






使用RNN网络建模SMILES序列
下载所需要的库
!pip install pandas
!pip install rdkit
!pip install torch导入所需要的包
import re
import time
import pandas as pd
from typing import List, Tuple
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader, Subset首先,我们定义一个RNN模型
可以直接使用pytorch完成。
# 定义RNN模型
class RNNModel(nn.Module):
def __init__(self, num_embed, input_size, hidden_size, output_size, num_layers, dropout, device):
super(RNNModel, self).__init__()
self.embed = nn.Embedding(num_embed, input_size)
self.rnn = nn.RNN(input_size, hidden_size, num_layers=num_layers,
batch_first=True, dropout=dropout, bidirectional=True)
self.fc = nn.Sequential(nn.Linear(2 * num_layers * hidden_size, output_size),
nn.Sigmoid(),
nn.Linear(output_size, 1),
nn.Sigmoid())
def forward(self, x):
# x : [bs, seq_len]
x = self.embed(x)
# x : [bs, seq_len, input_size]
_, hn = self.rnn(x) # hn : [2*num_layers, bs, h_dim]
hn = hn.transpose(0,1)
z = hn.reshape(hn.shape[0], -1) # z shape: [bs, 2*num_layers*h_dim]
output = self.fc(z).squeeze(-1) # output shape: [bs, 1]
return output这一部分我们定义数据处理函数,以及tokenizer
这里的tokenizer是自定义的,目的是针对SMILES划分token。
# import matplotlib.pyplot as plt
## 数据处理部分
# tokenizer,鉴于SMILES的特性,这里需要自己定义tokenizer和vocab
# 这里直接将smiles str按字符拆分,并替换为词汇表中的序号
class Smiles_tokenizer():
def __init__(self, pad_token, regex, vocab_file, max_length):
self.pad_token = pad_token
self.regex = regex
self.vocab_file = vocab_file
self.max_length = max_length
with open(self.vocab_file, "r") as f:
lines = f.readlines()
lines = [line.strip("\n") for line in lines]
vocab_dic = {}
for index, token in enumerate(lines):
vocab_dic[token] = index
self.vocab_dic = vocab_dic
def _regex_match(self, smiles):
regex_string = r"(" + self.regex + r"|"
regex_string += r".)"
prog = re.compile(regex_string)
tokenised = []
for smi in smiles:
tokens = prog.findall(smi)
if len(tokens) > self.max_length:
tokens = tokens[:self.max_length]
tokenised.append(tokens) # 返回一个所有的字符串列表
return tokenised
def tokenize(self, smiles):
tokens = self._regex_match(smiles)
# 添加上表示开始和结束的token:<cls>, <end>
tokens = [["<CLS>"] + token + ["<SEP>"] for token in tokens]
tokens = self._pad_seqs(tokens, self.pad_token)
token_idx = self._pad_token_to_idx(tokens)
return tokens, token_idx
def _pad_seqs(self, seqs, pad_token):
pad_length = max([len(seq) for seq in seqs])
padded = [seq + ([pad_token] * (pad_length - len(seq))) for seq in seqs]
return padded
def _pad_token_to_idx(self, tokens):
idx_list = []
for token in tokens:
tokens_idx = []
for i in token:
if i in self.vocab_dic.keys():
tokens_idx.append(self.vocab_dic[i])
else:
self.vocab_dic[i] = max(self.vocab_dic.values()) + 1
tokens_idx.append(self.vocab_dic[i])
idx_list.append(tokens_idx)
return idx_list
# 读数据并处理
def read_data(file_path, train=True):
df = pd.read_csv(file_path)
reactant1 = df["Reactant1"].tolist()
reactant2 = df["Reactant2"].tolist()
product = df["Product"].tolist()
additive = df["Additive"].tolist()
solvent = df["Solvent"].tolist()
if train:
react_yield = df["Yield"].tolist()
else:
react_yield = [0 for i in range(len(reactant1))]
# 将reactant拼到一起,之间用.分开。product也拼到一起,用>分开
input_data_list = []
for react1, react2, prod, addi, sol in zip(reactant1, reactant2, product, additive, solvent):
input_info = ".".join([react1, react2])
input_info = ">".join([input_info, prod])
input_data_list.append(input_info)
output = [(react, y) for react, y in zip(input_data_list, react_yield)]
# 下面的代码将reactant\additive\solvent拼到一起,之间用.分开。product也拼到一起,用>分开
'''
input_data_list = []
for react1, react2, prod, addi, sol in zip(reactant1, reactant2, product, additive, solvent):
input_info = ".".join([react1, react2, addi, sol])
input_info = ">".join([input_info, prod])
input_data_list.append(input_info)
output = [(react, y) for react, y in zip(input_data_list, react_yield)]
'''
# # 统计seq length,序列的长度是一个重要的参考,可以使用下面的代码统计查看以下序列长度的分布
# seq_length = [len(i[0]) for i in output]
# seq_length_400 = [len(i[0]) for i in output if len(i[0])>200]
# print(len(seq_length_400) / len(seq_length))
# seq_length.sort(reverse=True)
# plt.plot(range(len(seq_length)), seq_length)
# plt.title("templates frequence")
# plt.show()
return output
class ReactionDataset(Dataset):
def __init__(self, data: List[Tuple[List[str], float]]):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def collate_fn(batch):
REGEX = r"\[[^\]]+]|Br?|Cl?|N|O|S|P|F|I|b|c|n|o|s|p|\(|\)|\.|=|#|-|\+|\\\\|\/|:|~|@|\?|>|\*|\$|\%[0-9]{2}|[0-9]"
tokenizer = Smiles_tokenizer("<PAD>", REGEX, "../vocab_full.txt", max_length=300)
smi_list = []
yield_list = []
for i in batch:
smi_list.append(i[0])
yield_list.append(i[1])
tokenizer_batch = torch.tensor(tokenizer.tokenize(smi_list)[1])
yield_list = torch.tensor(yield_list)
return tokenizer_batch, yield_list训练的函数(里面的参数是我自己调过,但不是我最终选择的参数)
def train():
## super param
N = 10 #int / int(len(dataset) * 1) # 或者你可以设置为数据集大小的一定比例,如 int(len(dataset) * 0.1)
NUM_EMBED = 294 # nn.Embedding()
INPUT_SIZE = 300 # src length
HIDDEN_SIZE = 512
OUTPUT_SIZE = 512
NUM_LAYERS = 10
DROPOUT = 0.01
CLIP = 1 # CLIP value
N_EPOCHS = 10
LR = 0.00001
start_time = time.time() # 开始计时
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# device = 'cpu'
data = read_data("../dataset/round1_train_data.csv")
dataset = ReactionDataset(data)
subset_indices = list(range(N))
subset_dataset = Subset(dataset, subset_indices)
train_loader = DataLoader(dataset, batch_size=128, shuffle=True, collate_fn=collate_fn)
model = RNNModel(NUM_EMBED, INPUT_SIZE, HIDDEN_SIZE, OUTPUT_SIZE, NUM_LAYERS, DROPOUT, device).to(device)
model.train()
optimizer = optim.Adam(model.parameters(), lr=LR)
# criterion = nn.MSELoss() # MSE
criterion = nn.L1Loss() # MAE
best_loss = 10
for epoch in range(N_EPOCHS):
epoch_loss = 0
for i, (src, y) in enumerate(train_loader):
src, y = src.to(device), y.to(device)
optimizer.zero_grad()
output = model(src)
loss = criterion(output, y)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), CLIP)
optimizer.step()
epoch_loss += loss.item()
loss_in_a_epoch = epoch_loss / len(train_loader)
print(f'Epoch: {epoch+1:02} | Train Loss: {loss_in_a_epoch:.3f}')
if loss_in_a_epoch < best_loss:
# 在训练循环结束后保存模型
torch.save(model.state_dict(), '../model/RNN.pth')
end_time = time.time() # 结束计时
# 计算并打印运行时间
elapsed_time_minute = (end_time - start_time)/60
print(f"Total running time: {elapsed_time_minute:.2f} minutes")
if __name__ == '__main__':
train()保存提交结果所需的文件
# 生成结果文件
def predicit_and_make_submit_file(model_file, output_file):
NUM_EMBED = 294
INPUT_SIZE = 300
HIDDEN_SIZE = 512
OUTPUT_SIZE = 512
NUM_LAYERS = 10
DROPOUT = 0.01
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
test_data = read_data("../dataset/round1_test_data.csv", train=False)
test_dataset = ReactionDataset(test_data)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False, collate_fn=collate_fn)
model = RNNModel(NUM_EMBED, INPUT_SIZE, HIDDEN_SIZE, OUTPUT_SIZE, NUM_LAYERS, DROPOUT, device).to(device)
# 加载最佳模型
model.load_state_dict(torch.load(model_file))
model.eval()
output_list = []
for i, (src, y) in enumerate(test_loader):
src, y = src.to(device), y.to(device)
with torch.no_grad():
output = model(src)
output_list += output.detach().tolist()
ans_str_lst = ['rxnid,Yield']
for idx,y in enumerate(output_list):
ans_str_lst.append(f'test{idx+1},{y:.4f}')
with open(output_file,'w') as fw:
fw.writelines('\n'.join(ans_str_lst))
print("done!!!")
predicit_and_make_submit_file("../model/RNN.pth",
"../output/RNN_submit.txt")学习心得
这次使用的深度学习rnn比第一次用的机器学习的得分还低,根据我自己的了解的话,可能是因为数据量多且杂,rnn不容易自主学习到其中的特征。另外就是rnn是短期记忆网络,数据集中某些化学向量比较长,导致rnn无法记忆整个向量,训练出的结果也随之下降。初始参数感觉很不合理,dropout=0.2太大了,训练轮数还只有10轮,咱就是说让一个短期记忆网络丢弃20%的神经元并且只训练10次是不是太高估人家了😨
我自己按默认参数训练时,发现损失一直降不下去,感觉是学习率太高的原因,于是我讲学习率降到了0.0001,训练过程如下图(层数为30,dropout为0.01),最后面那个是训练时所花费的时间,不过是拿初始时间减当前时间,给减反了,而且没有把小数给省略🥺
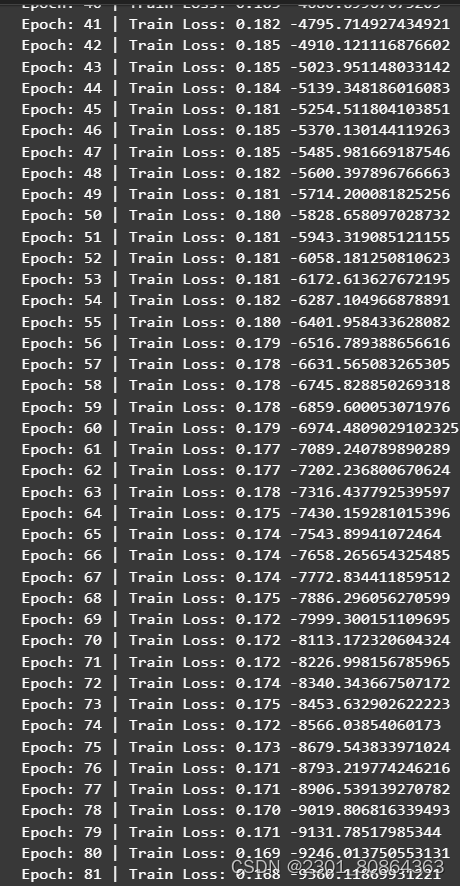
感觉损失是在逐步下降的,最终的打分为0.0600,感觉这个得分还是不理想,而且损失在是存在摇摆的情况的。然后我试了一下LSTM长短期记忆网络,层数为10,dropout为0.01,学习率为0.00005,训练时的损失如下(后面训练的秒数我给整好了😊)
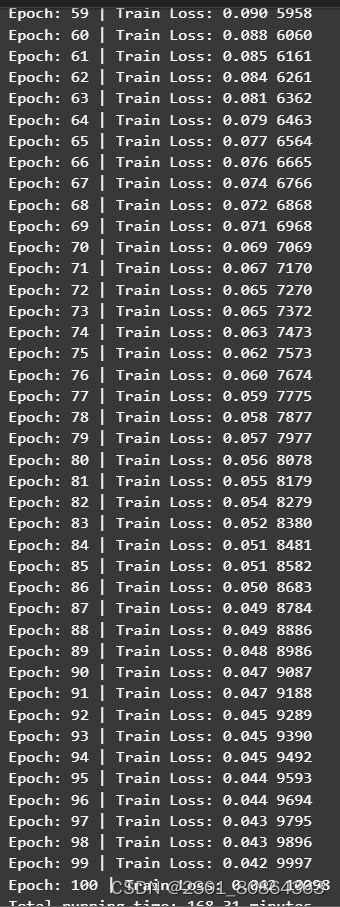
这个损失已经是算挺不错的了,但是最终的打分还是只有0.1298,有可能是已经过拟合了。















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









