







对应分析是R型因子分析和Q型因子分析的结合。本质是将列联表里面的频数数据作变换(通过降维的方法)以后,利用二维图的方式,简单直观的表示行变量和列变量之间的相关性,适合于多分类型变量的研究。数据展示如下(由于数据共195条仅展示部分):
| 专业 | 专业编号 | 院校 | 等级 | 等级编号 | 频率 |
| 财务管理 | 1 | 青岛理工大学 | 双非 | 3 | 35 |
| 财务管理 | 1 | 青岛理工大学 | 双非 | 3 | 35 |
| 财务管理 | 1 | 青岛大学 | 双非 | 3 | 35 |
| 财务管理 | 1 | 北京国家会计学院 | 双非 | 3 | 35 |
| 财务管理 | 1 | 首都经济贸易大学 | 双非 | 3 | 35 |
| 财务管理 | 1 | 宁夏大学 | 211 | 2 | 10 |
| 财务管理 | 1 | 青岛理工大学 | 双非 | 3 | 35 |
| 财务管理(中外) | 1 | 山东财经大学 | 双非 | 3 | 35 |
| 财务管理(中外) | 1 | 山东科技大学 | 双非 | 3 | 35 |
| 财务管理(中外) | 1 | 浙江理工大学 | 双非 | 3 | 35 |
| 财务管理(中外) | 1 | 中国石油大学华东 | 211 | 2 | 10 |
| 财务管理(中外) | 1 | 北京化工大学 | 211 | 2 | 10 |
| 财务管理(中外) | 1 | 南京信息工程大学 | 双非 | 3 | 35 |
| 财务管理(中外) | 1 | 北京第二外国语学院 | 双非 | 3 | 35 |
| 财务管理(中外) | 1 | 青岛理工大学 | 双非 | 3 | 35 |
| 财务管理(中外) | 1 | 中国石油大学 | 211 | 2 | 10 |
| 电子商务 | 2 | 沈阳航空航天大学 | 双非 | 3 | 1 |
| 国际经济与贸易 | 3 | 曲阜师范大学 | 双非 | 3 | 10 |
| 国际经济与贸易 | 3 | 青岛大学 | 双非 | 3 | 10 |
| 国际经济与贸易 | 3 | 宁波大学 | 双非 | 3 | 10 |
| 国际经济与贸易 | 3 | 青岛理工大学 | 双非 | 3 | 10 |
将表中第一列、第二列、第四列、第五列数据录人 SPSS 数据窗口,并对变量 专业编号 和 等级编号 的取值进行标签设定,其中专业编号1、2、3、4、5、6、7、8分别代表财务管理、电子商务、国际经济与贸易、国际商务、会计学、经济学、市场营销、统计学;等级编号1、2、3分别代表985、211、双非。对 专业编号 和 等级编号 进行对应分析,依次点选“分析-降维-对应分析”,打开对应分析对话框。变量名 专业编号 和 等级编号 将出现在对话框的左边,将 专业编号 选入右侧 行 下方的框中,此时该框的显示为 专业编号 (??)。同时,其下方的 定义范围 按钮被激活,点击该按钮,进入对话框,在该对话框中需要确定 专业编号 的取值范围,最小值( Minimum value )与最大值( Maximum value )处分别填上1和8,点击右侧的 更新 按钮,可以看到 专业编号 的取值1~8已出现在 类别约束 框架左侧的窗口中,该框架的作用是对 专业编号 的各状态加以限定,保持默认值 None 不变,即对 专业编号 的取值不加限定。
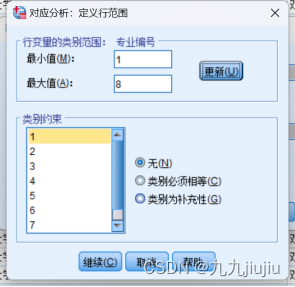
点击继续,回到对应分析主对话框,可以看到此时变量 专业编号 的显示为 专业编号 (1 8)。按照同样的方法把 等级编号 选入 列 下方的框中,并设定其取值范围为1~3,点击 确定 按钮运行,则可以得到输出结果。
| 对应表 | ||||
| 专业序号 | 院校类型 | |||
| 985 | 211 | 双非 | 活动边际 | |
| 财务管理 | 2 | 10 | 35 | 47 |
| 电子商务 | 0 | 2 | 1 | 3 |
| 国际经济与贸易 | 4 | 3 | 10 | 17 |
| 国际商务 | 0 | 5 | 4 | 9 |
| 会计 | 3 | 18 | 54 | 75 |
| 经济 | 1 | 8 | 9 | 18 |
| 市场营销 | 0 | 1 | 2 | 3 |
| 统计 | 5 | 6 | 12 | 23 |
| 活动边际 | 15 | 53 | 127 | 195 |
| 摘要 | ||||||||
| 维 | 奇异值 | 惯量 | 卡方 | 显著性 | 惯量比例 | 置信度奇异值 | ||
| 占 | 累积 | 标准差 | 相关性 | |||||
| 2 | ||||||||
| 1 | .289 | .083 | .620 | .620 | .084 | .095 | ||
| 2 | .226 | .051 | .380 | 1.000 | .076 | |||
| 总计 | .134 | 26.178 | .025a | 1.000 | 1.000 | |||
| 行点总览a | |||||||||
| 专业序号 | 数量 | 维得分 | 惯量 | 贡献 | |||||
| 1 | 2 | 点对维的惯量 | 维对点的惯量 | ||||||
| 1 | 2 | 1 | 2 | 总计 | |||||
| 财务管理 | .241 | .177 | .379 | .010 | .026 | .154 | .218 | .782 | 1.000 |
| 电子商务 | .015 | .841 | -1.633 | .012 | .038 | .182 | .253 | .747 | 1.000 |
| 国际经济与贸易 | .087 | -1.126 | -.019 | .032 | .383 | .000 | 1.000 | .000 | 1.000 |
| 国际商务 | .046 | .747 | -1.109 | .020 | .089 | .251 | .367 | .633 | 1.000 |
| 会计 | .385 | .217 | .259 | .011 | .063 | .114 | .473 | .527 | 1.000 |
| 经济 | .092 | .287 | -.750 | .014 | .026 | .230 | .157 | .843 | 1.000 |
| 市场营销 | .015 | .560 | -.063 | .001 | .017 | .000 | .990 | .010 | 1.000 |
| 统计 | .118 | -.936 | -.363 | .033 | .358 | .069 | .895 | .105 | 1.000 |
| 活动总计 | 1.000 | .134 | 1.000 | 1.000 | |||||
| 列点总览a | |||||||||
| 院校类型 | 数量 | 维得分 | 惯量 | 贡献 | |||||
| 1 | 2 | 点对维的惯量 | 维对点的惯量 | ||||||
| 1 | 2 | 1 | 2 | 总计 | |||||
| 985 | .077 | -1.824 | -.326 | .076 | .887 | .036 | .976 | .024 | 1.000 |
| 211 | .272 | .324 | -.723 | .040 | .099 | .630 | .204 | .796 | 1.000 |
| 双非 | .651 | .080 | .340 | .018 | .015 | .334 | .066 | .934 | 1.000 |
| 活动总计 | 1.000 | .134 | 1.000 | 1.000 | |||||
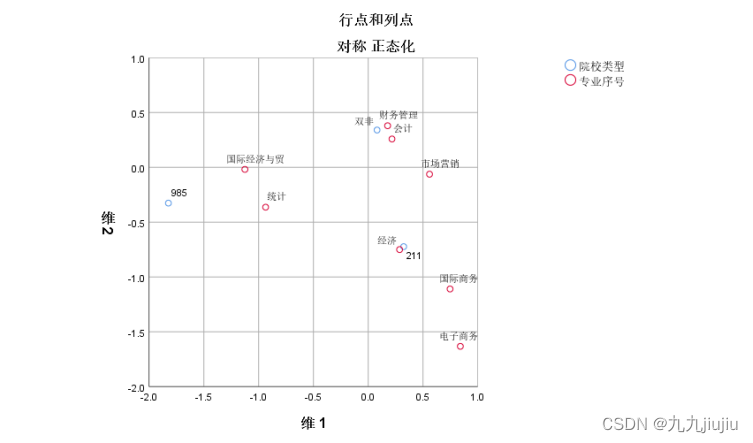
其中,输出的第一部分 对应表 是由原始数据按 专业编号 与 等级编号 分类的列联表,可以看到观测总数 n =195。
第二部分 摘要给出了惯量、卡方值及每一维度(公共因子)所解释的总惯量的百分比的信息。可知总惯量为0.134, 卡方 值为26.178,有关系式:26.178=0.134x195(由于保留小数时四舍五人,故存在误差),由此可以清楚地看到总惯量与 卡方 值的关系。同时说明总惯量描述了列联表行与列之间总的相关关系。 奇异值 反映的是行与列各状态在二维图中分值的相关程度,实际上是对行与列进行因子分析产生的新的综合变量的典型相关系数,其在取值上等于特征根的平方根。 显著性 是假设 卡方值为0成立的概率,表注表明自由度为(8-1) X (3-1)=14, 显著性 值很小说明列联表的行与列之间有较强的相关性。 惯量比例 部分是各维度(公共因子)分别解释总惯量的比例及累计百分比,类似于因子分析中公共因子解释能力的说明。
第三部分和第四部分是对列联表行与列各状态有关信息的概括。其中, 数量 部分分别指列联表中行与列的边缘概率,也就是PI与PJ。 维得分 是各维度的分值。也就是行与列各状态在二维图中的坐标值。惯量,是每一行(列)与其重心的加权距离的平方,可以看到II=IJ=0.134,即行剖面的总惯量等于列剖面的总惯量。 贡献 部分是指行(列)的每一状态对每一维度(公共因子)特征根的贡献及每一维度对行(列)各个状态的特征根的贡献。由此可以更好地理解维度的来源及意义,如第一维度中,国际经济与贸易对应的数值最大,为0.383,说明国际经济与贸易这一状态对第一维度的贡献最大。在表的最后部分维度对各状态特征根的贡献部分,看到第一维度集中了国际经济与贸易和统计学两状态的大部分差异,第二维度主要反映了国际商务和经济学的大部分差异,而对于市场营销这一状态,两个维度对其贡献度都不是特别大。
输出的最后一部分是 专业编号各状态 与 等级编号各状态 同时在一张二维图上的投影。在图上既可以看到每一变量内部各状态之间的相关关系,又可以同时考察两变量之间的相关关系。从输出结果图中可以看出, 专业 的8个状态分布较为分散,很明显形成三大类;对于 专业 国际经济与贸易和统计学被分为一类,财务管理、会计学和市场营销等被分为一类,经济、国际商务和电子商务被分为一类。同时考察两变量各状态,可以看到985的学校主要是国际经济与贸易和统计学;211学校主要是财务管理、会计学和市场营销;双非学校的主要是经济、国际商务和电子商务。以上是由 SPSS 默认设置得到的结果。实际研究时,可以根据不同的研究目的对有关设置进行修改。
下面对 SPSS 提供的有关选项进行简要说明。在 对应分析 对话框中点击右侧的 模型 按钮进入 模型 对话框,在该对话框中,可以设定进行对应分析的有关方法:在上部 解中的维数 处可以规定对应分析的最大维数,默认维数是2。由本章的论述知,最大维数应该是 min(n,p)-1,此处保留默认值即可。 距离测度 对话框中可以规定距离量度方法,默认为卡方距离,也就是加权的欧氏距离,还可以规定用欧氏距离。在 标准化方法 对话框中可以规定标准化方法,若距离的量度使用卡方距离,则应使用默认的标准化方法,即对行与列均进行中心化处理;若选择欧氏距离,则有不同的标准化方法可以选择。最下方 正态化方法 框架中可以规定不同的正态化方法,默认为 对称方法,当我们的目的是考察两变量各状态之间的差异性或相似性时,应选择此方法。当我们的目的是考察两个属性变量之间各状态及同一变量内部各状态之间的差异性时,则应当选择 主成分 方法。当我们的目的是考察不同行(列)之间的差异性或相似性时,则应当选择 行主成分(列主成分),而选中 定制 并自己设定一个﹣1~1之间的值,则可能输出更容易解释的二维图。
| 行概要 | ||||
| 专业编号 | 等级编号 | |||
| 985 | 211 | 双非 | 活动边际 | |
| 财务管理 | .043 | .213 | .745 | 1.000 |
| 电子商务 | .000 | .667 | .333 | 1.000 |
| 国际经济与贸易 | .235 | .176 | .588 | 1.000 |
| 国际商务 | .000 | .556 | .444 | 1.000 |
| 会计 | .040 | .240 | .720 | 1.000 |
| 经济 | .056 | .444 | .500 | 1.000 |
| 市场营销 | .000 | .333 | .667 | 1.000 |
| 统计 | .217 | .261 | .522 | 1.000 |
| 数量 | .077 | .272 | .651 | |
在 对应分析 对话框中点击 统计 按钮,进入 统计 对话框,选中 行剖面 和 列剖面 交由程序运行,则除上面的结果外,还可以输出行剖面与列剖面,如上表所示。
在 统计 对话框中选择其他选项,可以输出一些有用的统计量,这些统计量有助于检验对应分析的效果。在 对应分析 对话框中,点击 图 按钮进入 图 对话框,看到在 散点图 框架中系统默认输出 双标图 ,即在同一张二维图上同时输出两个属性变量的各个状态。为了考察列联表各行(列)之间的相关性,有时需要输出仅包括一个变量各种状态参数的二维图,选择 行点 及 列点 可以实现。同时选中 行点 与 列点 并交由程序运行,则可以得到输出结果如下。
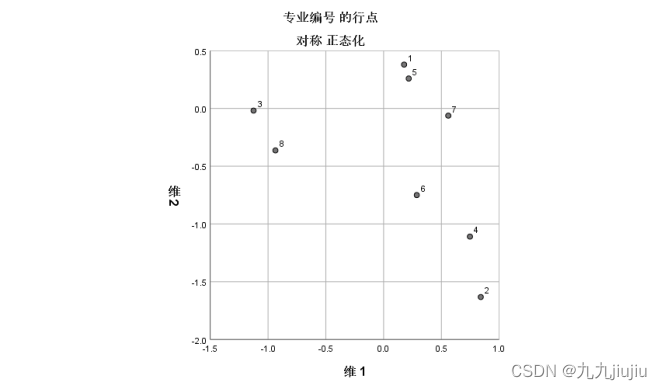
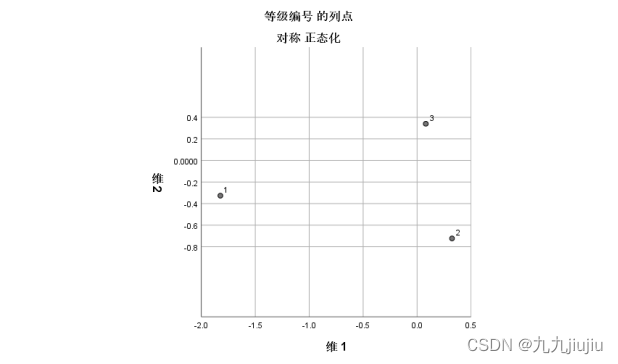
这样可以更清楚地考察每一变量各个状态之间的距离或接近程度。 SPSS 软件还提供了其他许多有用的选项,可以针对不同的研究问题及研究目的,选择这些选项以得到更多的结果。



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











