






1.背景简介
Ecapa Tdnn的性能出色,但需要以高的计算复杂度和慢的推理速度为代价。
不适合在对推理速度和计算资源有限制的条件下使用。
1.1 目的
兼顾Ecapa Tdnn的表现和tdnn的效率。
1.2Cam++
cam++采取了D-Tdnn和multi-granularity pooling来提取上下文信息。
1.3数据集
VoxCeleb和CnCeleb上cam++以更低的计算复杂度和更快的推理速度超过了其他主流说话人验证系统
2.模型架构
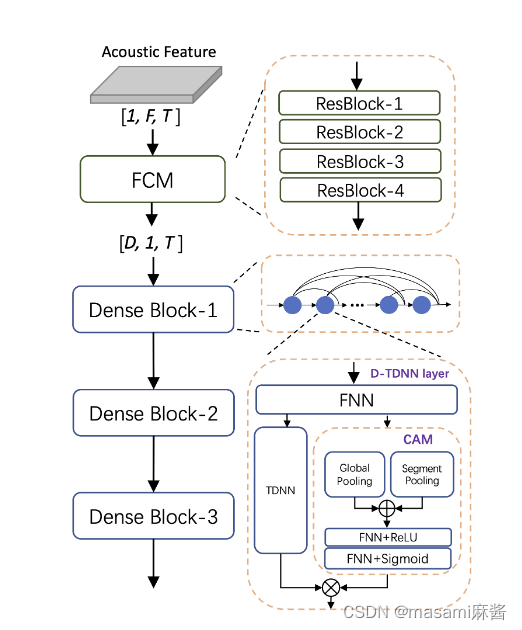
2.1 D-Tdnn
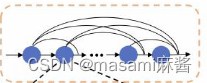 每个Dtdnn层的输入都是前面所有Dtdnn层的输出以及整个Dtdnn快的输入。
每个Dtdnn层的输入都是前面所有Dtdnn层的输出以及整个Dtdnn快的输入。
D-Tdnn是相对于Tdnn,它可以做到更少参数,计算成本更低,但和ecapa tdnn,resnet34有差距。
这篇论文先将D-TDNN块的D-TDNN层进行了改进
原来的样子是:
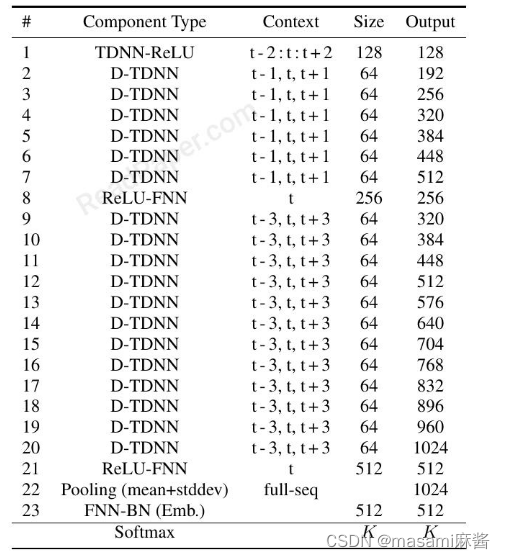
原来1和8之间夹了6个dtdnn层,现在增加到12层,原来8和21之间夹了12个dtdnn层,现在增加到24,之后它应该是在21之后又加了16个tdnn层。将原来Dtdnn层的Size(增长率)由64同意降低到32.此外,还将每一层的滤波器的通道数减少。最后实现了模型深度增加,控制了复杂性的增加。
2.2CAM
tdnn层关注局部时间特征,cam是通过上下文嵌入e来预测,预计得到的M会包含关注的说话者和噪声的特征。
cam使用全局统计池化和分段平均统计池化,将两者结果聚合并经过FNN,relu,sigmoid函数得到M。
M与tdnn的结果F(X)逐元素相乘。让结果有效感知上下文。
作用:将CAM模块嵌入到每个Dtdnn层,增强网络的声纹特征的表示能力。
2.3 FCM
原来TDNN采用一维卷积,使用的卷积核会覆盖时延范围内的全频率,会在某些局部频率区域捕获说话人的声音特征比较困难。
此外Dtdnn为了让网络深度变深,就让每个Dtdnn层变窄,减少参数量,这样会导致在某些局部频率区域捕获说话人的声音特征比较困难。
FCM采用具有残差连接的二维卷积块对时频域同时卷积。
3.实验结果
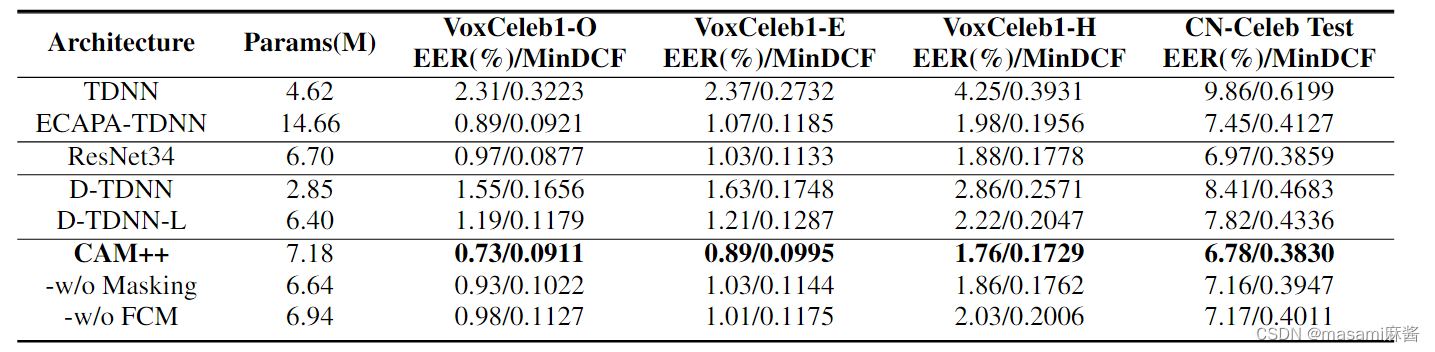
CAM++在VoxCeleb1和CN-Celeb上错误iv都是最低的
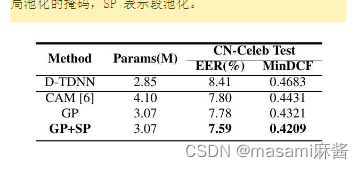
使用了带全局池化(GP)和分段池化(SP)的CAM,并且将CAM加入到每个DTDNN层中(CAM[6]是指将CAM加入到DTDNN块后的过渡层)效果最好。
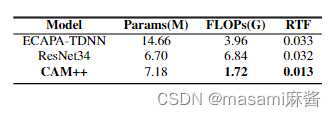
复杂性上,CAM++略高于Resnet34,但浮点运算和推理时间都远低于Ecapa和resnet34.
4.结论
CAM+引入了一种新颖的上下文感知遮蔽方法,旨在聚焦于感兴趣的说话者,并提高特征的质量,同时,多粒度池化将不同层次的上下文信息融合,生成准确的注意力权重。
CAM++在计算复杂性更低和推断速度更快的情况下,相较于流行的ECAPA-TDNN和ResNet34系统,取得了更优越的性能。















 4007
4007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









