







 一、关于评测的三个问题?
一、关于评测的三个问题?
1.为什么需要评测?
- 模型选型
- 模型能力提升
- 真是应用场景效果评测
2.我们需要测什么?
- 知识、推理、语言
- 长文本、智能体、多轮对话
- 情感、认知、价值观
3.怎么样测试大语言模型
- 自动化客观评测
- 人机交互评测
- 基于大模型的大模型评测
二、我们为什么需要评测?

建立在公平的、全面的统一框架下
可以知道模型的能力边界
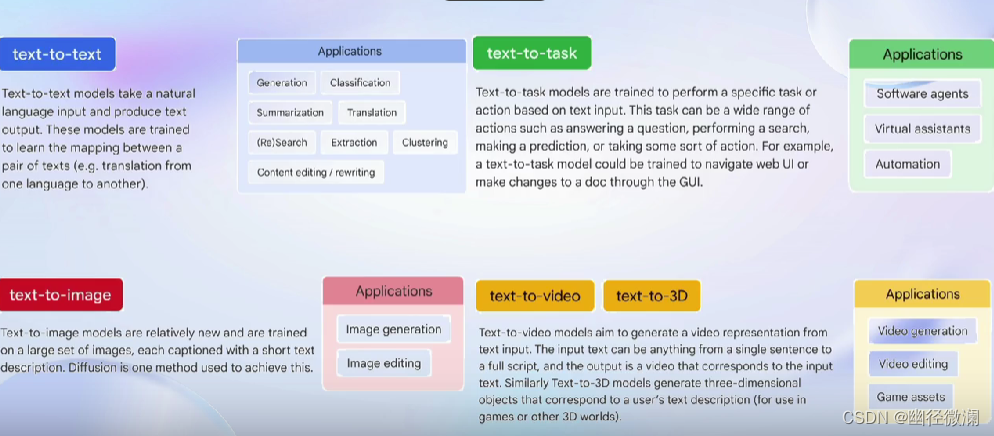
三、我们需要评测什么?
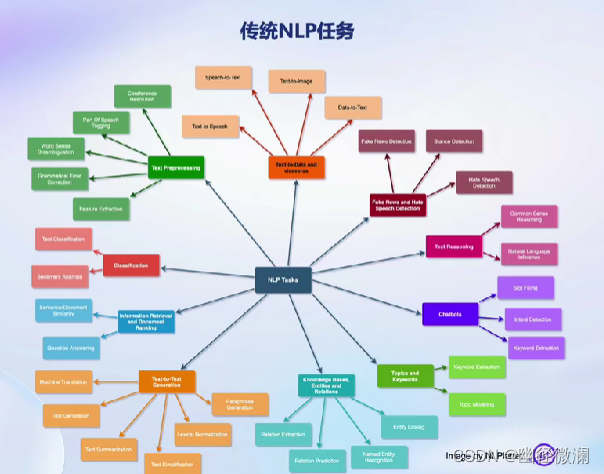
四、如何评测大语言模型
1.根据模型
- 基座模型
- 对话模型(经过指令微调的模型)
2.根据评测
- 客观评测(问答题、多选题、判断题/分类题/...)
- 主观评测(人类评价、模型评价)
3.提示词工程

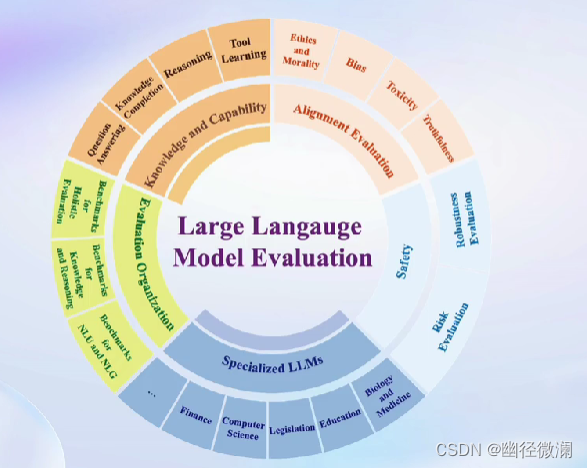
五、主流大模型评测框架

六、OpenCompass 能力框架

Meta官方推荐,唯一由国内开发的大模型评测体系,其他三个分别是HuggingFace、Stanford和Google退出的测评体系。
架构:
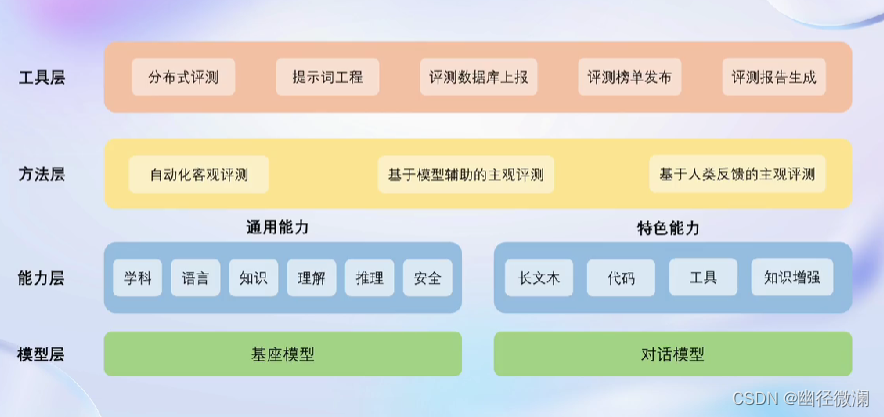
OpenCompass会将评测请求切分为多个独立执行的任务,从而最大化利用计算资源。
七、OpenCompass前沿探索
- 多模态(基于感知与推理将评估维度逐级细分)
- 法律领域(三维认知维度:法律知识理解、法律知识记忆、法律知识应用)
- 医疗领域(多来源基准评估维度)
八、大模型评测领域的挑战
- 缺少高质量中文评测集
- 难以准确提取答案
- 能力维度不足
- 测试集混入训练集
- 测试标准各异
- 人工测试成本高昂















 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









