






一、项目背景:
在现代生活中,水果识别技术在农业、零售和健康管理等领域具有广泛的应用前景。水果识别技术可以帮助农民实时监测果园中水果的生长情况,也可以帮助零售商自动计数和管理水果库存。我们将使用YOLO v8模型来实现这一功能,利用Python和Qt库构建一个简洁的用户界面,实现图片和视频文件检测功能。
二、数据集准备
本次任务使用到同济子豪兄的水果识别数据集,该数据集包含了81种水果:水果数据集
其中每种水果种类的图片都非常丰富,数据多样,对模型的泛化能力有很好的帮助。同时,还有一段视频作为待会测试的视频数据,该视频包含包含了三种水果,分别是猕猴桃,柠檬,石榴,菠萝以及西瓜,所以为了简化任务,我单独抽出以上五种水果的数据集做了一个简单的小数据集,如下图: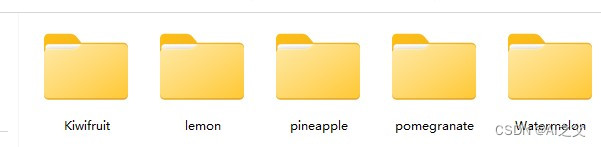
视频数据集:
三.训练模型
给出部分代码:
1.导入必要的库:- 导入了 `os`、`PIL`(用于图像处理)、`torch`(包括数据加载、优化器和模型定义)和 `sklearn`(用于数据集划分)等库。
import os
from PIL import Image
from torch.utils import data
from torchvision import transforms as T
from sklearn.model_selection import train_test_split
import torch.optim as optim
import torch
import torch.nn as nn
import torch.utils.data
import torchvision.transforms as transforms
from torch.autograd import Variable
from torchvision.models import vgg16, VGG16_Weights
import matplotlib.pyplot as plt2. **标签字典** 更新 `Labels` 字典以包含新的标签 'pineapple' 和 'Watermelon':
Labels = {'Kiwifruit': 0, 'lemon': 1, 'pomegranate': 2, 'pineapple': 3, 'Watermelon': 4}3. **数据集类**:
- 定义 `SeedlingData` 类用于加载和处理图像数据:
class SeedlingData(data.Dataset):
def __init__(self, root, transforms=None, train=True, test=False):
self.test = test
self.transforms = transforms
# 加载图像路径
if self.test:
self.imgs = [os.path.join(root, img) for img in os.listdir(root)]
else:
imgs_labels = [os.path.join(root, img) for img in os.listdir(root)]
imgs = []
for imglable in imgs_labels:
for imgname in os.listdir(imglable):
imgpath = os.path.join(imglable, imgname)
imgs.append(imgpath)
trainval_files, val_files = train_test_split(imgs, test_size=0.3, random_state=42)
self.imgs = trainval_files if train else val_files
def __getitem__(self, index):
img_path = self.imgs[index]
if self.test:
label = -1
else:
labelname = os.path.basename(os.path.dirname(img_path))
label = Labels[labelname]
data = Image.open(img_path).convert('RGB')
data = self.transforms(data)
return data, label
def __len__(self):
return len(self.imgs)
```4. **全局参数设置**:
- 设置了模型的学习率、批次大小、训练轮数和设备(CPU 或 GPU):
modellr = 1e-4
BATCH_SIZE = 32
EPOCHS = 10
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
```5. **数据预处理**:
- 定义图像预处理的变换操作,包括调整大小和转换为张量(其他预处理操作可以添加在这里):
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),6. **定义和加载模型**:
- 使用预训练的 VGG16 模型,并调整最后的全连接层以适应新的类别数量:
model_ft = vgg16(weights=VGG16_Weights.IMAGENET1K_V1)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs, len(Labels))
model_ft = model_ft.to(DEVICE)
```7. **优化器和损失函数**:
- 设置了 Adam 优化器和交叉熵损失函数:
optimizer = optim.Adam(model_ft.parameters(), lr=modellr)
criterion = nn.CrossEntropyLoss() 8. **学习率调整函数**:
- 定义一个函数来根据训练轮数调整学习率:
def adjust_learning_rate(optimizer, epoch):
modellrnew = modellr * (0.1 ** (epoch // 50))
for param_group in optimizer.param_groups:
param_group['lr'] = modellrnew 9. **训练和验证过程**:
- 定义训练和验证的过程函数,包括计算损失和准确率:
def train(model, device, train_loader, optimizer, epoch):
model.train()
sum_loss = 0
correct = 0
total_num = len(train_loader.dataset)
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
sum_loss += loss.item()
_, pred = torch.max(output, 1)
correct += pred.eq(target).sum().item()
if (batch_idx + 1) % 10 == 0:
print(f'Train Epoch: {epoch} [{(batch_idx + 1) * len(data)}/{total_num} ({100. * (batch_idx + 1) / len(train_loader):.0f}%)]\\tLoss: {loss.item():.6f}')
avg_loss = sum_loss / len(train_loader)
accuracy = 100. * correct / total_num
print(f'Epoch: {epoch}, Loss: {avg_loss:.6f}, Accuracy: {accuracy:.2f}%')
def val(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
total_num = len(test_loader.dataset)
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
test_loss += loss.item()
_, pred = torch.max(output, 1)
correct += pred.eq(target).sum().item()
avg_loss = test_loss / len(test_loader)
accuracy = 100. * correct / total_num
print(f'\\nValidation set: Average loss: {avg_loss:.4f}, Accuracy: {correct}/{total_num} ({accuracy:.2f}%)\\n') 10. **训练模型并保存**:
- 循环训练模型并在每轮后进行验证,最后保存模型的参数:
for epoch in range(1, EPOCHS + 1):
adjust_learning_rate(optimizer, epoch)
train(model_ft, DEVICE, train_loader, optimizer, epoch)
val(model_ft, DEVICE, test_loader)
torch.save(model_ft.state_dict(), 'model.pth')脚本总结: 这个脚本的主要功能是加载和预处理图像数据,定义和训练卷积神经网络模型,并在训练过程中调整学习率和计算损失及准确率,最后保存训练好的模型。
四.系统实现与UI界面设计
1. 依旧是先导入库:
- 导入了 `PyQt5` 的 GUI 组件、`torch` 和 `torchvision` 模型,以及 `PIL` 用于图像处理,`os` 和 `cv2` 用于文件操作和图像处理,`numpy` 用于数组操作。
import sys
from PyQt5.QtWidgets import QApplication, QWidget, QLabel, QPushButton, QFileDialog, QVBoxLayout, QHBoxLayout, \
QMessageBox
from PyQt5.QtGui import QPixmap, QFont, QPalette, QBrush, QImage
from PyQt5.QtCore import Qt, QTimer
import torch
import torch.nn as nn
import torchvision.models as models
from PIL import Image
import torchvision.transforms as transforms
import os
import cv2
import numpy as np 2. **类别定义**:
- 定义了五种水果类别:
classes = ('Kiwifruit', 'lemon', 'pomegranate', 'pineapple', 'Watermelon')3. **图像预处理转换**:
- 定义了测试时的图像预处理步骤,包括调整大小、转换为张量和标准化:
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])4. **设备检查和模型加载**:
- 检查是否有可用的 GPU,并加载经过训练的 VGG16 模型:
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = models.vgg16(weights=None)
num_ftrs = model.classifier[6].in_features
model.classifier[6] = nn.Linear(num_ftrs, len(classes))
model_path = 'model.pth'
if not os.path.exists(model_path):
raise FileNotFoundError(f"The model file {model_path} does not exist.")
model.load_state_dict(torch.load(model_path, map_location=DEVICE))
model.to(DEVICE)
model.eval() 5. **GUI 应用程序类**:
- 定义了水果识别应用程序的 GUI 类,初始化了窗口和界面组件,包括标签、按钮和布局:
class FruitRecognitionApp(QWidget):
def __init__(self):
super().__init__()
self.initUI()
def initUI(self):
self.setWindowTitle('水果识别')
self.setGeometry(100, 100, 1200, 800)
palette = QPalette()
background_image = QPixmap("Backdrop.jpg")
if not background_image.isNull():
palette.setBrush(QPalette.Background, QBrush(background_image))
self.setPalette(palette)
# 左侧显示原始图片或视频
self.labelOriginal = QLabel(self)
self.labelOriginal.setAlignment(Qt.AlignCenter)
self.labelOriginal.setStyleSheet("border: 2px dashed black; padding: 10px; background-color: rgba(255, 255, 255, 150);")
# 右侧显示结果图片
self.labelResult = QLabel(self)
self.labelResult.setAlignment(Qt.AlignCenter)
self.labelResult.setStyleSheet("border: 2px dashed black; padding: 10px; background-color: rgba(255, 255, 255, 150);")
# 显示预测结果的标签
self.resultLabel = QLabel('预测类别: ')
self.resultLabel.setFont(QFont('Arial', 18))
# 按钮:上传图片、开始识别、新图片上传
self.uploadButton = QPushButton('上传图片')
self.uploadButton.clicked.connect(self.uploadImage)
self.predictButton = QPushButton('开始识别')
self.predictButton.clicked.connect(self.predictImageFromFile)
self.newUploadButton = QPushButton('上传新图片')
self.newUploadButton.clicked.connect(self.reset)
# 布局
layout = QVBoxLayout()
layout.addWidget(self.labelOriginal)
layout.addWidget(self.labelResult)
layout.addWidget(self.resultLabel)
buttonLayout = QHBoxLayout()
buttonLayout.addWidget(self.uploadButton)
buttonLayout.addWidget(self.predictButton)
buttonLayout.addWidget(self.newUploadButton)
layout.addLayout(buttonLayout)
self.setLayout(layout)
```6. **图像上传和预测功能**:
- 定义了图像上传、重置和预测的功能:
def uploadImage(self):
options = QFileDialog.Options()
fileName, _ = QFileDialog.getOpenFileName(self, "选择图片", "", "Images (*.png *.jpg *.jpeg)", options=options)
if fileName:
self.displayImage(fileName)
self.predictButton.setEnabled(True)
self.newUploadButton.setEnabled(False)
def predictImageFromFile(self):
fileName = self.labelOriginal.pixmap().toImage()
self.predictImage(fileName)
def reset(self):
self.labelOriginal.clear()
self.labelResult.clear()
self.resultLabel.setText('预测类别: ')
self.predictButton.setEnabled(False)
self.newUploadButton.setEnabled(False)7. **图像显示和预测**:
- 显示上传的图像并进行类别预测
def displayImage(self, imagePath):
self.labelOriginal.setPixmap(QPixmap(imagePath).scaled(400, 400, Qt.KeepAspectRatio))
def predictImage(self, image):
try:
if isinstance(image, str):
image = Image.open(image)
image_tensor = transform_test(image).unsqueeze(0).to(DEVICE)
print(f"Image tensor: {image_tensor}")
with torch.no_grad():
outputs = model(image_tensor)
print(f"Model outputs: {outputs}")
_, predicted = torch.max(outputs, 1)
class_name = classes[predicted.item()]
print(f"Predicted class: {class_name}")
self.resultLabel.setText(f'预测类别: {class_name}')
if isinstance(image, str):
self.labelResult.setPixmap(QPixmap(image).scaled(400, 400, Qt.KeepAspectRatio))
else:
image_pil = image.convert('RGB')
image_np = np.array(image_pil)
height, width, channel = image_np.shape
bytesPerLine = 3 * width
qImg = QImage(image_np.data, width, height, bytesPerLine, QImage.Format_RGB888)
self.labelResult.setPixmap(QPixmap.fromImage(qImg).scaled(400, 400, Qt.KeepAspectRatio))
self.predictButton.setEnabled(False)
self.newUploadButton.setEnabled(True)
except Exception as e:
QMessageBox.critical(self, '错误', f'识别失败: {str(e)}')
print(f"Error: {str(e)}")8. **主程序入口**:
- 定义了应用程序的入口:
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = FruitRecognitionApp()
ex.show()
sys.exit(app.exec_())脚本总结: 这个脚本实现了一个基于 PyQt5 的 GUI 应用程序,用户可以上传图片进行水果分类识别。使用预训练的 VGG16 模型进行预测,并在界面上显示结果。主要功能包括图像预处理、模型加载、图像显示和预测,以及与用户的交互。
五.系统运行
系统的UI界面:

我们试着上传一张图片进行测试:

系统正常运行,准确的识别出了图片中的水果名称。让我们再试视频识别功能:
水果视频
视频中能够精准的识别了各个水果。















 4003
4003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









