






联邦学习训练过程(以基础神经网络为模型)
1. 初始化全局模型
-
在中央服务器上初始化一个全局模型,包含模型的初始参数。初始化全局模型的步骤包括如下:
- 选择模型结构:例如神经网络、线性模型等。本文以基础神经网络为例,如下图所示:
- 在联邦学习有两种架构,
同构架构和异构架构,同构架构即全局模型和本地模型在结构上是一致的,异构架构则是不一致的,本文使用同构架构如下图所示:
- 在联邦学习有两种架构,

- 随机初始化参数:对所选择的模型结构的参数(权重和偏差等)进行随机初始化。这通常涉及在某个范围内或根据某个分布进行参数值的随机赋值。
- 选择模型结构:例如神经网络、线性模型等。本文以基础神经网络为例,如下图所示:
2. 分发全局模型
将上述选择的模型以及随机初始化的参数分发给参与联邦学习的本地设备或客户端。
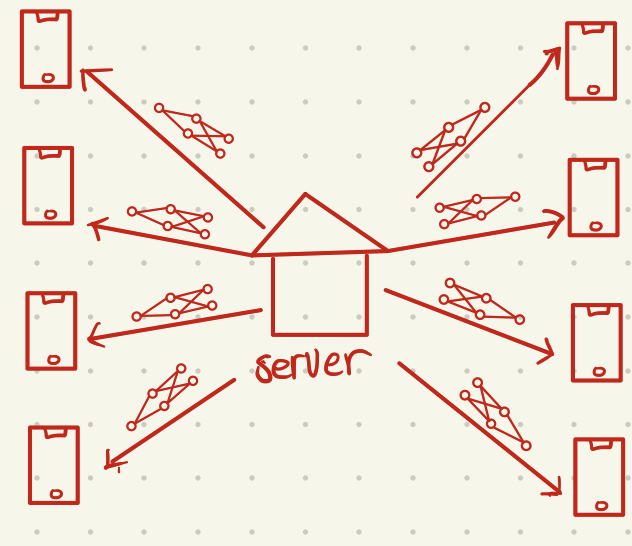
3. 本地训练(以FLavg为例)
FLavg
FLavg是基于FLSGD的一个算法,计算量由如下三个关键参数控制:
-
C:控制每一轮参与模型训练客户端的数量; -
E(epoch):每个客户端在每一轮(一轮迭代进行多次局部训练)局部训练中对本地数据集进行训练的次数; -
B(batch):每个客户端进行一次局部训练时用到的数据集大小。其中
E和C的关系中如下:在一轮模型迭代中,每个局部客户端会根据实验设置将自己本地的数据集划分为多个
batch,每一次进行局部训练时用一个batch的数据集进行训练,当数据集划分的每个batch都训练过一遍之后,就可以构成一个epoch。当
E = 1且batch为全部数据时,此时就是一个FLSGD
FLavg本地训练的详细过程
-
客户端在收到服务器发来的全局模型更新之后,根据模型训练任务中的
C、E、B进行训练,一般是联邦学习任务发起方设置的这些参数。 -
首先是在每个
epoch下训练多次batch,在每一个batch训练之后,这个batch中的每条数据样本都会计算出一个损失值,一个batch训练结束后,计算整个batch的损失值,然后进行反向传播,就会得到这个batch的梯度,然后根据模型更新方式对局部模型参数进行更新。(这里所说的参数就是神经网络模型中的权重和偏置,神经网络每个权重和偏置都是样本梯度中的一个维度)那么梯度是如何得到的并且模型参数是如何进行更新的呢?
这就要涉及神经网络的训练过程了,神经网络主要有如下阶段:
-
初始化:初始化也就是模型开始训练前服务器所做的初始化工作
-
前向传播、计算损失、反向传播:这三个阶段可以见下图:
-
前向传播之后得到输出值/预测值,中间会用到激活函数,下图用
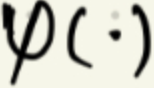 表示激活函数;
表示激活函数; -
计算损失,根据任务设定的损失函数计算真是值和预测值之间的损失(也就是两个值之间的差距),下图用
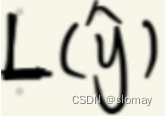
表示损失函数; -
然后就是反向传播了,反向传播的过程就是计算得到某个参数的导数的过程,反向传播过程用到了链式法则,如下的例子所示:求

的导数的过程,因为损失函数距离会中间会经过一些别的函数(如激活函数等),根据链式法则不断向着 的方向求偏导数,最后就可以得到
的方向求偏导数,最后就可以得到 的梯度。(根据下面的例子的链式求导,我们可以知道每一个链式过程的偏导数都是可以根据已有的数值得到的)
的梯度。(根据下面的例子的链式求导,我们可以知道每一个链式过程的偏导数都是可以根据已有的数值得到的)需要注意的是:
样本梯度是多维的,每个参数的梯度作为样本梯度的一个维度,下面的例子只是其中一个参数的反向传播求导过程。
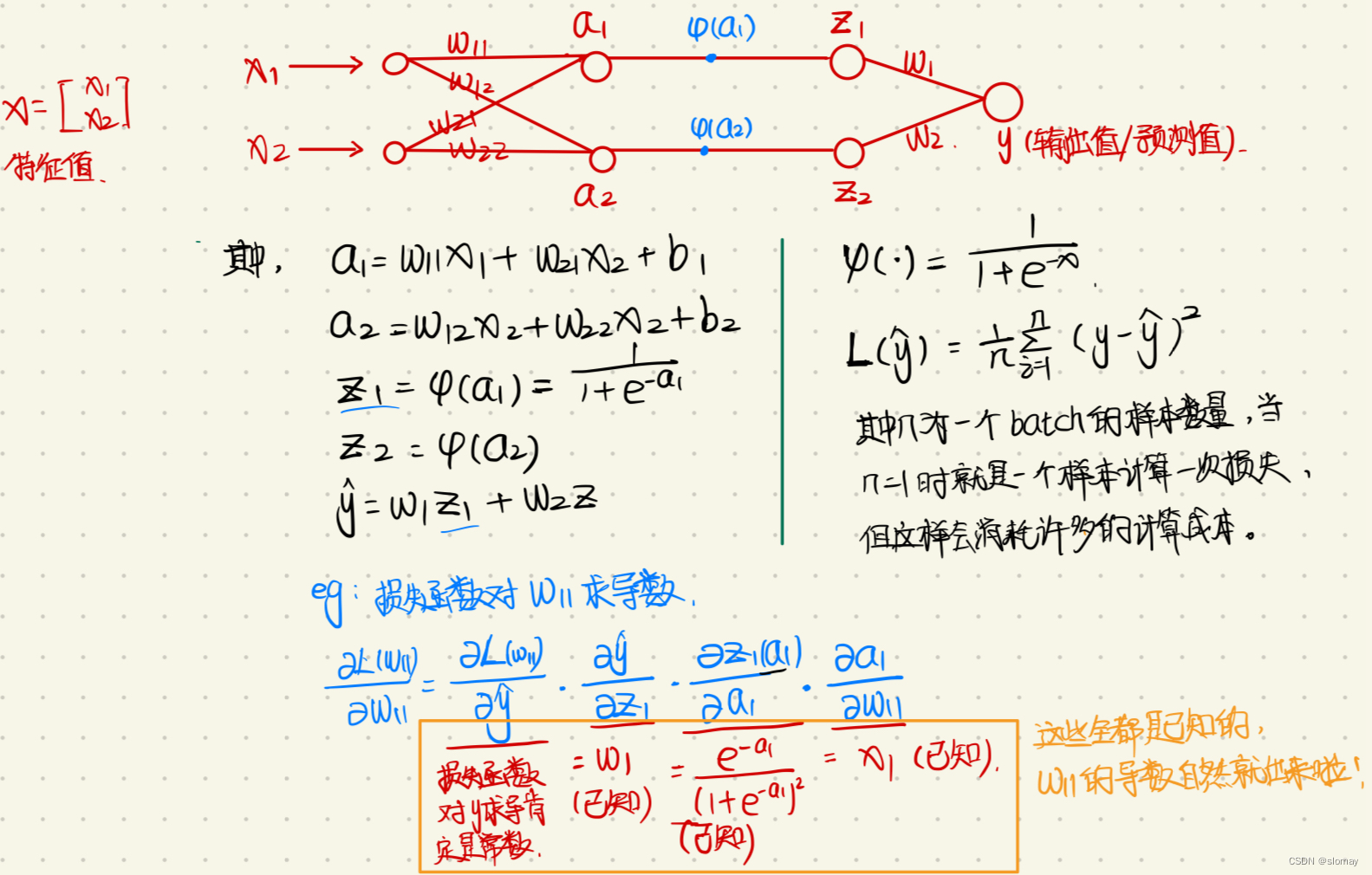
-
- 参数更新:得到梯度之后便可以利用模型更新方式对参数进行更新,FLavg的更新方式如下:
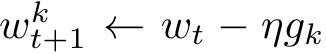
-
4. 模型参数更新聚合
- 所有epoch训练结束之后,每个本地设备将其本地模型的参数(权重、偏置啥的)发送回中央服务器。
5. 全局模型更新
-
中央服务器收到所有本地设备的模型更新,聚合方式如下:
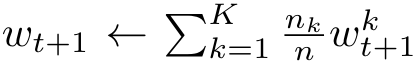
6. 重复迭代上述过程直至收敛
- 上述步骤循环迭代进行,直到满足预定义的停止条件,比如达到一定的迭代次数或全局模型在验证数据上达到一定的性能。

















 666
666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









