






- 微调范式:(1) 增量预训练微调:让底座模型(foundation)学习一些垂直领域的知识。(2) 指令跟随微调:让模型学会与人类对话。
- 一条数据的一生:(1) 原始数据:从书籍、网络等渠道获得的信息。(2) 标准格式数据:训练框架可以识别的数据格式。比如获取信息为世界最高峰为珠穆朗玛峰,那么在AI模型中应该转换为有system、user、assistant的格式,而在xtuner中为json文件格式。(3) 添加对话模板:为了区分user和assistant,需要在各自出现的时候添加对应的前缀,因此当数据投喂给模型时会转变为拥有前缀的对话。(4) Tokenized数据:将数据打包。(5) 添加Label。 (6) 开始训练。
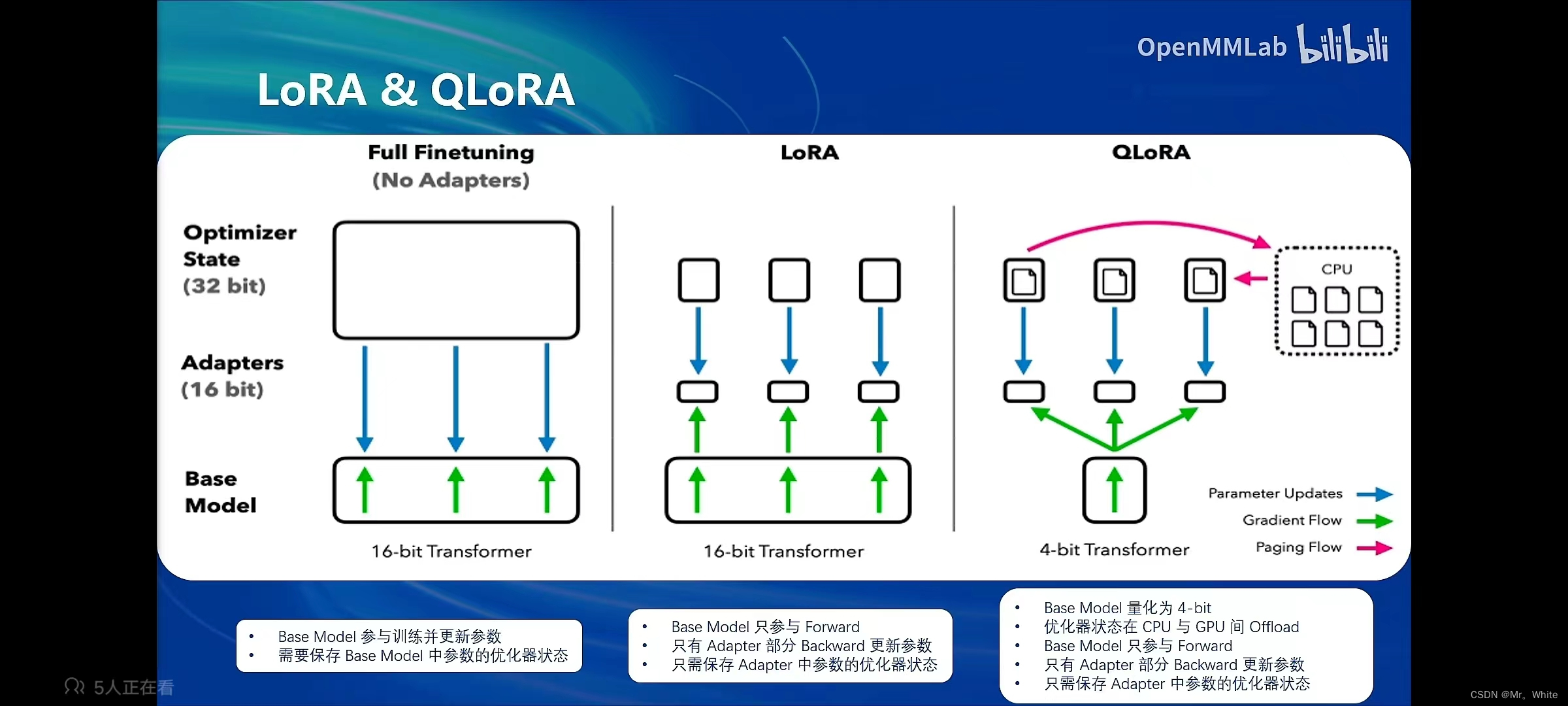
- LoRA和QLoRA:(1) LoRA模型:如果对所有参数进行微调,那么需要很大的显存,LoRA模型可以规避这一问题。形象理解就是只更改部分零件,算法中为增加分支。(2) QLoRA方法在模型载入显存的时候采用特殊方法使得模型载入的时候 进行一些简化,从而减小显存的负担。
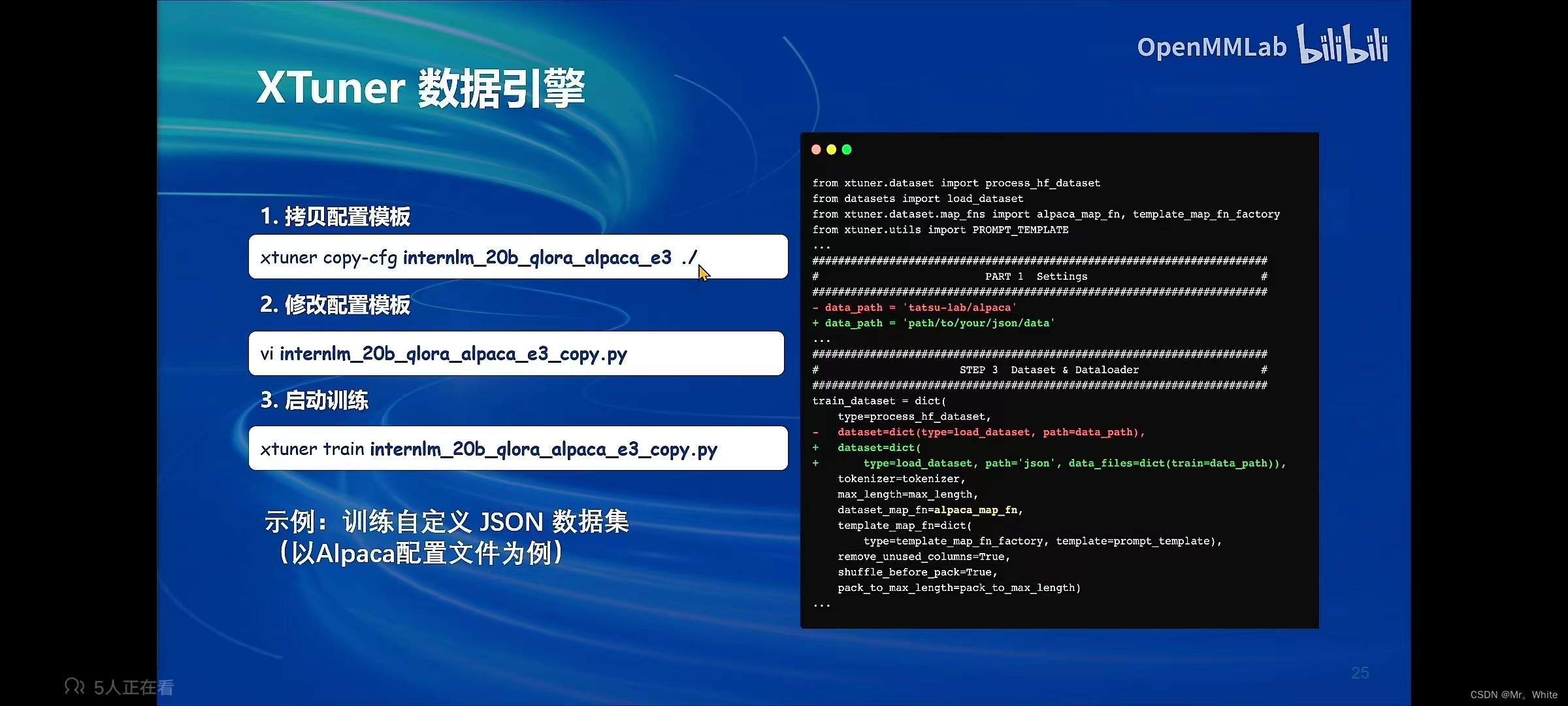
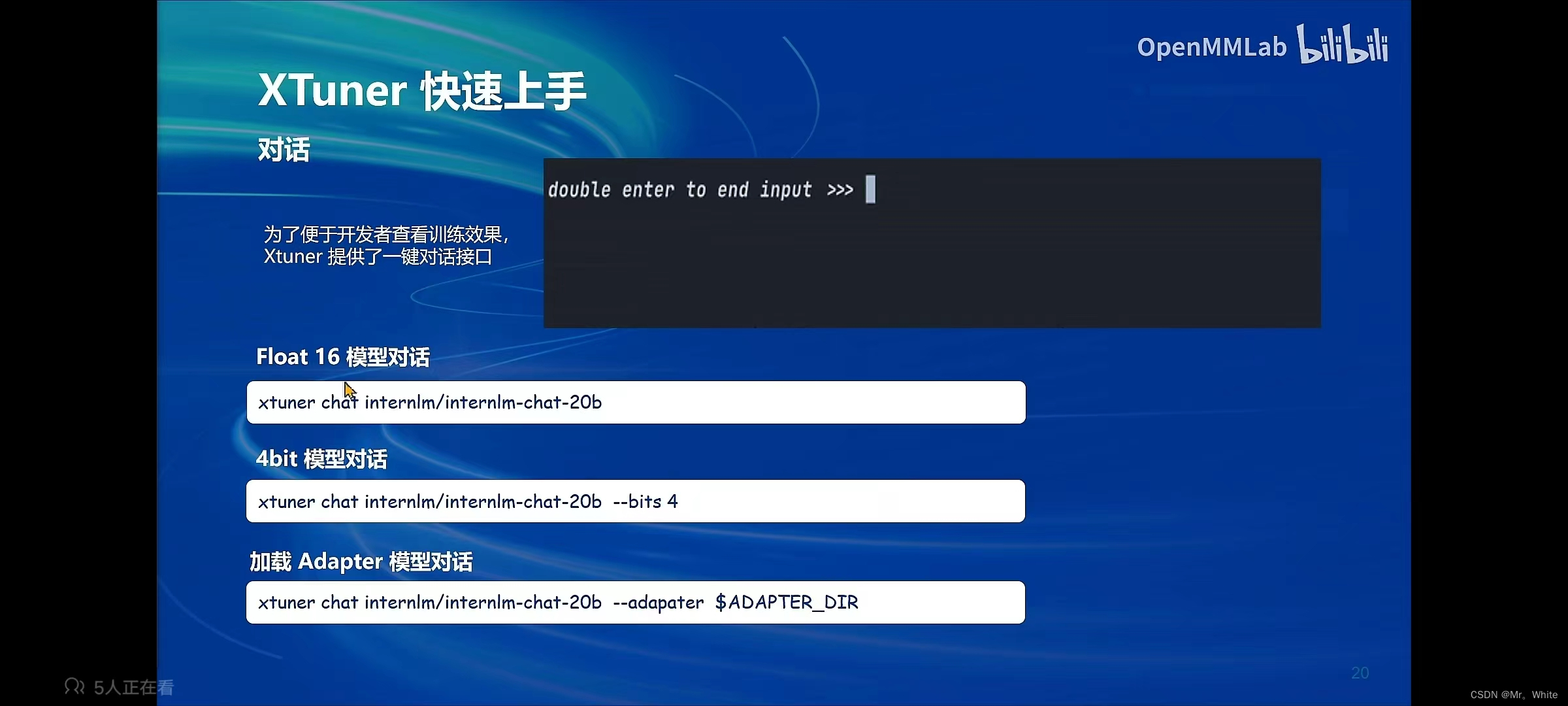
- Xtuner:(1) 含有多种微调算法、拥有加速服务、适配多种硬件。
- LLM模型:(1) 多模态LLM原理:对文本和图像进行向量化处理,载入LLM,最终输出文本。

















01-28
 408
408
408
06-25
127
127
03-04
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









