






目录
Leecode-125-验证回文串
题目
如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。
字母和数字都属于字母数字字符。
给你一个字符串 s,如果它是 回文串 ,返回 true ;否则,返回 false
示例
示例1
输入: s = “A man, a plan, a canal: Panama”
输出:true
解释:“amanaplanacanalpanama” 是回文串。
示例2
输入:s = “race a car”
输出:false
解释:“raceacar” 不是回文串。
示例3
输入:s = " "
输出:true
解释:在移除非字母数字字符之后,s 是一个空字符串 “” 。
由于空字符串正着反着读都一样,所以是回文串。
解题思路
- 获取字符串 s 的长度,并存储在变量 len 中
如果字符串长度为1,那么它肯定是一个回文串,所以直接返回 true - 遍历原始字符串 s 中的每个字符。
· 如果字符是大写字母,则将其转换为小写字母并存储在 new 中。
· 如果字符是小写字母或数字,则直接将其存储在 new 中。
通过这种方式,new 字符串只包含小写字母和数字,并且与原始字符串 s 的长度相同或更短。 - 在 new 字符串的末尾添加空字符 ‘\0’,以表示字符串的结束
- 循环判断new中存储的是否为回文字符串
代码实现
bool isPalindrome(char* s) {
int len = strlen(s);
if(len == 1) return true;
char new[100001] ;
int index = 0;
for(int i = 0; i < len; i++){
if(s[i] >= 'A' && s[i] <= 'Z'){
new[index] = s[i] + 32;
index++;
}
else if((s[i] >= 'a' && s[i] <= 'z') || (s[i] >= '0' && s[i] <= '9')){
new[index] = s[i];
index++;
}
}
new[index] = '\0';
int len2 = strlen(new);
for(int i = 0,j = len2 - 1; i <= j; i++,j--){
if(new[i] != new[j]){
return false;
}
}
return true;
}
Leecode-73-矩阵置零
题目
给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。
示例
示例1
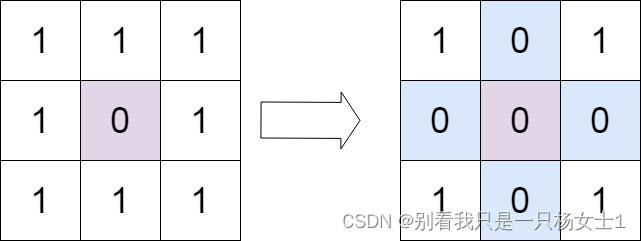
输入:matrix = [[1,1,1],[1,0,1],[1,1,1]]
输出:[[1,0,1],[0,0,0],[1,0,1]]
示例2
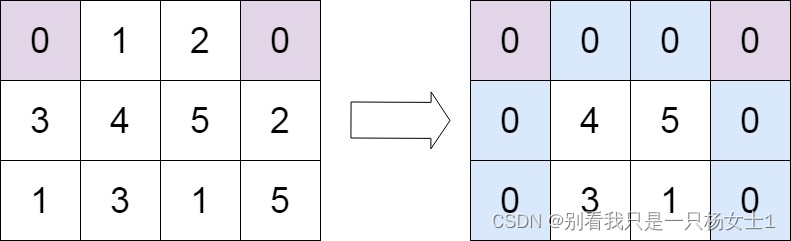
输入:matrix = [[0,1,2,0],[3,4,5,2],[1,3,1,5]]
输出:[[0,0,0,0],[0,4,5,0],[0,3,1,0]]
解题思路
- 首先创建了一个大小为201x201的临时矩阵tmp,将每个元素的值复制到临时矩阵tmp中
- 再次遍历临时矩阵tmp。如果找到一个值为0的元素,它会遍历整行和整列,并将相应位置上的元素在原始矩阵matrix中设置为0
代码实现
void setZeroes(int** matrix, int matrixSize, int* matrixColSize) {
int tmp[201][201];
//int cnt1 = 0, cnt2 = 0;
for(int i = 0; i < matrixSize; i++){
for(int j = 0; j < *matrixColSize; j++){
tmp[i][j] = matrix[i][j];
}
}
for(int i = 0; i < matrixSize; i++){
for(int j = 0; j < *matrixColSize; j++){
if(tmp[i][j] == 0){
for(int n = 0;n < *matrixColSize;n++){
matrix[i][n] = 0;
}
for(int m = 0;m < matrixSize;m++){
matrix[m][j] = 0;
}
}
}
}
}
这个实现方法效率很低,因为它对每一个值为0的元素都进行了两次额外的遍历,以下是改进后的代码
void setZeroes(int** matrix, int matrixSize, int* matrixColSize) {
int rows[matrixSize];
int cols[*matrixColSize];
int rowZero = 0, colZero = 0;
// 初始化rows和cols数组
memset(rows, 0, sizeof(rows));
memset(cols, 0, sizeof(cols));
// 遍历矩阵,记录哪些行和列包含0
for (int i = 0; i < matrixSize; i++) {
for (int j = 0; j < *matrixColSize; j++) {
if (matrix[i][j] == 0) {
rows[i] = 1; // 第i行包含0
cols[j] = 1; // 第j列包含0
if (i == 0) rowZero = 1; // 第一行包含0
if (j == 0) colZero = 1; // 第一列包含0
}
}
}
// 将包含0的行和列的元素设置为0
for (int i = 0; i < matrixSize; i++) {
for (int j = 0; j < *matrixColSize; j++) {
if (rows[i] || (j == 0 && rowZero)) {
matrix[i][j] = 0; // 设置行
}
if (cols[j] || (i == 0 && colZero)) {
matrix[i][j] = 0; // 设置列
}
}
}
}
Leecode-21-合并两个有序链表
题目
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例
示例1
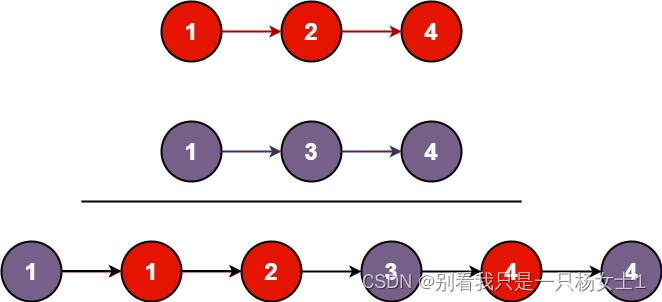
输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
示例2
输入:l1 = [], l2 = []
输出:[]
示例3
输入:l1 = [], l2 = [0]
输出:[0]
解题思路
- 判断如果两个链表其中有一个为空,则返回另一个链表
- 从两个链表的第一个值进行比较,如果第一个链表的第一个值小于第二个链表的第一个值,则更新mergelist的值为第一个链表
- 递归更新mergelist->next
代码实现
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {
if (list1 == NULL) {
return list2;
}
if (list2 == NULL) {
return list1;
}
struct ListNode* mergedList;
if (list1->val <= list2->val) {
mergedList = list1;
mergedList->next = mergeTwoLists(list1->next, list2);
} else if(list1->val > list2->val) {
mergedList = list2;
mergedList->next = mergeTwoLists(list1, list2->next);
}
return mergedList;
}
Leecode-147-对链表进行插入排序
题目
给定单个链表的头 head ,使用 插入排序 对链表进行排序,并返回 排序后链表的头 。
插入排序 算法的步骤:
- 插入排序是迭代的,每次只移动一个元素,直到所有元素可以形成一个有序的输出列表。
- 每次迭代中,插入排序只从输入数据中移除一个待排序的元素,找到它在序列中适当的位置,并将其插入。
- 重复直到所有输入数据插入完为止。
下面是插入排序算法的一个图形示例。部分排序的列表(黑色)最初只包含列表中的第一个元素。每次迭代时,从输入数据中删除一个元素(红色),并就地插入已排序的列表中。
对链表进行插入排序。
示例
示例1
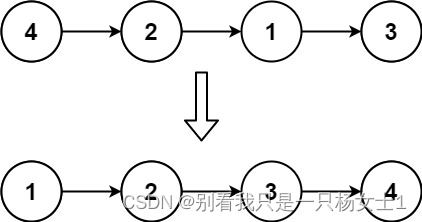
输入: head = [4,2,1,3]
输出: [1,2,3,4]
示例2
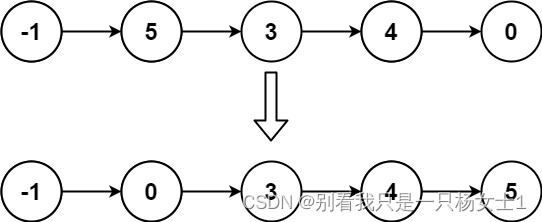
输入: head = [-1,5,3,4,0]
输出: [-1,0,3,4,5]
解题思路
-
检查链表是否为空或只有一个节点。如果是,则不需要进行排序,直接返回原链表。
-
创建一个虚拟头节点
dummyhead,并将其next指针指向原链表的头节点head。虚拟头节点的作用是简化边界条件的处理,使得排序逻辑更加清晰。 -
定义一个指针pCurrent,初始化为dummyhead的下一个节点,即原链表的头节点。
-
外层循环,遍历链表中的每个节点。对于每个节点pCurrent,内层循环用于找到第一个比pCurrent->val大的节点。如果找不到这样的节点,说明pCurrent已经处于正确的位置,内层循环结束。
-
在内层循环结束后,pCurrent指向的节点及其之后的子链表已经是有序的。接下来,需要找到pCurrent->next(即tmp)在有序子链表中的正确位置,并进行插入操作。
-
为了找到tmp的正确位置,定义一个指针pPrev,初始化为dummyhead。然后,通过比较pPrev->next->val和tmp->val的值,移动pPrev直到找到tmp应该插入的位置。
-
找到插入位置后,更新指针的指向关系,将tmp插入到pPrev->next之前。具体操作为:将pCurrent->next指向tmp->next,将tmp->next指向pPrev->next,将pPrev->next指向tmp。
-
完成插入操作后,将pCurrent移动到下一个节点,继续外层循环的下一轮迭代。
-
当外层循环结束后,整个链表已经排好序。最后,将head更新为dummyhead->next,即排序后的链表的头节点,并释放虚拟头节点dummyhead的内存。
-
返回排序后的链表的头节点head
代码实现
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode Node;
struct ListNode* insertionSortList(struct ListNode* head) {
if (head || head->next)
{
Node *dummyhead = (Node *)malloc( sizeof(Node) );
dummyhead->next = head;
head = dummyhead;
Node *pCurrent = head->next;
while (pCurrent != NULL)
{
while (pCurrent->next != NULL && pCurrent->val <= pCurrent->next->val)
{
pCurrent = pCurrent->next;
}
Node *tmp = pCurrent->next;
if (tmp)
{
Node *pPrev = head;
while (pPrev->next != pCurrent && (pPrev->next->val <= tmp->val))
{
pPrev = pPrev->next;
}
pCurrent->next = tmp->next;
tmp->next = pPrev->next;
pPrev->next = tmp;
}else{
pCurrent = pCurrent->next;
}
}
head = dummyhead->next;
free(dummyhead);
}
return head;
}
Leecode-309-买卖股票的最佳时机含冷冻期
题目
给定一个整数数组prices,其中第 prices[i] 表示第 i 天的股票价格 。
设计一个算法计算出最大利润。在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票):
卖出股票后,你无法在第二天买入股票 (即冷冻期为 1 天)。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例
示例1
输入: prices = [1,2,3,0,2]
输出: 3
解释: 对应的交易状态为: [买入, 卖出, 冷冻期, 买入, 卖出]
示例2
输入: prices = [1]
输出: 0
解题思路
- DP数组dp是一个二维数组,其中dp[i][j]表示第i天结束时,状态为j时的最大利润。状态有三种:
FREE:当前手上没有股票,且不在冷冻期,可以随时买入。
HOLD:当前手上有股票,无法卖出,等待价格上涨。
COOLDOWN:刚刚卖出了股票,处于冷冻期,无法买入。 - 对于每一天,我们可以根据前一天的状态转移到当前状态,并更新最大利润。状态转移方程如下:
- dp[i][FREE] = max(dp[i - 1][FREE]
dp[i - 1][COOLDOWN]):如果当前状态为FREE,那么前一天可以是FREE状态(没有操作)或COOLDOWN状态(冷冻期结束) - dp[i][HOLD] = max(dp[i - 1][HOLD],
dp[i - 1][FREE] - prices[i]):如果当前状态为HOLD,那么前一天可以是HOLD状态(没有操作)或FREE状态(买入股票) - dp[i][COOLDOWN] = dp[i - 1][HOLD] + prices[i]:
如果当前状态为COOLDOWN,那么前一天必须是HOLD状态(卖出股票)
- 最后,返回最后一天结束时的最大利润,即max(dp[pricesSize - 1][FREE], dp[pricesSize - 1][COOLDOWN])。
代码实现
const int FREE = 0, HOLD = 1, COOLDOWN = 2;
int maxProfit(int* prices, int pricesSize) {
int** dp = (int**) malloc(sizeof(int*) * pricesSize);
for (int i = 0; i < pricesSize; i++) {
dp[i] = (int*) malloc(sizeof(int) * 3);
}
dp[0][FREE] = 0;
dp[0][HOLD] = -prices[0];
dp[0][COOLDOWN] = INT_MIN;
for (int i = 1; i < pricesSize; i++) {
dp[i][FREE] = fmax(dp[i - 1][FREE], dp[i - 1][COOLDOWN]);
dp[i][HOLD] = fmax(dp[i - 1][HOLD], dp[i - 1][FREE] - prices[i]);
dp[i][COOLDOWN] = dp[i - 1][HOLD] + prices[i];
}
return fmax(dp[pricesSize - 1][FREE], dp[pricesSize - 1][COOLDOWN]);
}
Leecode-187-重复的DNA序列
题目
DNA序列 由一系列核苷酸组成,缩写为 ‘A’, ‘C’, ‘G’ 和 ‘T’.。
例如,“ACGAATTCCG” 是一个 DNA序列 。
在研究 DNA 时,识别 DNA 中的重复序列非常有用。
给定一个表示 DNA序列 的字符串 s ,返回所有在 DNA 分子中出现不止一次的 长度为 10 的序列(子字符串)。你可以按 任意顺序 返回答案。
示例
示例1
输入:s = “AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT”
输出:[“AAAAACCCCC”,“CCCCCAAAAA”]
示例2
输入:s = “AAAAAAAAAAAAA”
输出:[“AAAAAAAAAA”]
解题思路
- 辅助函数:
- DNAHash* FindDna(char *s, int begin):从哈希表中查找从s的begin位置开始的长度为10的子串。如果找到,返回对应的DNAHash结构体指针;否则返回NULL。
- int GetDnaCnt(char *s, int begin):返回从s的begin位置开始的长度为10的子串在哈希表中出现的次数。
- void AddDna2Hash(char *s, int begin):将从s的begin位置开始的长度为10的子串添加到哈希表中。如果该子串已经存在,则增加其计数;否则,创建一个新的DNAHash结构体并添加到哈希表中。
- 主函数:
char ** findRepeatedDnaSequences(char * s, int* returnSize):这是主要的函数,用于查找并返回所有出现至少两次的、长度为10的连续子串。
· 首先,它计算了DNA字符串s的长度。
· 初始化一个结果数组result,用于存储找到的重复子串。
· 遍历字符串s,从每个可能的起始位置开始,长度为10的子串被添加到哈希表中。
· 如果某个子串的计数达到2(即它第二次出现),则将其添加到结果数组中。
· 在完成所有操作后,遍历哈希表并释放其占用的内存。
· 最后,返回结果数组并设置returnSize为结果数组中的子串数量。
代码实现
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
#define LEN 10
typedef struct DnaHash{
char dna[LEN + 1];
int cnt;
UT_hash_handle hh;
}DnaHash;
DnaHash* Dnahead = NULL;
DnaHash* FindDna(char* s,int begin){
DnaHash* flag = NULL;
char tmp[LEN+1] = {0};
strncpy(tmp, s + begin, LEN);
HASH_FIND_STR(Dnahead, tmp, flag);
return flag;
}
int GetDnaCnt(char *s, int begin){
DnaHash* tmp = FindDna(s, begin);
if(tmp != NULL){
return tmp->cnt;
}else{
return 0;
}
}
void AddDnaToHash(char *s,int begin){
DnaHash *tmp = FindDna(s, begin);
if(tmp == NULL){
tmp = (DnaHash *)malloc(sizeof(DnaHash));
memset(tmp, 0, sizeof(DnaHash));
strncpy(tmp->dna, s + begin, LEN);
tmp->cnt = 1;
HASH_ADD_STR(Dnahead, dna, tmp);
}else{
(tmp->cnt)++;
}
}
char ** findRepeatedDnaSequences(char * s, int* returnSize){
int len = strlen(s);
char **res = (char **)malloc(sizeof(char*)*len);
int cnt = 0;
for(int i = 0; i <= len - LEN; i++){
AddDnaToHash(s, i);
if(GetDnaCnt(s, i) == 2){
char* tmp = (char*)malloc(LEN + 1);
memset(tmp, 0, LEN + 1);
strncpy(tmp, s + i, LEN);
res[cnt++] = tmp;
}
}
DnaHash* pPrev = NULL;
DnaHash* pCurrent = NULL;
HASH_ITER(hh, Dnahead, pPrev, pCurrent) {
HASH_DEL(Dnahead, pPrev);
free(pPrev);
}
Dnahead = NULL;
*returnSize = cnt;
return res;
}
Leecode-2517-礼盒的最大甜蜜度
题目
给你一个正整数数组 price ,其中 price[i] 表示第 i 类糖果的价格,另给你一个正整数 k 。
商店组合 k 类 不同 糖果打包成礼盒出售。礼盒的 甜蜜度 是礼盒中任意两种糖果 价格 绝对差的最小值。
返回礼盒的 最大 甜蜜度。
示例
示例1
输入:price = [13,5,1,8,21,2], k = 3
输出:8
解释:选出价格分别为 [13,5,21] 的三类糖果。
礼盒的甜蜜度为 min(|13 - 5|, |13 - 21|, |5 - 21|) = min(8, 8, 16) = 8 。
可以证明能够取得的最大甜蜜度就是 8 。
示例2
输入:price = [1,3,1], k = 2
输出:2
解释:选出价格分别为 [1,3] 的两类糖果。
礼盒的甜蜜度为 min(|1 - 3|) = min(2) = 2 。
可以证明能够取得的最大甜蜜度就是 2 。
示例3
输入:price = [7,7,7,7], k = 2
输出:0
解释:从现有的糖果中任选两类糖果,甜蜜度都会是 0 。
解题思路
-
check 函数:
检查给定的味道值 tastiness 是否有效。从价格数组的第一个元素开始遍历,尝试找到尽可能多的满足条件的价格对。如果一对价格(当前元素和前一个元素)的差值大于或等于 tastiness,那么这对价格就是有效的,计数器 cnt 增加,并且更新起点为当前元素。最后,如果找到的有效价格对数量 cnt 大于或等于 k,则返回 true,否则返回 false。 -
maximumTastiness 函数:
用二分查找来确定最大的味道值。首先,对价格数组进行排序,以便在 check 函数中更容易找到满足条件的价格对。然后,设置二分查找的左右边界 left 和 right,分别为0和价格数组的最大值与最小值的差。在每次迭代中,计算中间值 mid,并调用 check 函数检查它是否有效。如果有效,更新 left 为 mid,以便在右侧继续查找更大的味道值;如果无效,更新 right 为 mid - 1,缩小查找范围。最终,当 left 和 right 相等时,循环结束,返回 left 作为最大的味道值。
代码实现
bool check(const int* price, int priceSize,int k, int tastiness) {
int prev = price[0];
int cnt = 1;
for (int i = 0; i < priceSize; i++) {
int p = price[i];
if (p - prev >= tastiness) {
cnt++;
prev = p;
}
}
return cnt >= k;
}
static inline int cmp(const void *pa, const void *pb) {
return *(int *)pa - *(int *)pb;
}
int maximumTastiness(int* price, int priceSize, int k) {
qsort(price, priceSize, sizeof(int), cmp);
int left = 0, right = price[priceSize - 1] - price[0];
while (left < right) {
int mid = (left + right + 1) >> 1;
if (check(price, priceSize, k, mid)) {
left = mid;
} else {
right = mid - 1;
}
}
return left;
}
Leecode-238-除自身以外数组的乘积
题目
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。
题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。
请 不要使用除法,且在 O(n) 时间复杂度内完成此题。
示例
示例1
输入: nums = [1,2,3,4]
输出: [24,12,8,6]
示例2
输入: nums = [-1,1,0,-3,3]
输出: [0,0,9,0,0]
解题思路
- 创建一个结果数组 res,并将第一个元素初始化为 1
- 从左到右遍历数组,记录左侧元素的乘积
- 从右到左遍历数组,记录右侧元素的乘积
- 返回结果数组 res
代码实现
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
int* productExceptSelf(int* nums, int numsSize, int* returnSize) {
int *res = (int *)malloc(sizeof(int)* numsSize);
*returnSize = numsSize;
res[0] = 1;
for(int i = 1; i < numsSize; i++){
res[i] = res[i - 1] * nums[i - 1];
}
int flag = 1;
for(int i = numsSize - 1; i >= 0; i--){
res[i] *= flag;
flag *= nums[i];
}
return res;
}
Leecode-394-字符串解码
题目
给定一个经过编码的字符串,返回它解码后的字符串。
编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。
你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4] 的输入。
示例
示例1
输入:s = “3[a]2[bc]”
输出:“aaabcbc”
示例2
输入:s = “3[a2[c]]”
输出:“accaccacc”
示例3
输入:s = “2[abc]3[cd]ef”
输出:“abcabccdcdcdef”
解题思路
- 初始化两个栈 ch 和 num,以及两个栈顶指针 c_top 和 n_top。ch 用于存储解码后的字符,num 用于存储对应子字符串的重复次数
- 遍历输入字符串 s 中的每个字符
- 当遇到 [ 时,将当前的重复次数 tmp 压入 num 栈,并将 [ 压入 ch 栈。然后将 tmp 重置为 0,准备计算下一个子字符串的重复次数
- 当遇到 ] 时,开始解码当前的子字符串。首先,创建一个临时字符串 str 用于存储 [ 和 ] 之间的字符。然后,从 ch 栈中弹出字符直到遇到 [,并将这些字符反向添加到 str 中。接着,弹出 [。此时,str 存储了需要重复的子字符串。然后,从 num 栈中弹出对应的重复次数 times,并将 str 重复 times 次,再将这些字符压回 ch 栈
- 当遇到数字时,更新 tmp 的值
- 当遇到字母时,直接将其压入 ch 栈
- 遍历结束后,ch 栈中存储了解码后的字符串。将 ch 栈中的内容复制到动态分配的内存 res 中,并返回 res
代码实现
void reverse(char * s)
{
for(int i = 0, j = strlen(s) - 1; i < j; i++, j--){
char tmp = s[i];
s[i] = s[j];
s[j] = tmp;
}
}
#define size_max 10000
char* decodeString(char* s) {
char ch[size_max] = "";
int num[size_max] = { 0 };
int tmp = 0;
int c_top = -1, n_top = -1;
int len = strlen(s);
for(int i = 0;i < len; i++){
if(s[i] == '['){
num[++n_top] = tmp;
ch[++c_top] = '[';
tmp = 0;
}else if(s[i] == ']'){
char str[1000] = "";
int k = 0;
while(ch[c_top] != '['){
str[k++] = ch[c_top--];
}
c_top--;
reverse(str);
int times = num[n_top--];
for(int j = 0; j < times; j++){
for(int m = 0; m < k; m++){
ch[++c_top] = str[m];
}
}
}else if(s[i] >= '0' && s[i] <= '9'){
tmp = tmp*10 + (s[i] - '0');
}else {
ch[++c_top] = s[i];
}
}
char *res = malloc(sizeof(char)*size_max);
memset(res, '\0', sizeof(char) * size_max);
memcpy(res, ch, c_top + 1);
return res;
}
Leecode-23-合并K个升序链表
题目
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例
示例1
输入:lists = [[1,4,5],[1,3,4],[2,6]]
输出:[1,1,2,3,4,4,5,6]
解释:链表数组如下:
[
1->4->5,
1->3->4,
2->6
]
将它们合并到一个有序链表中得到。
1->1->2->3->4->4->5->6
示例2
输入:lists = []
输出:[]
示例3
输入:lists = [[]]
输出:[]
解题思路
-
mergeTwoLists这个函数使用递归的方式合并两个有序链表。- 如果 list1 为空,返回 list2。如果 list2 为空,返回 list1
- 递归:比较 list1 和 list2 的头节点值
如果 list1 的头节点值小于等于 list2 的头节点值,那么将 list1 作为结果链表的当前节点,地合并 list1 的下一个节点和 list2。否则,将 list2 作为结果链表的当前节点,并递归地合并 list1 和 list2 的下一个节点 - 返回合并后的链表头节点 ans
-
mergeKLists这个函数使用上述的 mergeTwoLists 函数来合并多个有序链表- 如果 listsSize 为0(即没有链表需要合并),返回 NULL
- 初始化一个 head 指针为 NULL,它将用于保存合并后的链表的头节点
- 遍历 lists 数组中的每个链表,使用 mergeTwoLists 函数将 head 与当前链表 lists[i] 合并,并将结果赋值给 head
- 返回合并后的链表头节点 head
代码实现
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {
if(list1 == NULL){
return list2;
}
if(list2 == NULL){
return list1;
}
struct ListNode* ans;
if(list1->val <= list2->val){
ans = list1;
ans->next = mergeTwoLists(list1->next,list2);
}
else{
ans = list2;
ans->next = mergeTwoLists(list1,list2->next);
}
return ans;
}
struct ListNode* mergeKLists(struct ListNode** lists, int listsSize) {
if(!listsSize) return NULL;
struct ListNode* head = NULL;
for(int i = 0; i < listsSize; i++){
head = mergeTwoLists(head,lists[i]);
}
return head;
}
Leecode-232-用栈实现队列
题目
请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty):
实现 MyQueue 类:
void push(int x) 将元素 x 推到队列的末尾
int pop() 从队列的开头移除并返回元素
int peek() 返回队列开头的元素
boolean empty() 如果队列为空,返回 true ;否则,返回 false
说明:
你 只能 使用标准的栈操作 —— 也就是只有 push to top, peek/pop from top, size, 和 is empty 操作是合法的。
你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
示例
示例1
输入:
[“MyQueue”, “push”, “push”, “peek”, “pop”, “empty”]
[[], [1], [2], [], [], []]
输出:
[null, null, null, 1, 1, false]
解释:
MyQueue myQueue = new MyQueue();
myQueue.push(1); // queue is: [1]
myQueue.push(2); // queue is: [1, 2] (leftmost is front of the queue)
myQueue.peek(); // return 1
myQueue.pop(); // return 1, queue is [2]
myQueue.empty(); // return false
解题思路
- myQueueCreate
功能:创建一个新的队列,并初始化栈顶指针。 - myQueuePush
功能:将一个元素推入队列。 - myQueuePop
功能:从队列中弹出一个元素。
如果 stkOut 是空的,它会从 stkIn 中取出所有元素并放入 stkOut 中,然后弹出 stkOut 的顶部元素。这是为了确保弹出的元素是队列中最先进入的元素。 - myQueuePeek
功能:查看队列的顶部元素但不弹出。 - myQueueEmpty
功能:检查队列是否为空。 - myQueueFree
功能:释放队列。
代码实现
typedef struct {
int stkInTop,stkOutTop;
int stkIn[100],stkOut[100];
} MyQueue;
MyQueue* myQueueCreate() {
MyQueue* queue = (MyQueue*)malloc(sizeof(MyQueue));
queue->stkInTop = 0;
queue->stkOutTop = 0;
return queue;
}
void myQueuePush(MyQueue* obj, int x) {
obj->stkIn[(obj->stkInTop)++] = x;
}
int myQueuePop(MyQueue* obj) {
int inTop = obj->stkInTop;
int outTop = obj->stkOutTop;
if(outTop == 0){
while(inTop){
obj->stkOut[outTop++] = obj->stkIn[--inTop];
}
}
int res = obj->stkOut[--outTop];
while(outTop){
obj->stkIn[inTop++] = obj->stkOut[--outTop];
}
obj->stkInTop = inTop;
obj->stkOutTop = outTop;
return res;
}
int myQueuePeek(MyQueue* obj) {
return obj->stkIn[0];
}
bool myQueueEmpty(MyQueue* obj) {
return obj->stkInTop == 0 && obj->stkOutTop == 0;
}
void myQueueFree(MyQueue* obj) {
obj->stkInTop = 0;
obj->stkOutTop = 0;
}
Leecode-61-旋转链表
题目
给你一个链表的头节点 head ,旋转链表,将链表每个节点向右移动 k 个位置。
示例
示例1
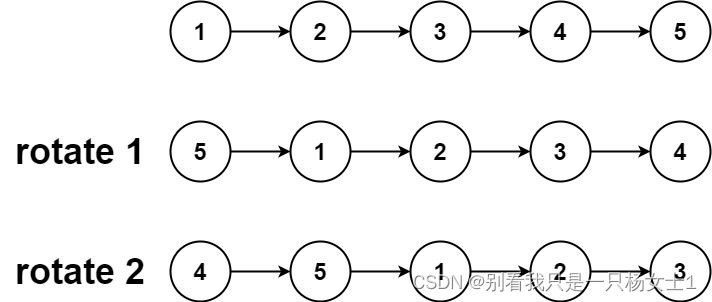
输入:head = [1,2,3,4,5], k = 2
输出:[4,5,1,2,3]
示例2
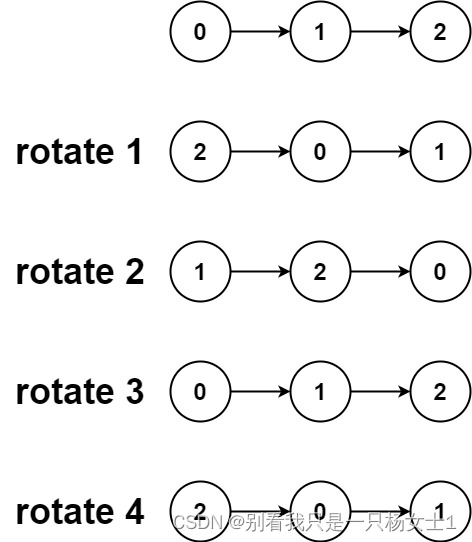
输入:head = [0,1,2], k = 4
输出:[2,0,1]
解题思路
- 边界条件检查:
如果链表为空 (head == NULL),则直接返回 head,因为无法对空链表进行旋转 - 计算链表长度:
使用 pPrev 指针遍历整个链表,同时计算链表的长度 len - 处理特殊情况:
如果链表只有一个节点 (len == 1) 或者 k 为0,则链表无需旋转,直接返回 head - 调整 k 的值:
使用 k = k % len 确保 k 的值不超过链表的长度,因为如果 k 大于链表长度,则实际上的旋转效果会与 k 对链表长度取模的结果相同 - 找到新的头节点的前一个节点:
使用 pPrev 再次遍历链表,直到找到新的头节点的前一个节点。新的头节点是原链表中倒数第 k 个节点 - 断开链表并连接新的头节点:
将 pPrev->next 设置为 NULL,断开原链表的尾部与新头节点之间的连接。然后,通过遍历找到原链表的最后一个节点,并将其 next 指针指向原链表的头节点 head,完成链表的旋转 - 返回新的头节点:
代码实现
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* rotateRight(struct ListNode* head, int k) {
if(head == NULL) return head;
struct ListNode* pPrev = head;
int len = 0;
while(pPrev != NULL){
len++;
pPrev = pPrev->next;
}
k = k % len;
if(len == 1 || k == 0){
return head;
}
pPrev = head;
for(int i = 0; i < len - k - 1; i++){
pPrev = pPrev->next;
}
struct ListNode* pCurrent = pPrev->next;
struct ListNode* res = pCurrent;
pPrev->next = NULL;
while(pCurrent->next){
pCurrent = pCurrent->next;
}
pCurrent->next = head;
return res;
}
Leecode-392-判断子序列
题目
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序列,而"aec"不是)。
进阶:
如果有大量输入的 S,称作 S1, S2, … , Sk 其中 k >= 10亿,你需要依次检查它们是否为 T 的子序列。在这种情况下,你会怎样改变代码?
示例
示例1
输入:s = “abc”, t = “ahbgdc”
输出:true
示例2
输入:s = “axc”, t = “ahbgdc”
输出:false
解题思路
- 分别记录字符串
s和t长度: - 处理边界: 如果 s 为空字符串(长度为0),则它是任何字符串(包括空字符串)的子序列,所以返回 true。
- 双指针遍历:
使用两个指针 i 和 j 分别指向 s 和 t 的当前字符。 - 字符匹配:
检查当前 s 和 t 的字符是否匹配,如果匹配,则 i 指针向前移动一位,表示已经找到了 s 的一个字符在 t 中的位置。如果 i 已经遍历完 s 的所有字符,说明 s 是 t 的子序列,返回 true。 - 返回结果:
如果循环结束仍然没有找到完整的子序列(即 s 中的所有字符),则返回 false。
代码实现
bool isSubsequence(char* s, char* t) {
int len1 = strlen(s);
int len2 = strlen(t);
if(len1 == 0) return true;
for(int i = 0,j = 0; i < len1 && j < len2; j++){
if(s[i] == t[j]){
i++;
if(i == len1 ) return true;
}
}
return false;
}















 2251
2251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









