






按现行统计报表制度,城镇居民可支配收入主要由四部分构成,即工资性收入、经营净收入、财产净收入、转移净收入。图1列出了 2019年全国31个省、直辖市、自治区城镇居民人均可支配收入的数据(数据来源于2020年《中国统计年鉴》)。试进行对应分析,揭示全国城镇居民人均可支配收入的特征以及各省、直辖市、自治区与各收入类型间的关系。
(1)打开SPSS软件,在表格下方有两个选项,分别是Data View 和Variable View,点击Variable View 选项,将各选项改为如下形式(见图)
其中Values项需要做如下设置:在弹出的对话框里,对北京至新疆的31省区以及工资等4项收入进行数字赋值;完成后,点击Data View进行数据的输入。
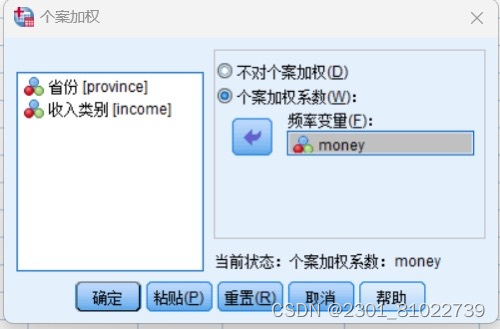
在 SPSS的数据窗口完成数据输入,然后依次点选 Data→Weight Cases 进入 WeightCases对话框,系统默认是对观测不使用权重,选中 Weight cases by 选项,此时下面的Frequency Variable 被激活,选中 money并点击箭头, 使变量money 充当权数的作用,点击OK(见图)。
其中Values项需要做如下设置:在弹出的对话框里,对北京至新疆的31省区以及工资等4项收入进行数字赋值;完成后,点击Data View进行数据的输入。
(2) 选择 Analyze→Dimension Reduction→Correspondence Analysis,然后把“省区”选入“Row”,再点击 Define Range 来定义范围为1(Minimum value) 到31 (Maximum val-ue),之后点击 Update, 再点击 Continue。之后同样地,把“收入类别”选入 Column,并定义其范围为1~4。
然后点击 Model,在出现的对话框中选择数据标准化方法,在 Distance Measure部分点选Euclidean,下面的 Standardization Method 选择选项被激活,有5 种可供选择的数据标准化方法,本例选择第5 种: Column totals are equalized and means are removed,其余选项为默认, 点击 OK 运行。
(3)输出结果分析。根据SPSS对数据的计算,会得到一系列的表格,输出表格之一就是下面各维的汇总表。输出结果中图4给出了行和列记分的关系。
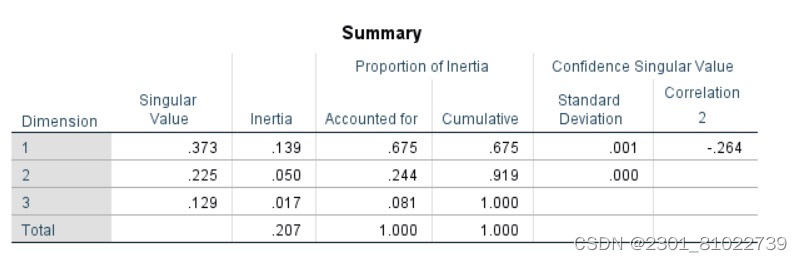
Summary给出了总惯量及每一维度(公共因子)所解释的总惯量的百分比的信息。可知总惯量为 0.207。
Singular Value 反映的是行与列各状态在二维图中分值的相关程度,实际上是对行与列进行因子分析产生的新的综合变量的典型相关系数, 其在取值上等于特征根的平方根。
Proportion of Inertia 部分是各维度(公共因子) 分别解释总惯量的比例及累计百分比,类似于因子分析中公共因子解释能力的说明。从中可以看出第一维和第二维的惯量比例占总惯量的91.9%,因此可以选取两维来进行分析。
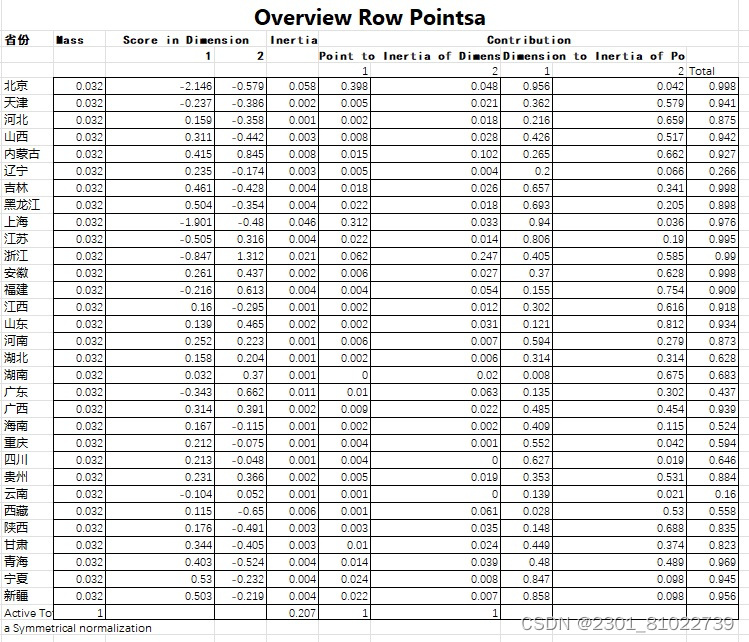
首先是关于行变量(省区) 的点坐标表,Scoręin Dimension 是各维度的分值,也就是行与列各状态在二维图中的坐标值。例如北京(-2.146,-0.579),新疆(0.503,-0.219)等。
Mass部分分别指列联表中行与列的边缘概率。即=。
Inertia是惯量,是每一行(列)与其重心的加权距离的平方,可以看到== 0.207,即行剖面的总惯量等于列剖面的总惯量。
contribution部分是指行(列)的每一状态对每一维度(公共因子) 特征根的贡献及每一维度对行(列)各个状态的特征根的贡献。由此可以更好地理解维度的来源及意义。
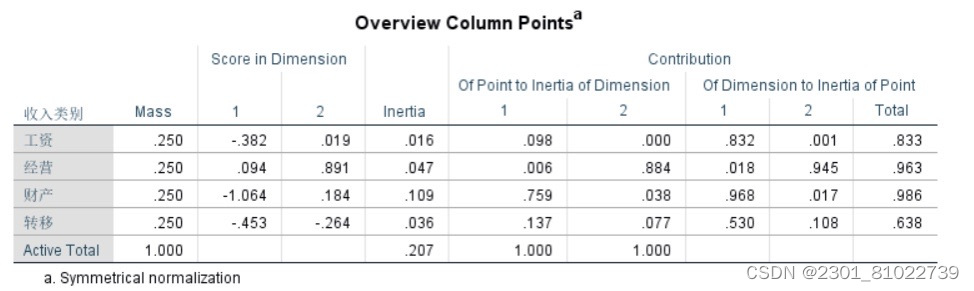
同样的,列变量(收入类别)的点坐标见输出结果。
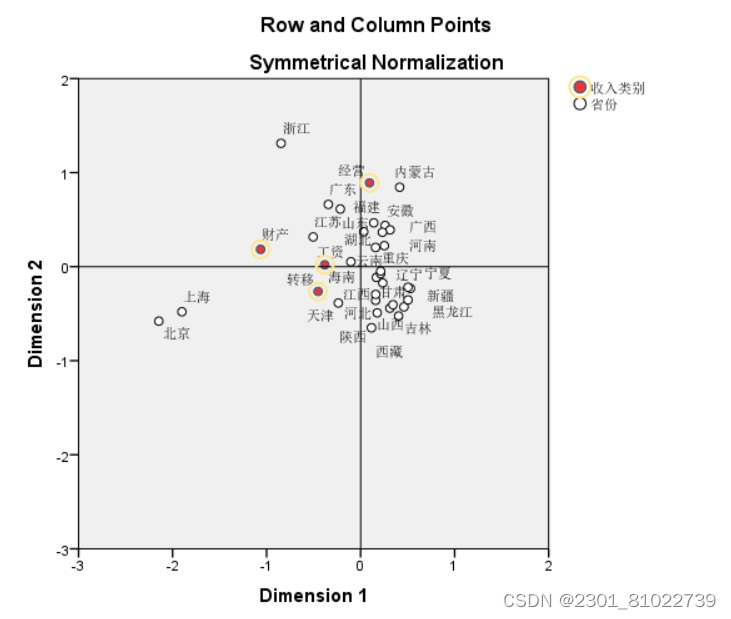
根据图5与图6表中的坐标点可以叠加散点图,在SPSS的输出结果给出了相应的散点图。从散点图中我们不难看出,北京、上海、天津等,城镇居民的收入来源主要以转移净收入为主;而广东、江苏、浙江等地区以财产净收入与工资性收入;广西、内蒙古、安徽等地区以经营净收入为主。
(如有错误,请指正)
















 1919
1919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











