






目录
一、引言
在人工智能(AI)的浪潮中,模型部署是将AI技术从理论转化为实际应用的关键步骤。从模型训练到生产环境的部署,每一步都需要精心设计和考虑。本文将结合具体例子和图片,深入探讨模型部署的最佳实践,并增加一些细节描述。
二、模型部署前的准备
- 模型评估
模型评估是确保模型性能达标的关键步骤。以自然语言处理(NLP)中的情感分析模型为例,我们首先需要在测试集上评估模型的性能。通过计算准确率、召回率、F1分数等指标,我们可以全面了解模型在不同情感类别上的表现。此外,混淆矩阵、ROC曲线等可视化工具也可以帮助我们更直观地了解模型的性能。
在评估过程中,我们还需要注意以下几点:
- 使用与训练集不同但具有相似分布的测试集,以确保评估结果的可靠性。
- 考虑模型在不同场景下的性能表现,如跨领域、跨语言等。
- 对模型进行鲁棒性测试,以评估其在异常输入或噪声干扰下的性能。
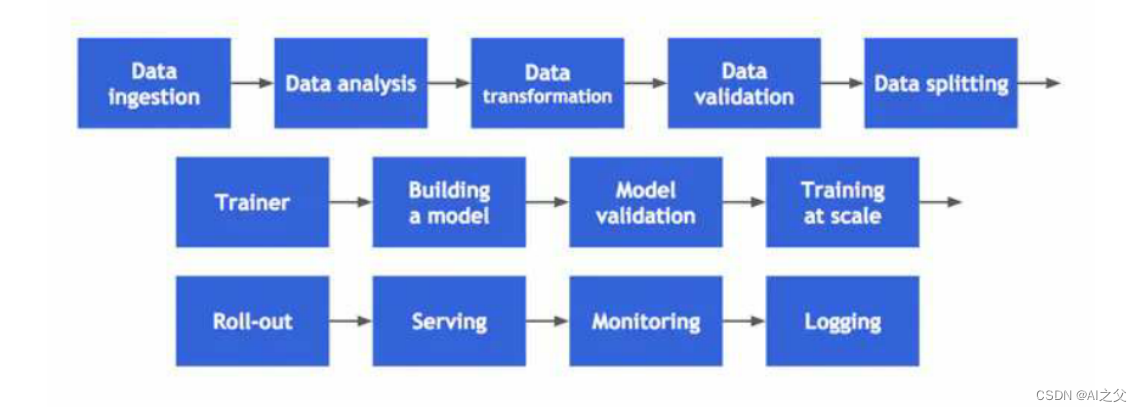
2.硬件和软件准备
根据模型的复杂度和需求,选择合适的硬件和软件环境。对于深度学习模型,高性能的GPU是不可或缺的。NVIDIA的Tesla系列GPU以其强大的计算能力和高效的内存管理而受到广泛欢迎。在软件方面,我们需要安装深度学习框架(如TensorFlow、PyTorch等)和必要的库(如NumPy、Pandas等)。
在准备过程中,我们还需要注意以下几点:
- 确保硬件和软件的兼容性,以避免在部署过程中出现不必要的麻烦。
- 根据模型的需求和预算限制选择合适的硬件配置。
- 提前规划好软件的安装和配置流程,以确保部署过程的顺利进行。
- 数据预处理
数据预处理是确保模型输入数据质量的关键步骤。以图像识别模型为例,我们可能需要将输入图像调整为固定大小、进行归一化处理等操作。对于文本数据,我们可能需要进行分词、去除停用词、词向量转换等操作。
在数据预处理过程中,我们需要注意以下几点:
- 保持与训练阶段一致的数据预处理流程,以确保模型能够正确处理输入数据。
- 对输入数据进行清洗和过滤,以去除无关信息和噪声干扰。
- 对输入数据进行适当的增强和变换,以提高模型的泛化能力。
三、模型部署流程
- 模型导出
在TensorFlow中,我们可以使用SavedModel格式将训练好的模型导出。SavedModel是一种跨平台的序列化格式,可以方便地加载到不同的环境中。在导出模型时,我们需要指定模型的输入输出格式、依赖项等信息。
2.模型加载
在部署环境中,我们可以使用TensorFlow Serving等框架来加载和提供模型服务。TensorFlow Serving是一个高性能、可扩展的机器学习服务系统,可以方便地将机器学习模型部署到生产环境中。在加载模型时,我们需要确保所有依赖项都已正确安装,并配置好模型的输入输出接口。
3.输入处理
在接收用户输入时,我们需要进行必要的预处理。对于文本数据,我们可能需要进行分词、去除停用词、词向量转换等操作;对于图像数据,我们可能需要进行图像加载、缩放、裁剪等操作。在输入处理过程中,我们需要确保处理流程与训练阶段保持一致,并考虑到性能和效率的优化。
4.模型推理
在TensorFlow Serving中,我们可以使用REST API或gRPC接口来调用模型进行推理。将预处理后的输入数据传递给模型,即可获得模型的输出结果。在推理过程中,我们需要注意以下几点:
- 确保输入数据的格式和大小与模型要求一致。
- 对输入数据进行适当的批处理或流式处理,以提高推理速度和吞吐量。
- 监控推理过程中的资源消耗和性能指标,以确保系统的稳定性和可靠性。
5.输出处理
对于模型的输出结果,我们可能需要进行后处理。以情感分析模型为例,我们可以将模型的输出结果转换为人类可读的文本(如“积极”、“消极”等),并添加置信度分数。在输出处理过程中,我们需要根据具体应用场景进行定制化处理,并考虑到用户体验和易用性。
6.错误处理和日志记录
在部署过程中,我们需要实现有效的错误处理和日志记录机制。当模型推理失败或出现异常时,我们可以返回错误信息并记录相关日志。这些日志信息可以帮助我们快速定位问题并采取相应的措施。同时,我们还需要设置告警阈值,当模型性能下降或出现异常时及时收到通知。
四、模型部署后的优化
性能优化
在模型部署后,我们可以根据实际需求对模型进行性能优化。对于实时性要求较高的应用(如在线广告推荐系统),我们可以使用模型。
参考:
拓展
五.模型训练跟模型评估的区别
模型训练和评估在机器学习中是两个不同的阶段,它们各自的目的和过程有所不同。
模型训练是指利用大量标注好的数据,通过调整模型的参数,使模型能够从输入数据中学习到有效的特征表示,从而实现特定任务的过程。这个过程通常包括以下几个步骤:
- 定义模型:根据分类或预测的具体问题来确定模型的类型和结构。
- 准备数据集:收集和整理大量标注好的数据,以便于模型从中学习。
- 拆分数据集:将准备好的数据集分为训练集、验证集和测试集。
- 确定损失函数:根据问题的性质,在训练时需要使用合适的损失函数来衡量预测结果的准确度。
- 选择优化算法:选择一个合适的优化算法,用来调整模型中的参数使其误差最小化。
- 训练模型:使用训练集进行模型的训练,通过优化算法调整模型参数,不断降低损失函数的值。
- 验证模型:使用验证集对模型进行验证,用来调整模型的超参数,提高模型的泛化性能。
而模型评估是机器学习中的一个重要环节,它指的是对训练好的模型进行性能评估,以了解模型在未见过的新数据上的表现。这通常包括使用一系列指标来量化模型的预测能力、泛化能力、稳定性等。模型评估方法不针对模型本身,只针对问题和数据,因此可以用来评价来自不同方法的模型和泛化能力,进行用于部署的最终模型的选择。
具体来说,模型训练和评估之间的主要区别如下:
- 目的不同:模型训练的目的是使模型能够从数据中学习到有效的特征表示,以实现特定任务;而模型评估的目的是评估训练好的模型在未见过的新数据上的性能表现。
- 数据使用不同:模型训练主要使用训练集和验证集;而模型评估主要使用测试集。
- 过程不同:模型训练是一个迭代的过程,通过不断优化算法调整模型参数以降低损失函数的值;而模型评估则是使用一系列指标来量化模型的性能表现。
- 结果不同:模型训练的结果是得到一个训练好的模型;而模型评估的结果是对模型性能的评价和量化指标。

















 1145
1145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









