






1.创建开发机以及配置环境下载模型


2.运行模型
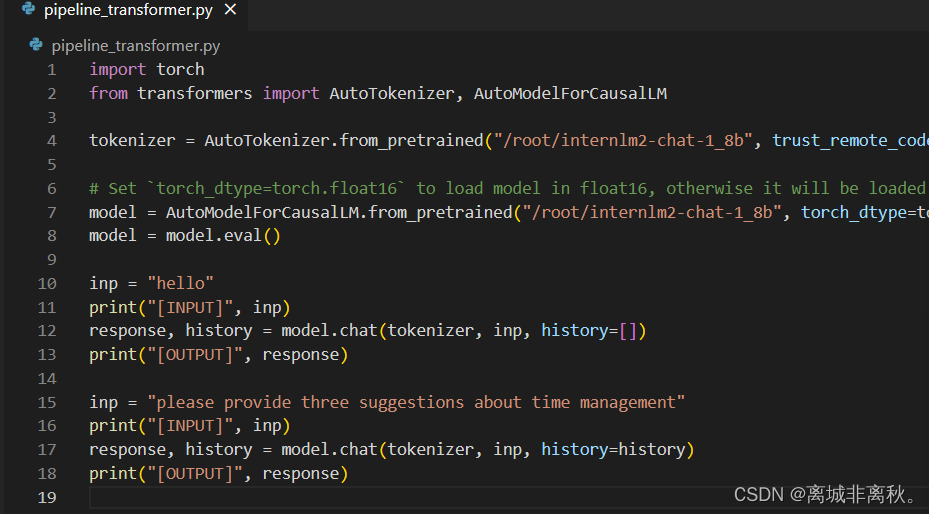

3.使用LMDeploy与模型对话

速度要快很多
4.模型量化
首先保持不加该参数(默认0.8),运行1.8B模型,与模型对话,查看右上角资源监视器中的显存占用情况。

下面,改变--cache-max-entry-count参数,设为0.5。与模型对话,再次查看右上角资源监视器中的显存占用情况。
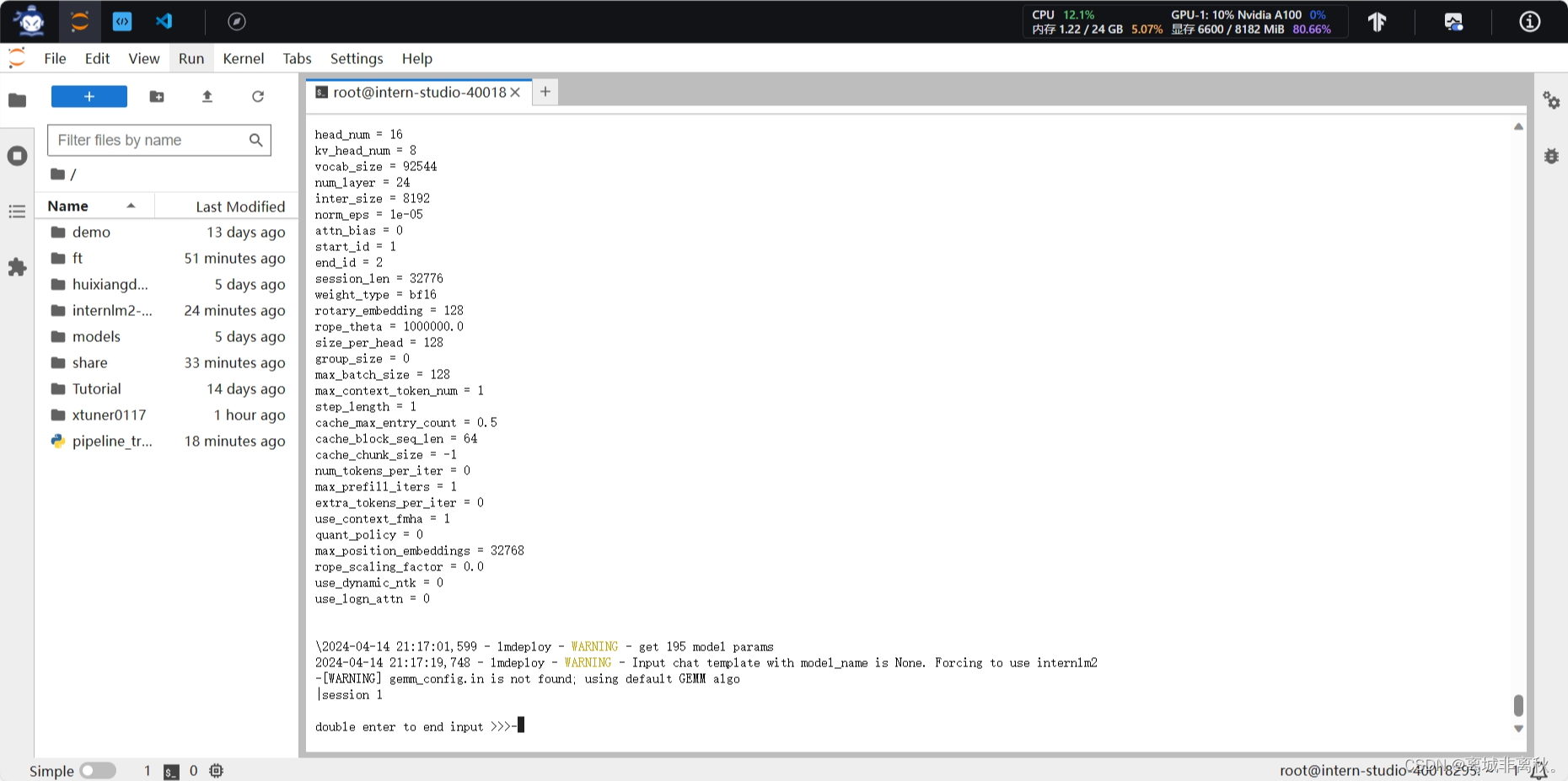
把--cache-max-entry-count参数设置为0.01,约等于禁止KV Cache占用显存。然后与模型对话,可以看到,此时显存占用仅为4560MB,代价是会降低模型推理速度。
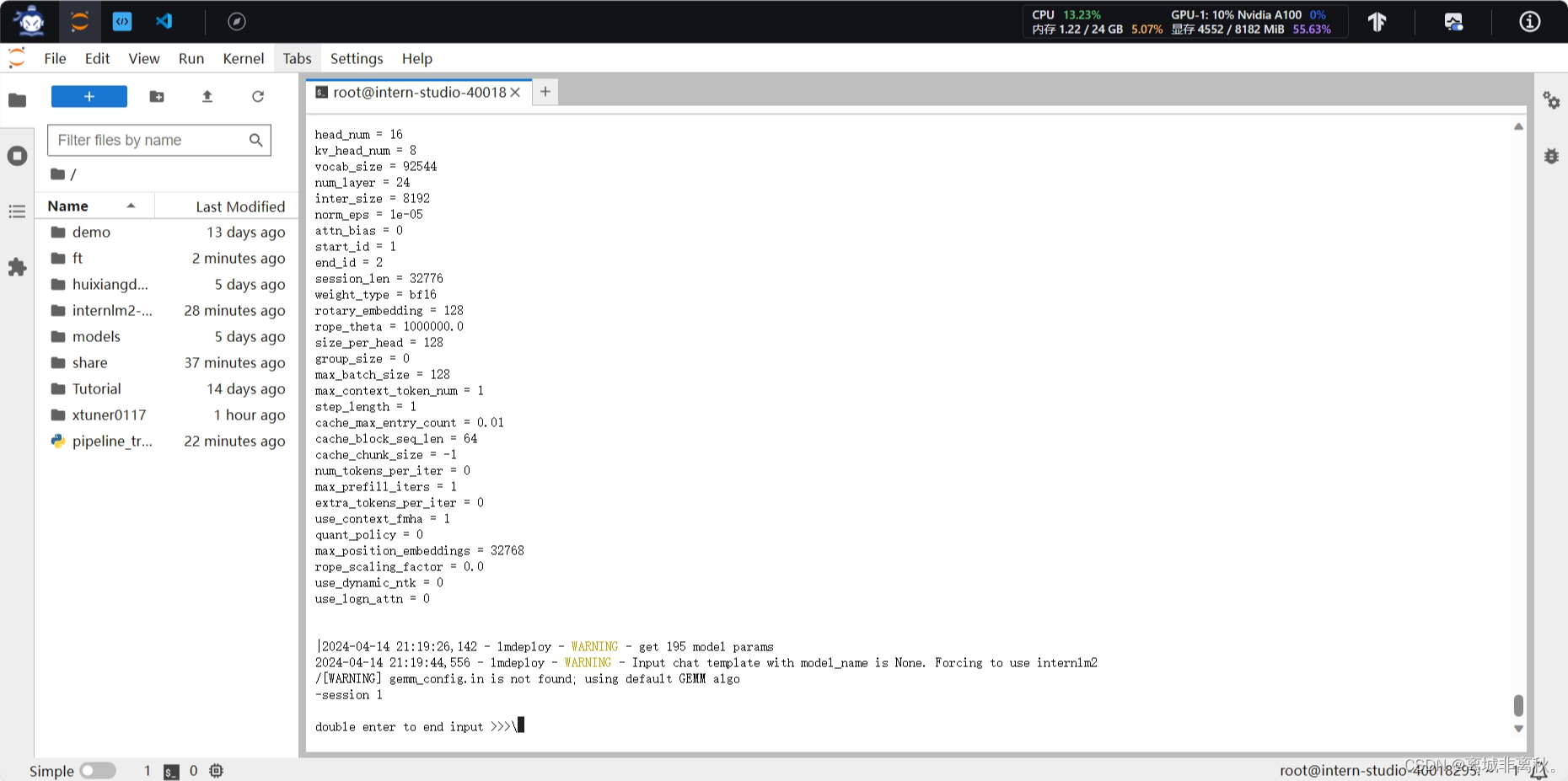
5.量化:运行命令后得到量化后的模型
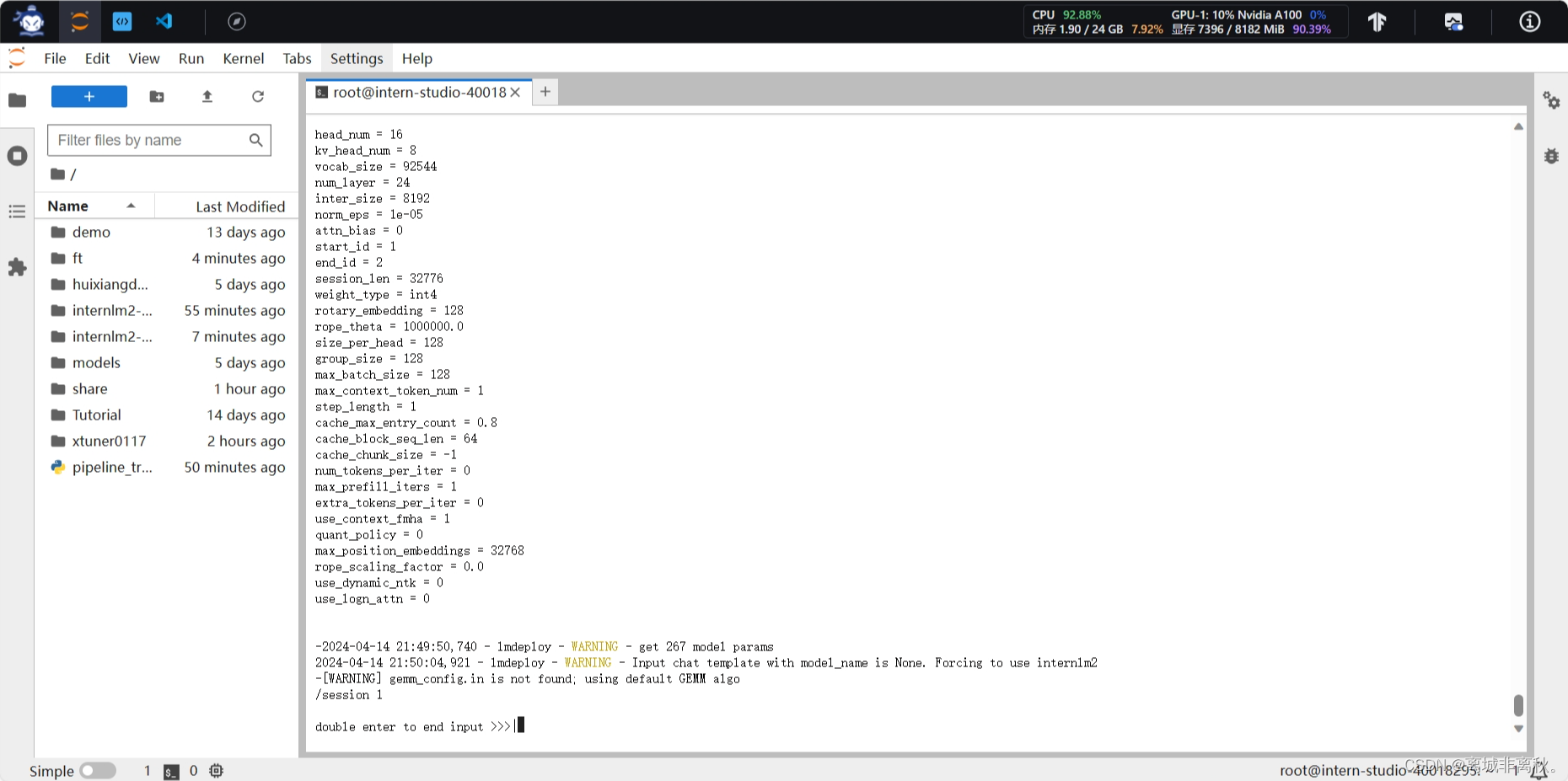
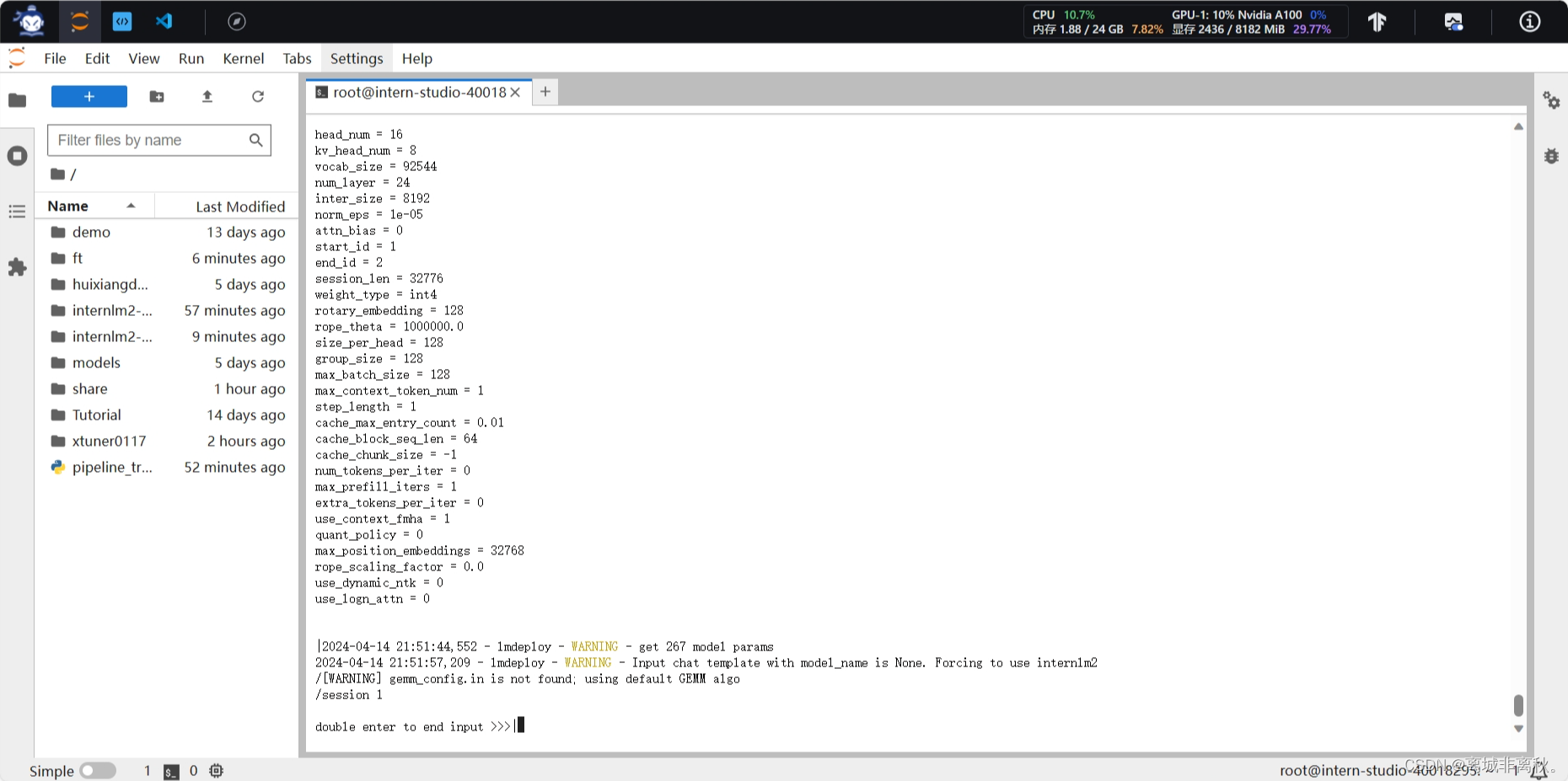
为了更加明显体会到W4A16的作用,我们将KV Cache比例再次调为0.01,查看显存占用情况。看到,显存占用变为2472MB,明显降低。
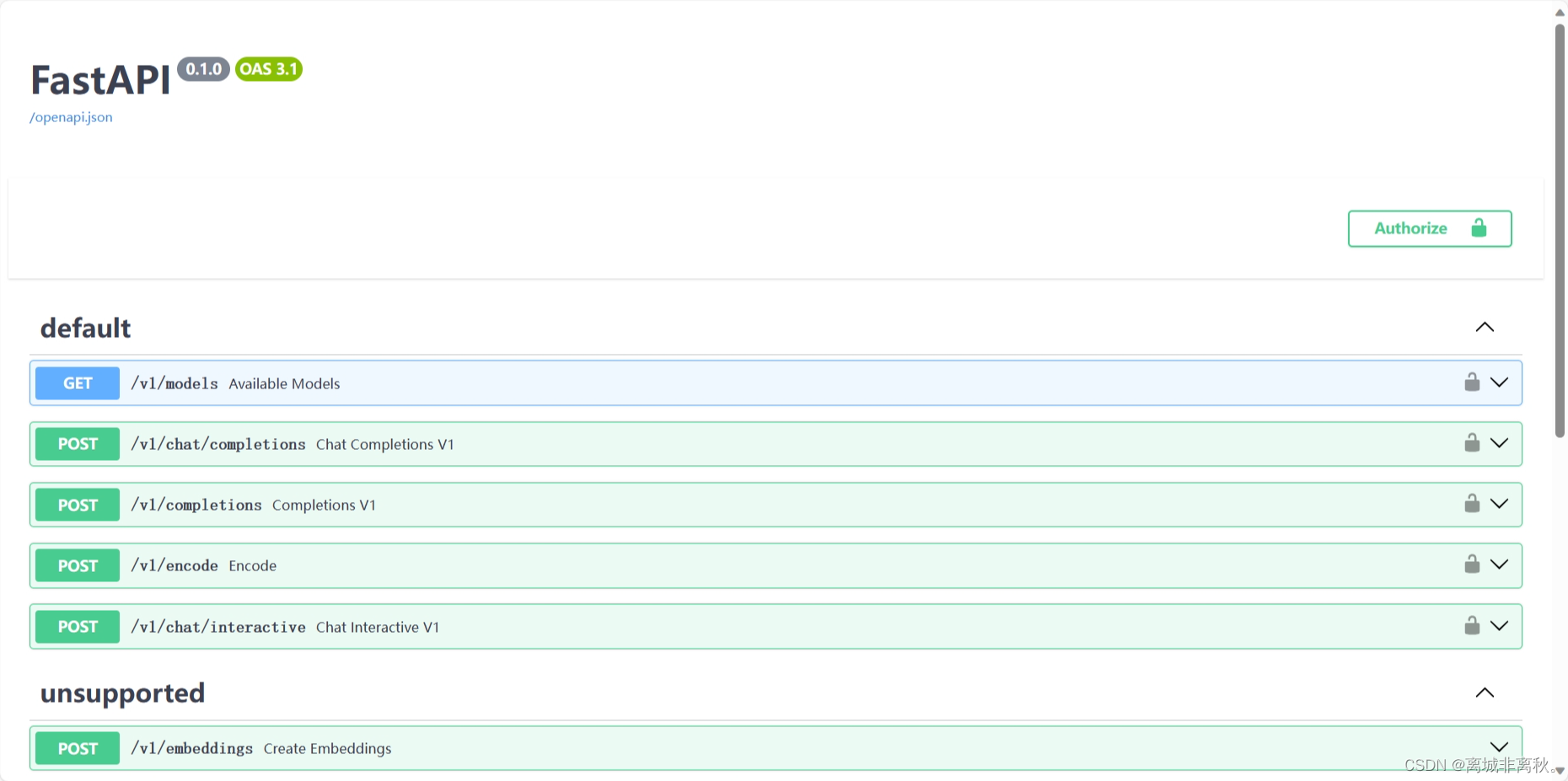
6.启动api服务器
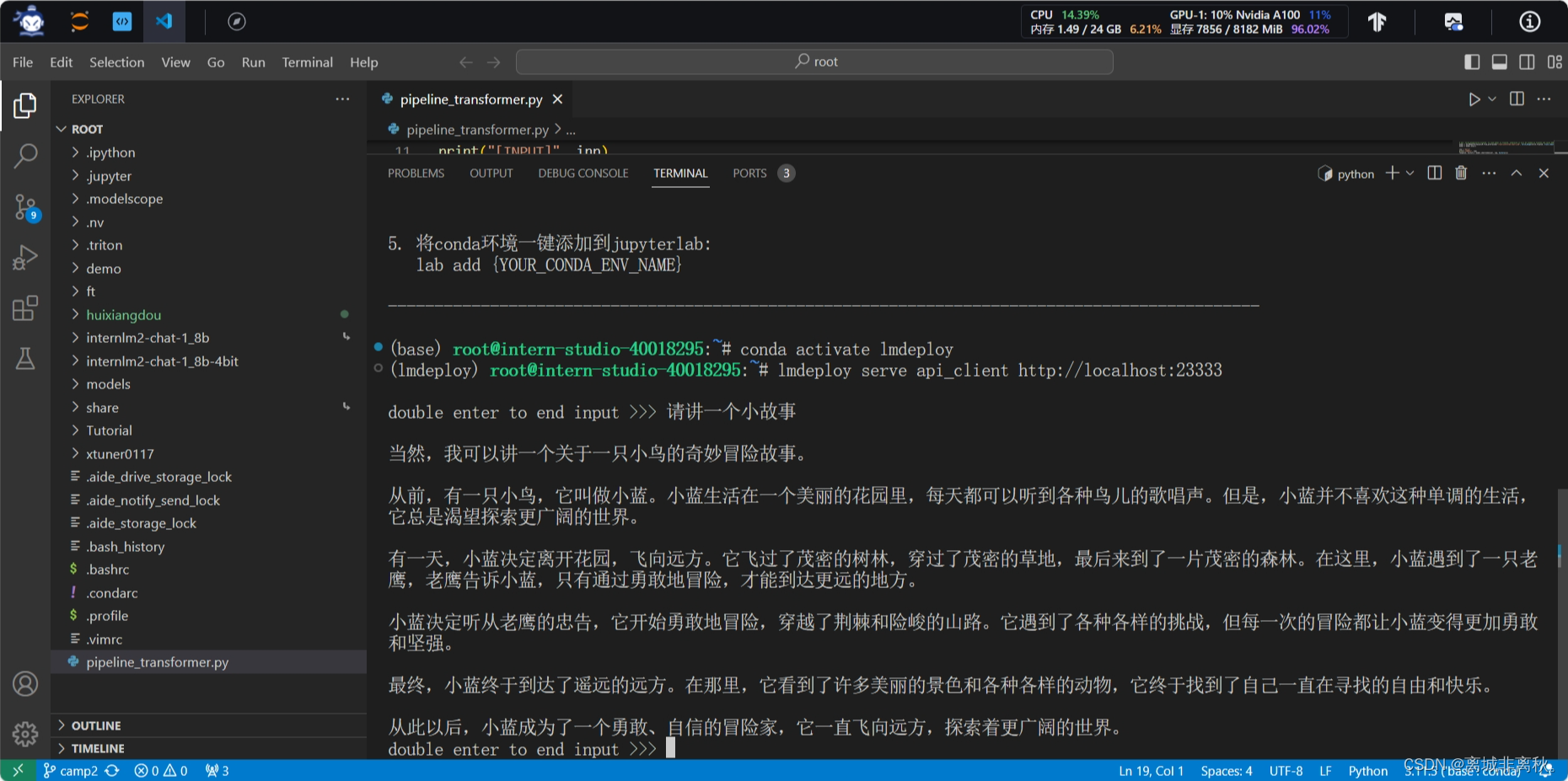
在vscode终端直接通过命令行窗口与模型对话
网页端我死活加载不出来,放弃了
7.python代码集成并向传递参数


拓展部份我的网页端一直打不开并且说我的显存不够,好像10%太少了
 ...遂放弃
...遂放弃















 440
440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









