






前言
这篇笔记是对ELE AI算法大赛“赛道二:智慧骑士—消防隐患识别”baseline的记录,我会为baseline进行详细的注释,以下是对赛题的简要描述。
赛题背景
在履约配送过程中,蓝骑士穿梭于大街小巷及楼梯拐角,能够及时发现各类隐患,堪称城市安全隐患的“移动监测员”。然而,隐患上报链路存在两大卡点:一是蓝骑士上传信息的真实性和准确性难以保证;二是上报行为的奖励反馈不够及时,这在一定程度上影响了隐患上报的积极性。借助AI的实时识别功能,可有效解决上述问题,既能确保隐患信息真实有效,又能对蓝骑士进行即时奖励,鼓励其积极上报隐患。
赛事任务
本次比赛主题为“消防隐患随手拍”项目中的照片内容识别。需实时判断拍摄照片内场景是否存在消防安全隐患以及隐患的危险程度。根据楼道中堆积物的情况、堆积物的可燃性以及起火风险,将隐患分为无隐患、低风险、中等风险、高风险四个等级,同时识别非楼道场景。
具体等级划分标准如下:
- 高风险:楼道中出现电动自行车停放、电瓶充电、飞线充电等可能引发火灾的行为之一或多项。
- 中风险:需满足以下两个条件之一:①楼道内堆积物众多,严重影响通行;②楼道堆积物中有明显可见的纸箱、木质家具、布质家具、泡沫箱等可燃物品。
- 低风险:楼道中有物品摆放,但基本不影响通行,数量较少且靠边有序摆放。
- 无风险:楼道干净整洁,无堆放物品。
- 非楼道:与楼道无关的图片。
细则:
1、高风险场景需要有过道中停放电动自行车、给电瓶充电、楼道中飞线充电等一项行为或多项行为。
2、中风险场景需要至少满足以下两个条件之一:①楼道内堆积众多堆积物已经严重影响通行。②楼道的堆积物中有明显可见的纸箱、木质或布质的家具、泡沫箱等可燃物品。
3、低风险场景主要为楼道中有物品摆放但基本不影响通行,数量较少或靠边有序摆放。
初赛评分标准

数据格式
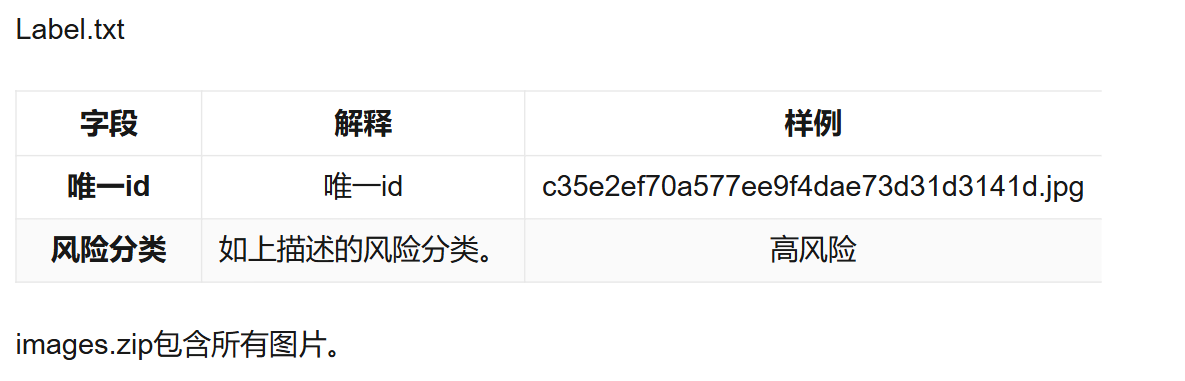
baseline
# --- 导入所需库 ---
import numpy as np
import cv2 # OpenCV 用于图像处理,如此处的 is_valid_image
import os # 用于处理文件和目录路径
import pandas as pd # 用于读取和处理 .txt 文件中的数据
from PIL import Image # Python Imaging Library,用于打开图像文件
import time # 用于计时 (在此脚本的保留部分未使用,但原始代码包含)
from datetime import datetime # 用于在训练过程中打印带时间戳的日志
import torch
import torchvision.models as models # 包含预训练模型,如 ResNet18
import torchvision.transforms as transforms # 包含常用的图像变换操作
import torchvision.datasets as datasets # PyTorch 数据集相关
import torch.nn as nn # PyTorch 神经网络模块
import torch.nn.functional as F # PyTorch 神经网络函数
import torch.optim as optim # 包含优化器,如 Adam
from torch.autograd import Variable # 早期 PyTorch 版本中用于自动求导
from torch.utils.data.dataset import Dataset # 自定义数据集的基类
from torch.utils.data import DataLoader # 数据加载器
# Scikit-learn 用于数据划分
from sklearn.model_selection import StratifiedKFold
# --- 加载和预处理训练数据 ---
# 从 train.txt 读取数据
train_df = pd.read_csv("data/train.txt", sep="\t", header=None)
# 为第一列(文件名)添加路径前缀
train_df[0] = 'data/train/' + train_df[0]
def is_valid_image(image_path):
"""检查图像路径是否存在且可以被 OpenCV 读取"""
if not os.path.exists(image_path):
return False # 文件不存在
image = cv2.imread(image_path)
return image is not None # 检查 cv2.imread 是否成功返回图像数据
# 应用 is_valid_image 函数过滤掉无效的图像条目
train_df = train_df[train_df[0].apply(is_valid_image)]
# --- 标签映射 ---
# 将中文标签映射为整数索引,方便模型训练
mapping_dict = {
'高风险': 0,
'中风险': 1,
'低风险': 2,
'无风险': 3,
'非楼道': 4
}
# 应用映射,将第二列(标签列)转换为整数
train_df[1] = train_df[1].map(mapping_dict)
# --- 自定义数据集类 ---
class GalaxyDataset(Dataset):
"""用于加载图像及其对应标签的自定义 PyTorch 数据集"""
def __init__(self, images, labels, transform=None):
"""
初始化数据集
Args:
images (list/array): 图像文件路径列表
labels (list/array): 对应的标签列表
transform (callable, optional): 应用于图像的转换操作
"""
self.images = images
self.labels = labels
if transform is not None:
self.transform = transform
else:
self.transform = None # 若未提供 transform,则设为 None
def __getitem__(self, index):
"""根据索引获取单个数据样本 (图像和标签)"""
# start_time = time.time() # 原始代码中的计时,此处保留但未使用
# 使用 PIL 打开图像并转换为 RGB 格式
img = Image.open(self.images[index]).convert('RGB')
# 如果定义了 transform,则应用它
if self.transform is not None:
img = self.transform(img)
# 将标签转换为 PyTorch 张量 (确保是 numpy array 再转 tensor)
return img, torch.from_numpy(np.array(self.labels[index]))
def __len__(self):
"""返回数据集中样本的总数"""
return len(self.labels)
# --- 模型定义函数 ---
def get_model1():
"""定义并返回一个修改后的 ResNet18 模型"""
model = models.resnet18(True) # 加载预训练的 ResNet18 模型 (True 表示使用预训练权重)
# 将 ResNet18 的最后一个全连接层 (fc) 替换为新的线性层
# 新层的输出维度为 5,对应我们的 5 个类别
model.fc = nn.Linear(512, 5) # ResNet18 fc 层的输入特征数为 512
return model
# --- 验证函数 ---
def validate(val_loader, model, criterion):
"""在验证集上评估模型性能"""
# 将模型切换到评估模式 (这会关闭 Dropout 和 BatchNorm 的更新)
model.eval()
total_acc = 0 # 用于累加正确预测的数量
# 在评估时,不需要计算梯度,可以节省内存和计算资源
with torch.no_grad():
end = time.time() # 原始代码中的计时
# 遍历验证数据加载器
for i, (input, target) in enumerate(val_loader):
# 将输入数据和目标标签移动到 GPU (如果可用)
input = input.cuda()
target = target.cuda()
# 模型前向传播,获取输出 (logits)
output = model(input)
# 计算损失 (虽然 validate 主要关心准确率,但有时也计算损失)
# loss = criterion(output, target) # 原始代码中计算了 loss 但未使用
# 计算准确率:找到输出概率最高的类别索引,与真实标签比较
# .argmax(1) 找到维度 1 (类别维度) 上的最大值索引
# .long() 确保数据类型一致
# .sum().item() 计算批次中预测正确的样本数并转为 Python number
total_acc += (output.argmax(1).long() == target.long()).sum().item()
# 返回平均准确率 (总正确数 / 总样本数)
return total_acc / len(val_loader.dataset)
# --- 训练函数 ---
def train(train_loader, model, criterion, optimizer, epoch):
"""执行一个训练轮次 (epoch)"""
# 将模型切换到训练模式 (启用 Dropout 和 BatchNorm 的更新)
model.train()
end = time.time() # 原始代码中的计时
# 遍历训练数据加载器
for i, (input, target) in enumerate(train_loader):
# 将输入数据和目标标签移动到 GPU (non_blocking=True 可以尝试加速数据传输)
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
# 模型前向传播,得到预测输出
output = model(input)
# 计算损失
loss = criterion(output, target)
# 计算当前批次的准确率 (用于日志打印)
acc1 = (output.argmax(1).long() == target.long()).sum().item()
# --- 反向传播和优化 ---
# 1. 清空之前的梯度
optimizer.zero_grad()
# 2. 计算损失相对于模型参数的梯度
loss.backward()
# 3. 根据计算出的梯度更新模型参数
optimizer.step()
# 每隔 100 个批次打印一次训练信息
if i % 100 == 0:
# 打印当前时间、损失值、当前批次的准确率
print(datetime.now(), loss.item(), acc1 / input.size(0))
# --- 数据划分 ---
# 使用 StratifiedKFold 进行分层 K 折交叉验证的设置
# n_splits=5 表示分成 5 折
# random_state=233 保证每次划分结果一致
# shuffle=True 表示在划分前打乱数据顺序
skf = StratifiedKFold(n_splits=5, random_state=233, shuffle=True)
# 遍历 K 折划分的结果 (获取训练集和验证集的索引)
# 注意:原始代码在这里使用了 break,意味着只使用了 KFold 产生的第一折数据划分
for _, (train_idx, val_idx) in enumerate(skf.split(train_df[0].values, train_df[1].values)):
break # 获取第一折的 train_idx 和 val_idx 后立即退出循环
# --- 创建数据加载器 (DataLoader) ---
# 训练数据加载器
train_loader = torch.utils.data.DataLoader(
# 使用上面划分出的 train_idx 创建训练数据集
GalaxyDataset(train_df[0].iloc[train_idx].values, train_df[1].iloc[train_idx].values,
# 定义应用于训练图像的变换
transforms.Compose([
transforms.Resize((256, 256)), # 调整图像大小
transforms.RandomHorizontalFlip(), # 随机水平翻转 (数据增强)
transforms.RandomVerticalFlip(), # 随机垂直翻转 (数据增强)
transforms.ToTensor(), # 将 PIL 图像转换为 PyTorch 张量 (HWC -> CHW, [0, 255] -> [0.0, 1.0])
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 标准化 (使用 ImageNet 的均值和标准差)
])
),
batch_size=20, # 每个批次加载 20 个样本
shuffle=True, # 每个 epoch 开始时打乱训练数据顺序
num_workers=20, # 使用 20 个子进程加载数据 (根据系统性能调整)
pin_memory=True # 如果使用 GPU,设为 True 可能加速内存拷贝
)
# 验证数据加载器
val_loader = torch.utils.data.DataLoader(
# 使用上面划分出的 val_idx 创建验证数据集
GalaxyDataset(train_df[0].iloc[val_idx].values, train_df[1].iloc[val_idx].values,
# 定义应用于验证/测试图像的变换 (通常不包含随机数据增强)
transforms.Compose([
transforms.Resize((256, 256)), # 调整图像大小
transforms.ToTensor(), # 转换为张量
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 标准化
])
),
batch_size=20, # 批次大小
shuffle=False, # 验证集不需要打乱顺序
num_workers=10, # 使用 10 个子进程加载数据
pin_memory=True
)
# --- 初始化模型、损失函数和优化器 ---
model = get_model1().cuda() # 创建模型实例并将其移动到 GPU
criterion = nn.CrossEntropyLoss().cuda() # 定义交叉熵损失函数,并移动到 GPU
optimizer = torch.optim.Adam(model.parameters(), 0.005) # 定义 Adam 优化器,设置学习率为 0.005
# --- 训练循环 ---
for epoch in range(5): # 训练 5 个轮次
print('Epoch: ', epoch) # 打印当前轮次
# 执行一个轮次的训练
train(train_loader, model, criterion, optimizer, epoch)
# 在验证集上评估模型
val_acc = validate(val_loader, model, criterion)
# 打印当前轮次的验证准确率
print("Val acc", val_acc)
# --- 预测函数 ---
def predict(test_loader, model):
"""使用训练好的模型在测试集上进行预测"""
# 将模型切换到评估模式
model.eval()
pred = [] # 用于存储预测结果的列表
# 在预测时不需要计算梯度
with torch.no_grad():
end = time.time() # 原始代码中的计时
# 遍历测试数据加载器
# 注意:这里的 target 是我们为测试集设置的占位标签,预测时不需要使用
for i, (input, target) in enumerate(test_loader):
# 将输入数据移动到 GPU
input = input.cuda()
# target = target.cuda() # 目标标签在预测时不需要移动到 GPU
# 模型前向传播获取输出
output = model(input)
# loss = criterion(output, target) # 预测时通常不需要计算损失
# 获取概率最高的类别索引作为预测结果,并转换为 numpy array
# .cpu() 将结果从 GPU 移回 CPU
# .numpy() 将 PyTorch 张量转换为 NumPy 数组
pred += list(output.argmax(1).long().cpu().numpy())
# 返回包含所有预测结果的列表
return pred
# --- 加载测试数据并进行预测 ---
# 读取测试文件列表 (A.txt),假设 tab 分隔,无表头
test_df = pd.read_csv("data/A.txt", sep="\t", header=None)
# 为测试图像文件名添加路径前缀
test_df["path"] = 'data/A/' + test_df[0]
# 为测试数据添加一个占位标签列 (因为 GalaxyDataset 需要标签输入,但预测时不用)
test_df["label"] = 1
# 创建测试数据加载器
test_loader = torch.utils.data.DataLoader(
# 使用测试数据的文件路径和占位标签创建数据集
GalaxyDataset(test_df["path"].values, test_df["label"].values,
# 使用与验证集相同的图像变换
transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
),
batch_size=20, # 批次大小
shuffle=False, # 测试集不需要打乱顺序
num_workers=10, # 使用 10 个子进程
pin_memory=True
)
# 调用 predict 函数获取预测结果 (整数索引列表)
pred = predict(test_loader, model)
# --- 后处理与保存结果 ---
# 将整数预测结果列表转换为 NumPy 数组
pred = np.stack(pred)
# 创建反向映射字典,用于将整数索引转换回中文标签
inverse_mapping_dict = {v: k for k, v in mapping_dict.items()}
# 定义一个向量化的函数,将反向映射应用到整个 NumPy 数组上
inverse_transform = np.vectorize(inverse_mapping_dict.get)
# 将整数预测数组转换为中文标签数组
test_df["label"] = inverse_transform(pred)
# 选择原始文件名列 (第 0 列) 和包含中文标签的 'label' 列
# 将这两列保存到 submit.txt 文件中,使用 tab 分隔,不包含索引和表头
test_df[[0, "label"]].to_csv("submit.txt", index=None, sep="\t", header=None)
提交结果


















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









