






LMDeploy量化部署
1. 模型部署:将已经训练好的模型放到特定的环境中运行。由于最后模型需要应用到业务场景,因此通常需要把模型部署到服务器或移动端。
2. 模型在部署时会遇到的问题和困难:
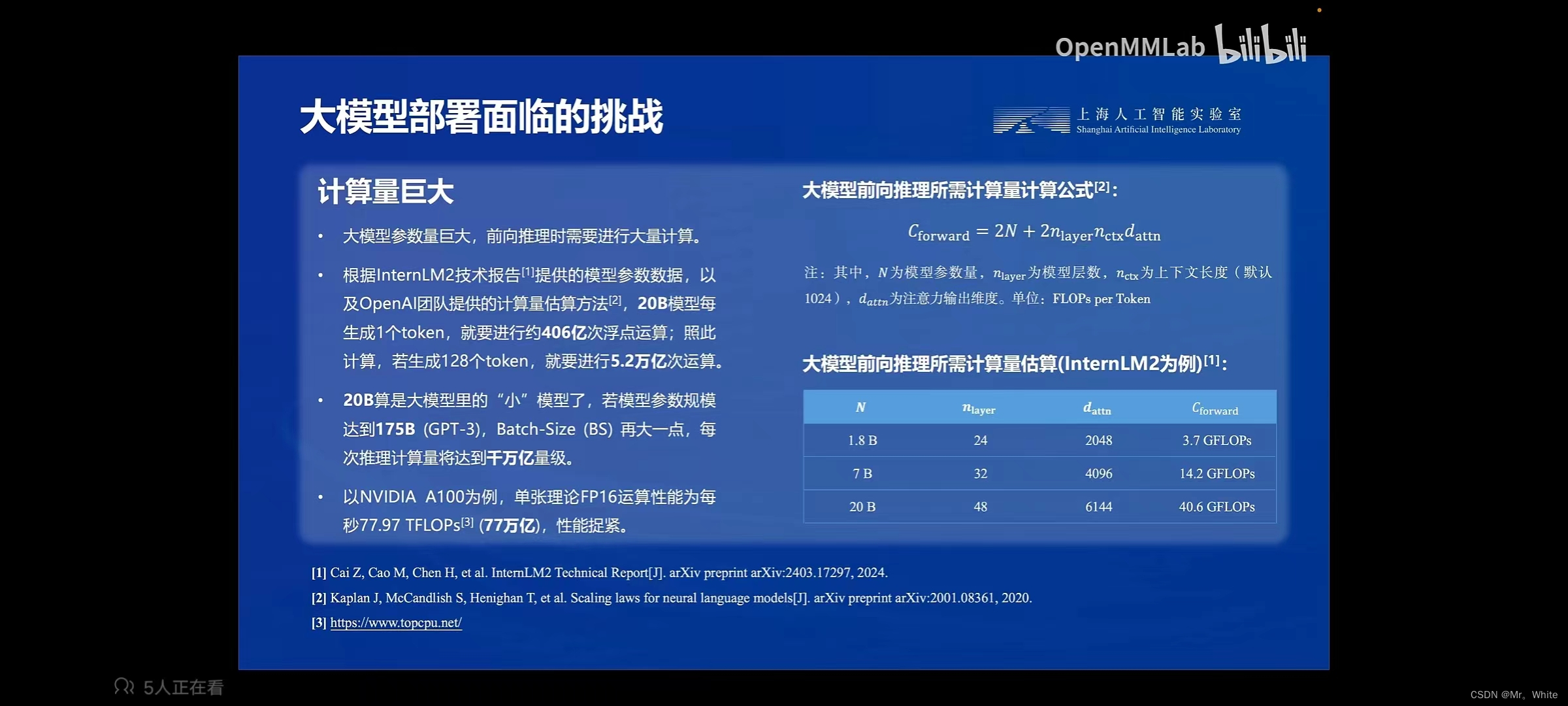
(1) 计算量巨大。
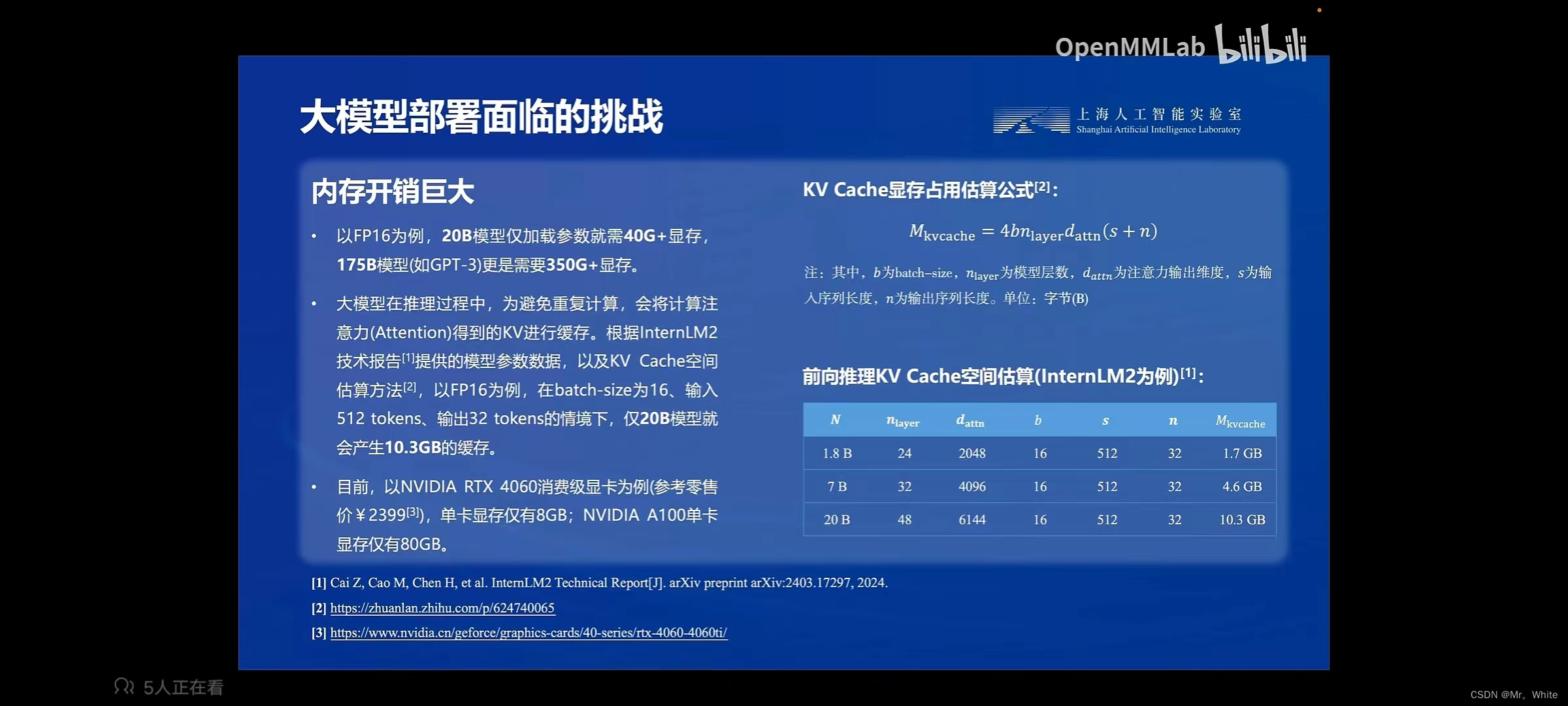
(2) 内存开销巨大。
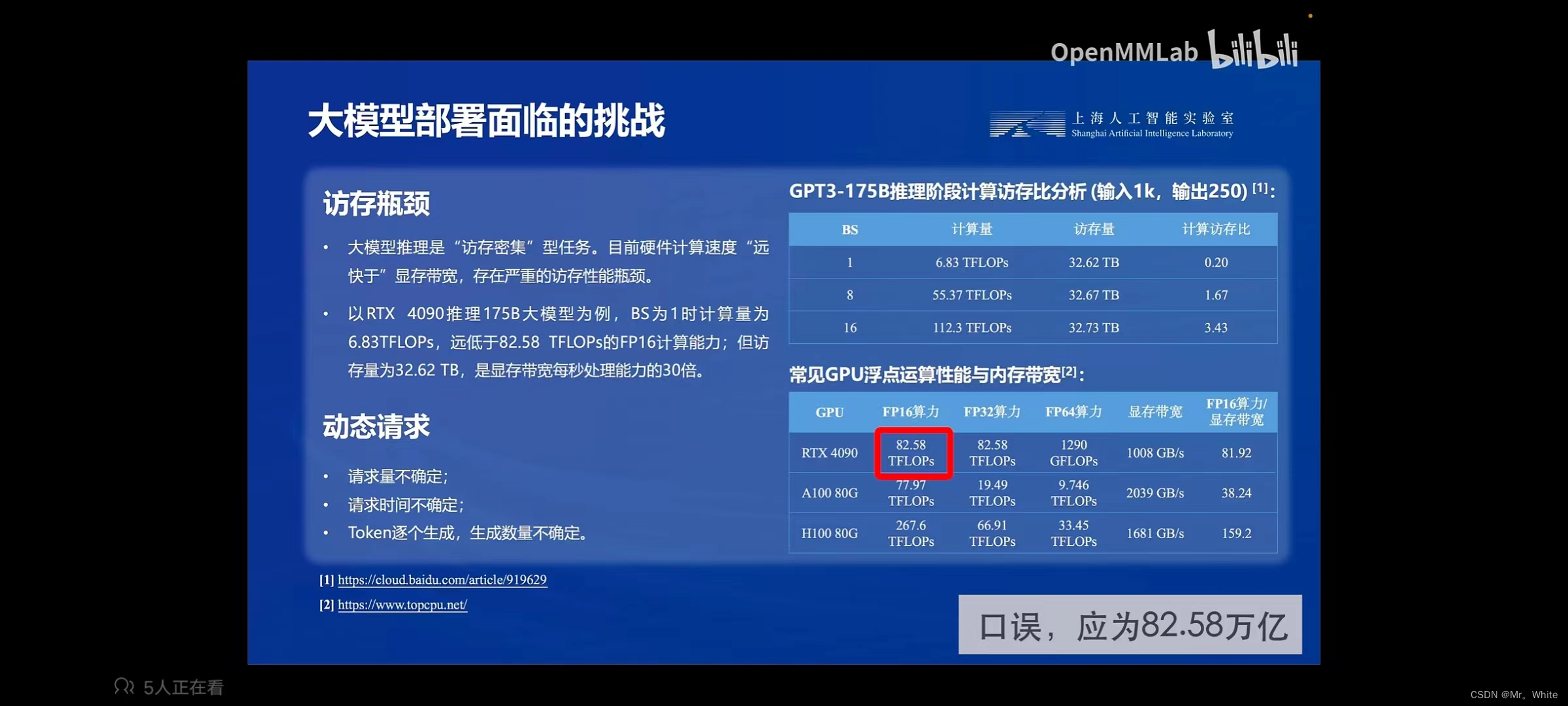
(3) 访存密集,访存量大。
(4) 动态请求,请求量和请求时间不确定。
3. 大模型部署的方法:
(1) 模型剪枝:减少模型中贡献有限的冗余参数,保证性能下降最低的情况下减少存储需求,提高计算效率。包括非结构剪枝(不考虑整体网络而移除部分参数)和结构化剪枝(在考虑整体网络的前提下移除参数)。
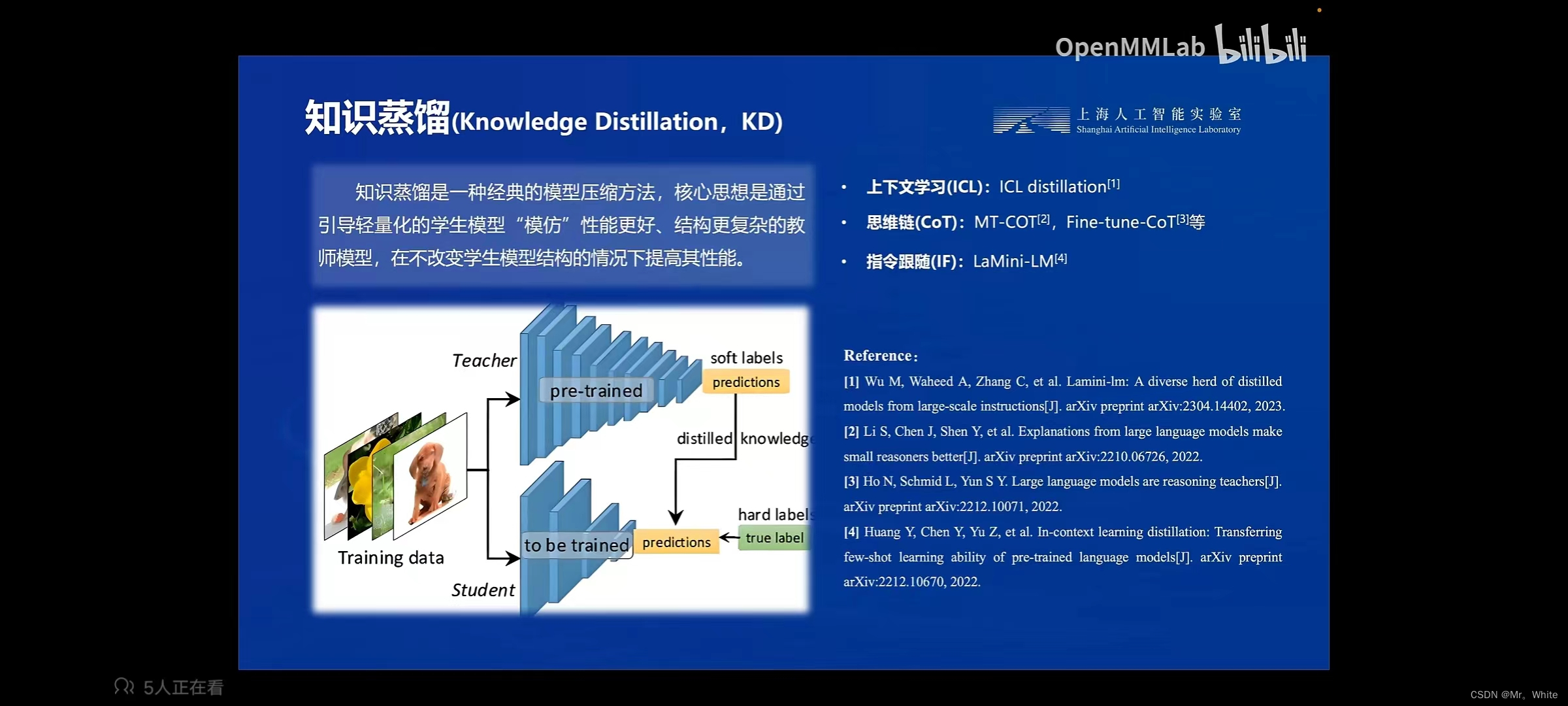
(2) 知识蒸馏:直接训练参数量小的模型难度大,可以先通过训练参数量大的模型,再让大模型训练小模型就可以提高效率。
(3) 量化:将浮点数转化为整数形式来减轻存储和计算负担。包括量化感知训练(量化目标无缝地集成到模型的训练过程中)、量化感知微调(确保微调的LLM仍能保持性能)和训练后量化(减少LLM的存储和计算复杂性,而无需对LLM架构进行修改或进行重新训练)
4. LMDeploy:(1) 核心功能:模型高校推理、模型量化压缩、服务化部署

















 240
240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









