






数据结构是“数据”和“结构”两词结合组成而来,数据结构是计算机存储、组织数据的方式
本篇文章重点是搭建顺序和链表,就像我们现在使用数组一样,可以添加数据,也可以修开数组。
此次链表为单链表
目录
前言
我们在之前的学习过程中,我们接触过数组,数组可以将数据在内存中存储时使之连续,而且还可以通过上下标找到每一个元素。
一、什么是顺序表?什么又是链表?
这两个都是线性表,在以前我们学习数学时,线性就是函数连续;而再次的线性表也是一样,它意味着,我们数据在存储时,每一个数据之间都有之一定的关系将其连接起来;
线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使用的数据结 构,常见的线性表:顺序表、链表、栈、队列、字符串...
线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的,线性表在物 理上存储时,通常以数组和链式结构的形式存储。
二、顺序表和链表的区别
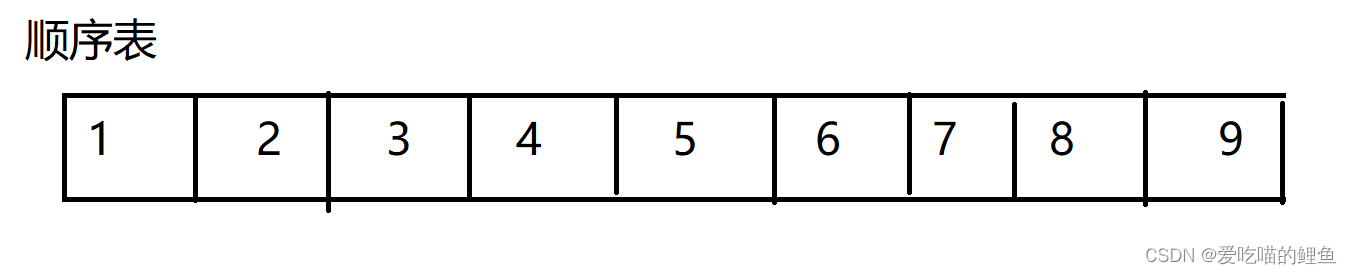
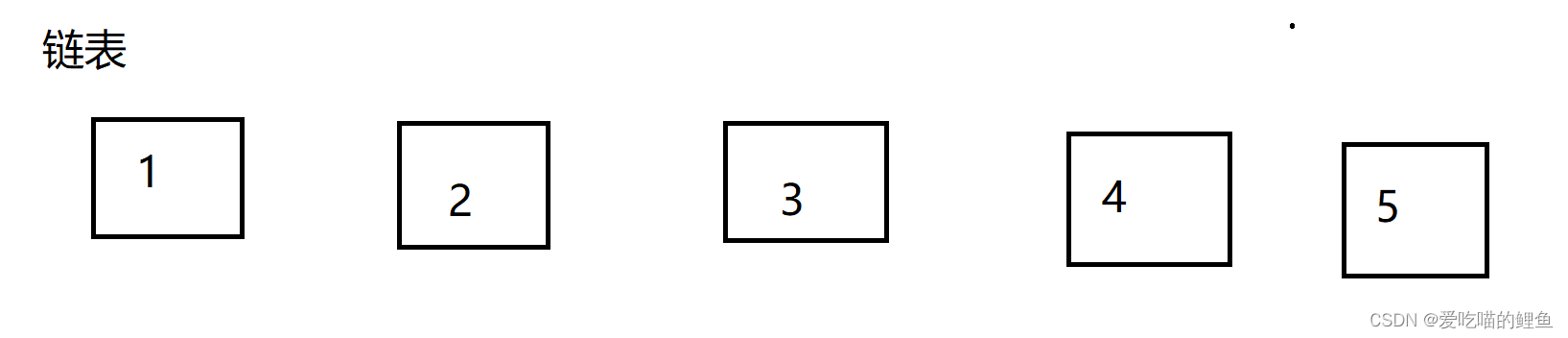
由图可见,我们发现顺序表有点像数组,那么它和数组的区别是什么呢?为何又不直接使用数组呢?
链表我们发现它是一小块一小块的,当我们找到了1 又应该怎么才能找到2呢?他们之间应该用什么维护呢?
顺序表在存储数据时是开辟一整块空间,然后将数据一个挨着一个将数据放进去,也就是我们说的物理空间连续;有人可能就会问了这不就是数组吗!
其实它的本质就是一个数组,只不过我们使用数组时空间是固定的,当我们存储数据变多的时候,数组的空间不够那么就只能修改数组的大小了;而我们前面学习了动态内存管理,动态内存管理和数组结合起来,那么我们就可以在空间不够时扩容;
链表在存储数据时,是将每一个数据放在一个小空间了,然后将这一个个数据通过地址的方式连接起来;就像酒店,每一个小房间就像链表中的一个节点,而房号好比地址,当我们想要叫人来住时,我们给他开好房,然后他通过到酒店找到我们,我们在把房号告诉他,他就可以通过房号找到房间住进去了。
所以链表的每一个节点都需要有下一个节点的地址;
三、顺序表
顺序表的结构
typedef int SLDatarype;
typedef struct SeqList
{
int size;//有效数据个数
SLDatarype* a;
int capacity;//容量
}sl;顺序表需要学会的一些功能;
//给数据初始化
void SLInit(sl* psl);
//销毁链表
void SLDestroy(sl* psl);
//在链表头部插入
void SLPushFront(sl* psl, SLDatarype x);
//在链表尾部插入数据
void SLPushBack(sl* psl, SLDatarype x);
//在链表头部删除
void SLPopforont(sl* psl);
//在链表尾部删除数据
void SLPohBack(sl* psl);
//打印顺序表每一个数据
void SLPrint(sl* psl);
//给顺序表扩容
void SLCheckCapacity(sl* psl);
//在y的位置插入数据
void SLInsert(sl* psl, SLDatarype y, SLDatarype x);
//删除y位置数据
void SLErase(sl* psl, SLDatarype y);1.给数据初始化
代码如下(示例):
void SLInit(sl* psl)
{
psl->a = (SLDatarype*)malloc(sizeof(SLDatarype) * 4);//我们在刚进入程序时,没有空间存储数据,需要malloc一片空间
if (psl->a == NULL)
{
perror("malloc");
return;
}
psl->size = 0;
psl->capacity = 4;
}我们在刚进入程序时,没有空间存储数据,需要malloc一片空间,然后将这片空间给a,让a这个数组来存储数据(我们在前面的学习过程中知道数组的本质是指针)。因为是初始化数据,所以顺序表刚开始没有数据,size就为0,然而capacity是我们想要初始化的容量,是顺序表可以存储最大个数。
2.销毁链表
代码如下(示例):
void SLDestroy(sl* psl)
{
free(psl->a);
psl->a = NULL;
psl->capacity = 0;
psl->size = 0;
}销毁链表我们只需要将a这个空间给释放掉就可以了,然后顺序表中也没有元素和空间了,所以赋值为0;
3.头部插入
代码如下(示例):
void SLCheckCapacity(sl* psl)
{
if (psl->size == psl->capacity)
{
SLDatarype* tmp = realloc(psl->a, sizeof(SLDatarype) * 2 * psl->capacity);
if (tmp == NULL)
{
perror("realloc");
return;
}
psl->a = tmp;
psl->capacity *= 2;
return;
}
}
void SLPushFront(sl* psl, SLDatarype x)
{
if (psl->capacity == psl->size)
{
SLCheckCapacity(psl);
}
//方法一
//memmove(psl->a + 1, psl->a, sizeof(SLDatarype) * psl->size);
//从前往后挪,从后往前挪都没有问题
//方法二
int end = psl->size;
while (end)
{
psl->a[end] = psl->a[end-1];
end--;
}
psl->a[0] = x;
psl->size++;
}在头部插入数据,就需要将后面的数据一次向后挪动把头部的空间给让出来,这里我们是从后开始挪动的,因为从后面开始挪动不会出现数据覆盖问题;
在每次头插、尾插和任意位置插入数据时,我们都要判断空间够不够,不够就需要扩容,所以我们将扩容那部分分离出来,写在一个函数里;
4.尾部插入
代码如下(示例):
void SLCheckCapacity(sl* psl)
{
if (psl->size == psl->capacity)
{
SLDatarype* tmp = realloc(psl->a, sizeof(SLDatarype) * 2 * psl->capacity);
if (tmp == NULL)
{
perror("realloc");
return;
}
psl->a = tmp;
psl->capacity *= 2;
return;
}
}
void SLPushBack(sl* psl, SLDatarype x)
{
if (psl->capacity == psl->size)
{
SLCheckCapacity(psl);
}
psl->a[psl->size] = x;
psl->size++;
}尾插是比较简单的,我们只需将数据放在最后面就可以了,不需要移动数据,然后让size++就可以了;
在每次头插、尾插和任意位置插入数据时,我们都要判断空间够不够,不够就需要扩容,所以我们将扩容那部分分离出来,写在一个函数里;
5.头删
代码如下(示例):
void SLPopforont(sl* psl)
{
//温柔检查
if (psl->size == 0)
return;
assert(psl->size > 0);
//perror("assert");//暴力检查
int end=psl->size-1;
while (end)
{
psl->a[psl->size-end-1] = psl->a[psl->size-end];
end--;
}
psl->size--;
}这里的检查是检查顺序是否为空,因为空的顺序表再删除里面元素什么也删不掉;
6.尾删
代码如下(示例):
void SLPohBack(sl* psl)
{
if (psl->size == 0)
return;
psl->size--;
}这里的检查是检查顺序是否为空,因为空的顺序表再删除里面元素什么也删不掉;然后然size--就可以了;
7.Y位置插入数据
代码如下(示例):
void SLInsert(sl* psl, SLDatarype y, SLDatarype x)
{
if (psl->capacity == psl->size)
{
SLCheckCapacity(psl);
}
int end = psl->size;
while (end>y)
{
psl->a[end] = psl->a[end - 1];
end--;
}
psl->a[y] = x;
psl->size++;
}关键问题说三遍:在每次头插、尾插和任意位置插入数据时,我们都要判断空间够不够,不够就需要扩容,所以我们将扩容那部分分离出来,写在一个函数里;
将后面的数据向后移动,将y位置让出来放插入数X;
8.Y位置数据删除
代码如下(示例):
void SLErase(sl* psl, SLDatarype y)
{
//memmove(psl->a[y - 1], psl->a[y], sizeof(SLDatarype) * (psl->size - y-1));
//10 2
// z1 2 3 4 5 6 7 8 9
//1 2 3 4 5 6 7 8 9 10
SLDatarype z = y - 1;
int s = psl->size - y;
while (s)
{
psl->a[z] = psl->a[z+1];
z++;
s--;
}
psl->size--;
}我们只需要把Y后面的数据向前挪动,将Y这个位置原来的数给覆盖了就可以了
9.打印顺序表
void SLPrint(sl* psl)
{
for (int i = 0; i < psl->size; i++)
{
printf("%d ", *(psl->a + i));
}
printf("\n");
}遍历的打印就可以了
10.顺序表的问题及思考
问题:
1. 中间/头部的插入删除,时间复杂度为O(N)
2. 增容需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗。
3. 增容一般是呈2倍的增长,势必会有一定的空间浪费。例如当前容量为100,满了以后增容到200,我们 再继续插入了5个数据,后面没有数据插入了,那么就浪费了95个数据空间。 思考:如何解决以上问题呢?下面给出了链表的结构来看看。
二、链表
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链 接次序实现的 。


这就是链表的物理结构
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int SListint;
typedef struct SListNode
{
SListint data;
struct SListNode* next;
}SLTNode;//在此为声名了结构体,也是链表的一个部分
//打印链表
void SLTPrin(SLTNode* phead);
//链表头插
void SLPushFront(SLTNode** phead, SListint x);
//尾插
void SListPushBack(SLTNode** pplist, SListint x);
//创建节点
SLTNode* buySLT(SListint x);
//头删
void SLPopFront(SLTNode** phead);
//尾删
void SListPopBack(SLTNode** pplist);
//查找存储X的节点
SLTNode* SLFind(SLTNode* phead, SListint x);
//给定位置插入
void SLInsert(SLTNode* phead, SLTNode* pos, SListint x);
//给定位置删除
void SLErase(SLTNode* phead, SLTNode* pos);
//删除pos后面的值
void SLEraseAdter(SLTNode* pos);1.打印链表
代码如下(示例):
oid SLTPrin( SLTNode* phend)
//我们可以加const修饰,也可以不加,因为是形参,出这个栈帧的时候里面的东西也就被销毁了
{
//SLTNode* cur = phend;
//while (cur != NULL)
//{
// printf("%d->", cur->data);
// cur=cur->next;
//}
//printf("NULL\n");
//SLTNode* cur = phend;
while (phend != NULL)
{
printf("%d->", phend->data);
phend = phend->next;
}
printf("NULL\n");
phend = NULL;
}遍历整个链表,然后一次打印data就可以了;
2.创建节点
代码如下(示例):
SLTNode* buySLT(SListint x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));//开辟了一块空间
if (newnode == NULL)
{
perror("malloc dail");
return;
}
newnode->data = x;//插入的数,开辟的空间为SLTNode类型,为结构体,我们可以用箭头的方式解引用调出类型中的data
newnode->next = NULL;//先让新空间中的下一个地址为空
return newnode;
}我们创建了一个节点,然后将x给放进去,然后将NULL制空,方便后续链接;
3.头部插入
代码如下(示例):
void SLPushFront(SLTNode** phead, SListint x)//如果一级指针,那么phead中方的就是火车头的内容,为空指针;二级指针放的就是火车头的地址
//*phead 为NULL,也就是火车头里面的东西;phead为放空指针的地址,也就是火车头的地址
{
assert(phead);//火车头一定存在的,所以不存在找不到火车头,但是火车头里面可以什么都不放
SLTNode* newnode = buySLT(x);//开辟了一块空间
newnode->next = *phead;//然后在让新的空间中放入火车头的内容;火车头放的是之前第一个空间的地址
*phead = newnode;//*phead 为火车头的内容,让火车头里面放入开辟新空间的地址;
}因为我们开辟节点返回来的是一个指针,在头部插入数据,我们让新节点的下一个元素的变为火车头原来的地址;所以我们需要让火车头指向新的节点;
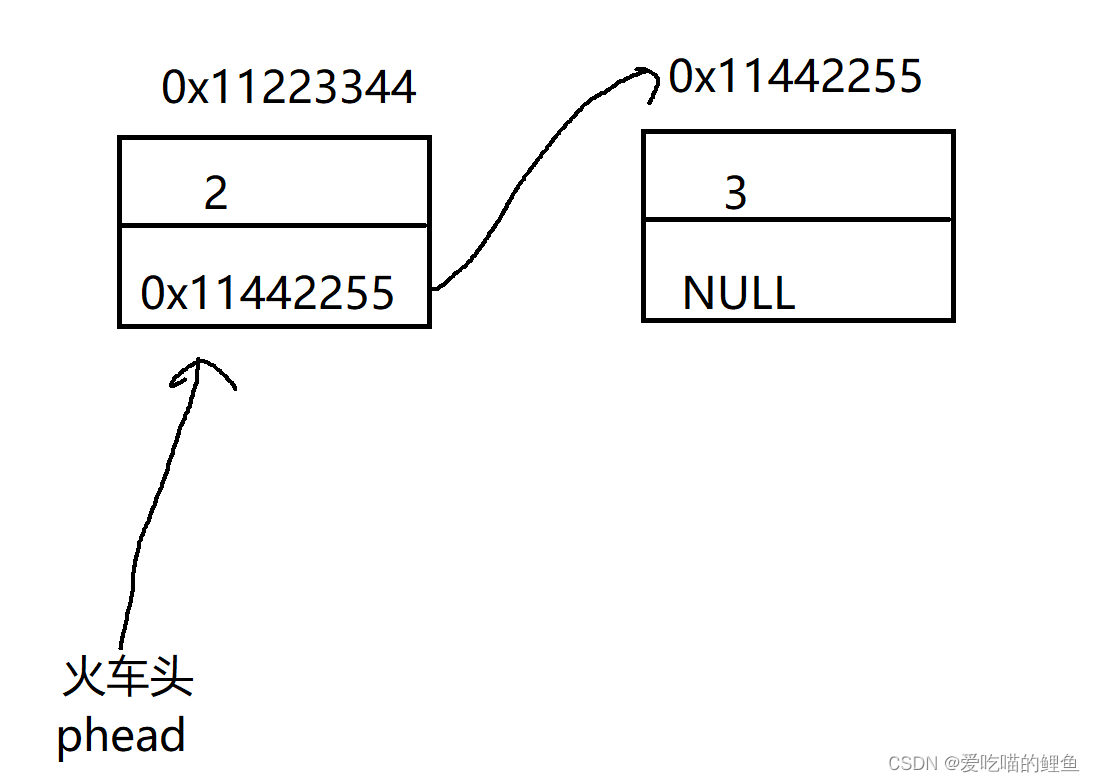
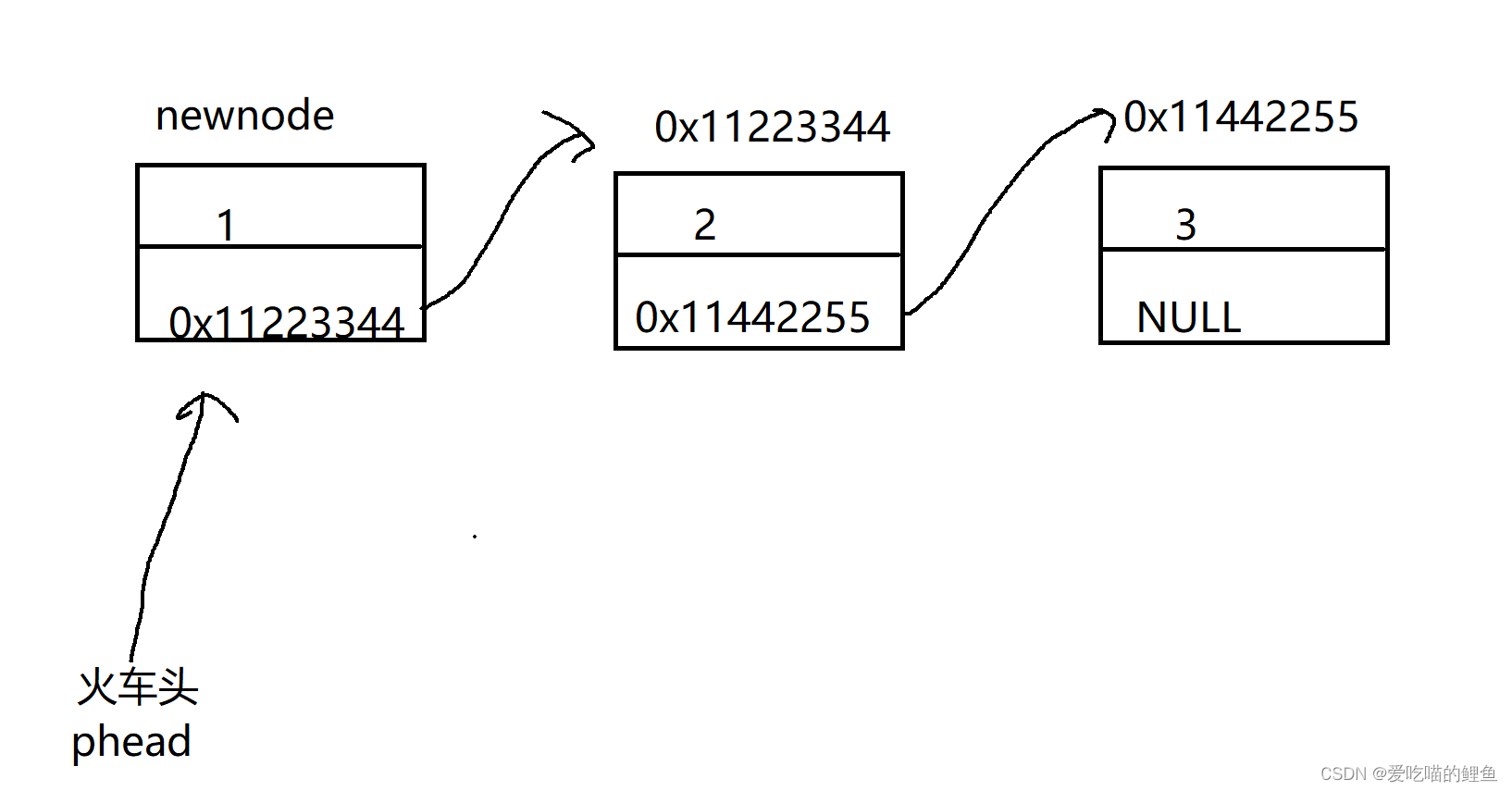
4.尾部插入
代码如下(示例):
void SListPushBack(SLTNode** pplist, SListint x)
{
assert(pplist);
SLTNode* newnode = buySLT(x);
//分两种情况
//1.火车头里面是空指针,如果我们直接通过空指针往下找,什么也找不到,也就是当链表长度为0是,我们尾插,找不到存放next为空的那个节点,我们就可以直接将火车头修改掉
//2.链表长度不为0,我们直接可以找到存放next为空的那个节点,也就是最后一个节点,因为只有最后面的节点nest为空
if (*pplist == NULL)//
{
*pplist = newnode;//因为需要改变火车头里面的内容,改变地址,所以我们用的是二级指针,一级指针已经是一个地址,所以需要二级指针来修改一级指针中的内容
}
else
{
SLTNode* tail = *pplist;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}我们只需要先找到尾部节点,尾部节点有一个特点没那就是尾部节点的next为NULL;
然后让尾部节点的next等于新建的节点的地址
5.头删
代码如下(示例):
void SLPopFront(SLTNode** phead)
{
assert(phead);
assert(*phead);//链表为空了不能删除
SLTNode* tail = *phead;
SLTNode* prev = tail;
//一个节点
if (tail->next == NULL)
{
free(tail);
*phead = NULL;
}
//没有节点
else if (tail == NULL)
{
return;
}
//多个节点
else
{
//找到结尾的节点
//找前后
//方法一定义一个指针指向tail;
while (tail->next != NULL)//因为我们要找倒数第二节点,我们就可以用两个箭头的方式
{ //方法二 while(tail->next->next!=NULL);第一步找到tail这个地址里面的next这个地址,然后在通过这个地址,找到下一个节点里面的next,当这个next为空的时候也就是说tail找到了倒数第二节点,然后停止
prev = tail;
tail = tail->next;
}
prev->next = NULL;
free(tail);
tail = *phead;
}
}6.尾删
代码如下(示例):
void SListPopBack(SLTNode** pplist)
{
assert(pplist);
assert(*pplist);//链表为空了不能删除
SLTNode* plist = *pplist;
if (plist->next == NULL)
{//一个节点
free(*pplist);
*pplist = NULL;
}
else
{
*pplist = plist->next;
free(plist);
*pplist = NULL;
}
}尾删和头删都需要考虑第二个节点是不是空的,也就是只有一个节点的情况
7.查找data为x的节点
代码如下(示例):
SLTNode* SLFind(SLTNode* phead, SListint x)
{
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur= cur -> next;
}
return NULL;
}
遍历的找一遍,找的了就返回那个节点的地址,否则返回空指针
8.在pos前面插入
代码如下(示例):
void SLInsert(SLTNode** phead, SLTNode* pos, SListint x)
{
//assert(pos);
assert(phead);
assert(*phead);
if (*phead == pos)
{
SListPushBack(phead, x);
}
SLTNode* haid = *phead;
while (haid->next != pos)
{
haid = haid->next;
}
SLTNode* newnode = buySLT(x);
haid->next = newnode;
haid->next->next = pos;
}前提是链表不为空,如果是空的,所以这里我们最先就断言了一下;断言如果是我们想要的就会继续往下走,不是就直接结束了
9.删除pos位置的值
void SLErase(SLTNode** phead, SLTNode* pos)
{
assert(phead);
assert(*phead);
if (*phead == pos)
{
SListPopBack(phead);
}
SLTNode* haid = *phead;
while (haid->next != pos)
{
haid = haid->next;
}
haid->next = pos->next;
free(pos);
}10.删除pos后面的值
void SLEraseAdter( SLTNode* pos)
{
assert(pos);
assert(pos->next);
SLTNode* haid = pos->next;
pos->next=haid->next;
free(haid);
}总结
什么是线性表?
创建顺序表和链表。
















 2594
2594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











