







大多数机器学习和深度学习模型都缺乏解释和解释结果的方法。由于深度学习模型的动态特性和不断增加的最先进模型,当前的模型评估基于准确度分数。这使得机器学习和深度学习成为黑盒模型。这导致对应用模型缺乏信心,对生成的结果缺乏信任。有多个库可以帮助我们解释结构化数据模型,例如 SHAP 和 LIME。本章介绍计算机视觉模型输出。
以下是近年来提出的一些用于计算机视觉的白盒算法:
CAM
Grad-CAM
Grad-CAM++
Layer-wise relevance propagation (LRP)
SmoothGRAD
RISE
Neural based decision trees (NBDT)
本章重点介绍 Grad-CAM、Grad-CAM++ 和 NBDT。在我们继续实施之前,我们深入探讨以下概念。
Grad-CAM
类激活图 (CAM)是一种提取热图的技术,该热图突出了影响结果的空间信息。CAM 架构如图10-1a和10-1b所示。

图 10-1a CAM架构
生成的特征图通过全局平均池化来提取权重。权重通过全连接层输出分类结果。
架构中突出显示的部分,即特征图和权重,用于生成预测类的热图。
特征图的加权和 = ∑k (wk *Ak ^class)
其中 k 表示来自最后一个卷积层的特征图。
在特征图生成步骤之前,Grad-CAM 与 CAM 类似。在这一步之后,可以添加任何神经网络(例如VGG、ResNet等),这些神经网络可以是可微的,以取回梯度。基于预测结果,计算每个特征图的梯度。使用特征图维度 (i,j) 宽度和深度上的梯度“全局平均池化”为每个特征图计算神经元重要性(alpha 值/权重)。Grad-CAM 架构如图10-1b所示。突出显示的组件相乘以生成热图。

图 10-1b CAM架构
Grad-CAM++
这类似于 Grad-CAM算法,但在反向传播步骤上有所不同。简单来说,Grad-CAM 在反向传播过程中使用一阶梯度。在 Grad-CAM++ 中,使用二阶梯度,从而使过程更加复杂。
在 Grad-CAM 中,与最终热图中具有高空间信息的特征图相比,具有较少空间信息的特征图没有得到重视。在热图中无法检测到包含多个对象或单个对象的图像,从而导致准确性和可解释性较低。
在 Grad-CAM++ 中,通过重视最终热图中的所有特征图来解决此问题。图10-2显示了整体架构。

图 10-2 Grad-CAM++架构
图10-3显示了 Grad-CAM 和 Grad-CAM++ 的结果差异。

图 10-3 Grad-CAM 和Grad-CAM++的结果
NBDT
这代表基于神经的决策树. 许多算法被提出用于模型的可解释性,但遗漏了结果可解释性的概念。
可解释性:理解模型的内部机制,即它在内部是如何工作的。
可解释性:了解结果的因果关系,即特定结果是在什么基础上产生的。
决策树是白盒模型,因为它们可以很容易地理解节点是如何划分的。这使得 DT 可以解释。
也很容易知道相对于输入变化的预测输出。这使得 DT 可解释。
与深度学习模型相比,DT 的滞后点是模型准确性。NBDT 具有决策树(用于可解释性和可解释性)和神经网络(用于准确性)的内置组合。图10-4显示了 NBDT流程。
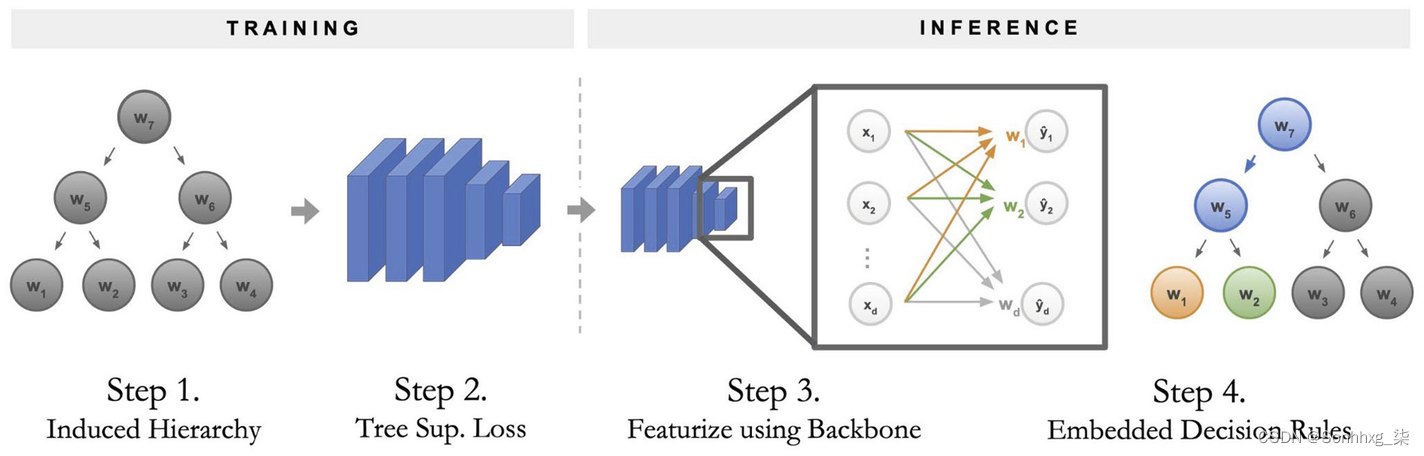
图 10-4 NBDT流程
第 2 步
此步骤训练用于图像分类的 CNN 模型。提取每个类别预测的权重 (w1, w2,...),其中 w1 表示用于预测类别 1 的隐藏权重向量。
最近的向量(也称为叶子)聚集在一起形成中间节点。这些中间节点聚集在一起,直到到达根节点。这种层次结构称为诱导层次结构。在此之后,我们将 NN 转换为 DT。
中间节点的名称是基于 WordNet 模块提取的。(例如,狗和猫是叶节点。中间节点可以是从 WordNet 中提取的“动物”。)
第2步
这一步计算分类损失并对模型进行微调。可以使用两种模式计算分类损失。
困难模式
柔和模式
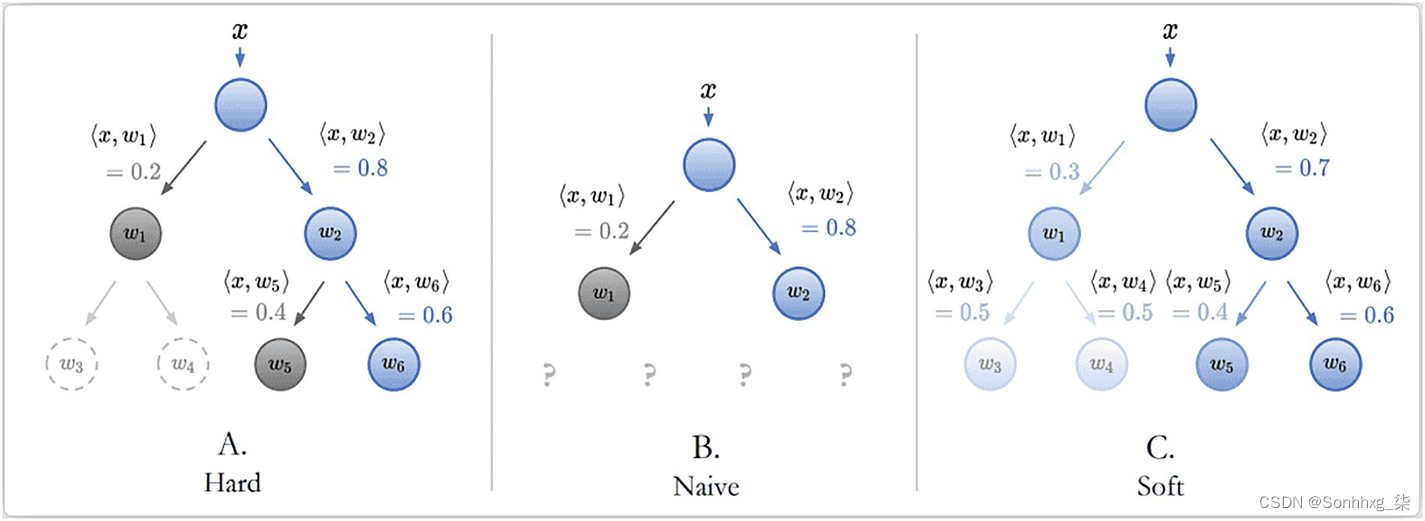
图 10-5 硬模式和软模式的区别
Loss (Total) = Loss (original) + Loss (hard or soft)
将硬损失或软损失添加到原始损失(来自 CNN)以获得最终损失。
第 3 步 和 第 4 步
根据计算出的最终损失,对模型进行微调并更新决策树(层次结构)。
Grad-CAM 和 Grad-CAM++ 实施
首先,我们讨论单个图像上的 Grad-CAM 和 Grad-CAM++ 实现,然后我们讨论单个图像上的 NBDT 实现。
Grad-CAM 和 Grad-CAM++ 在单个图像上的实现
第一步:对输入图像进行图像变换(见图10-6)。

图 10-6 对输入图像进行图像变换
这包括:
根据步骤 2 中的架构调整图像大小。
使用 PyTorch 将调整大小的图像转换为张量以加快计算速度。
图 10-7 改造前

图 10-8 改造后
# Transform input Image- 在传递给模型之前调整大小
resized_torch_img = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor()])(pil_img).to(device)
# 图像归一化
normalized_torch_img = transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])(resized_torch_img)[None]第 2 步:加载神经网络架构(在本例中使用预训练权重)。测试了以下预训练模型以比较它们的结果:
AlexNet
VGG16
ResNet101
DenseNet161
SqueezeNet
# pytorch-gradcam 库中支持的架构
model_alexnet = models.alexnet(pretrained=True)
model_vgg = models.vgg16(pretrained=True)
model_resnet = models.resnet101(pretrained=True)
model_densenet = models.densenet161(pretrained=True)
model_squeezenet = models.squeezenet1_1(pretrained=True)第三步:选择神经网络中的反馈层来反向传播梯度。选择首选层来反向传播梯度。
# 将模型存储为字典项,其中包含将采用渐变的各个层
loaded_configs = [
dict(model_type='alexnet', arch=model_alexnet, layer_name='features_11'),
dict(model_type='vgg', arch=model_vgg, layer_name='features_29'),
dict(model_type='resnet', arch=model_resnet, layer_name='layer4'),
dict(model_type='densenet', arch=model_densenet, layer_name='features_norm5'),
dict(model_type='squeezenet', arch=model_squeezenet, layer_name='features_12_expand3x3_activation')]第 4 步:加载 Grad-CAM 和 Grad-CAM++ 模型。
这两个模型都是从pytorch-gradcam库加载的。
# 将配置加载到“Grad CAM”和“Grad CAM ++”
# 此库中仅提供“Grad CAM”和“Grad CAM ++”
for model_config in loaded_configs:
model_config['arch'].to(device).eval()
#为所有可用架构(loaded_configs)保存“Grad CAM”和“Grad CAM ++”实例
cams = [[cls.from_config(**model_config) for cls in (GradCAM, GradCAMpp)] for model_config in loaded_configs]第五步:传递变换后的输入图像,生成热图。
将转换后的图像传递给两个模型,并以热图的形式生成结果。这些热图将突出显示图像中的关键补丁。
# 将归一化后的图像加载到各个架构下的“gradcam,gradcam++”函数中,产生heatmaps和result
images = []
for gradcam, gradcam_pp in cams:
mask, _ = gradcam(normalized_torch_img)
heatmap, result = visualize_cam(mask, resized_torch_img)
mask_pp, _ = gradcam_pp(normalized_torch_img)
heatmap_pp, result_pp = visualize_cam(mask_pp, resized_torch_img)
images.extend([resized_torch_img.cpu(),result,result_pp])
# Grid原始图像,gradcam结果,gradcam++结果
grid_image = make_grid(images, nrow=3)第 6 步:结合输入图像和热图,可视化选择用于分类的重要特征。
将输出张量转换为 Python 可读图像以可视化结果。以下输出是使用 DenseNet 预训练权重生成的。
输入图像>> Grad-CAM输出>> Grad-CAM++输出

图 10-9 输出
单个图像上的 NBDT 实现
第一步:对输入图像进行图像变换,类似于Grad-CAM。
# 加载图像和执行图像转换的功能(调整大小、居中裁剪、转换为张量、归一化)
def load_image():
assert len(sys.argv) > 1
im = load_image_from_path("image_path”)
transform = transforms.Compose([
transforms.Resize(32),
transforms.CenterCrop(32),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
x = transform(im)[None]
return x第 2 步:使用预训练模型加载 NBDT 模型。为了查找模型层次结构,使用了wordnet库。
# 加载带有预训练权重的NBDT模型的函数
def load_model():
model = wrn28_10_cifar10()
model = HardNBDT(
pretrained=True,
dataset='CIFAR10',
arch='wrn28_10_cifar10',
model=model)
return model第 3 步:预测HardNBDT 模型的输出。将预测结果和层次结构转换为已知类。
# 输出分类结果和层级的函数
def hierarchy_output(outputs, decisions):
_, predicted = outputs.max(1)
predicted_class = DATASET_TO_CLASSES['CIFAR10'][predicted[0]]
print('Predicted Class:', predicted_class,
'\n\nHierarchy:',
', '.join(['\n{} ({:.2f}%)'.format(info['name'], info['prob'] * 100)
for info in decisions[0]][1:]))第四步:从决策树中输出预测的类和层级。
def main():
model = load_model()
x = load_image()
outputs, decisions = model.forward_with_decisions(x)
hierarchy_output(outputs, decisions)
if __name__ == '__main__':
main()这是结果:
Predicted Class: horse
Hierarchy:
animal (99.52%),
ungulate (98.52%),
horse (99.71%)
概括
可解释性在未来发挥着重要作用,因为每个人都想了解幕后发生的事情。商业领袖将很难相信人工智能模型。如果无法解释结果,所有的 AI 解决方案都是不完整的,计算机视觉也不例外。
牢记这一点,我们在本章中浏览了各种库以实现可解释性。我们了解了 CAM、Grad-CAM 和 Grad-CAM++ 的概念。与此同时,我们使用预训练模型和预测实现了可解释性。这是对可解释性的简单介绍;有很多东西需要学习和实施。
















 1553
1553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











