






要说今年绘画圈最大的新秀
那妥妥的就Stable Diffution
V4升级版无需安装**,直接解压就能用**
*(在此要感谢秋葉aaaki大佬的分享!*)
比之前推送的更加智能、快速和简单
有多简单呢?这么说吧
之前的版本需要初中生级别
现在的V4加强版小学生也能上手!

1
背景信息
▍****Stable Diffusion 是什么?
Stable Diffusion(简称SD)是一种生成式人工智能,于2022年发布,主要用于根据文本描述生成详细图像,也可用于其他任务,如图像的修补、扩展和通过文本提示指导图像到图像的转换。除图像外,您还可以使用该模型创建视频和动画。
这是AI绘画第一次能在可以在消费级显卡上运行,任何人都可以下载模型并生成自己的图像。另外,SD高质量的成图以及强大的自由度(自定义、个性化)受到诸多网友的追捧。Stable
Diffusion XL 1.0 (SDXL 1.0) 是Stable Diffusion的一个更为高级和优化的版本,它在模型规模、图像质量、语言理解和模型架构等方面都有显著的改进。
▍****Stable Diffusion 能做什么?
首先,大家在入坑SD前,务必要清楚现阶段的SD到底能做什么?能否满足自己的需求?
Stable Diffusion 功能包括文本转图像、图像转图像、图形插图、图像编辑和视频创作。
- **文本转图像生成:**最常见和最基础的功能。Stable Diffusion 会根据文本提示生成图像。
- 图像转图像生成使用输入图像和文本提示,您可以根据输入图像创建新图像。典型的案例是使用草图和合适的提示。
- 创作图形、插图和徽标使用一系列提示,可以创建各种风格的插图、图形和徽标。
- 图像编辑和修正可以使用 Stable Diffusion 来编辑和修正照片。例如,可以修复旧照片、移除图片中的对象、更改主体特征以及向图片添加新元素。
- 视频创作使用 GitHub 中的 Deforum 等功能,可以借助 Stable Diffusion 创作短视频片段和动画。另一种应用是为电影添加不同的风格。 还可以通过营造运动印象(例如流水)来为照片制作动画。
2
安装和部署Stable Diffusion
**
**
介绍如何安装和部署Stable Diffusion。我使用的是秋葉aaaki的整合包,文章末尾提供180G整合包~
**
**
电脑系统:Windows10及以上/macOS Monterey (12.5)。
显卡:RTX3060及以上。
显存:8G及以上。
内存:16G及以上。
磁盘空间:500 SSD及以上
▍****操作步骤
步骤一:右键解压Stable Diffusion安装包。
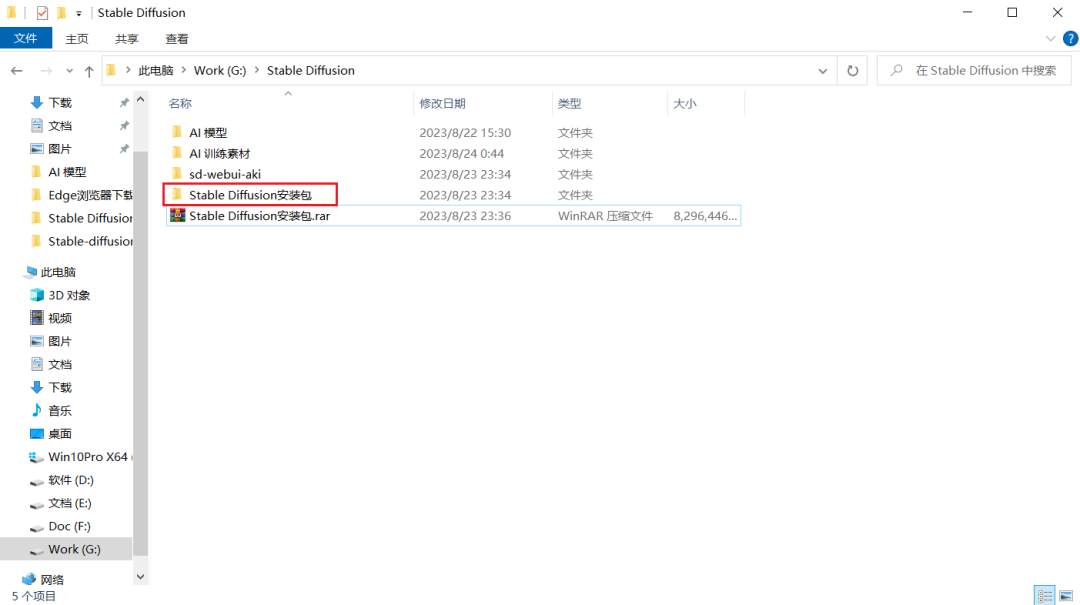
步骤二:双击Stable Diffusion安装包进入文件夹中,解压sd-webui-aki-v4.2。
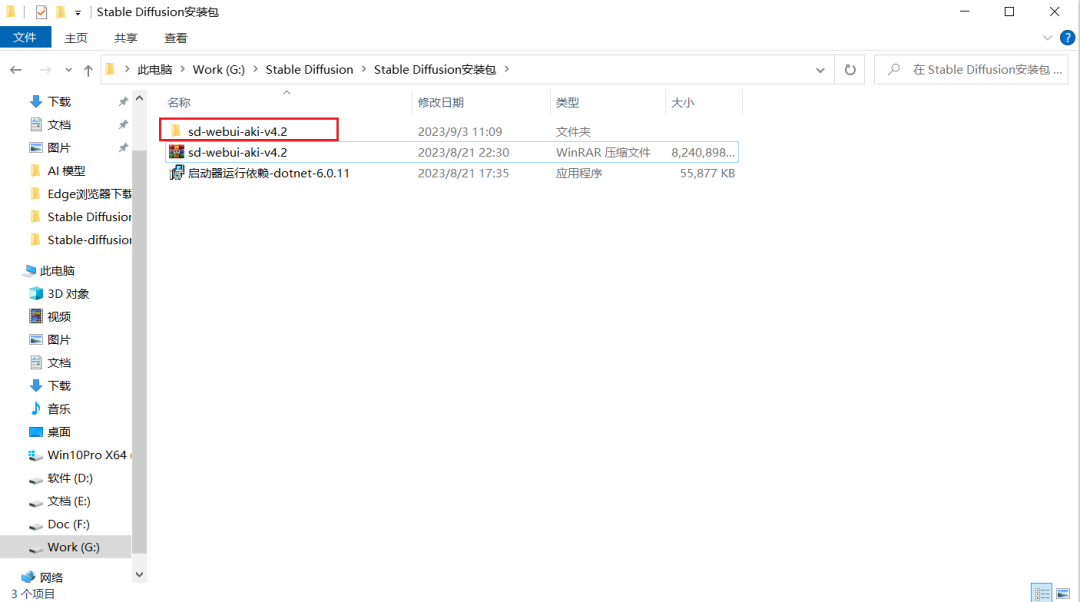
步骤三:双击启动器运行依赖-dotnet-6.0.11,安装所需依赖。
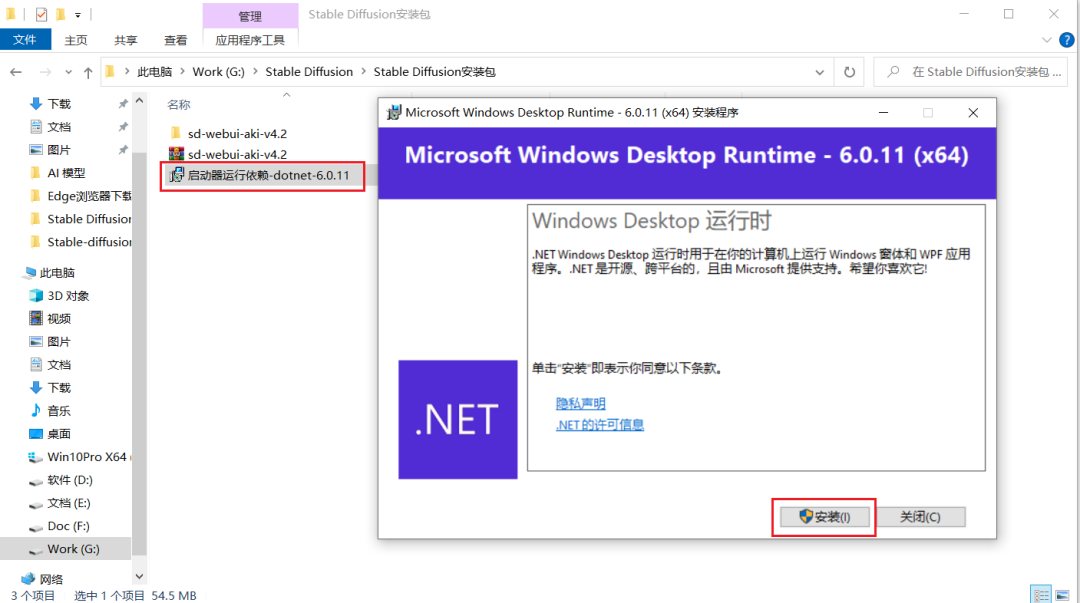
步骤四:双击sd-webui-aki-v4.xx进入该文件夹中,下拉找到A启动器并启动。
注:第一次启动,需要一些时间部署Python和Git环境,请耐心等待,后面启动就很快了。若未弹出WebUI界面,请将复制链接:http://127.0.0.1:7860 到浏览器中即可。
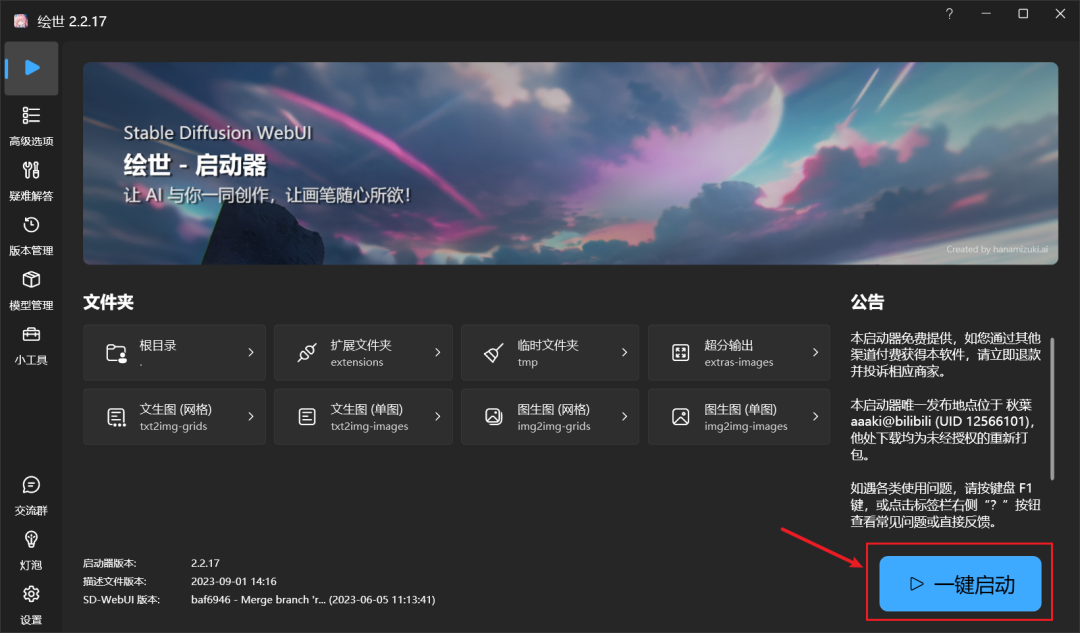
若弹出Stable Diffusion WebUI界面,则表示启动成功。
3
Stable Diffusion教程与模型

Stable Diffusion WebUI界面介绍
***▍*Stable Diffusion WebUI 介绍
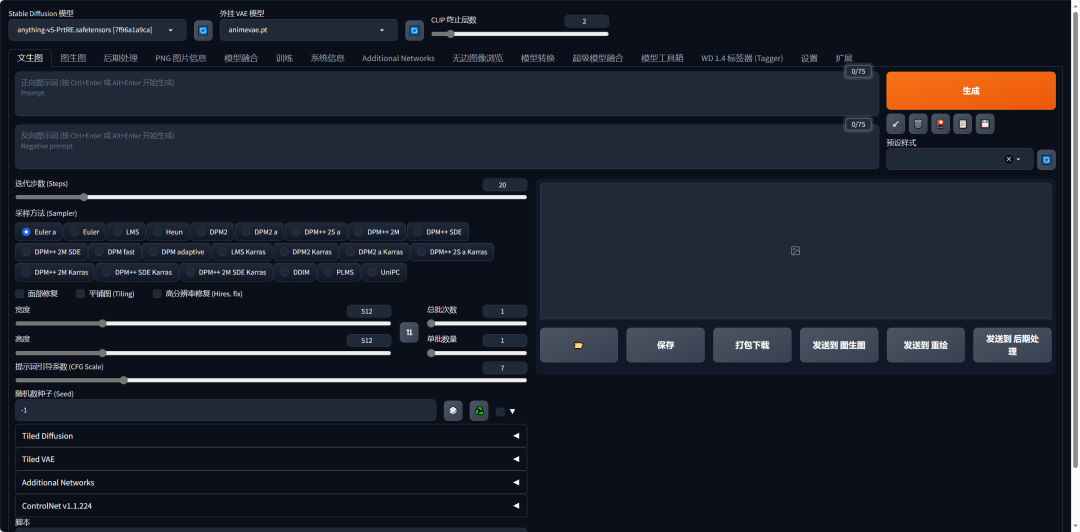
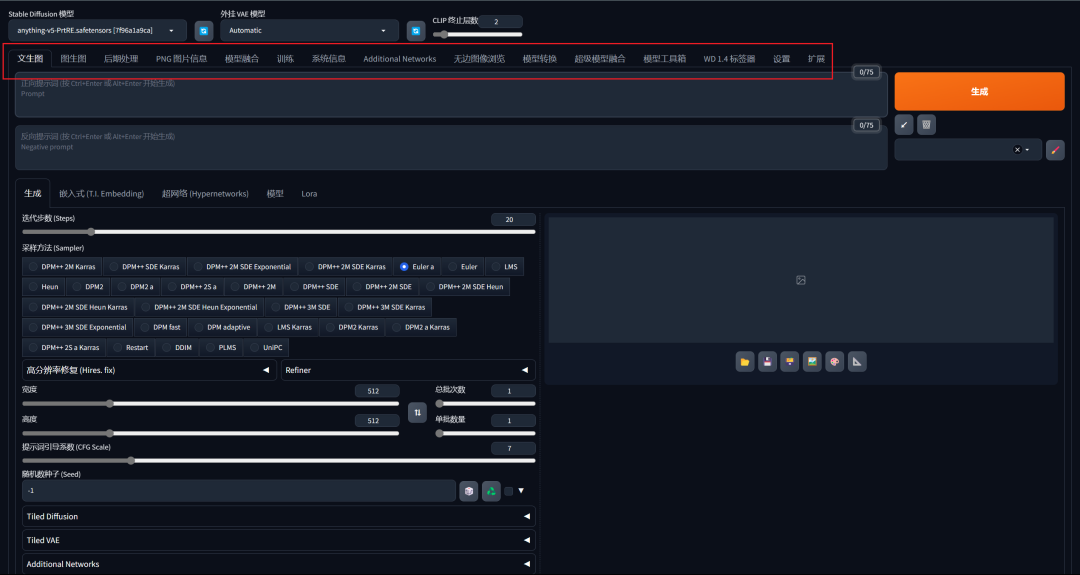
\1. Stable Diffusion WebUI界面主要分为三个区域:模型选择区、功能选择区、参数配置区。
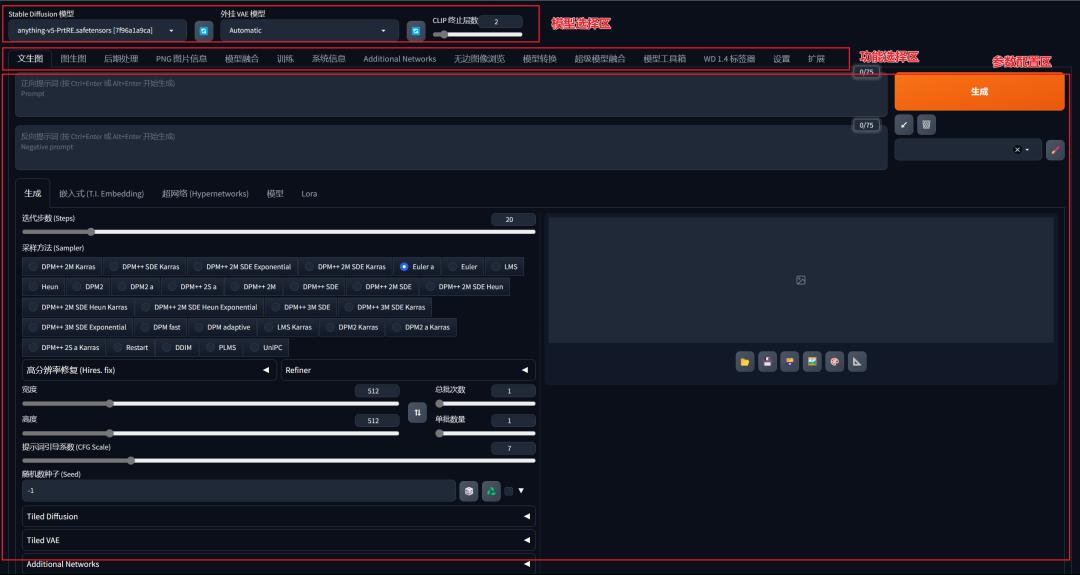
\2. 里面的参数非常多,第一次看到定会眼花缭乱,我对此进行了一次归类分组,这些参数主要分为两类:
一是为了告诉AI,用户的需求是什么,进而完成作图任务,称为基础参数。如提示词框、模型选择,迭代步数,采样器,图片尺寸等。
二是为了高效率地完成这个任务而存在的参数,称为额外参数,是非必要的参数。如垃圾桶,一键清除提示词、文件夹、打包下载、预设样式等。
那么,现在我们在看到某个参数时就知道它大致的作用是什么了。
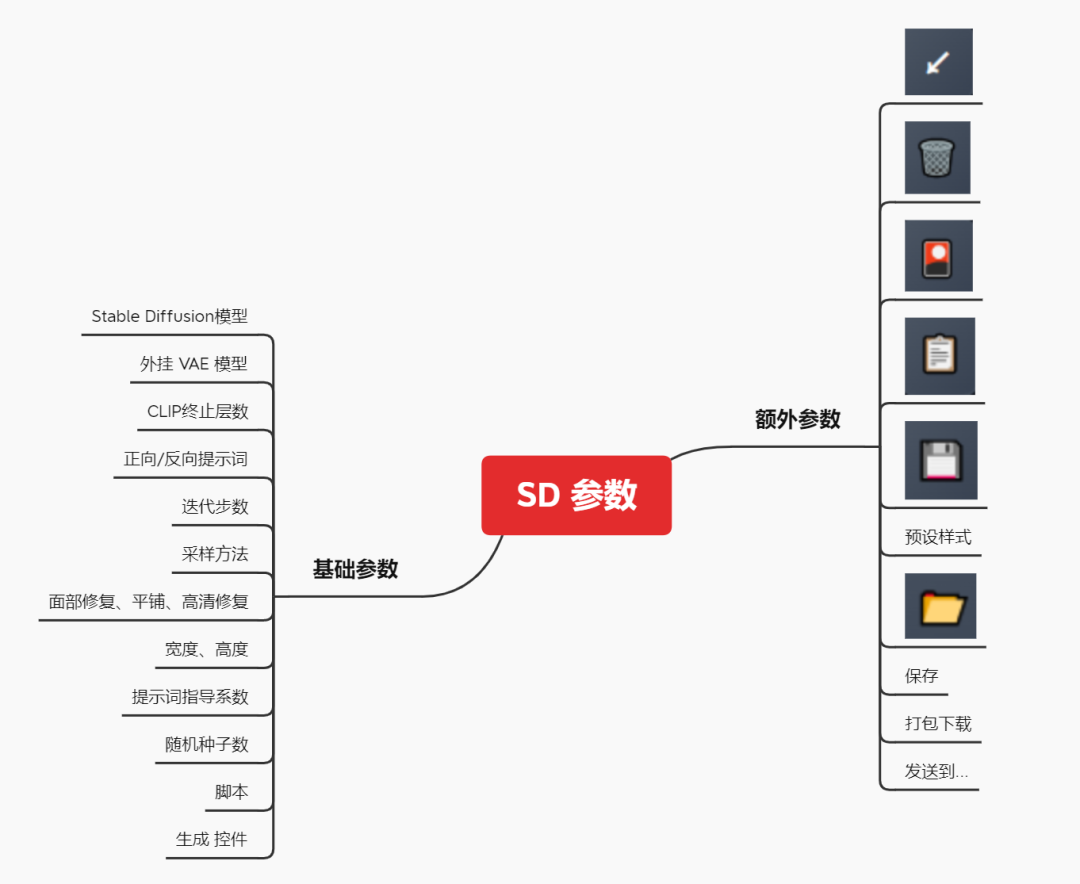
Stable Diffusion 布局/参数介绍
接下来我将依次介绍Stable Diffusion文生图功能中的参数,指导用户快速了解和使用这些参数,以便更好地出图。
注:1. 这里的参数介绍只起到指导性作用,若想进一步了解各个参数的细节和原理,请阅读后续的文章。2. 由于这是整合包相比较原生的Stable Diffusion安装包,功能较多,且已经汉化了。
模型选择区
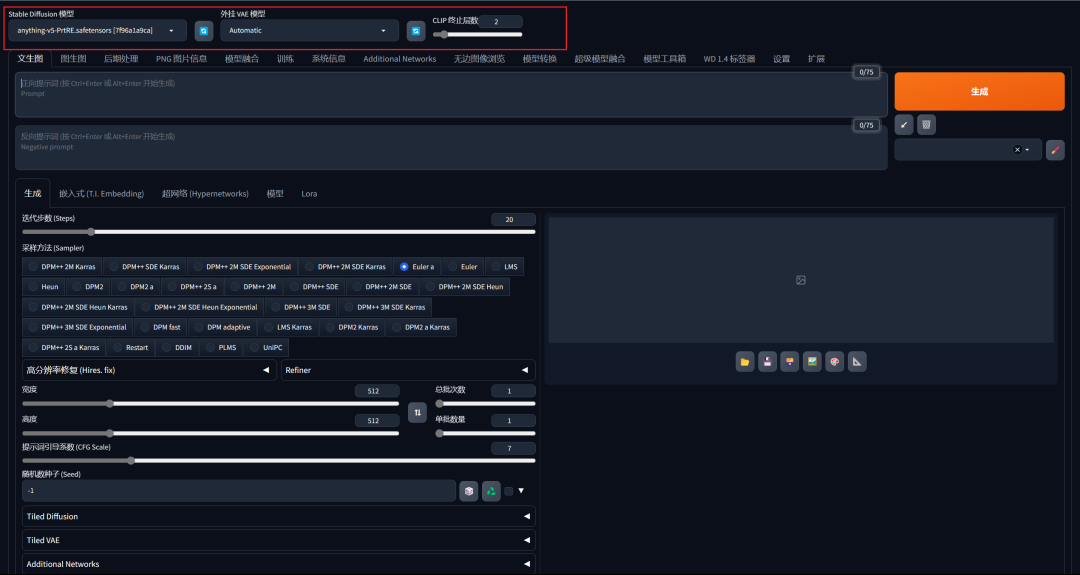
1. Stable Diffusion模型:下拉选择大模型,默认anyting-V5模型。请根据自身需求选择不同类型的模型,如现实主义风格的模型;动漫,二次元风格的模型。
2. 外挂VAE模型:下拉选择VAE模型,默认无。是可选操作,可以选择不同效果的VAE模型,对成图细节或颜色进行修复,同时选择VAE也可以起到节省电脑算力的作用。
3. CLIP终止层数(Clip Skip):滑动确认或输入层数,层数范围为1~12层,默认层数为2。1层,成图更加精确;2层,成图更加平衡,即AI遵循提示词,也有一定自己的创意;3-12层,成图更加有创意。这里推荐2层。若你希望AI更加有自己的创意,还是请调节提示词引导系数(CFG Scale)参数,效果会更好。
注:选择模型时,需要提前下载模型并存储到对应的路径中。模型下载可前往:huggingface网站或Civital网站。Stable Diffusion模型存储位置是:
*\models\Stable-diffusion。VAE模型存储位置是:*\models\VAE。存储完后,点击“🔄”即可。
功能配置区
参数配置区
简单介绍各个参数信息,分为基础参数、额外参数以及老版本的参数。 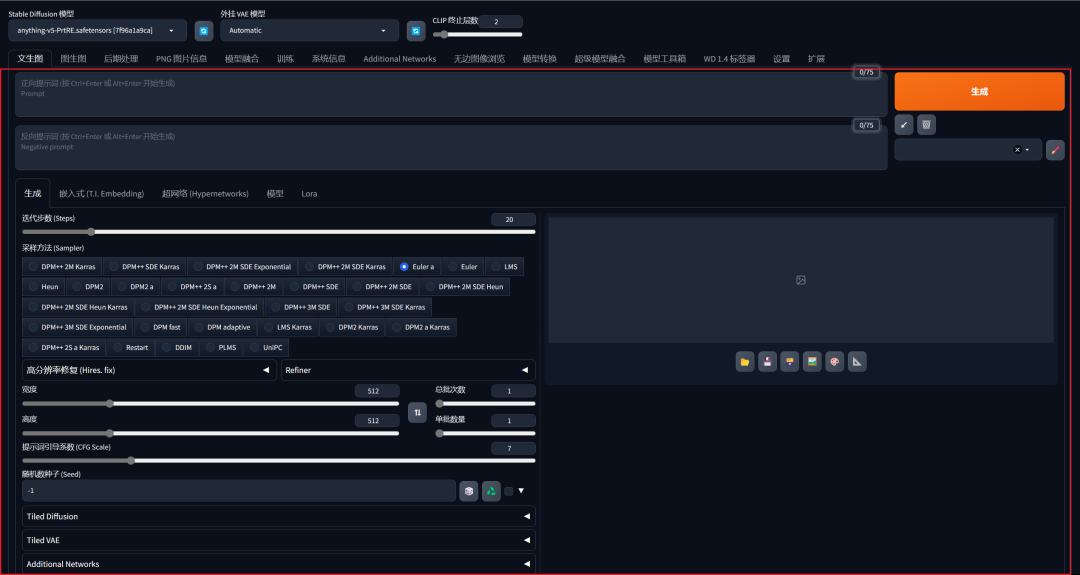
基础参数
1. 正向提示词(Prompt):输入你希望图片中出现什么内容。仅支持英文输入。
2. 反向提示词(Negative prompt):输入你不希望图片中出现什么内容,比如多手指。仅支持英文输入。
3. 迭代步数(Sampling Steps):设置图片去噪的步数,步数越多画面越精细,出图时间也越长。步数范围1~150步,1~19步更加模糊,粗糙;20~40步,更加平衡;40~150步更加精细。其中并不是步数越多越好,为了避免过犹不及,这里推荐20~40步,更加平衡。
4. 采样方法(Sampler Method):点击勾选采样方法。不同的采样方法,有不同效果,这里大家多次尝试即可。
5. 高分辨率修复(Hires. fix):勾选即可将图片的分辨率放大。如从512512px到10241024。
请根据自身显卡性能,设置图片基础分辨率,请勿设置的过高,否则在勾选高分辨率修复后,会显示:Out Of Memory Error,爆显存了。
6. Refiner:待补充。
7. 尺寸(宽度、高度):设置成图的尺寸。默认512512px。推荐的尺寸有:512768px、768512px、7681152。
8. 总批次数:指一次生成图片多少张,这里指陆续跑图。根据显卡性能,酌情设置,推荐1~4。
9. 单批数量:指一次同时生成几张图片,这里指同时跑图。显卡压力更大,不建议设置为2以上。
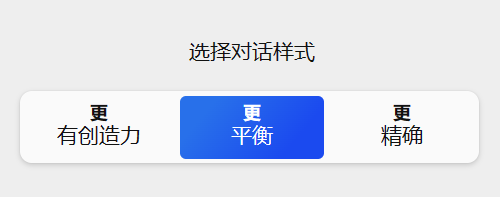
10. 提示词引导系数(CFG Scale):AI遵循提示词的程度/成图与提示词相关度。数值越低更加精确,越高则更有创造力,这里推荐5~7更加平衡。
注:该参数类似于New Bing对话框中的选择对话样式,分为更有创造力、更平衡、更精确。提示词引导系数(CFG Scale)则是以具体的数值来供用户设置。
11. 随机种子数(Seed):设置成图是否随机。文本框默认-1,表示随机产生不同的图片。点击“🎲”将随机种子设置为-1;点击“♻️”将成图的种子数(即唯一编码),设置为随机种子数,在其他参数不变的情况下生成的图片相似99%;点击“⏹️”则是进行更多设置。
12. 脚本(Script):一键测试提示词或各个参数变化对成图的影响。选项默认无,分为提示词矩阵、从文本框或文件载入提示词、X/Y/Z图表、controlnet m2m。

关于模型(和谐部分,请自行查阅)
我们现在可以在很多的模型网站,比如c站、huggingface,也就是抱脸网,上找到很多的训练好的stable diffusion 模型。比如我现在已经用过的Linaqruf/animagine-xl 和 xiaolxl/GuoFeng3模型。
Linaqruf/animagine-xl 是一个可以生成优质动漫风格图像的SD模型。我们只需要输入设计好的提示词,Linaqruf/animagine-xl 就可以自动生成相应的动漫图片了。下面是通过 Linaqruf/animagine-xl 生成的卡通图片:

xiaolxl/GuoFeng3 是一个中国华丽古风风格模型,也可以说是一个古风游戏角色模型,具有2.5D的质感。相比于前几代,第三代大幅度减少上手难度,增加了场景元素与男性古风人物,除此之外为了模型能更好地适应其它TAG,还增加了其它风格的元素。
相比于前几代,这一代对脸和手的崩坏有一定的修复,同时素材大小也提高到了最长边1024。效果图如下:


关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 3873
3873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









