






联邦学习:
初始阶段
服务器:初始化全局模型,状态准备(模型权重、偏置等),以便分发给参与训练的客户端。
配置联邦学习的参数(迭代轮数、学习率、参与客户端的采样策略等)
客户端:等待服务器发起训练请求或主动向服务器请求参与训练。
接收全局模型后,准备本地训练数据。
训练阶段
主函数/协调逻辑:触发训练过程,根据配置选择参与本轮训练的客户端。
服务器将全局模型分发给选定的客户端。
服务器:将当前的全局模型状态打包并发送给选定的客户端。
等待客户端上传本地训练后的模型更新。
客户端:从服务器下载全局模型。
使用本地数据训练模型,计算本地模型的更新(如权重梯度)。
将本地模型的更新上传给服务器。
聚合阶段
服务器:接收来自各个客户端的模型更新。
使用聚合算法将客户端模型更新合并全局模型中,生成新的全局模型状态。
主函数/协调逻辑:监控聚合过程的进度,准备进行下一轮迭代(如果未达到预设的迭代轮数)。
迭代与收敛:重复训练阶段和聚合阶段,直到全局模型收敛
每轮迭代后,评估全局模型的性能。
全局模型的分发、本地训练、模型更新的上传、聚合以及可能的再分发
每个本地客户端都持有一组独特的训练数据,并且各自训练自己的模型副本(即局部模型)。这些局部模型在训练过程中会学习到基于本地数据的模型参数(权重和偏置)。然后,这些参数(或者它们的某种形式,如参数的更新量)会被发送到中央服务器(或聚合器),中央服务器会以一种隐私保护的方式(如使用差分隐私、安全多方计算等技术)来汇总这些信息,并据此更新全局模型!!!???。
全局模型的更新不是直接“决定”本地客户端的模型参数,而是提供了一种机制,使得本地客户端在后续的训练过程中能够利用来自其他客户端的知识。这种机制通常是通过将全局模型的更新(或其部分)分发回本地客户端,并与本地模型的当前状态进行合并(例如,通过加权平均)来实现的。
因此,虽然全局模型在联邦学习中起着协调和汇总的作用,但它并不直接“指导”本地客户端的训练过程,而是通过共享和更新机制来促进整个系统的知识共享和性能提升。每个本地客户端仍然保留其独特的模型参数,并根据其本地数据和全局更新来调整这些参数。
模型参数(Model Parameters)
模型参数是模型在训练过程中自动学习到的参数。它们是模型为了最小化某个损失函数(比如均方误差、交叉熵等)而不断调整的数值。在神经网络中,这些参数主要包括:
- 权重(Weights):连接不同神经元之间的参数,决定了输入数据对输出的影响程度。
- 偏置(Biases):也称为偏移项或截距项,它们为每个神经元的输出提供一个基础值。
超参数(Hyperparameters)
超参数是在模型训练之前设置的,而不是通过训练过程学习得到的。它们控制训练过程本身,比如:
- 学习率(Learning Rate):决定了在优化过程中参数更新的步长大小。
- 批次大小(Batch Size):每次梯度更新时使用的样本数量。
- 迭代次数(Epochs):整个训练集被遍历的次数。
- 网络结构(Network Architecture):比如层数、每层的神经元数量等。
- 正则化参数(Regularization Parameters):如L1、L2正则化项的强度,用于防止过拟合。
实际应用
在机器学习和深度学习的实际应用中,模型参数(如权重和偏置)通常是通过反向传播算法等优化算法在训练数据上自动学习的。而超参数则需要人工设置,并可能需要通过交叉验证等方法进行调优,以找到最优的组合。
总结来说,model_parameters 主要指的是模型参数,即模型在训练过程中学习和调整的权重和偏置等参数,而超参数则是控制模型训练过程的参数,需要手动设置。
结合fedavg代码解读:
model.py
模型注册表,用户通过装饰器的方式注册模型类,名称检索模型类实例。
# 初始化模型注册表
model_registry = {}'''模型名称(字符串)到模型类(Python类)'''
#注册模型的装饰器函数
def register_model(name):
def decorator(cls):
'''关键用法一'''
model_registry[name] = cls '''#字典中键name对应的对值cls'''
print(f"Model {name} registered for class {cls.__name__}")
return cls
return decorator
#从注册表中获取模型类的实例
def get_model(name):
"""不存在则抛出错误。"""
'''关键用法二'''
model_cls = model_registry.get(name) ''' # 尝试获取与给定名称关联的类 '''
if model_cls is None:
raise ValueError(f"Model '{name}' not found in registry.")
return model_cls()
# 自动导入所有子模块以确保它们被注册
from .mnist import *
from .emnist import *
from .cifar10 import *register_model函数是一个高阶函数,它接收一个字符串name作为参数,并返回一个装饰器函数decorator。- 装饰器函数
decorator接收一个类cls作为参数,并将这个类与提供的模型名称name关联起来,存储在全局的model_registry字典中。 - 同时,装饰器打印一条消息,说明已经为哪个类注册了哪个模型名称。
- 最后,装饰器返回类本身,这样它就可以在不改变类原有行为的情况下被“附加”额外的功能(在这个例子中是注册到注册表)。
- 这些子模块(
mnist、emnist、cifar10)应该包含了使用@register_model装饰器注册的模型类。 - 当这些模块被导入时,它们的顶级代码(即不在任何函数或类定义内部的代码)将被执行。如果这些模块中包含了使用
@register_model装饰的类定义,那么这些类就会在导入过程中被自动注册到model_registry中。
client.py
class Client:
def __init__(self, data, config, client_id):
self.client_id = client_id
self.config = config
self.model = get_model(config['model'])
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.model.to(self.device)
# self.model.device = self.device
self.batch_size = config['base_config']['batch_size']
self.data_loader = DataLoader(data, batch_size=self.batch_size, shuffle=True)
self.learning_rate = config['base_config']['learning_rate']
self.epochs = config['base_config']['epochs']
self.privacy_method = config['privacy_protection']
self.is_malicious = np.random.rand() < config['malicious_rate']
def load_global_model(self, model_parameters):#加载全局模型,其实是加载全局模型参数
"""Load model parameters received from the server."""
self.model.load_state_dict(model_parameters)
def train(self):
"""训练模型 """
optimizer = torch.optim.Adam(self.model.parameters(), lr=self.learning_rate)
self.model.train()
total, correct = 0, 0
for epoch in range(self.epochs):
for data, target in self.data_loader:
data, target = data.to(self.device), target.to(self.device)
optimizer.zero_grad()
output = self.model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
# 计算准确率
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
accuracy = 100 * correct / total
print(f"Client {self.client_id} - Epoch {epoch + 1}: Loss = {loss.item()}, Accuracy = {accuracy}%")
def send_model_to_server(self):
"""Prepare and send the model update to the server."""
update = self.model.state_dict()
if self.is_malicious:
self.perform_attack(update) # Modify the update if client is malicious
return update
def apply_privacy_protection(self):
"""Apply the configured privacy protection method."""
print(f"Applying privacy protection: {self.privacy_method}")
def perform_attack(self, update):
"""Simulate a malicious attack by modifying the model parameters."""
print("Performing malicious attack on the model by modifying parameters.")
def run(self, model_parameters):
"""Receive parameters, train, apply privacy (if any), and send the model back."""
self.load_global_model(model_parameters)
self.train()
if self.privacy_method != "None":
self.apply_privacy_protection()
self.send_model_to_server()__init__
self.client_id = client_id # 客户端的唯一标识符
self.config = config # 客户端的配置信息
加载模型,移动设备,设置参数
load_global_model
(从服务器全局模型中加载模型参数,即加载一些与本地模型有关的参数来自于本地模型的)
(取之于客户端用之于客户端),模型参数取自于客户端,服务器进行一定处理融入了全局模型,这里再取出来模型参数,更新本地模型
全局模型参数加载到本地模型==
从全局模型中加载模型参数==
将服务器上的模型参数加载到本地模型
将服务器上的模型参数加载到本地客户端模型实例中,利用这些参数来更新本地模型的权重
self.model = get_model(config['model']) def load_global_model(self, model_parameters):
"""Load model parameters received from the server."""
self.model.load_state_dict(model_parameters)
往本地模型中加载 ?不应该是本地模型给全局模型的吗
load_global_model接收一个参数model_parameters, 加载到self.model中
self.model:实例,与从服务器接收到的model_parameters相匹配的架构。model_parameters:含模型参数的字典,从服务器发送过来的,更新本地模型的权重。包含了需要加载到本地模型中的所有参数((权重和偏置))
model_parameters
(模型参数传给服务器后服务器用于更新全局模型,这里由服务器再传给客户端)
参数model_parameters不应该是来自客户端本地吗,为什么要从服务器中加载
其中模型参数是在多个客户端之间进行共享和更新的,但最终这些参数的“全局”版本(即包含了所有客户端贡献的更新)被存储在服务器上。
参数 model_parameters 实际上是从服务器加载的,而不是从客户端本地加载的。
在这个场景下,服务器通常扮演着中心协调者的角色,它负责:
- 初始化全局模型参数。
- 接收来自各个客户端的模型更新(这些更新可能是在本地数据上训练后得到的参数变化)。
- 聚合这些更新来更新全局模型参数(这通常涉及某种形式的平均或加权平均)。
- 将更新后的全局模型参数分发回客户端,以便它们可以在新的或相同的数据上继续训练。
当 load_global_model 函数被调用时,它的目的是将服务器上的最新全局模型参数加载到本地模型的实例中。这通常发生在以下情况之一:
- 客户端首次加入系统并需要初始化其本地模型时。
- 客户端完成了一轮或几轮本地训练,并准备从服务器获取最新的全局模型参数以继续训练时。
因此,尽管 model_parameters 最终会影响到客户端的本地模型,但它们最初是从服务器加载的,以反映所有客户端对全局模型的共同贡献。这种机制允许系统从分布在不同地点的多个数据源中学习,同时保护客户端数据的隐私。
如果 model_parameters 是从客户端本地加载的,那么这就不是分布式学习或联邦学习的典型场景了。在那种情况下,每个客户端都会使用自己的本地数据来训练模型,并且不会与其他客户端共享模型参数(除非通过某种形式的显式通信或数据共享)。但是,在联邦学习和类似的分布式学习框架中,模型参数的共享和更新是通过服务器来协调和管理的。
全局参数通常指的是在分布式学习或联邦学习场景中,所有客户端贡献的模型参数的聚合结果,这些参数是可以被所有客户端共享的。而超参数则不是通过训练过程学习的,也不需要在客户端之间共享或更新。
全局参数等价于模型参数
客户端接收到更新后的全局模型参数后,会将这些参数加载到其本地模型中,更新后的全局模型参数作为起点继续训练(使用了新的参数而新的参数即考虑了这个客户端又考虑了其他的客户端,相当于客户端能够利用从其他客户端学到的知识来改进其本地模型)
train
(给了一个示范写法,可用可不用)
def train(self):
"""训练模型 """
optimizer = torch.optim.Adam(self.model.parameters(), lr=self.learning_rate)
self.model.train()
total, correct = 0, 0
for epoch in range(self.epochs):#迭代轮数
for data, target in self.data_loader:#数据批次
data, target = data.to(self.device), target.to(self.device)
optimizer.zero_grad()
output = self.model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
# 计算准确率
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
accuracy = 100 * correct / total
print(f"Client {self.client_id} - Epoch {epoch + 1}: Loss = {loss.item()}, Accuracy = {accuracy}%")
## 注意这里的loss是最后一个batch的loss设置模型为训练模式:当你调用self.model.train()时,你告诉PyTorch你的模型即将进入训练阶段。在这个模式下,所有与训练相关的特定行为(如Dropout和BatchNorm层的行为)都会被激活。与self.model.train()相对应的是self.model.eval()方法,它用于将模型设置为评估模式。
-
.size(0):这个函数返回张量在第一维度(即批次大小)的大小。因此,target.size(0)给出了当前批次中样本的总数。 -
total += ...:这行代码将当前批次的样本数加到total变量上。total变量用于跟踪到目前为止处理过的总样本数。
-
Loss = {loss.item()}:loss.item()是获取loss张量(Tensor)中单个元素的值。在PyTorch中,即使loss是一个只包含一个元素的张量,你也需要使用.item()来获取其Python数值,而不是直接作为张量处理。
send_model_to_server
将本地客户端模型的更新发送到服务器(前面提到的一个过程)
apply_privacy_protection
perform_attack
run!!
run方法作为总结,方法将多个步骤封装在一起,轻松地调用整个流程,而无需在每个步骤中分别调用不同的方法
fedavg_client.py
from .client import Client
import torch
class FedAvgClient(Client):
def __init__(self, data, config, client_id):
super().__init__(data, config, client_id)
# 可以添加FedAvg特有的初始化代码
def train(self):
"""可能修改训练过程以适应FedAvg特有的训练需求"""
super().train() # 调用基类的训练方法
# 在这里可以添加FedAvg特有的训练后处理,比如调整学习率等
一个客户端(或设备)
from .client import Client:.表示当前包,相对导入,包内部模块之间的互相引用。
super,调用了父类,参数传递,正确初始化
server.py
class Server:
def __init__(self, model, test_data=None):
self.model = model
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.model.to(self.device)
self.batch_size = 32
self.test_loader = DataLoader(test_data, batch_size=32, shuffle=False)
self.client_updates = []
def initialize_model(self):
"""使用He初始化来初始化模型参数."""
for layer in self.model.modules():
if isinstance(layer, nn.Conv2d): # 检查当前层是否是卷积层(nn.Conv2d)
init.kaiming_normal_(layer.weight, mode='fan_out', nonlinearity='relu')
if layer.bias is not None:
init.constant_(layer.bias, 0)
elif isinstance(layer, nn.Linear):# 检查当前层是否是全连接层(nn.Linear)
init.kaiming_normal_(layer.weight, mode='fan_out', nonlinearity='relu')
if layer.bias is not None:
init.constant_(layer.bias, 0)
def receive_updates(self, model_update):
"""收集来自客户端的模型更新"""
self.client_updates.append(model_update)
def aggregate_updates(self):
"""默认使用平均聚合方法聚合更新"""
total_weight = len(self.client_updates)
average_update = defaultdict(float)
for update in self.client_updates:
for name, data in update.items():
average_update[name] += data / total_weight
self.model.load_state_dict(average_update, strict=False)
self.client_updates = [] # 清空更新以备下次聚合
#写一个密态计算的方法,可以添加密态计算,比如使用FHE或者MPC等方法
def privacy_computation(self):
"""应用隐私保护方法,比如使用FHE或者MPC等方法"""
pass
def get_global_model_params(self):
"""获取当前的全局模型参数."""
return self.model.state_dict()
def evaluate_model(self):
"""评估聚合后模型的精度,并计算其他统计指标"""
self.model.eval()
all_predictions = []
all_targets = []
with torch.no_grad():
for data, target in self.test_loader:
data, target = data.to(self.device), target.to(self.device)
outputs = self.model(data)
_, predicted = torch.max(outputs.data, 1)
all_predictions.extend(predicted.tolist())
all_targets.extend(target.tolist())
# 计算准确度、精确度、召回率和F1分数
accuracy = accuracy_score(all_targets, all_predictions)
precision, recall, f1, _ = precision_recall_fscore_support(all_targets, all_predictions, average='macro')
# 返回一个包含所有相关指标的字典
return {
'accuracy': accuracy,
'precision': precision,
'recall': recall,
'f1_score': f1
}
def run(self):
"""聚合更新并评估模型"""
self.aggregate_updates()
accuracy = self.evaluate_model()
print(f"Model Accuracy: {accuracy}%")
return accuracy
__init__
model(要管理的模型)和test_data(可选的测试数据集,默认为None)
self.model = model将传入的模型保存到实例变量中。
self.test_loader = DataLoader(test_data, batch_size=32, shuffle=False)
self.client_updates = []初始化一个空列表,用于存储来自客户端的模型更新。
initialize_model
使用He初始化来初始化模型参数。
此方法遍历模型的所有层(包括子模块),并对卷积层和全连接层应用He初始化。 He初始化考虑了ReLU激活函数,旨在保持网络层之间的方差一致性,有助于防止梯度消失或爆炸。
receive_updates
def receive_updates(self, model_update):
"""收集来自客户端的模型更新"""
self.client_updates.append(model_update)接收一个模型更新(通常是一个包含模型权重和偏置的字典),并将其添加到client_updates列表中。.append()方法将model_update参数添加到这个列表中(字典加入列表)
aggregate_updates
聚合模型更新
self.model.load_state_dict(average_update, strict=False):将聚合后的更新(即average_update)加载到模型的状态字典
self.client_updates = []这行代码将self.client_updates列表清空,以便存储下一次聚合的更新
get_global_model_params
def get_global_model_params(self):
"""获取当前的全局模型参数."""
return self.model.state_dict()返回当前模型的状态字典,即全局模型参数,获取当前的全局模型参数
get_global_model_params(服务器的,从服务器中加载全局模型参数)(self.model.state_dict())self.model指的是服务器的模型
获取当前服务器上全局模型的参数(通过调用模型的state_dict()方法),并将这些参数返回给请求它的客户端
load_global_model(客户端的,从服务器中加载全局模型参数)
(self.model.load_state_dict(model_parameters))self.model指的是客户端的模型
来自服务器的全局模型参数(model_parameters)
load_global_model方法中的数据流是从服务器到客户端的,即服务器发送全局模型参数给客户端。get_global_model_params方法中的数据流是潜在的,但它通常是在客户端请求全局模型参数时,服务器响应这个请求并发送参数。虽然这个方法本身不直接涉及数据流,但它是数据流触发的起点。-
.state_dict()方法可以获取模型的参数 - load_state_dict()加载模型的状态字典(state_dict)到模型的参数中
evaluate_model
run! !
fedproc_server.py
class FedAvgServer(Server):
def __init__(self, model, test_data=None):
super().__init__(model, test_data)
def aggregate_updates(self):
"""重写聚合逻辑以实现FedAvg特定的需求"""
# 这里我们简单地调用基类的平均聚合逻辑
super().aggregate_updates()
print("Aggregated using FedAvg strategy.")
fedavg.py
相当于主函数
config = {
"experiment": {
"description": "本次实验主要探究不同的训练周期(epochs)对联邦学习性能的影响。",
"method_name": "fedavg",
"save_model": False, # 是否保存模型
"plot_accuracy": True, # 是否绘制精度图
"accuracy_csv": False # 是否生成精度记录文件(如 CSV)
},
"data_manager": {
"dataset": "MNIST",
"partitions": 3,
"distribution": "nonIID",
"skewness_level": 7,
"sample_rate": 0.1,
"seed": 42
},
"client": {
"base_config": {##。。。###。。。##
"learning_rate": 0.01,
"epochs": 2,
"batch_size": 32
},
"model": "mnist_cnn",
"privacy_protection": "DP",
"malicious_rate": 0
},
"server": {
"rounds": 50
}
}
def fedavg_main(config, experiment_path):
# 初始化数据管理和客户端
data_manager = DataManager(config['data_manager'])
clients = [FedAvgClient(data=data, config=config['client'], client_id=i) for i, data in enumerate(data_manager.client_data)]
# 初始化服务器和监控器
server = FedAvgServer(model=copy.deepcopy(clients[0].model), test_data=data_manager.test_data)
monitor = Monitor()
# 执行多轮联邦学习
for round in range(config['server']['rounds']):
global_model_params = server.get_global_model_params()
for client in clients:
client.load_global_model(global_model_params)
client.train()
update = client.send_model_to_server()
server.receive_updates(update)
server.aggregate_updates()
metrics = server.evaluate_model()
# 更新和记录性能指标
monitor.update(round, metrics)
monitor.log(f"Round {round}: Metrics: {metrics}")
# 关闭监控器
monitor.close()
if __name__ == "__main__":
configs = process_config(config)
for index, config in enumerate(configs):
experiment_path = setup_experiment_dirs(config, index)
fedavg_main(config, experiment_path)config 是一个字典,包含了实验的所有配置信息;experiment_path 是一个字符串,表示实验数据的存储路径(尽管在这个特定的函数体中未直接使用)。
数据初始化,客户端对象的创建和初始化
clients = [FedAvgClient(data=data, config=config['client'], client_id=i) for i, data in enumerate(data_manager.client_data)]
- 使用列表推导式创建客户端列表。每个客户端都分配了来自
data_manager的一部分数据,并根据配置设置其参数。
最终,clients列表将包含多个FedAvgClient实例,每个实例都代表了一个参与联邦学习的客户端。这些客户端具有不同的数据(data)但共享相同的配置(config['client']),并且每个客户端都有一个唯一的ID(client_id)
服务器和监控器初始化
创建FedAvgServer实例
执行联邦学习
# 执行多轮联邦学习
for round in range(config['server']['rounds']):
global_model_params = server.get_global_model_params()
for client in clients:
client.load_global_model(global_model_params)
client.train()
update = client.send_model_to_server()
server.receive_updates(update)
server.aggregate_updates()
metrics = server.evaluate_model()循环,联邦学习多个轮次
- 服务器分发全局模型参数给客户端
- 客户端加载全局模型参数,在本地数据上训练,将模型更新发送服务器
- 服务器接收所有客户端更新,聚合,使用聚合后的更新更新全局模型
- 服务器评估更新后的全局模型,将性能指标记录到监控器
最初的全局模型参数通常来源于一个预训练的模型或者是一个随机初始化的模型
-
预训练的模型:
如果有一个与当前任务相似或相关的已训练模型,可以使用该模型的参数作为全局模型的初始参数。这种方式利用了迁移学习的思想,可以加速训练过程,并可能提高最终模型的性能。预训练的模型可能已经学习到了一些通用的特征表示,这些特征对于当前任务也是有用的。 -
随机初始化的模型:
如果没有可用的预训练模型,或者出于某种原因想要从头开始训练模型,那么全局模型的参数通常会通过随机初始化来生成。随机初始化意味着模型参数的初始值是随机选择的,通常遵循某种分布(如正态分布或均匀分布)。然后,在训练过程中,这些参数会根据客户端上传的梯度更新进行迭代优化。
全局模型参数具体包括什么
权重(Weights):权重是神经网络中最重要的参数之一,它们决定了网络中各个节点(或神经元)之间的连接强度
偏置(Biases):偏置是神经网络中另一个重要的参数,它为每个节点提供了一个可学习的偏移量。
其他参数
假设客户端有一个初始的模型mnist_cnn,里面有了一些权重,那么再分发全局模型的时候又会给一些权重,这冲突吗
在联邦学习的场景中,当客户端已经有一个初始的模型(比如 mnist_cnn)并且这个模型里已经有了一些预训练的权重时,分发全局模型时再给一些权重并不会直接导致冲突,但如何处理这些权重取决于联邦学习的具体实现和策略。
首先,需要明确的是,全局模型在分发时给出的“权重”实际上是全局模型在聚合了所有客户端上传的本地模型更新后得到的参数。这些全局权重代表了当前所有客户端数据上的最优(或次优)解的一个估计。
替换本地权重:客户端可以直接用接收到的全局权重替换其当前模型的权重。
加权平均:客户端可以将接收到的全局权重与其当前模型的权重进行加权平均。权重的选择可以根据实际情况进行调整,比如基于本地数据的重要性或模型的性能。
微调:客户端可以先将全局权重作为起点,然后在其本地数据集上进行少量的额外训练(微调)。这种方法可以使得模型更好地适应本地数据的分布,同时保留全局模型的知识。
保持不变:
主函数
if __name__ == "__main__":
configs = process_config(config)
for index, config in enumerate(configs):
experiment_path = setup_experiment_dirs(config, index)
fedavg_main(config, experiment_path)根据一系列配置来启动多个实验,每个实验都使用联邦学习(可能是联邦平均算法)来训练模型,并将结果存储在指定的实验目录中。
fedproc论文
客户端的本地数据非独立同分布non - IID
不平衡的数据分布
特征分布差异(猫狗)
标签分布差异(多个0多个1)
数量不均衡
-
全局最优:
- 全局最优指的是在所有客户端数据上的最优模型参数。即,假设可以访问所有客户端的数据并联合训练模型,所得到的最优参数。最小化这个全局损失函数,我们可以找到全局最优参数
-
局部最优:
- 局部最优指的是在某个客户端本地数据上的最优模型参数。由于每个客户端的数据分布不同,局部最优的参数可能会显著偏离全局最优。
提高模型聚合的效率,另一种是通过调节局部模型在参数空间上偏离全局模型来稳定局部训练阶段,这些方法都没有充分利用每个客户端提供的底层知识。
本地网络由三个模块组成:基编码器、投影头和输出层。
1. 基编码器
- 从输入数据中提取特征表示
- 通常CNN
- 基编码器的主要作用是将高维的原始数据(如图像)转换为低维的特征表示。降维
2. 投影头
- 特征表示 映射为向量表示
- 一个隐藏层的多层感知器(MLP)实现。
- 更适合用于对比学习任务
- 向量变化:将 rrr 转换为 zzz 是为了增强特征表示的表达能力,使其在对比学习任务中更具判别力。通过将特征映射到另一个空间,可以更好地分离不同类别的特征,从而提高模型的性能。
- MLP的作用:使用一个隐藏层的MLP可以增强特征表示的非线性转换能力。这种非线性转换可以帮助模型更好地捕捉数据中的复杂模式,提升表示的质量。Chen等人(2020)的研究表明,投影头有助于提高特征表示的效果,尤其是在对比学习任务中。
3. 输出层
- 基于输入的特征表示 zzz 进行类别预测。
- 一个单线性层 fc(⋅)fc(\cdot)fc(⋅)。

- 通过一个简单的线性层,模型可以在给定的特征表示上进行线性分类,从而输出每个类别的预测概率。
-
增强表示能力:
- 特征表示映射向量表示,增强特征的表达能力。
-
适应对比学习的需求:
- 对比学习要求特征表示具有良好的区分能力。通过将特征映射到一个新的空间,可以更好地分离不同类别的特征,提高对比学习的效果。
-
非线性转换:
- 使用MLP进行非线性转换,可以捕捉数据中的复杂模式,使特征表示更加丰富和多样。
MLP的用意
-
非线性特征提取:
- MLP能够通过非线性激活函数(如ReLU)提取更复杂的特征,使特征表示更加具有区分性。
-
提升表示质量:
- 通过增加一个隐藏层,MLP可以对输入特征进行进一步的处理和转换,提升特征表示的质量。Chen等人(2020)的研究表明,使用MLP作为投影头可以显著提高特征表示的效果。
-
适应对比学习任务:
- MLP可以通过非线性转换使特征表示更适合对比学习任务,从而提高模型在计算全局原型对比损失 ℓgpc\ell_{gpc}ℓgpc 时的性能。
多层感知器(MLP)
- 全连接层:MLP由多个全连接层(Fully Connected Layers)组成,每一层的每个神经元都与上一层的所有神经元相连接。
- 激活函数:每个全连接层后面通常会有一个非线性激活函数(如ReLU、sigmoid、tanh等)。
- 层数:MLP可以有多个隐藏层,这些隐藏层可以叠加,以增加模型的表达能力。
-
h = h.squeeze():去除特征张量中的不必要维度,通常是为了确保数据格式适合后续处理。h = self.l1(h):这是投影头的第一层,self.l1通常是一个全连接层(linear layer)。这一层对特征进行线性变换。h = F.relu(h):这是一个激活函数(ReLU),它引入了非线性,使模型能够学习到更复杂的特征表示。h = self.l2(h):这是投影头的第二层,self.l2也是一个全连接层。通过这一层,特征进一步被转换和处理。
这些步骤组合在一起,形成了一个典型的 MLP,用于对初始特征进行进一步的特征提取和转换


fedproc代码
local_methods.py
fedproc_local.py
假设在某个客户端上,有一个数据集,其中包含两个类别 class1 和 class2。每个类别的样本特征
class1_features = [feature1_class1, feature2_class1, feature3_class1, ...] class2_features = [feature1_class2, feature2_class2, feature3_class2, ...]
计算本地类别原型
对于 class1:
-
求和:
sum_class1 = feature1_class1 + feature2_class1 + feature3_class1 + ... -
求均值:
-
proto_class1 = sum_class1 / len(class1_features)
对于 class2:
-
求和:
sum_class2 = feature1_class2 + feature2_class2 + feature3_class2 + ... -
求均值:
proto_class2 = sum_class2 / len(class2_features)
def agg_func(protos):
for [label, proto_list] in protos.items():
if len(proto_list) > 1:
proto = 0 * proto_list[0].data
for i in proto_list:
proto += i.data
protos[label] = proto / len(proto_list)
else:
protos[label] = proto_list[0]
return protos
输入字典返回字典,输入是某个客户端的一个特征键,对应一组数据在该特征下的值
protos={client1_feature1:[..,..,..,..,],
client1_feature2:[..,..,..,..,],
client1_feature3:[..,..,..,..,],
client1_feature4:[..,..,..,..,]
}
客户端1,不是客户1
[]内是客户1,客户2,客户3,,,返回的是
protos={client1_feature1:原型1,
client1_feature2:原型2,
client1_feature3:原型3,
client1_feature4:原型4
}
客户端1,不是客户1
[]内是客户1,客户2,客户3,,,
某原型是之前[]所有加起来求的平均值总而言之,求的是本地类别原型
全局原型的结构
global_protos = {
"class1": [proto_client1_class1, proto_client2_class1, proto_client3_class1],
"class2": [proto_client1_class2, proto_client2_class2],
...
}
将同一类别在不同客户端上计算出的特征向量进行拼接,并将其转移到指定的设备
- 汇总特征向量:通过拼接同一类别在不同客户端上计算出的特征向量,将所有特征向量汇总到一个张量中,方便进行统一处理。
- 利用GPU进行计算:将拼接后的张量转移到 GPU 上,可以利用 GPU 的强大计算能力,提高计算速度和效率。
for protos_key in all_global_protos_keys:
temp_f = global_protos[protos_key]
temp_f = torch.cat(temp_f, dim=0).to(self.device)
all_f.append(temp_f.cpu())
f = net.features(images)
outputs = net.classifier(f)smple_cnn
def features(self, x: torch.Tensor) -> torch.Tensor:
h = self.feats(x)
'''MLP'''
h = h.squeeze() # 去除不必要的维度
h = self.l1(h)# 投影头的第一层
h = F.relu(h)# 激活函数
h = self.l2(h)# 投影头的第二层
return h
def classifier(self, h: torch.Tensor) -> torch.Tensor:
y = self.cls(h)
return y
self.feats(x) 基编码器
self.cls(h) 输出层
self.l1(h) 和 self.l2(h) 投影头
resnet
def features(self, x: torch.Tensor) -> torch.Tensor:
out = self._features(x)
out = avg_pool2d(out, out.shape[2])
feat = out.view(out.size(0), -1)
return feat
def classifier(self, x: torch.Tensor) -> torch.Tensor:
out = self.cls(x)
return outresnet_pretrain
def forward(self, x):
feature_out = self.features(x)
x = self.cls(feature_out)
return x
def classifier(self, x):
out = self.cls(x)
return out
for label in labels:
if label.item() in global_protos.keys():
'''获取正负样本特征'''
f_pos = np.array(all_f)[all_global_protos_keys == label.item()][0].to(self.device)
f_neg = torch.cat(list(np.array(all_f)[all_global_protos_keys != label.item()])).to(
self.device)
'''维度(形状调整)'''
f_now = f[i].unsqueeze(0)
embedding_len = f_pos.shape#获取正样本形状
f_neg = f_neg.unsqueeze(1).view(-1, embedding_len[0])#调整负样本形状
f_pos = f_pos.view(-1, embedding_len[0])#调整正样本形状
f_proto = torch.cat((f_pos, f_neg), dim=0)#拼接正负样本特征
l = torch.cosine_similarity(f_now, f_proto, dim=1)
l = l
'''相似度取指并调整形状'''
exp_l = torch.exp(l)
exp_l = exp_l.view(1, -1)
pos_mask = [1 for _ in range(f_pos.shape[0])] + [0 for _ in range(f_neg.shape[0])]
pos_mask = torch.tensor(pos_mask, dtype=torch.float).to(self.device)
pos_mask = pos_mask.view(1, -1)
pos_l = exp_l * pos_mask
sum_pos_l = pos_l.sum(1)
sum_exp_l = exp_l.sum(1)
loss_instance = -torch.log(sum_pos_l / sum_exp_l)
if loss_InfoNCE is None:
loss_InfoNCE = loss_instance
else:
loss_InfoNCE += loss_instance
i += 1
loss_InfoNCE = loss_InfoNCE / i
loss_InfoNCE = loss_InfoNCE获取正样本特征f_pos
获取负样本特征f_neg
当前特征
调整特征形状
获取正样本特征的形状
调整负样本特征的形状
调整正样本特征的形状
拼接正负样本特征
计算余弦相似度
计算相似度的指数值
创建正样本掩码
计算正样本的权重和损失
累计 InfoNCE 损失平均
遍历的是标签
获取正样本特征f_pos
从 all_f 中选取标签等于当前标签 label 的特征。np.array(all_f) 将特征转换为 NumPy 数组,all_global_protos_keys == label.item() 用于筛选与当前标签匹配的特征,取第一个特征,并移动到计算设备(例如 GPU)。
获取负样本特征f_neg
从 all_f 中选取标签不等于当前标签 label 的特征,并将这些特征拼接成一个张量,移动到计算设备。
f_now = f[i].unsqueeze(0)
- 当前特征: 取当前索引
i对应的特征,并增加一个维度,使其形状与其他特征一致
当前样本的特征向量从一维调整为二维
chatgpt解释
第一步:获取正样本特征的形状
embedding_len = f_pos.shape
- 目的: 获取正样本特征的形状信息。
- 作用:
f_pos是正样本特征向量。通过f_pos.shape获取其形状,这在后续调整负样本特征形状时将会用到。 - 输出: 假设
f_pos的形状为[n],则embedding_len变为(n,),表示特征向量的长度为n。
第二步:调整负样本特征的形状
f_neg = f_neg.unsqueeze(1).view(-1, embedding_len[0])
- 目的: 调整负样本特征的形状,使其与正样本特征的形状兼容,以便后续拼接。
- 步骤:
unsqueeze(1): 在第 1 维度插入一个新的维度,使f_neg的形状从[m, n]变为[m, 1, n]。view(-1, embedding_len[0]): 重新调整形状,其中-1表示该维度的大小根据其他维度自动推断。embedding_len[0]是特征向量的长度n。
- 输出: 最终
f_neg的形状变为[m, n],即每个负样本特征的长度与正样本特征一致。
第三步:调整正样本特征的形状
f_pos = f_pos.view(-1, embedding_len[0])
- 目的: 确保正样本特征的形状与负样本特征一致。
- 步骤:
view(-1, embedding_len[0]): 重新调整形状,使正样本特征的形状符合[-1, n]的格式,其中n是特征向量的长度。
- 输出:
f_pos的形状变为[1, n],即每个正样本特征的长度与负样本特征一致。
第四步:拼接正负样本特征
f_proto = torch.cat((f_pos, f_neg), dim=0)
- 目的: 将正样本特征和负样本特征拼接在一起,形成一个新的张量
f_proto。 - 步骤:
torch.cat((f_pos, f_neg), dim=0): 在第 0 维度上拼接f_pos和f_neg,即按行进行拼接。
- 输出:
f_proto的形状变为[(1 + m), n],其中(1 + m)表示拼接后的总样本数,n表示特征向量的长度。
整体意义
- 确保形状一致: 正样本特征和负样本特征在形状上保持一致,以便进行拼接和后续计算。
- 拼接正负样本特征: 将正样本和负样本特征拼接成一个整体张量
f_proto,用于计算相似度。
示例
假设我们有以下正样本和负样本特征:
f_pos = torch.tensor([0.1, 0.2, 0.3]) # 正样本特征,形状为 [3] f_neg = torch.tensor([[0.4, 0.5, 0.6], [0.7, 0.8, 0.9]]) # 负样本特征,形状为 [2, 3]
embedding_len = f_pos.shape
# f_pos.shape = [3]
f_neg = f_neg.unsqueeze(1).view(-1, embedding_len[0]) # 负样本调整形状
# f_neg = [[0.4, 0.5, 0.6], [0.7, 0.8, 0.9]] 形状仍为 [2, 3]
f_pos = f_pos.view(-1, embedding_len[0]) # 正样本调整形状
# f_pos = [0.1, 0.2, 0.3] 形状为 [1, 3]
f_proto = torch.cat((f_pos, f_neg), dim=0) # 拼接正负样本
# f_proto = [[0.1, 0.2, 0.3], [0.4, 0.5, 0.6], [0.7, 0.8, 0.9]] 形状为 [3, 3]
通过这些步骤,代码确保正负样本特征在形状上一致,并拼接成一个新的张量 f_proto。这种操作是为了在后续的相似度计算和损失计算中使用。确保形状一致和拼接后的张量形式有助于对比学习中正负样本的有效对比,从而提升模型的学习效果。
相似度:
这一行代码计算的是当前样本特征向量 f_now 和拼接后的特征向量 f_proto 之间的余弦相似度。具体来说,它计算 f_now 与 f_proto 中每一个特征向量的相似度。
f_proto 包含了所有正负样本特征
当前样本与所有正负样本的相似度
当前特征与所有原型特征的相似度。
pos_mask = [1 for _ in range(f_pos.shape[0])] + [0 for _ in range(f_neg.shape[0])] pos_mask = torch.tensor(pos_mask, dtype=torch.float).to(self.device) pos_mask = pos_mask.view(1, -1)
创建正样本掩码: 创建一个掩码,标记正样本的位置。正样本位置为1,负样本位置为0。
模型创建了一个掩码张量 pos_mask,用于区分正样本和负样本的位置。它允许模型选择性地操作正样本或负样本的相似度值,从而准确地计算 InfoNCE 损失。这个掩码的创建和调整形状步骤确保了计算过程的正确性和高效性。
计算正样本的权重和损失: 通过掩码筛选正样本的指数值,计算正样本指数值的和与所有指数值的和,计算其比值并取对数,得到当前实例的 InfoNCE 损失。
if iter == self.cfg.OPTIMIZER.local_epoch - 1:
for i in range(len(labels)):
if labels[i].item() in agg_protos_label:
agg_protos_label[labels[i].item()].append(f[i, :])
else:
agg_protos_label[labels[i].item()] = [f[i, :]]聚合原型更新:
- 最后一次迭代时,将每个样本的特征向量根据其标签进行分类和存储。
- 这种聚合操作通常用于更新每个类别的特征表示,以便在全局模型聚合或后续计算中使用
条款25:聚合本地模型参数
- 图中的内容:
- 这一步表示将本地模型的参数进行聚合,准备进行下一步的计算。
- 代码对应部分:
- 虽然代码中没有直接显示模型参数的聚合,但是可以理解为代码中的
f[i, :]代表了模型在每个样本上的特征输出,而这些特征输出可以被视为模型的中间状态或结果。
- 虽然代码中没有直接显示模型参数的聚合,但是可以理解为代码中的
条款27:计算本地类别原型
- 计算每个类别的本地原型
- 代码对应部分:
if labels[i].item() in agg_protos_label:这部分代码检查标签是否已经在agg_protos_label字典中。agg_protos_label[labels[i].item()].append(f[i, :])将对应标签的样本特征追加到字典中。agg_protos_label[labels[i].item()] = [f[i, :]]创建新的字典项。- 这些操作等效于将每个类别的样本特征聚合起来,为计算类别原型做准备。
条款28:返回本地模型参数和类别原型
- 图中的内容:
- 将本地模型参数和计算好的类别原型返回给服务器。
- 代码对应部分:
agg_protos = agg_func(agg_protos_label)调用agg_func函数计算聚合后的原型。local_protos[index] = agg_protos将计算结果存储到local_protos中。agg_func可以视为实现了条款27中的聚合和平均操作,并将结果返回给服务器。
net==self.model
self.model = get_model(config['model'])
global_protos字典,储存了全局原型
all_global_protos_keys全局原型的键
all_f 全局原型的特征张量列表
agg_protos_label==protos(那个函数里面的)
local_protos_dict是一个字典,键是客户端的索引,值是每个客户端对应的本地原型(prototypes)字典。
global_protos{}
global_protos 全局原型向量。每个原型向量代表某一类别或簇的特征中心。字典的键通常是类别标签,值是对应类别的特征向量。具体来说:
- 键(key): 类别标签(如
0,1,2等)。 - 值(value): 对应类别的特征向量(可能是平均特征或从训练数据中选出的代表性特征)。
all_f[]
all_f 存储所有样本的特征向量。这些特征向量是从模型的某一层提取的,用于计算与全局原型的相似度。具体来说:
- 元素(element): 每个样本的特征向量,通常是从模型的某一层提取的高维表示。
- 用途(usage): 用于与全局原型比较,以计算 InfoNCE 损失。
-
内容类型:
global_protos:包含类别标签和对应的特征向量,是类别特征的代表。all_f:包含所有样本的特征向量,是输入数据在特征空间的表示。
-
数据结构:
global_protos:字典结构,键为类别标签,值为特征向量。all_f:列表或数组结构,每个元素是一个样本的特征向量。
-
功能用途:
global_protos:用于对比学习中的参考原型,计算与样本的相似度。all_f:用于获取当前批次样本的特征,计算与全局原型的相似度。
f是提取的特征向量

对比学习原理计算相似度
无监督对比学习
模型的目标是学习一个嵌入空间,使得来自同一实例的样本(正对,positive pairs)靠近,而来自不同实例的样本(负对,negative pairs)远离。
- 数据增强: 对每个输入样本应用不同的数据增强方法,生成两个不同的视图(augmentation)。
- 特征提取: 使用神经网络(通常是卷积神经网络)提取每个视图的特征向量。
- 计算相似度: 使用某种相似度度量(如余弦相似度)计算正对之间的相似度和负对之间的相似度。
- 损失函数: 使用对比损失函数(如 InfoNCE)来最大化正对之间的相似度,同时最小化负对之间的相似度。
有监督对比学习
有监督对比学习是对无监督对比学习的扩展,通过引入标签信息来构建正负对:
- 正对和负对: 使用标签信息将同一类别的样本视为正对,不同类别的样本视为负对。
- 特征提取: 同样使用神经网络提取每个样本的特征向量。
- 计算相似度: 使用相似度度量计算正对和负对之间的相似度。
- 损失函数: 使用扩展的对比损失函数,利用标签信息来进一步区分正负对。
使用了余弦相似度来计算当前样本与全局原型之间的相似度。对比学习相似度计算方法。
- 选取正样本特征 (
f_pos): 从all_f中选择与当前标签匹配的特征。 - 选取负样本特征 (
f_neg): 从all_f中选择与当前标签不匹配的特征。 - 调整特征形状 (
f_neg和f_pos): 调整形状使其可以在同一维度上拼接,形成f_proto。 - 计算余弦相似度 (
torch.cosine_similarity): 计算当前特征f_now与拼接后的正负样本特征f_proto之间的余弦相似度。 - 计算指数值 (
torch.exp): 对相似度取指数,方便后续计算。 - 创建正样本掩码 (
pos_mask): 用于标记正样本的位置。 - 计算损失 (
loss_instance): 通过对比正样本和所有样本的相似度,计算 InfoNCE 损失。
基于标签信息的有监督对比学习,利用余弦相似度计算当前样本与全局原型之间的相似度,从而进行特征学习和优化。
softmax类似结构
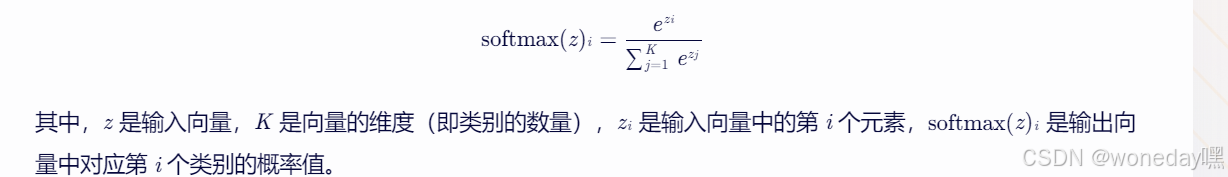

fedproc_server.py
def proto_aggregation(self, online_clients, local_protos_dict):
agg_protos_label = dict()
for idx in online_clients:
local_protos = local_protos_dict[idx]
for label in local_protos.keys():
if label in agg_protos_label:
agg_protos_label[label].append(local_protos[label])
else:
agg_protos_label[label] = [local_protos[label]]
for [label, proto_list] in agg_protos_label.items():
if len(proto_list) > 1:
proto = 0 * proto_list[0].data
for i in proto_list:
proto += i.data
agg_protos_label[label] = [proto / len(proto_list)]
else:
agg_protos_label[label] = [proto_list[0].data]
return agg_protos_label
proto_aggregation()
聚合字典初始化
online_clients:[]所有客户端索引local_protos_dict:{}键是客户端索引,值是原型的字典,这些原型进一步以标签为键。agg_protos_label:{}每个标签的聚合原型
从在线客户端收集原型
for idx in online_clients:
local_protos = local_protos_dict[idx]
for label in local_protos.keys():
if label in agg_protos_label:
agg_protos_label[label].append(local_protos[label])
else:
agg_protos_label[label] = [local_protos[label]]
local_protos当前客户端的原型的字典
聚合原型
for [label, proto_list] in agg_protos_label.items():
if len(proto_list) > 1:
proto = 0 * proto_list[0].data
for i in proto_list:
proto += i.data
agg_protos_label[label] = [proto / len(proto_list)]
else:
agg_protos_label[label] = [proto_list[0].data]
遍历聚合的原型:对于 agg_protos_label 中的每个标签及其关联的原型列表
返回结果
返回聚合后的原型字典:最终返回包含每个标签聚合原型的字典 agg_protos_label。
sever_update
这段代码首先计算在线客户端的权重,然后使用这些权重来聚合部分网络,最后聚合原型,并返回权重和聚合后的全局原型
-
online_clients_list:在线客户端的列表。priloader_list:一些与客户端相关的加载器的列表。
- 结果:计算并返回一个频率或权重,用于后续的聚合步骤。结果存储在
freq变量中。
聚合部分网络
fed_aggregation.agg_parts(online_clients_list=online_clients_list, nets_list=nets_list,
global_net=global_net, freq=freq, except_part=[], global_only=False)
原型聚合
global_protos = self.proto_aggregation(online_clients_list, local_protos)
global_protos:聚合后的全局原型

















 857
857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









