






OpenCompass 大模型评测
- 如何通过能力评测促进模型发展:(1) 面向未来拓展能力维度,增加注入数学的新能力维度 (2) 扎根通用能力、聚焦垂直行业,需要结合行业知识和规范,以评估行业适用性 (3) 高质量中文基准,针对中文场景,促进中文社区的大模型发展 (4) 性能评测反哺能力迭代,探索模型能力形成机制,针对性提升
- 大语言模型评测中的挑战:(1) 全面性:场景千变万化、模型能力演进迅速 (2) 评测成本:需要大量算力资源、主管评测成本高昂 (3) 数据污染:海量语料会给评测集带来污染,需要可靠的数据污染检测技术,设计可动态更新的高质量评测基准 (4) 鲁棒性:对提示词十分敏感且性能不稳定
- 如何评测大模型:(1) 基座模型:海量数据无监督训练 (2) 对话模型:指令数据有监督微调、人类偏好对齐 (3) 公开权重的开源模型:使用GPU/推理加速卡进行本地推理 (4) API模型:发送网络请求获取回复
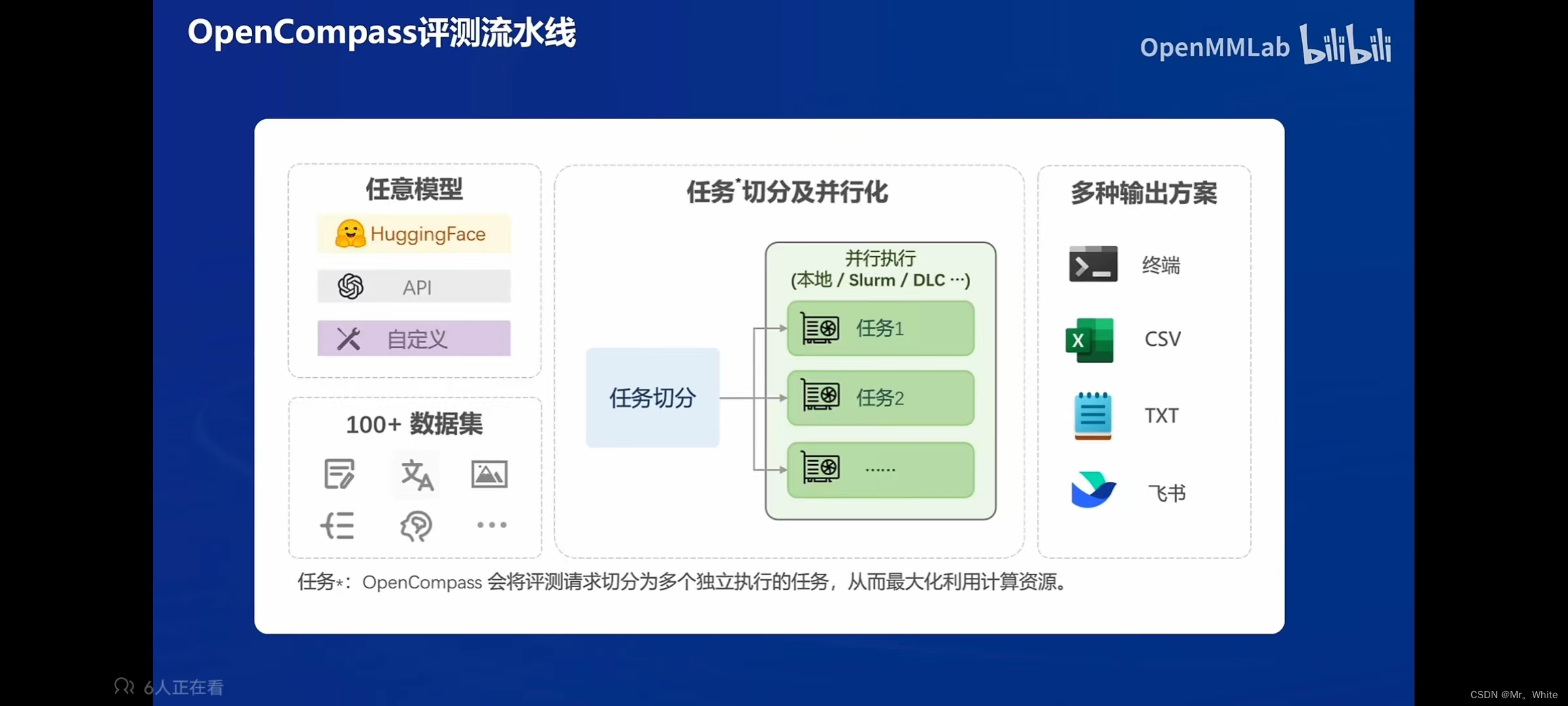
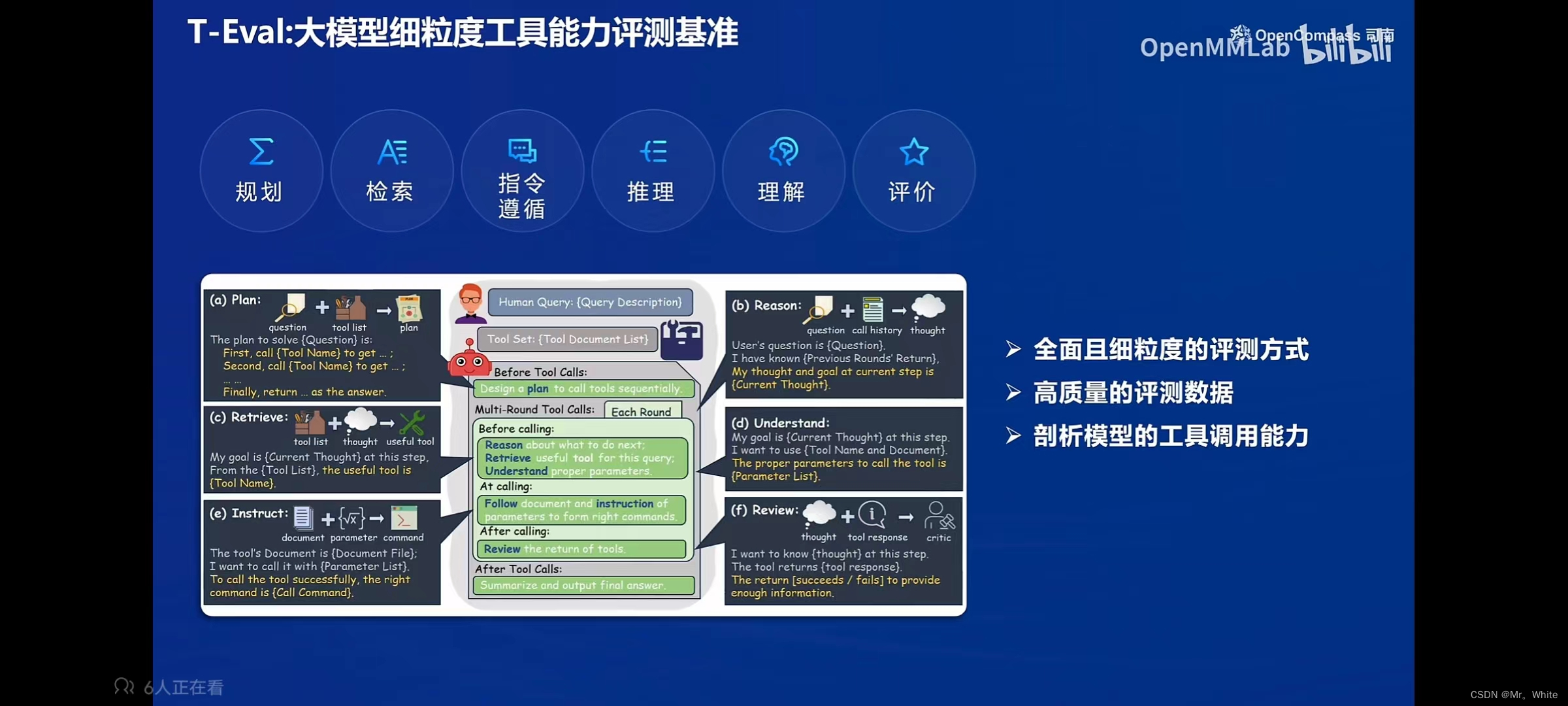
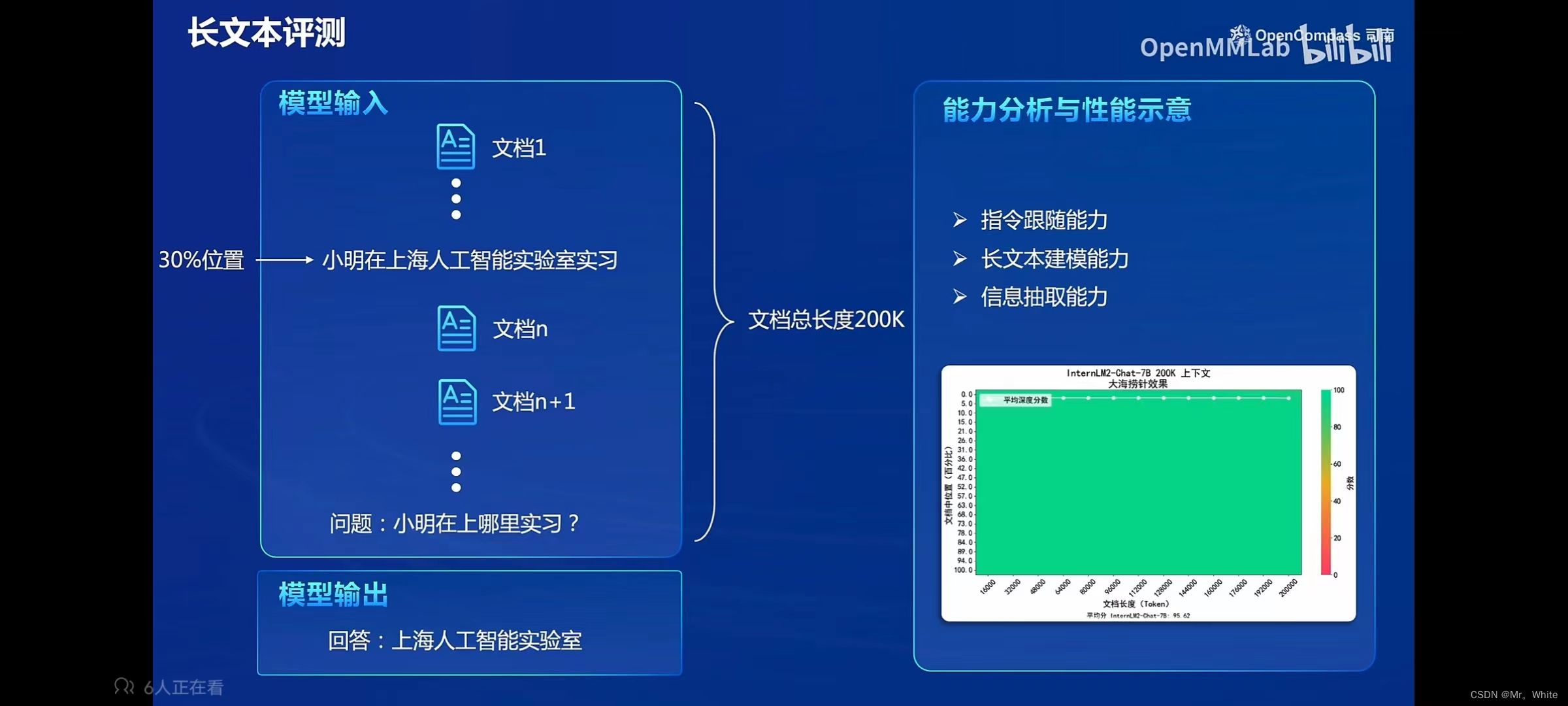
- 需要有客观评测和主观评测、提示词工程、长文本评测、工具-基准-榜单三位一体
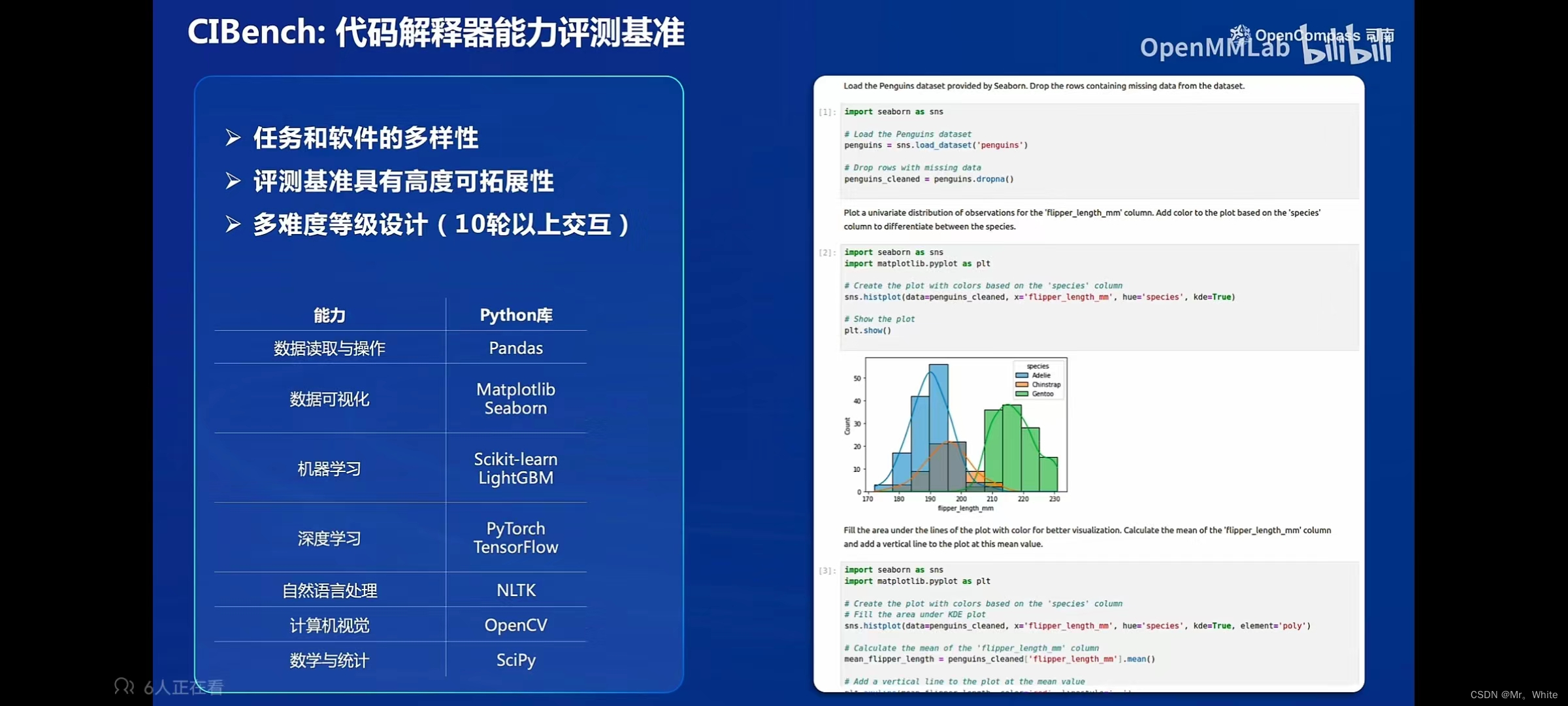
- CompassKit:VLMEvalKit多模态评测工具、代码评测工具、MixtralKit MoE模型入门工具




















 127
127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









