >> a[i][j];
s[i][j] = s[i - 1][j] + s[i][j - 1] - s[i - 1][j - 1] + a[i][j];
}
// 三层嵌套循环用于枚举“口”字形状区域的左上角坐标(i, j)以及边长k(通过限制条件确定合法的范围)
// i从1到n - 2,因为要保证“口”字形状能完整存在,至少需要留下下面两行
// j从1到m - 2,同理,至少需要留下右边两列
// k表示“口”字形状的边长(从2开始,因为边长至少为2才能构成“口”字形状),且要保证不超出矩阵范围(k <= n - i && k <= m - j)
for (int i = 1; i <= n - 2; i++)
{
for (int j = 1; j <= m - 2; j++)
{
for (int k = 2; k <= n - i && k <= m - j; k++)
{
// 对于每一组合法的“口”字形状区域坐标和边长,调用kou函数计算其元素值之和
// 并通过max函数更新ans,使其始终记录当前找到的最大的“口”字形状区域值的和
ans = max(ans, kou(i, j, i + k, j + k));
}
}
}
// 输出找到的最大的“口”字形状区域值的和
cout << ans;
return 0;
}第十题
小蓝正在玩一个寻宝游戏。寻宝游戏在一个方格图上进行。方格图中的每一个格子都有一个坐标 (r, c),其中越往北 r 越小,越往南 r 越大,越往东 c 越大,越往西 c 越小。南北相邻方格的 c 坐标相同,r 坐标差一。东西相邻方格的 r 坐标相同, c 坐标差一。
游戏开始时,小蓝站在 (0, 0) 处,面向北边。游戏区域无限大,且没有障碍。每一步,小蓝控制自己的角色走一步,他可以有如下三种选择:
向前走:朝现在的方向前进到相邻的方格中,并保持当前的方向。
向左走:向左转90度,并前进到相邻的方格中(即进入到原来左边的方格),面向的方向变为了原来的左边。
向右走:向右转90度,并前进到相邻的方格中(即进入到原来右边的方格),面向的方向变为了原来的右边。
小蓝玩了一会儿,一共走了 n 步,他记录了自己的每一个动作。但是他没有找到宝藏。他怀疑前面的某一步出现了失误。他想知道,如果他改变之前的某一步,能到的位置有哪些。由于这个太复杂,他想知道最终到的位置(第 n 步后到的位置)有多少种。
【输入格式】
输入的第一行包含一个整数 n ,表示小蓝走了 n 步。
第二行包含一个长度为 n 的由大写字母组成的字符串,依次表示小蓝走的每一步。字母 F 、 L 、 R 分别表示对应的步是向前走、向左走、向右走。
【输出格式】
输出一行,包含一个整数,表示如果改变某一步,可以到的位置的种类数。
【样例输入】
3
FLR
【样例输出】
6
【样例说明】
如果不改变,三步依次走到:(-1, 0), (-1, -1), (-2, -1) ,最终位置为 (-2, -1) 。
如果第一步改成 L,三步依次走到:(0, -1), (1, -1), (1, -2) ,最终位置为 (1, -2) 。
如果第一步改成 R,三步依次走到:(0, 1), (-1, 1), (-1, 2) ,最终位置为 (-1, 2) 。
如果第二步改成 F,三步依次走到:(-1, 0), (-2, 0), (-2, 1) ,最终位置为 (-2, 1) 。
如果第二步改成 R,三步依次走到:(-1, 0), (-1, 1), (0, 1) ,最终位置为 (0, 1) 。
如果第三步改成 F,三步依次走到:(-1, 0), (-1, -1), (-1, -2) ,最终位置为 (-1, -2) 。
如果第三步改成 L,三步依次走到:(-1, 0), (-1, -1), (0, -1) ,最终位置为 (0, -1) 。
共有 6 种不同的最终位置。
【样例输入】
4
RRRR
【样例输出】
6
【样例说明】
有 8 种改变方法:
改为 FRRR ,最终位置为 (0, 0);
改为 LRRR ,最终位置为 (0, 0);
改为 RFRR ,最终位置为 (1, 1);
改为 RLRR ,最终位置为 (0, 2);
改为 RRFR ,最终位置为 (2, 0);
改为 RRLR ,最终位置为 (2, 2);
改为 RRRF ,最终位置为 (1, -1);
改为 RRRL ,最终位置为 (2, 0)。
不同的最终位置共有 6 种。
【评测用例规模与约定】
对于 30% 的评测用例,1 <= n <= 20。
对于 60% 的评测用例,1 <= n <= 1000。
对于所有评测用例,1 <= n <= 100000。
队列、容器:
看到这么多字,头大。果断放弃
先进行知识点补充:
队列—>队列
queue容器—>queue
set容器—>set
广度优先搜索—>bfs
讲解代码全放注释里吧,加油
完整代码
#include <iostream>
#include <queue>
#include <set>
using namespace std;
using ll = long long;
// 定义一个结构体Point,用于表示坐标点以及当前的方向
// x表示横坐标,y表示纵坐标,direction表示方向(通过后续代码中与dx、dy数组配合来确定具体朝向)
struct Point {
int x;
int y;
int direction;
};
// 定义一个队列q,用于存储已经改变方向的点,后续会根据不同的操作不断更新队列中的点的状态
queue<Point> q;
// 定义一个数组dx,用于表示在北、东、南、西四个方向上横坐标x的变化量
// 按照顺序依次对应北、东、南、西方向,例如向北走时x坐标减1(对应dx[0] = -1),向东走时x坐标不变(dx[1] = 0)等
int dx[4] = {-1, 0, 1, 0};
// 定义一个数组dy,用于表示在北、东、南、西四个方向上纵坐标y的变化量
// 同样按照顺序依次对应北、东、南、西方向,例如向北走时y坐标不变(对应dy[0] = 0),向东走时y坐标加1(dy[1] = 1)等
int dy[4] = {0, 1, 0, -1};
int main() {
ios::sync_with_stdio(0); // 解除iostream输入输出流与C标准输入输出的同步,提高输入输出效率(在某些情况下可能有影响,需谨慎使用)
int n; // 用于存储小蓝总共走的步数
string s; // 用于存储表示小蓝每一步操作的字符串(由'F'、'L'、'R'组成)
cin >> n >> s; // 从标准输入读取步数n以及操作字符串s
int cx = 0, cy = 0; // 当前坐标,初始化为原点(0, 0),表示小蓝最开始所在的位置
int d = 1; // 当前方向,初始化为东(这里按照代码中dx、dy数组对应顺序假设1代表东方向,可根据实际情况调整理解)
// 遍历输入的每一步操作
for (int i = 0; i < n; i++) {
int sz = q.size(); // 获取当前队列q中已有的点数,用于后续循环处理每个点
int dd; // 方向变化量,根据当前操作字符确定
if (s[i] == 'F') {
dd = 0; // 向前走,方向不变,所以方向变化量设为0
} else if (s[i] == 'L') {
dd = -1; // 向左转,方向逆时针变化,所以方向变化量设为 -1
} else {
dd = 1; // 向右转,方向顺时针变化,所以方向变化量设为 1
}
// 处理已经改变过方向的点,让它们按照当前操作进行相应变化
for (int j = 0; j < sz; j++) {
Point cur = q.front(); // 获取队列头部的点(即当前要处理的已改变方向的点)
q.pop(); // 将该点从队列头部弹出
// 根据当前方向变化量更新方向,并计算新坐标
// 通过取模运算保证方向值始终在0到3的范围内(对应北、东、南、西四个方向)
int new_direction = (cur.direction + dd + 4) % 4;
// 根据新方向,结合dx数组计算横坐标的变化量,更新横坐标
int new_x = cur.x + dx[new_direction];
// 根据新方向,结合dy数组计算纵坐标的变化量,更新纵坐标
int new_y = cur.y + dy[new_direction];
// 将更新后的点(包含新坐标和新方向)重新加入队列
q.push({new_x, new_y, new_direction});
}
// 尝试三种不同的方向改变情况(除了当前实际执行的方向改变情况)并加入队列
for (int k = -1; k <= 1; k++) {
if (k == dd) continue; // 如果当前尝试的方向变化量和实际执行的方向变化量相同,则跳过,避免重复添加
int new_direction = (d + k + 4) % 4; // 根据当前方向和尝试的变化量计算新方向
int new_x = cx + dx[new_direction]; // 根据新方向计算横坐标变化量,更新横坐标
int new_y = cy + dy[new_direction]; // 根据新方向计算纵坐标变化量,更新纵坐标
q.push({new_x, new_y, new_direction}); // 将新生成的点(包含新坐标和新方向)加入队列
}
// 更新当前方向和坐标
d = (d + dd + 4) % 4; // 根据实际执行的方向变化量更新当前方向
cx += dx[d]; // 根据更新后的当前方向,结合dx数组更新横坐标
cy += dy[d]; // 根据更新后的当前方向,结合dy数组更新纵坐标
}
set<pair<int, int> > ss; // 定义一个集合ss,用于存储不同的最终位置坐标,集合会自动去重
// 将队列中所有点的坐标(去除重复的)加入集合,以统计不同的最终位置数量
while (q.size()) {
Point cur = q.front(); // 获取队列头部的点
q.pop(); // 将该点从队列头部弹出
ss.insert(make_pair(cur.x, cur.y)); // 将该点的坐标以pair形式插入集合,利用集合的去重特性只保留不同的坐标
}
cout << ss.size(); // 输出集合中不同坐标的数量,即改变某一步后可以到达的不同最终位置的种类数
return 0;
}
















 4485
4485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









