






一、引言
随着人工智能技术的飞速发展,自然语言处理(NLP)成为备受瞩目的领域,旨在让机器理解、生成人类语言。Transformer 架构掀起了 NLP 革命,Google 提出的 T5 模型更是在此基础上大放异彩,凭借独特的文本到文本框架,统一多种 NLP 任务,展现出强大的泛化与适应能力,成为学界、业界的重点关注对象。
二、T5 模型基础架构剖析
2.1 Transformer 核心组件回顾
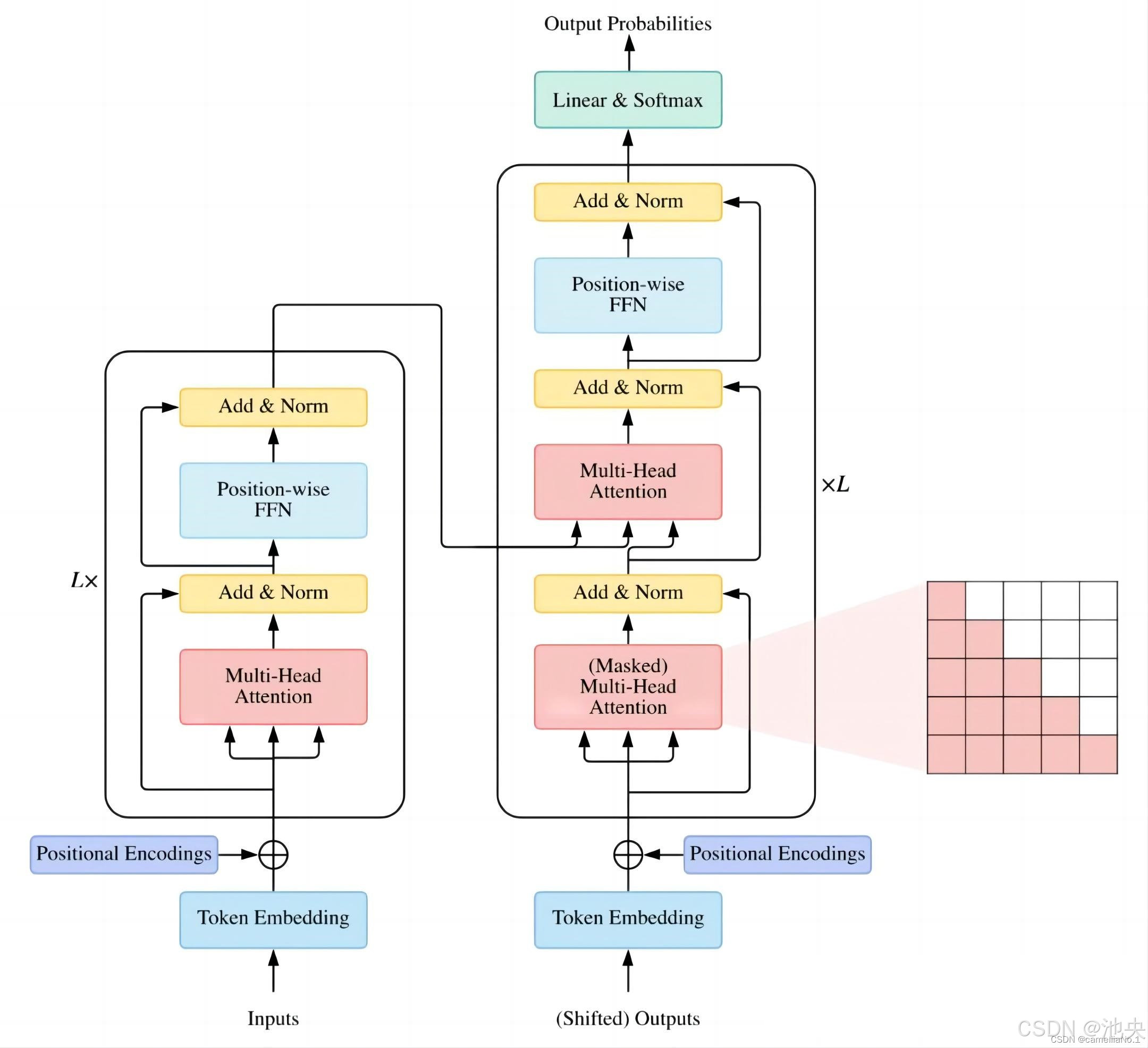
Transformer 关键在于多头注意力机制(Multi-Head Attention)、前馈神经网络(Feed-Forward Network)。多头注意力允许模型并行捕捉输入不同子空间信息,公式如下:
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads
assert self.head_dim * num_heads == d_model, "Invalid head configuration"
self.q_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.out_linear = nn.Linear(d_model, d_model)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
Q = self.q_linear(query).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
K = self.k_linear(key).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
V = self.v_linear(value).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.head_dim ** 0.5)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, float('-inf'))
attn_probs = torch.softmax(attn_scores, dim=-1)
output = torch.matmul(attn_probs, V).transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
return self.out_linear(output)前馈网络则对每个位置独立处理,增强模型非线性表达,形如:FFN(x) = max(0, xW1 + b1)W2 + b2,代码呈现为:
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super(FeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
def forward(self, x):
x = torch.nn.functional.relu(self.linear1(x))
return self.linear2(x)2.2 T5 架构特色
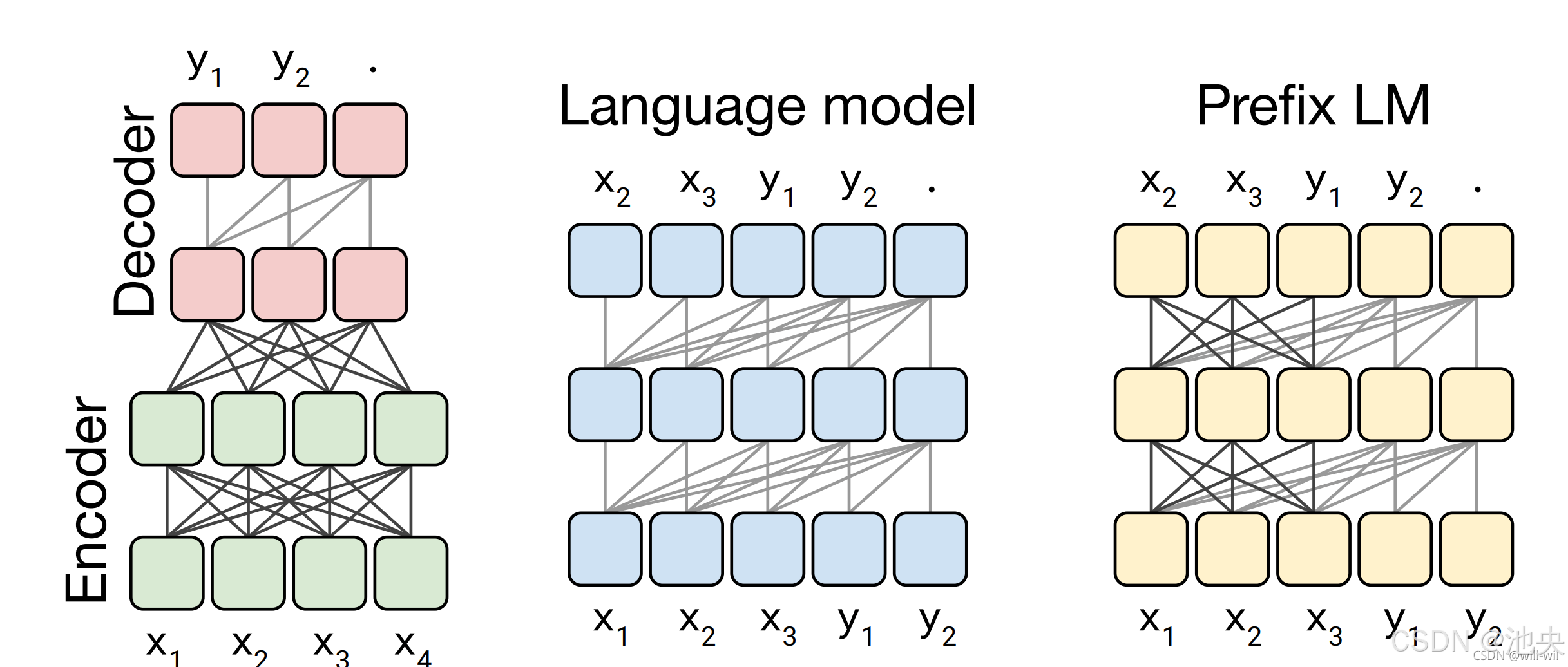
T5 模型架构基于标准 Transformer 改良,编码器 - 解码器结构对称。编码器堆叠多层双向注意力模块解析输入文本语义;解码器借掩码多头注意力关注已生成部分,配合交叉注意力参考编码器输出生成后续文本,确保生成连贯性、准确性。模型全程文本序列处理,输入、输出均为文本形式,输入前添加特定任务前缀,如 “translate English to French:” 引导模型执行英法翻译,实现多任务统一表征。
三、T5 预训练策略
3.1 预训练数据
T5 预训练动用大规模多领域文本语料,涵盖维基百科、书籍、新闻文章等超万亿单词量,数据清洗、去重后经字节对编码(Byte-Pair Encoding,BPE)分词,将文本切分为子词单元便于模型学习词法、句法规律,提升泛化性,不同语种数据融合预训练赋予模型多语处理潜能。
3.2 训练目标:去噪自编码器
T5 训练采用去噪自编码器范式,对原始文本随机破坏,像删除单词、替换单词、打乱词序,模型接收受损文本恢复原始内容。给定原始文本 x = [x1, x2,..., xn],破坏操作得 x',模型最小化重构损失 L(x, x''),x'' 是模型输出,常用交叉熵损失:
import torch.nn.functional as F
def compute_loss(logits, targets):
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1))
return loss这驱使模型捕捉文本内在结构、语义依赖,学会补全、纠错,强化语言理解与生成功底。
四、T5 在自然语言处理任务中的实战应用
4.1 文本分类任务
文本分类是常见 NLP 任务,将文本分入预定类别,如新闻情感正负判别、邮件优先级分级。用 T5 时,输入形如 “classify sentiment of text: [待分类文本]”,模型输出 “positive” 或 “negative” 等类别标签。代码实现
import transformers
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained('t5-base')
model = T5ForConditionalGeneration.from_pretrained('t5-base')
text = "This movie is amazing, I really enjoyed it."
input_text = "classify sentiment of text: " + text
input_ids = tokenizer.encode(input_text, return_tensors='pt')
outputs = model.generate(input_ids)
decoded_output = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded_output)
# 预期输出 "positive"4.2 机器翻译
机器翻译是 T5 强项,输入 “translate [源语言] to [目标语言]: [源文本]”,输出目标语言译文。以下是英译汉示例:
text = "Hello, how are you?"
input_text = "translate English to Chinese: " + text
input_ids = tokenizer.encode(input_text, return_tensors='pt')
outputs = model.generate(input_ids)
decoded_output = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded_output)
# 预期输出 "你好,你怎么样?"调整超参数(如生成长度、温度系数)可优化译文流畅自然度,温度越高译文越多样,长度限制控制输出字数。
五、T5 模型的局限性与挑战
5.1 长文本处理
T5 处理长文本有局限,随文本变长,注意力计算量呈二次增长,内存消耗大、效率低,易梯度消失或爆炸。虽引入滑动窗口、局部敏感哈希优化,长距语义捕捉仍待提升,处理超长合同、小说章节时连贯性欠佳。
5.2 知识更新与时效性
预训练模型知识固化,新事件、热词难实时反映,问答热门影视资讯,模型可能输出过时信息;知识图谱融合、持续学习机制待完善,确保模型知识与时俱进。
5.3 伦理与偏见问题
训练数据偏见嵌入模型,性别、种族偏见影响决策,招聘简历筛选、信贷评估场景可能不公;生成内容可控性弱,恶意引导易产不当信息,需对抗训练、人工审核把关,确保伦理合规。



















 850
850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











